【论文阅读】RepVGG: Making VGG-style ConvNets Great Again(CVPR2021)
论文题目:RepVGG: Making VGG-style ConvNets Great Again
论文地址:https://arxiv.org/abs/2101.03697
代码地址:https://github.com/DingXiaoH/RepVGG
文章贡献:
1. 提出RepVGG网络,实现精度与速度的权衡;
2. 提出 structural re-parameterization ,将多分支的训练模型解耦成普通结构用于推理;
3. 展示了RepVGG在图像分类和语义分割方面的有效性,以及实现的效率和易用性。
总的来说,提出了一个思想,用A网络来进行训练,然后将A网络等价变换为B网络,用B网络来推理。A网络精度高,而B网络速度快。
1 背景和动机
神经网络自各种复杂结构(如resnet,inception等)提出后,vgg这样的“直筒型”简单架构鲜有问津。
| VGG结构 | 复杂结构 | |
| 优点 | 无额外分支,只有3x3卷积和ReLU(工业实际使用时可节约成本),设计简单,运行速度快(3x3卷积计算密度高于1x1和5x5)。 | 多分支结构集成了浅层和深层特征,避免梯度消失问题。 |
| 缺点 | 精度不够高。 | 1.降低了推理速度,增加了显存使用;2.增加了内存访问,对GPU设备有限制。 |
基于上述优缺点,多分支结构适合用于训练阶段,而不适合用于推理阶段,单分支结构与之相反。
因此,论文提出将网络模型structural re-parameterization,用多分支模型训练,之后将其等价变换成简单模型用于推理阶段,由此提出RepVGG,实现精度和速度的平权衡。
2 相关工作
单路径和多分支:自单路径的vgg后,涌现了很多多分支复杂结构,如GoogLeNet、inception、resnet、densenet等。NAS和手工设计的复杂结构使得网络性能更高,但需要大量计算资源。一些过于复杂的模型对GPU有需求,限制了实际使用,且可能降低推理速度。
单路径模型的有效训练:以往的研究主要是为了使非常深的模型收敛到合理的精度,而没有达到比复杂模型更好的性能。如initialization method[1]训练了1w层但效果和低层网络差不多;Leaky ReLU, max-norm and careful initialization方法的精度也没有高过resnet101的基线网络。
模型重参数化:DiracNet[2]在训练阶段并不是一个真正的多分支模型,且其性能比resnet低。Asym Conv Block、DO-Conv和ExpandNet将一个block转换成了conv,为组件级的改进而设计,并被用作任何体系结构中conv层的临时替代。
而RepVGG在训练阶段是多分支模型,性能高于resnet,其re-parameterization对于训练来说是至关重要的。
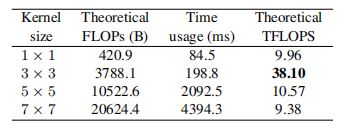
Winograd Convolution:不同kernel size的计算成本对比,第一列为FLOPs,第二列实际运行时间,第3列为计算密度:
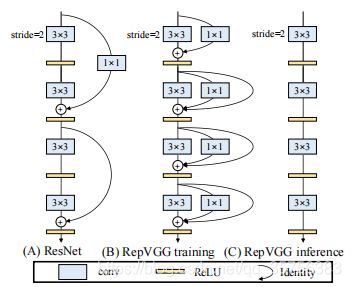
3 模型结构
RepVGG相较于多分支结构的优点
- 速度快:fragmented operators的数量(一个block中卷积核池化的数量)为1,而resnets为2或3;
- 内存少:残差结构和普通结构内存使用的对比,残差结构每个分支的结果都需要保持到+为止:
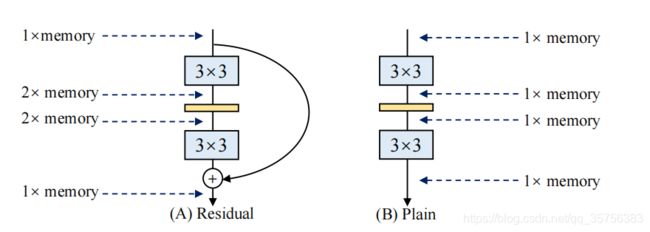
- 灵活性:resnet要求每个residual block的最后一个conv层必须产生相同shape的张量,且多分支结构也限制了通道剪枝(移除一些不重要的通道)的应用。
训练阶段的多分支结构
ResNet:y=x+f(x) 或 y=g(x)+f(x) ,其中f是残差结构,当x和f(x)通道数不匹配时有g为1x1卷积来调整通道数。
RepVGG:y=x+g(x)+f(x),仅当通道数匹配时使用x。简单堆叠上述几个块作为训练模型。
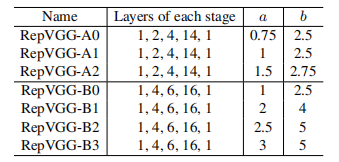
下面用一句话介绍RepVGG模型的基本架构:将20多层3x3卷积堆起来,分成5个stage,每个stage的第一层是stride=2的降采样,每个卷积层用ReLU作为激活函数。
再用一句话介绍RepVGG模型的详细结构:RepVGG-A的5个stage分别有[1, 2, 4, 14, 1]层,RepVGG-B的5个stage分别有[1, 4, 6, 16, 1]层,宽度是[64, 128, 256, 512]的若干倍。这里的倍数是随意指定的诸如1.5,2.5这样的“工整”的数字,没有经过细调。[3]
推理阶段的重参数化
定义M1为输入,M2为输出。W1表示1x1卷积,W3表示3x3卷积,μ、σ、γ、β分别为对应卷积后跟着的BN层的均值、方差、learned scaling factor和偏置,其中0表示identity分支的BN层。
则当M1和M2的shape相同时有如下关系,若其通道数不同则没有identity分支(只有式子的前2项):
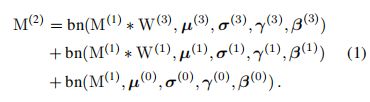
对于M做BN操作,有如下表示,即 (输入M-均值)/方差 * 学习因子 + 偏置:
![]()
将式2右边去括号有(吸BN操作,将BN层和其上的卷积层的参数合并在一起):
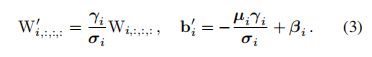
即对输入M经过卷积W+BN操作可表示为式4右边的结果,也就是将Conv+BN转换为带偏置的Conv:
![]()
将identity分支看成是以单位矩阵作为kernel的1x1卷积时,identity分支也可适用于该操作。
经过上面的转换操作后,式1可以得到1个3x3kernel,2个1x1kernel和3个bias。将3个bias相加得到最终的bias;将2个1x1卷积0填充为3x3卷积,然后将3个3x3卷积相加得到最终的3x3卷积(要求1x1卷积和3x3卷积的stride相同,且1x1卷积的padding比3x3的小1)。
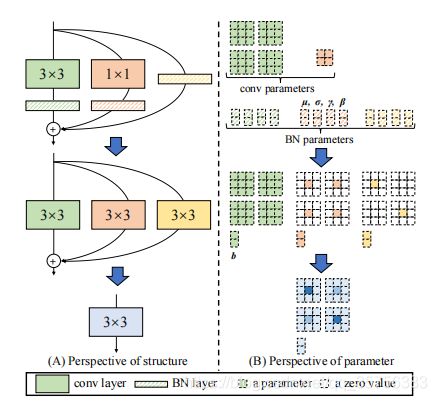
上图是当输入和输出通道数都为2时的一个示例,左边显示了结构的变化,由3分支结构可变为一个3x3卷积;右边显示了参数的变化,其中卷积参数应为4个1x1粉色块,应分开,而不是1个2x2块。
结构规范
共5个stage,ab表示1.5、2.5这样的一个倍率,64a表示通道数。只有卷积,不包含池化结构,每个stage的第一层stride=2:

对于每个stage中layers数量的确定,遵循下述几个原则:
- stage1图像分辨率大,计算量大,因此只用1layer;
- stage5通道数大,计算量大,因此也只用1layer;
- 仿照resnet,在倒数第2个stage使用大量layers。
作者共设计了AB两种层数,浅层网络A用来跟轻中量级网络竞争,较深层网络B用来跟其他高性能网络竞争。
对于每个stage的通道数的设定,作者参照了经典的[64,128,256,512],在前4个stage设定参数a,最后一个stage设定参数b,有b>a.
4 实验结果
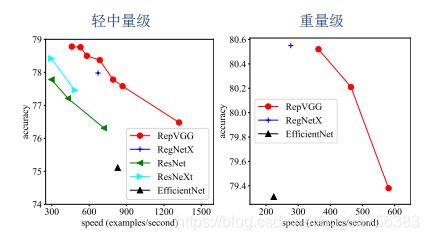
ImageNet图像分类
使用1.28M张图片训练,50K验证。更改RepVGG中的ab来生成一系列模型与其他网络结构进行对比:
EffificientNet-B0/B3和RegNet-3.2GF/12GF分别表示其中量级网络和重量级网络,g2/4表示使用了interleave groupwise,speed为推理时每秒处理的图片张数,训练120epoch结果:
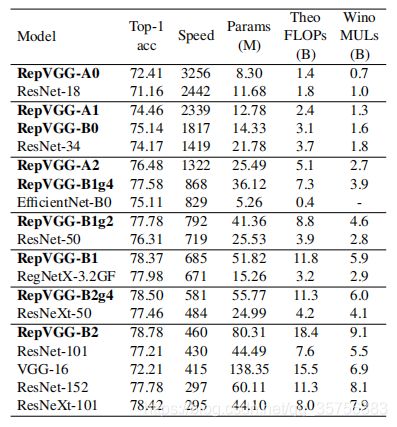
B1/B1g2/B1g4的对比说明interleave groupwise提升了速度,降低了精度。
训练200epoch结果,最高超过了80%的准确率:
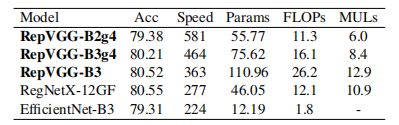
结构重参数化的重要性
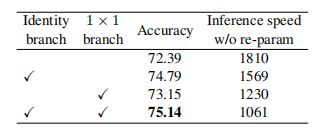
RepVGG-B0,epoch=120,推理速度为转换前计算。
训练阶段使用额外分支与否的对比,多分支精度提升但速度下降:
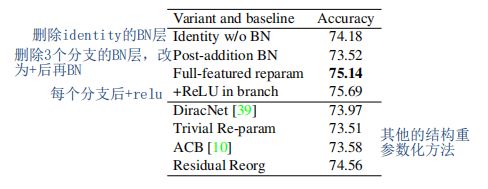
一些消融实验:
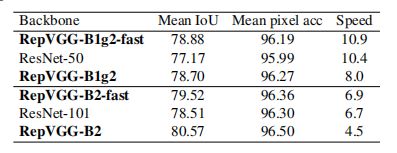
语义分割
使用在ImageNet上预训练的RepVGG在Cityscapes数据集上实验,使用pspnet作为框架
相关文献
[1] Lechao Xiao, Yasaman Bahri, Jascha Sohl-Dickstein, Samuel Schoenholz, and Jeffrey Pennington. Dynamical isometry and a mean fifield theory of cnns: How to train 10,000-layer vanilla convolutional neural networks. In International Conference on Machine Learning, pages 5393– 5402, 2018. 3
[2] Sergey Zagoruyko and Nikos Komodakis. Diracnets: Training very deep neural networks without skip-connections. arXiv preprint arXiv:1706.00388, 2017. 3, 7, 8
[3] RepVGG:极简架构,SOTA性能,让VGG式模型再次伟大(CVPR-2021)
[4] 让Vgg再次伟大:RepVGG论文笔记