生成式对抗网络的原理和实现方法
简介
- gan全称:generative adversarial network
- 发明时间:2014年,Ian Goodfellow和Yoshua Bengio的实验室中相关人员。
- gan的作用:训练出一个“造假机器人”,造出来的东西跟真的几乎类似。
- gan的实现原理:如何训练“造假机器人”?——两个网络,一个生成器网络 G G G和一个鉴别器网络 D D D,两者互相竞争来提升自己。生成器就是“造假机器人”,把造出来的东西丢到鉴别器网络,鉴别器网络要鉴别这东西到底来是真实数据还是造假数据。训练刚开始,生成器生成的东西几乎是四不像,鉴别器鉴别的能力也几乎是瞎猜,但训练正常进行下去,生成器生成的图像能力和鉴别器鉴别的能力都会上升。虽然从Loss上看,它们一直在波动并难以降低,但它们的能力有时候已经超过了人。(此案例中,生成器Loss和鉴别器Loss有点互斥的感觉,一个低,那么另一个就必然会高,两者Loss曲线似乎永远难以同时处于低值。)
使用MNIST手写数据集介绍gan的全过程
加载环境并下载MNIST数据集
%matplotlib inline
import numpy as np
import torch
import matplotlib.pyplot as plt
from torchvision import datasets
import torchvision.transforms as transforms
num_workers = 0
batch_size = 64
transform = transforms.ToTensor()
train_data = datasets.MNIST(root='data', train=True,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,
num_workers=num_workers)
可视化数据
dataiter = iter(train_loader)
images, labels = dataiter.next()
images = images.numpy()
img = np.squeeze(images[0])
fig = plt.figure(figsize = (3,3))
ax = fig.add_subplot(111)
ax.imshow(img, cmap='gray')

定义gan模型
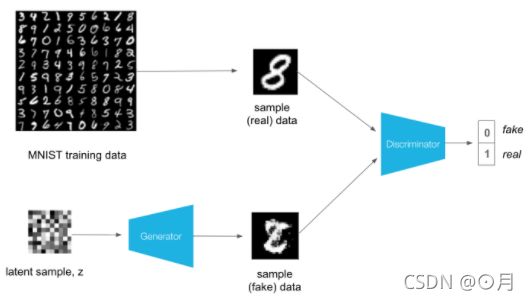
gan由两个网络组成:一个鉴别器网络、一个生成器网络。网络结构图如下:

此案例中,生成器和鉴别器都是用全连接层来搭建:
- 生成器输入的是一个28x28的随机矩阵,取值在(-1,1),输出是一个一维向量,有784个值,并且取值也在(-1,1)之间,因为最后一个全连接层用的tanh激励函数,输出值会控制在(-1,1)之间。当然生成器训练好后,把这个784的向量拉成28x28也就是一张伪造的手写图了。
- 鉴定器输入的也是一个28x28的图像,可能是生成器捏造出的图像,也可能是真实MNIST图像,输出是一个浮点数。当鉴定器训练好后,这个float点数大于0,则表示鉴定器认为输入的图像是真实的MNIST图像,小于0,则表示鉴定器认为输入的图像是捏造的图像。
鉴别器的网络结构代码
我们希望鉴别器输出0~1来表示输入的图像到底是真实图像,还是捏造的图像。
不过:后续我们会为此gan模型选择 BCEWithLogitsLoss 损失函数,它是sigmoid激励函数和BCEloss的结合体,所以我们的鉴别器网络输出,这里先不需要加sigmoid。
import torch.nn as nn
import torch.nn.functional as F
class Discriminator(nn.Module):
def __init__(self, input_size, hidden_dim, output_size):
super(Discriminator, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_dim*4)
self.fc2 = nn.Linear(hidden_dim*4, hidden_dim*2)
self.fc3 = nn.Linear(hidden_dim*2, hidden_dim)
self.fc4 = nn.Linear(hidden_dim, output_size)
self.dropout = nn.Dropout(0.3)
def forward(self, x):
x = x.view(-1, 28*28)
x = F.leaky_relu(self.fc1(x), 0.2) # (input, negative_slope=0.2)
x = self.dropout(x)
x = F.leaky_relu(self.fc2(x), 0.2)
x = self.dropout(x)
x = F.leaky_relu(self.fc3(x), 0.2)
x = self.dropout(x)
out = self.fc4(x)
return out
生成器的网络结构代码
class Generator(nn.Module):
def __init__(self, input_size, hidden_dim, output_size):
super(Generator, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim*2)
self.fc3 = nn.Linear(hidden_dim*2, hidden_dim*4)
self.fc4 = nn.Linear(hidden_dim*4, output_size)
self.dropout = nn.Dropout(0.3)
def forward(self, x):
x = F.leaky_relu(self.fc1(x), 0.2) # (input, negative_slope=0.2)
x = self.dropout(x)
x = F.leaky_relu(self.fc2(x), 0.2)
x = self.dropout(x)
x = F.leaky_relu(self.fc3(x), 0.2)
x = self.dropout(x)
out = F.tanh(self.fc4(x))
return out
【核心】鉴别器和生成器如何训练?
它们两个的训练其实很简单,又很机智。两个网络是分开训练的,但是需要同时训练,因为鉴别器的损失计算需要用到生成器生成的图像,而生成器的损失计算也需要鉴别器预测的结果。
鉴别器的训练过程:
- 抽取1张real图像,鉴定器去判定是真图还是假图,计算损失d_real_loss。
- 给生成器输入一个随机的28x28的矩阵,生成器网络生成一个新28x28图像,把这个fake图像输入鉴定器,它去判定是真图还是假图,计算损失d_fake_loss。
- 鉴别器本次训练的总损失:d_loss = d_real_loss + d_fake_loss
- 更新一次鉴别器网络参数。
生成器的训练过程:
- (紧接着上述第4步)生成器再次生成1张fake图,然后把这个fake图输入鉴别器网络,根据鉴别器的结果来计算出生成器本次的损失。
- 更新一次生成器网络参数。
损失函数
# Calculate losses
# 以下两个函数,唯一区别是real_loss使用了【标签平滑】技术。
def real_loss(D_out, smooth=False):
batch_size = D_out.size(0)
# label smoothing
if smooth:
# smooth, real labels = 0.9
labels = torch.ones(batch_size)*0.9 # 采用【标签平滑】训练技巧(因为真实图像太容易学会,导致过早停止学习)
else:
labels = torch.ones(batch_size) # real labels = 1
# numerically stable loss
criterion = nn.BCEWithLogitsLoss()
# calculate loss
loss = criterion(D_out.squeeze(), labels)
return loss
def fake_loss(D_out):
batch_size = D_out.size(0)
labels = torch.zeros(batch_size) # fake labels = 0
criterion = nn.BCEWithLogitsLoss()
# calculate loss
loss = criterion(D_out.squeeze(), labels)
return loss
训练代码
import torch.optim as optim
lr = 0.002
d_optimizer = optim.Adam(D.parameters(), lr)
g_optimizer = optim.Adam(G.parameters(), lr)
# Discriminator hyperparams
# Size of input image to discriminator (28*28)
input_size = 784
# Size of discriminator output (real or fake)
d_output_size = 1
# Size of last hidden layer in the discriminator
d_hidden_size = 32
# Generator hyperparams
# Size of latent vector to give to generator
z_size = 100
# Size of discriminator output (generated image)
g_output_size = 784
# Size of first hidden layer in the generator
g_hidden_size = 32
import pickle as pkl
num_epochs = 30
# keep track of loss and generated, "fake" samples
samples = [] #保存每个epoch后,生成器生成的样本效果图。
losses = [] #保存每个epoch的loss值。
# Get some fixed data for sampling. These are images that are held
# constant throughout training, and allow us to inspect the model's performance
sample_size=16
fixed_z = np.random.uniform(-1, 1, size=(sample_size, z_size))
fixed_z = torch.from_numpy(fixed_z).float()
# train the network
D.train()
G.train()
for epoch in range(num_epochs):
for batch_i, (real_images, _) in enumerate(train_loader):
batch_size = real_images.size(0)
## Important rescaling step ##
real_images = real_images*2 - 1 # rescale input images from [0,1) to [-1, 1)
# ============================================
# TRAIN THE DISCRIMINATOR
# ============================================
d_optimizer.zero_grad()
# 1. Train with real images
# Compute the discriminator losses on real images
# smooth the real labels
D_real = D(real_images)
d_real_loss = real_loss(D_real, smooth=True)
# 2. Train with fake images
# Generate fake images
z = np.random.uniform(-1, 1, size=(batch_size, z_size))
z = torch.from_numpy(z).float()
fake_images = G(z)
# Compute the discriminator losses on fake images
D_fake = D(fake_images)
d_fake_loss = fake_loss(D_fake)
# add up loss and perform backprop
d_loss = d_real_loss + d_fake_loss
d_loss.backward()
d_optimizer.step()
# =========================================
# TRAIN THE GENERATOR
# =========================================
g_optimizer.zero_grad()
# 1. Train with fake images and flipped labels
# Generate fake images
z = np.random.uniform(-1, 1, size=(batch_size, z_size))
z = torch.from_numpy(z).float()
fake_images = G(z)
# Compute the discriminator losses on fake images
# using flipped labels!
D_fake = D(fake_images)
g_loss = real_loss(D_fake) # use real loss to flip labels
# perform backprop
g_loss.backward()
g_optimizer.step()
print('Epoch [{:5d}/{:5d}] | d_loss: {:6.4f} | g_loss: {:6.4f}'.format(
epoch+1, num_epochs, d_loss.item(), g_loss.item()))
## AFTER EACH EPOCH##
# append discriminator loss and generator loss
losses.append((d_loss.item(), g_loss.item()))
#每训练一个epoch,测试生成器生成图像的情况,并保存生成的结果
# generate and save sample, fake images
G.eval() # eval mode for generating samples
samples_z = G(fixed_z)
samples.append(samples_z)
G.train() # back to train mode
# Save training generator samples
with open('train_samples.pkl', 'wb') as f: #将生成器每个epoch的生成效果图保存到pkl文件中。
pkl.dump(samples, f)
30个epoch,loss图如下:
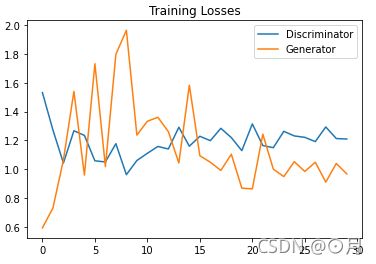
从上图可看出,loss很难下降,而且波动剧烈。但是实际上,生成器loss和鉴别器loss是一种相反关系,即鉴别器牛逼,那么生成器就很菜,它们loss会一个高一个低,这种情况,生成器就更大幅度的梯度下降,不要多久效果就超过鉴别器,导致它们的loss变反,后面鉴别器又会加速训练。。。
训练100个epoch图也差不多,两者从loss上并不会收敛:(忽略起始loss)

可视化生成器每个epoch后生成的效果
# Load samples from generator, taken while training
with open('train_samples.pkl', 'rb') as f:
samples = pkl.load(f)
rows = 30
cols = 16 # 每行显示几个生成图(注意:当初一个epoch只生成了16个样本,这里最大16)
fig, axes = plt.subplots(figsize=(14,28), nrows=rows, ncols=cols, sharex=True, sharey=True)
for sample, ax_row in zip(samples[::int(len(samples)/rows)], axes):
for img, ax in zip(sample[::int(len(sample)/cols)], ax_row):
img = img.detach()
ax.imshow(img.reshape((28,28)), cmap='Greys_r')
ax.xaxis.set_visible(False)
ax.yaxis.set_visible(False)
要知道,输入生成器的矩阵永远是随机的28x28的矩阵,长得像这样:

从下图可看出,经过一个epoch后,生成器已经知道要在图像中间形成一堆‘白色点’,在图像周围要‘变黑’。
再经过一些epoch后,开始学会捏造一些数字!

测试生成器效果
# helper function for viewing a list of passed in sample images
def view_samples(epoch, samples):
fig, axes = plt.subplots(figsize=(7,7), nrows=4, ncols=4, sharey=True, sharex=True)
for ax, img in zip(axes.flatten(), samples[epoch]):
img = img.detach()
ax.xaxis.set_visible(False)
ax.yaxis.set_visible(False)
im = ax.imshow(img.reshape((28,28)), cmap='Greys_r')
# randomly generated, new latent vectors
sample_size=16
rand_z = np.random.uniform(-1, 1, size=(sample_size, z_size))
rand_z = torch.from_numpy(rand_z).float()
G.eval() # eval mode
# generated samples
rand_images = G(rand_z)
# 0 indicates the first set of samples in the passed in list
# and we only have one batch of samples, here
view_samples(0, [rand_images])
