人体姿态估计HRNet网络模型搭建代码详解
HRNet-v1模型详解
源码参考:https://github.com/HRNet/HRNet-Human-Pose-Estimation
内容参考:点击跳转
仅作为个人的学习笔记,欢迎交流学习。
整体结构如下图
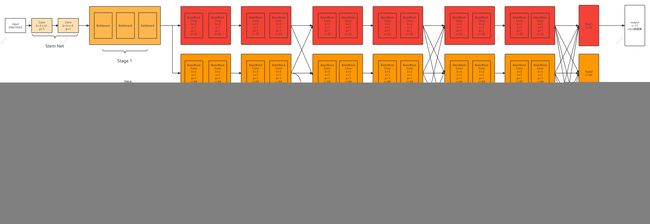 整体代码详解:
整体代码详解:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import logging
import torch
import torch.nn as nn
BN_MOMENTUM = 0.1
logger = logging.getLogger(__name__)
# 定义3x3卷积操作
def conv3x3(in_planes, out_planes, stride=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,padding=1, bias=False)
# 3x3的残差块
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1,
bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion,
momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
# 高分辨率模块
class HighResolutionModule(nn.Module):
def __init__(self, num_branches, blocks, num_blocks, num_inchannels,
num_channels, fuse_method, multi_scale_output=True):
super(HighResolutionModule, self).__init__()
"""
:param num_branches: 当前 stage 分支平行子网络的数目
:param blocks: BasicBlock或者BasicBlock
:param num_blocks: BasicBlock或者BasicBlock的数目
:param num_inchannels: 输入通道数
当stage = 2时: num_inchannels = [32, 64]
当stage = 3时: num_inchannels = [32, 64, 128]
当stage = 4时: num_inchannels = [32, 64, 128, 256]
:param num_channels: 输出通道数目
当stage = 2时: num_inchannels = [32, 64]
当stage = 3时: num_inchannels = [32, 64, 128]
当stage = 4时: num_inchannels = [32, 64, 128, 256]
:param fuse_method: 默认SUM
:param multi_scale_output:
当stage = 2时: multi_scale_output=Ture
当stage = 3时: multi_scale_output=Ture
当stage = 4时: multi_scale_output=False
"""
self._check_branches(
num_branches, blocks, num_blocks, num_inchannels, num_channels)
self.num_inchannels = num_inchannels
self.fuse_method = fuse_method
self.num_branches = num_branches
self.multi_scale_output = multi_scale_output
# 为每个分支构建分支网络
# 当stage=2,3,4时,num_branches分别为:2,3,4,表示每个stage平行网络的数目
# 当stage=2,3,4时,num_blocks分别为:[4,4], [4,4,4], [4,4,4,4],
self.branches = self._make_branches(
num_branches, blocks, num_blocks, num_channels)
# 创建一个多尺度融合层,当stage=2,3,4时
# len(self.fuse_layers)分别为2,3,4. 其与num_branches在每个stage的数目是一致的
self.fuse_layers = self._make_fuse_layers()
self.relu = nn.ReLU(True)
# 检查num_branches num_blocks num_inchannels num_channels 长度是否一致
def _check_branches(self, num_branches, blocks, num_blocks,
num_inchannels, num_channels):
if num_branches != len(num_blocks):
error_msg = 'NUM_BRANCHES({}) <> NUM_BLOCKS({})'.format(
num_branches, len(num_blocks))
logger.error(error_msg)
raise ValueError(error_msg)
if num_branches != len(num_channels):
error_msg = 'NUM_BRANCHES({}) <> NUM_CHANNELS({})'.format(
num_branches, len(num_channels))
logger.error(error_msg)
raise ValueError(error_msg)
if num_branches != len(num_inchannels):
error_msg = 'NUM_BRANCHES({}) <> NUM_INCHANNELS({})'.format(
num_branches, len(num_inchannels))
logger.error(error_msg)
raise ValueError(error_msg)
# 搭建分支,单个分支内部分辨率相等
# for i in range(num_branches): 2 3 4
# self._make_one_branch(i, block, num_blocks, num_channels)
def _make_one_branch(self, branch_index, block, num_blocks, num_channels,
stride=1):
downsample = None
# 如果stride不为1, 或者输入通道数目与输出通道数目不一致
# 则通过卷积,对其通道数进行改变
if stride != 1 or \
self.num_inchannels[branch_index] != num_channels[branch_index] * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(
self.num_inchannels[branch_index],
num_channels[branch_index] * block.expansion,
kernel_size=1, stride=stride, bias=False
),
nn.BatchNorm2d(
num_channels[branch_index] * block.expansion,
momentum=BN_MOMENTUM
),
)
layers = []
# 为当前分支branch_index创建一个block,该处进行下采样
layers.append(
block(
self.num_inchannels[branch_index],
num_channels[branch_index],
stride,
downsample
)
)
# 把输出通道数,赋值给输入通道数,为下一stage作准备
self.num_inchannels[branch_index] = \
num_channels[branch_index] * block.expansion
# 为[1, num_blocks[branch_index]]分支创建block
for i in range(1, num_blocks[branch_index]):
layers.append(
block(
self.num_inchannels[branch_index],
num_channels[branch_index]
)
)
return nn.Sequential(*layers)
# 循环调用 make_one_branch创建多个分支
def _make_branches(self, num_branches, block, num_blocks, num_channels):
branches = []
# 循环为每个分支构建网络
# 当stage=2,3,4时,num_branches分别为:2,3,4,表示每个stage平行网络的数目
# stage=2时, self._make_one_branch(0, BASICBLOCK, [4,4], [32,64]) ,self._make_one_branch(1, BASICBLOCK, [4,4], [32,64])
# 当stage=2,3,4时,num_blocks分别为:[4,4], [4,4,4], [4,4,4,4],
for i in range(num_branches):
branches.append(
self._make_one_branch(i, block, num_blocks, num_channels)
)
return nn.ModuleList(branches)
# 进行特征融合
def _make_fuse_layers(self):
# 如果只有一个分支,则不需要融合
if self.num_branches == 1:
return None
# 平行子网络(分支)数目
num_branches = self.num_branches
# 输入通道数
num_inchannels = self.num_inchannels
fuse_layers = []
# 如果self.multi_scale_output为True,意味着只需要输出最高分辨率特征图,
# 即只需要将其他尺寸特征图的特征融合入最高分辨率特征图中
for i in range(num_branches if self.multi_scale_output else 1):
fuse_layer = []
for j in range(num_branches):
# 每个分支网络的输出有多中情况
# 1.当前分支信息传递到上一分支(沿论文图示scale方向)的下一层(沿论文图示depth方向),进行上采样,分辨率加倍
if j > i:
fuse_layer.append(
nn.Sequential(
nn.Conv2d(
num_inchannels[j],
num_inchannels[i],
1, 1, 0, bias=False
),
nn.BatchNorm2d(num_inchannels[i]),
# 使用最近邻插值上采样(j-i)次
nn.Upsample(scale_factor=2**(j-i), mode='nearest')
)
)
# 2.当前分支信息传递到当前分支(论文图示沿scale方向)的下一层(沿论文图示depth方向),不做任何操作,分辨率相同
elif j == i:
fuse_layer.append(None)
# 3.当前分支信息传递到下前分支(论文图示沿scale方向)的下一层(沿论文图示depth方向),分辨率减半,分辨率减半
else:
conv3x3s = []
for k in range(i-j):
# 判断下采样几次,最后一次操作不使用Relu
if k == i - j - 1:
num_outchannels_conv3x3 = num_inchannels[i]
conv3x3s.append(
nn.Sequential(
nn.Conv2d(
num_inchannels[j],
num_outchannels_conv3x3,
3, 2, 1, bias=False
),
nn.BatchNorm2d(num_outchannels_conv3x3)
)
)
else:
num_outchannels_conv3x3 = num_inchannels[j]
conv3x3s.append(
nn.Sequential(
nn.Conv2d(
num_inchannels[j],
num_outchannels_conv3x3,
3, 2, 1, bias=False
),
nn.BatchNorm2d(num_outchannels_conv3x3),
nn.ReLU(True)
)
)
fuse_layer.append(nn.Sequential(*conv3x3s))
fuse_layers.append(nn.ModuleList(fuse_layer))
return nn.ModuleList(fuse_layers)
def get_num_inchannels(self):
return self.num_inchannels
def forward(self, x):
# 当stage=2,3,4时,num_branches分别为:2,3,4,表示每个stage平行网络的数目
# 在stage1中self.num_branches为2,所以不符合if条件
# 如果只有1个分支,就直接将单个分支特征图作为输入进入self.branches里设定的layers
if self.num_branches == 1:
return [self.branches[0](x[0])]
# 当前有多少个网络分支,则有多少个x当作输入
# 当stage=2:x=[b,32,64,48],[b,64,32,24]
# -->x=[b,32,64,48],[b,64,32,24]
# 当stage=3:x=[b,32,64,48],[b,64,32,24],[b,128,16,12]
# -->x=[b,32,64,48],[b,64,32,24],[b,128,16,12]
# 当stage=4:x=[b,32,64,48],[b,64,32,24],[b,128,16,12],[b,256,8,6]
# -->[b,32,64,48],[b,64,32,24],[b,128,16,12],[b,256,8,6]
# 简单的说,该处就是对每个分支进行了BasicBlock或者Bottleneck操作
# 如果有多个分支,self.branches会是一个有两个元素(这里的元素是预设的layers)的列表
# 把对应的x[i]输入self.branches[i]即可
# self.branches = self._make_branches(2, BASICBLOCK, [4,4], [32,64])
for i in range(self.num_branches):
x[i] = self.branches[i](x[i])
x_fuse = []
# 现在已知self.fuse_layers里面有num_branches(上面的i)个元素fuse_layer
# 接下来就把不同的x分支输入到相应的self.fuse_layers元素中分别进行上采样和下采样
# 然后进行融合(相加实现融合)
for i in range(len(self.fuse_layers)):
# 对每个分支进行融合(信息交流)
# 循环融合多个分支的输出信息,当作输入,进行下一轮融合
y = x[0] if i == 0 else self.fuse_layers[i][0](x[0])
for j in range(1, self.num_branches):
if i == j:
y = y + x[j]
else:
y = y + self.fuse_layers[i][j](x[j])
x_fuse.append(self.relu(y))
return x_fuse
blocks_dict = {
'BASIC': BasicBlock,
'BOTTLENECK': Bottleneck
}
class PoseHighResolutionNet(nn.Module):
def __init__(self, cfg, **kwargs):
self.inplanes = 64 # channel = 64
extra = cfg['MODEL']['EXTRA']
super(PoseHighResolutionNet, self).__init__()
# stem模块: 输入图片经过两个3x3的卷积操作,分辨率变为原来的1/4
# stem net,进行一系列的卷积操作,获得最初始的特征图N11
# resolution to 1/2 3 --> 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1,bias=False)
self.bn1 = nn.BatchNorm2d(64, momentum=BN_MOMENTUM)
# resolution to 1/4 64 --> 64
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1,bias=False)
self.bn2 = nn.BatchNorm2d(64, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
# stage1
self.layer1 = self._make_layer(Bottleneck, 64, 4)
# 获取stage2的相关配置信息
self.stage2_cfg = extra['STAGE2']
# num_channels=[32,64],num_channels表示输出通道,最后的64是新建平行分支N2的输出通道数
num_channels = self.stage2_cfg['NUM_CHANNELS']
# block为basic,传入的是一个类BasicBlock,
block = blocks_dict[self.stage2_cfg['BLOCK']]
# block.expansion默认为1,num_channels表示输出通道[32,64]
num_channels = [
num_channels[i] * block.expansion for i in range(len(num_channels))
]
# 这里会生成新的平行分N2支网络,即N11-->N21,N22这个过程
# 同时会对输入的特征图x进行通道变换(如果输入输出通道数不一致),由stage1的256通道变为[32, 64]
self.transition1 = self._make_transition_layer([256], num_channels)
# 对平行子网络进行加工,让其输出的y,可以当作下一个stage的输入x,
# 这里的pre_stage_channels为当前stage的输出通道数,也就是下一个stage的输入通道数
# 同时平行子网络信息交换模块,也包含再其中
self.stage2, pre_stage_channels = self._make_stage(
self.stage2_cfg, num_channels)
self.stage3_cfg = extra['STAGE3']
# num_channels=[32,64,128],num_channels表示输出通道,最后的128是新建平行分支N3的输出通道数
num_channels = self.stage3_cfg['NUM_CHANNELS']
block = blocks_dict[self.stage3_cfg['BLOCK']] # BasicBlock
# block.expansion默认为1,num_channels表示输出通道[32,64,128]
num_channels = [
num_channels[i] * block.expansion for i in range(len(num_channels))
]
self.transition2 = self._make_transition_layer(
pre_stage_channels, num_channels)
self.stage3, pre_stage_channels = self._make_stage(
self.stage3_cfg, num_channels)
self.stage4_cfg = extra['STAGE4']
# num_channels=[32,64,128,256],num_channels表示输出通道,最后的256是新建平行分支N4的输出通道数
num_channels = self.stage4_cfg['NUM_CHANNELS']
block = blocks_dict[self.stage4_cfg['BLOCK']]
# block.expansion默认为1,num_channels表示输出通道[32,64,128,256]
num_channels = [
num_channels[i] * block.expansion for i in range(len(num_channels))
]
self.transition3 = self._make_transition_layer(
pre_stage_channels, num_channels)
self.stage4, pre_stage_channels = self._make_stage(
self.stage4_cfg, num_channels, multi_scale_output=False)
# 对最终的结果进行混合之后进行一次卷积,预测关键点的heatmap
self.final_layer = nn.Conv2d(
in_channels=pre_stage_channels[0], # 取最后结果的第一层
out_channels=cfg['MODEL']['NUM_JOINTS'], # 17
kernel_size=extra['FINAL_CONV_KERNEL'],
stride=1,
padding=1 if extra['FINAL_CONV_KERNEL'] == 3 else 0
)
# 预测人体关键点的heatmap
self.pretrained_layers = extra['PRETRAINED_LAYERS']
# 不同层数分支进行创建
def _make_transition_layer(self, num_channels_pre_layer, num_channels_cur_layer):
"""
:param num_channels_pre_layer: 上一个stage平行网络的输出通道数目,为一个list,
stage=2时, num_channels_pre_layer=[256]
stage=3时, num_channels_pre_layer=[32,64]
stage=4时, num_channels_pre_layer=[32,64,128]
:param num_channels_cur_layer:
stage=2时, num_channels_cur_layer = [32,64]
stage=3时, num_channels_cur_layer = [32,64,128]
stage=4时, num_channels_cur_layer = [32,64,128,256]
"""
num_branches_cur = len(num_channels_cur_layer)
num_branches_pre = len(num_channels_pre_layer)
transition_layers = []
# 对stage的每个分支进行处理
for i in range(num_branches_cur):
# 如果不为最后一个分支
if i < num_branches_pre:
# 如果当前层的输入通道和输出通道数不相等,则通过卷积对通道数进行变换
if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
transition_layers.append(
nn.Sequential(
nn.Conv2d(
num_channels_pre_layer[i],
num_channels_cur_layer[i],
3, 1, 1, bias=False
),
nn.BatchNorm2d(num_channels_cur_layer[i]),
nn.ReLU(inplace=True)
)
)
else:
# 如果当前层的输入通道和输出通道数相等,则什么都不做
transition_layers.append(None)
else:
# 如果为最后一个分支,则再新建一个分支(该分支分辨率会减少一半)
conv3x3s = []
for j in range(i+1-num_branches_pre):
inchannels = num_channels_pre_layer[-1]
outchannels = num_channels_cur_layer[i] \
if j == i-num_branches_pre else inchannels
conv3x3s.append(
nn.Sequential(
nn.Conv2d(
inchannels, outchannels, 3, 2, 1, bias=False
),
nn.BatchNorm2d(outchannels),
nn.ReLU(inplace=True)
)
)
transition_layers.append(nn.Sequential(*conv3x3s))
return nn.ModuleList(transition_layers)
# stage1 self._make_layer(Bottleneck, 64, 4) , stride=1 block.expansion = 4
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion: # stage1时,成立,进入生成分支
downsample = nn.Sequential(
nn.Conv2d(
self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False
),
nn.BatchNorm2d(planes * block.expansion, momentum=BN_MOMENTUM),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
# 同级stage设计,通过 HighResolutionModule
def _make_stage(self, layer_config, num_inchannels,
multi_scale_output=True):
"""
当stage=2时: num_inchannels=[32,64] multi_scale_output=Ture
当stage=3时: num_inchannels=[32,64,128] multi_scale_output=Ture
当stage=4时: num_inchannels=[32,64,128,256] multi_scale_output=False
"""
# 当stage=2,3,4时,num_modules分别为:1,4,3
# 表示HighResolutionModule(平行之网络交换信息模块)模块的数目
num_modules = layer_config['NUM_MODULES']
# 当stage=2,3,4时,num_branches分别为:2,3,4,表示每个stage平行网络的数目
num_branches = layer_config['NUM_BRANCHES']
# 当stage=2,3,4时,num_blocks分别为:[4,4], [4,4,4], [4,4,4,4],
# 表示每个stage blocks(BasicBlock或者BasicBlock)的数目
num_blocks = layer_config['NUM_BLOCKS']
# 当stage=2,3,4时,num_channels分别为:[32,64],[32,64,128],[32,64,128,256]
# 在对应stage, 对应每个平行子网络的输出通道数
num_channels = layer_config['NUM_CHANNELS']
# 当stage=2,3,4时,分别为:BasicBlock,BasicBlock,BasicBlock
block = blocks_dict[layer_config['BLOCK']]
# 当stage=2,3,4时,都为:SUM,表示特征融合的方式
fuse_method = layer_config['FUSE_METHOD']
modules = []
# 根据num_modules的数目创建HighResolutionModule
for i in range(num_modules):
# multi_scale_output 只被用再最后一个HighResolutionModule
if not multi_scale_output and i == num_modules - 1:
reset_multi_scale_output = False
else:
reset_multi_scale_output = True
# 根据参数,添加HighResolutionModule到
modules.append(
HighResolutionModule(
num_branches, # 当前stage平行分支的数目
block, # BasicBlock,BasicBlock
num_blocks, # BasicBlock或者BasicBlock的数目
num_inchannels, # 输入通道数目
num_channels, # 输出通道数
fuse_method, # 通特征融合的方式
reset_multi_scale_output # 是否使用多尺度方式输出
)
)
# 获得最后一个HighResolutionModule的输出通道数
num_inchannels = modules[-1].get_num_inchannels()
return nn.Sequential(*modules), num_inchannels
# 传播函数 # 经过一系列的卷积, 获得初步特征图,总体过程为x[b,3,128,96] --> x[b,256,32,24] ,此处按照实际输入128x96计算
def forward(self, x):
# 第一部分
# stem模块:经过2个3x3卷积输入到HRNet中,分辨率降为1/4
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
# stage1 stem net --> stage1
x = self.layer1(x)
# 对应论文中的stage2,在配置文件中self.stage2_cfg['NUM_BRANCHES']为2
# 其中包含了创建分支的过程,即 N11-->N21,N22 这个过程
# N22的分辨率为N21的二分之一,总体过程为:
# x[b,256,64,48] ---> y[b, 32, 64, 48] 因为通道数不一致,通过卷积进行通道数变换
# y[b, 64, 32, 24] 通过新建平行分支生成
x_list = []
for i in range(self.stage2_cfg['NUM_BRANCHES']): # 2, 3, 4
if self.transition1[i] is not None:
x_list.append(self.transition1[i](x))
else:
x_list.append(x)
# 总体过程如下(经过一些卷积操作,但是特征图的分辨率和通道数都没有改变):
# x[b, 32, 64, 48] ---> y[b, 32, 64, 48]
# x[b, 64, 32, 24] ---> y[b, 64, 32, 24]
y_list = self.stage2(x_list)
# 对应论文中的stage3
# 其中包含了创建分支的过程,即 N22-->N32,N33 这个过程
# N33的分辨率为N32的二分之一,
# y[b, 32, 64, 48] ---> y[b, 32, 64, 48] 因为通道数一致,没有做任何操作
# y[b, 64, 32, 24] ---> y[b, 64, 32, 24] 因为通道数一致,没有做任何操作
# y[b, 128, 16, 12] 通过新建平行分支生成
x_list = []
for i in range(self.stage3_cfg['NUM_BRANCHES']):
if self.transition2[i] is not None:
x_list.append(self.transition2[i](y_list[-1]))
else:
x_list.append(y_list[i])
# 总体过程如下(经过一些卷积操作,但是特征图的分辨率和通道数都没有改变):
# x[b, 32, 64, 48] ---> x[b, 32, 64, 48]
# x[b, 32, 32, 24] ---> x[b, 32, 32, 24]
# x[b, 64, 16, 12] ---> x[b, 64, 16, 12]
y_list = self.stage3(x_list)
# 对应论文中的stage4
# 其中包含了创建分支的过程,即 N33-->N43,N44 这个过程
# N44的分辨率为N43的二分之一
# y[b, 32, 64, 48] ---> x[b, 32, 64, 48] 因为通道数一致,没有做任何操作
# y[b, 64, 32, 24] ---> x[b, 64, 32, 24] 因为通道数一致,没有做任何操作
# y[b, 128, 16, 12] ---> x[b, 128, 16, 12] 因为通道数一致,没有做任何操作
# x[b, 256, 8, 6 ] 通过新建平行分支生成
x_list = []
for i in range(self.stage4_cfg['NUM_BRANCHES']):
if self.transition3[i] is not None:
x_list.append(self.transition3[i](y_list[-1]))
else:
x_list.append(y_list[i])
# 进行多尺度特征融合
# x[b, 32, 64, 48] --->y[b, 32, 64, 48]
# x[b, 64, 32, 24] --->
# x[b, 128, 16, 12] --->
# x[b, 256, 8, 6 ] --->
y_list = self.stage4(x_list)
# y[b, 32, 64, 48] --> x[b, 17, 64, 48]
x = self.final_layer(y_list[0])
return x
# 初始化权重
def init_weights(self, pretrained=''):
logger.info('=> init weights from normal distribution')
for m in self.modules():
if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.normal_(m.weight, std=0.001)
for name, _ in m.named_parameters():
if name in ['bias']:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.ConvTranspose2d):
nn.init.normal_(m.weight, std=0.001)
for name, _ in m.named_parameters():
if name in ['bias']:
nn.init.constant_(m.bias, 0)
if os.path.isfile(pretrained):
pretrained_state_dict = torch.load(pretrained)
logger.info('=> loading pretrained model {}'.format(pretrained))
need_init_state_dict = {}
for name, m in pretrained_state_dict.items():
if name.split('.')[0] in self.pretrained_layers \
or self.pretrained_layers[0] is '*':
need_init_state_dict[name] = m
self.load_state_dict(need_init_state_dict, strict=False)
elif pretrained:
logger.error('=> please download pre-trained models first!')
raise ValueError('{} is not exist!'.format(pretrained))
# 构建hrnet网络
def get_pose_net(cfg, is_train, **kwargs):
model = PoseHighResolutionNet(cfg, **kwargs)
if is_train and cfg['MODEL']['INIT_WEIGHTS']:
model.init_weights(cfg['MODEL']['PRETRAINED'])
return model
0. 整体网络结构搭建
# 搭建HRNet模型,传入配置文件,位于 experiments/coco/hrnet/w32_256x192_adam_lr1e-3.yaml
def get_pose_net(cfg, is_train, **kwargs):
model = PoseHighResolutionNet(cfg, **kwargs)
if is_train and cfg.MODEL.INIT_WEIGHTS:
model.init_weights(cfg.MODEL.PRETRAINED)
return model
这里面用的model=PoseHighResolutionNet(cfg, **kwargs)来构建整个模型,所以我们来看PoseHighResolutionNet(cfg, **kwargs)类的forward函数,并且开始每个函数进行分析。
1. stem net结构
在输入之后进行特征提取,用两个3x3的卷积实现,将图片的分辨率变为原来的1/4
class PoseHighResolutionNet(nn.Module):
def __init__(self, cfg, **kwargs):
self.inplanes = 64 # channel = 64
extra = cfg['MODEL']['EXTRA']
super(PoseHighResolutionNet, self).__init__()
# stem模块: 输入图片经过两个3x3的卷积操作,分辨率变为原来的1/4
# stem net,进行一系列的卷积操作,获得最初始的特征图N11
# resolution to 1/2 3 --> 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1,bias=False)
self.bn1 = nn.BatchNorm2d(64, momentum=BN_MOMENTUM)
# resolution to 1/4 64 --> 64
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1,bias=False)
self.bn2 = nn.BatchNorm2d(64, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
# 经过一系列的卷积, 获得初步特征图,总体过程为x[b,3,256,192] --> x[b,256,64,48]
def forward(self, x):
# 第一部分
# stem模块:经过2个3x3卷积输入到HRNet中,分辨率降为1/4
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
模型结构如下:
(conv1): Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
2. stage1结构
图片经过stem net之后,传入到Stage1,使用3个Bottleneck结构完成Stage1的搭建。
class PoseHighResolutionNet(nn.Module):
def __init__(self, cfg, **kwargs):
... (stem net)
# stage1
self.layer1 = self._make_layer(Bottleneck, 64, 4)
def forward(self, x):
... (stem net)
# stage1 stem net --> stage1
x = self.layer1(x)
在self.layer1 = self._make_layer(Bottleneck, 64, 4)中的结构如下:
# self._make_layer(Bottleneck, 64, 4) , stride=1 block.expansion = 4
def _make_layer(self, block, planes, blocks, stride=1):
#这里的downsample会在后面的bottleneck里面用到,用于下面block中调整输入x的通道数,实现残差结构相加
downsample = None
#在layer1中,block传入的是Bottlenect类,block.expansion是block类里的一个变量,定义为4
#layer1的stride为1,planes为64,而self.inplane表示当前特征图通道数,经过初步提特征处理后的特征图通道数为是64,block.expanson=4,达成条件
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(
self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False
),
nn.BatchNorm2d(planes * block.expansion, momentum=BN_MOMENTUM),
)
layers = []
#所以layers里第一层是:bottleneck(64, 64, 1, downsample) (w,h,64)-->(w,h,256)
layers.append(block(self.inplanes, planes, stride, downsample))
#经过第一层后,当前特征图通道数为256
self.inplanes = planes * block.expansion
#这里的blocks为4,即for i in range(1,4)
#所以这里for循环实现了3层bottleneck,目的应该是为了加深层数
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
接下来详细看看stage1的bottleneck结构
#这里只看代码干了啥,不详细解释残差结构的特点啊原理啥的
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1,
bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion,
momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x) #n.Conv2d(64,64, kernel_size=1, bias=False) (w,h,64)-->(w,h,64)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out) #nn.Conv2d(64, 64, kernel_size=3, 1,padding=1, bias=False) (w,h,64)-->(w,h,64)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out) #nn.Conv2d(64, 64 * 4, kernel_size=1,bias=False) (w,h,64)-->(w,h,256)
out = self.bn3(out)
if self.downsample is not None:
#这里的downsample的作用是希望输入原图x与conv3输出的图维度相同,方便两种特征图进行相加,保留更多的信息
#如果x与conv3输出图维度本来就相同,就意味着可以直接相加,那么downsample会为空,自然就不会进行下面操作
residual = self.downsample(x)
#downsample = nn.Sequential(
# nn.Conv2d(64, 64*4,kernel_size=1, stride=1, bias=False),
# nn.BatchNorm2d(64*4, momentum=BN_MOMENTUM),
#
out += residual #残差结构相加嘛
out = self.relu(out) #得到结果
return out
整个stage1的模型如下:
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
3. stage2网络
首先看看forward中的stage2的搭建过程。
# 对应论文中的stage2,在配置文件中self.stage2_cfg['NUM_BRANCHES']为2
# 其中包含了创建分支的过程,即 N11-->N21,N22 这个过程
# N22的分辨率为N21的二分之一,总体过程为:
# x[b,256,64,48] ---> y[b, 32, 64, 48] 因为通道数不一致,通过卷积进行通道数变换
# y[b, 64, 32, 24] 通过新建平行分支生成
x_list = []
for i in range(self.stage2_cfg['NUM_BRANCHES']): # 2, 3, 4
if self.transition1[i] is not None:
x_list.append(self.transition1[i](x))
else:
x_list.append(x)
# 总体过程如下(经过一些卷积操作,但是特征图的分辨率和通道数都没有改变):
# x[b, 32, 32, 24] ---> y[b, 32, 32, 24]
# x[b, 64, 16, 12] ---> y[b, 64, 16, 12]
y_list = self.stage2(x_list)
其相关配置文件其代码如下:
'''''' #
extra['STAGE2']为
STAGE2:
NUM_MODULES: 1
NUM_BRANCHES: 2
BLOCK: BASIC
NUM_BLOCKS:
- 4
- 4
NUM_CHANNELS:
- 32
- 64
FUSE_METHOD: SUM
''''''
# 获取stage2的相关配置信息
self.stage2_cfg = extra['STAGE2']
# num_channels=[32,64],num_channels表示输出通道,最后的64是新建平行分支N2的输出通道数
num_channels = self.stage2_cfg['NUM_CHANNELS']
# block为basic,传入的是一个类BasicBlock,
block = blocks_dict[self.stage2_cfg['BLOCK']]
# block.expansion默认为1,num_channels表示输出通道[32,64]
num_channels = [
num_channels[i] * block.expansion for i in range(len(num_channels))
]
# 这里会生成新的平行分N2支网络,即N11-->N21,N22这个过程
# 同时会对输入的特征图x进行通道变换(如果输入输出通道数不一致),由stage1的256通道变为[32, 64]
self.transition1 = self._make_transition_layer([256], num_channels)
# 对平行子网络进行加工,让其输出的y,可以当作下一个stage的输入x,
# 这里的pre_stage_channels为当前stage的输出通道数,也就是下一个stage的输入通道数
# 同时平行子网络信息交换模块,也包含再其中
self.stage2, pre_stage_channels = self._make_stage(
self.stage2_cfg, num_channels)
于是我们再看看self._make_transition_layer这个函数到底做了什么
# 不同层数分支进行创建
def _make_transition_layer(self, num_channels_pre_layer, num_channels_cur_layer):
"""
:param num_channels_pre_layer: 上一个stage平行网络的输出通道数目,为一个list,
stage=2时, num_channels_pre_layer=[256]
stage=3时, num_channels_pre_layer=[32,64]
stage=4时, num_channels_pre_layer=[32,64,128]
:param num_channels_cur_layer:
stage=2时, num_channels_cur_layer = [32,64]
stage=3时, num_channels_cur_layer = [32,64,128]
stage=4时, num_channels_cur_layer = [32,64,128,256]
"""
num_branches_cur = len(num_channels_cur_layer)
num_branches_pre = len(num_channels_pre_layer)
transition_layers = []
# 对stage的每个分支进行处理
#stage1的时候,num_channels_cur_layer为2,所以有两个循环,i=0、1
for i in range(num_branches_cur):
# 如果不为最后一个分支
if i < num_branches_pre:
# 如果当前层的输入通道和输出通道数不相等,则通过卷积对通道数进行变换
#如果branches_cur通道数=branches_pre通道数,那么这个分支直接就可以用,不用做任何变化
#如果branches_cur通道数!=branches_pre通道数,那么就要用一个cnn网络改变通道数
#注意这个cnn是不会改变特征图的shape
#在stage1中,pre通道数是256,cur通道数为32,所以要添加这一层cnn改变通道数
#所以transition_layers第一层为
#conv2d(256,32,3,1,1)
#batchnorm2d(32)
#relu
if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
transition_layers.append(
nn.Sequential(
nn.Conv2d(
num_channels_pre_layer[i],
num_channels_cur_layer[i],
3, 1, 1, bias=False
),
nn.BatchNorm2d(num_channels_cur_layer[i]),
nn.ReLU(inplace=True)
)
)
else:
# 如果当前层的输入通道和输出通道数相等,则什么都不做
transition_layers.append(None)
else:
# 如果为最后一个分支,则再新建一个分支(该分支分辨率会减少一半)
#由于branches_cur有两个分支,branches_pre只有一个分支
#所以我们必须要利用branches_pre里的分支无中生有一个新分支
#这就是常见的缩减图片shape,增加通道数提特征的操作
conv3x3s = []
for j in range(i+1-num_branches_pre):
#利用branches_pre中shape最小,通道数最多的一个分支(即最后一个分支)来形成新分支
inchannels = num_channels_pre_layer[-1]
outchannels = num_channels_cur_layer[i] \
if j == i-num_branches_pre else inchannels
conv3x3s.append(
nn.Sequential(
nn.Conv2d(
inchannels, outchannels, 3, 2, 1, bias=False
),
nn.BatchNorm2d(outchannels),
nn.ReLU(inplace=True)
)
)
#所以transition_layers第二层为:
#nn.Conv2d(256, 64, 3, 2, 1, bias=False),
#nn.BatchNorm2d(64),
#nn.ReLU(inplace=True)
transition_layers.append(nn.Sequential(*conv3x3s))
return nn.ModuleList(transition_layers)
4. stage3网络
重新回到stage3的forward函数:
# 对应论文中的stage3
# 其中包含了创建分支的过程,即 N22-->N32,N33 这个过程
# N33的分辨率为N32的二分之一,
# y[b, 32, 64, 48] ---> x[b, 32, 64, 48] 因为通道数一致,没有做任何操作
# y[b, 64, 32, 24] ---> x[b, 64, 32, 24] 因为通道数一致,没有做任何操作
# x[b, 128, 16, 12] 通过新建平行分支生成
x_list = []
for i in range(self.stage3_cfg['NUM_BRANCHES']):
if self.transition2[i] is not None:
x_list.append(self.transition2[i](y_list[-1]))
else:
x_list.append(y_list[i])
# 总体过程如下(经过一些卷积操作,但是特征图的分辨率和通道数都没有改变):
# x[b, 32, 32, 24] ---> y[b, 32, 32, 24]
# x[b, 32, 16, 12] ---> y[b, 32, 16, 12]
# x[b, 64, 8, 6] ---> y[b, 64, 8, 6]
y_list = self.stage3(x_list)
我们在这一层看看self._make_stage如何实现提取特征和特征融合
# 同级stage设计,通过 HighResolutionModule
def _make_stage(self, layer_config, num_inchannels,
multi_scale_output=True):
"""
当stage=2时: num_inchannels=[32,64] multi_scale_output=Ture
当stage=3时: num_inchannels=[32,64,128] multi_scale_output=Ture
当stage=4时: num_inchannels=[32,64,128,256] multi_scale_output=False
"""
# 当stage=2,3,4时,num_modules分别为:1,4,3
# 表示HighResolutionModule(平行之网络交换信息模块)模块的数目
num_modules = layer_config['NUM_MODULES']
# 当stage=2,3,4时,num_branches分别为:2,3,4,表示每个stage平行网络的数目
num_branches = layer_config['NUM_BRANCHES']
# 当stage=2,3,4时,num_blocks分别为:[4,4], [4,4,4], [4,4,4,4],
# 表示每个stage blocks(BasicBlock或者BasicBlock)的数目
num_blocks = layer_config['NUM_BLOCKS']
# 当stage=2,3,4时,num_channels分别为:[32,64],[32,64,128],[32,64,128,256]
# 在对应stage, 对应每个平行子网络的输出通道数
num_channels = layer_config['NUM_CHANNELS']
# 当stage=2,3,4时,分别为:BasicBlock,BasicBlock,BasicBlock
block = blocks_dict[layer_config['BLOCK']]
# 当stage=2,3,4时,都为:SUM,表示特征融合的方式
fuse_method = layer_config['FUSE_METHOD']
modules = []
# 根据num_modules的数目创建HighResolutionModule
for i in range(num_modules):
#num_modules表示一个融合块中要进行几次融合,前几次融合是将其他分支的特征融合到最高分辨率的特征图上,只输出最高分辨率特征图(multi_scale_output = False)
#只有最后一次的融合是将所有分支的特征融合到每个特征图上,输出所有尺寸特征(multi_scale_output=True)
# multi_scale_output 只被用再最后一个HighResolutionModule
if not multi_scale_output and i == num_modules - 1:
reset_multi_scale_output = False
else:
reset_multi_scale_output = True
# 根据参数,添加HighResolutionModule到
modules.append(
HighResolutionModule(
num_branches, # 当前stage平行分支的数目
block, # BasicBlock,BasicBlock
num_blocks, # BasicBlock或者BasicBlock的数目
num_inchannels, # 输入通道数目
num_channels, # 输出通道数
fuse_method, # 通特征融合的方式
reset_multi_scale_output # 是否使用多尺度方式输出
)
)
# 获得最后一个HighResolutionModule的输出通道数
num_inchannels = modules[-1].get_num_inchannels()
return nn.Sequential(*modules), num_inchannels
5. stage4网络
stage4网络与前面的搭建一致。最后输出最高分辨率的一层就是预测分类。