2022搜狐校园NLP算法大赛情感分析第一名方案理解和复现
目录
一、比赛和方案理解
baseline的缺陷
第一名的方案
数据维度变化
二、代码实现
第一名代码
swa——平均权重
baseline代码
三、效果展示
第一名的方案:
a、adamW + swa
b、sgd + swa
baseline的方案
在知乎上看到2022搜狐校园NLP算法大赛情感分析第一名方案分享分享,觉得方案非常简单优雅,同时又有点prompt learning的意味在里面(严格来说不是prompt learning),并且效果非常好。虽然在他们的方案分享中也给出了比较详细的思路和基于pytorch-lightning的代码,但是有一些细节的地方还不够清楚,同时代码也不太容易理解,因此在博客中做更加清晰的说明和分享更加简洁(更好理解基于torch)的代码。
一、比赛和方案理解
这次比赛的任务是——面向实体对象的文本描述情感极性及色彩强度分析。情感极性和强度分为五种情况:极正向、正向、中立、负向、极负向。选手需要针对给定的每一个实体对象,从文本描述的角度,分析出对该实体的情感极性和强度。
数据如下:
{"id": 7410, "content": "如此战斗力惊人的篮网,球迷和专家对他的季后赛期待值能不高吗?因此整个赛季,大家的预测还是有道理的,今年的季后赛东部分区决赛应该还是去年的老样式,篮网和雄鹿估计是还是如约相见。今天的篮网三巨头其实还不是究极体,但也轻松“庖丁解牛”,公牛的路应该还是很漫长的,NBA终究还是那个超级巨星说话的舞台!", "entity": {"篮网": 1, "季后赛": 0}}{"id": 88679, "content": "2014.09 海南省委常委、儋州市委书记,兼洋浦经济开发区工委副书记2014.10 海南省委常委、三亚市委书记2016.11 海南省委常委、海口市委书记2019年9月被查。", "entity": {"市委书记": 0, "海南省委": 0}}
针对上面数据中的content文本和给出的entity,分析出它们分别在content中包含的情感色彩。很明显这是一个分类任务,我当时看见这个赛题的时候,头脑中闪现出的解决方案就是和他们给出的baseline一模一样:
[CLS]content[SEP]entity_0[SEP]
[CLS]content[SEP]entity_1[SEP]
[CLS]content[SEP]entity_2[SEP]
......
[CLS]content[SEP]entity_n[SEP]
按照上面把content和每个entity拼接起来后,送入bert模型提取句向量,然后过分类器,这样就完成了这个任务,这个方案在比赛中也有人使用据说效果不是很理想。下面来看看比赛第一名的方案:
baseline的缺陷
如下图(引用比赛作者方案分享中的图)

因为每条数据的实体数据不相等,所以如同baseline那样的拼接方案,会导致模型见到content文本次数不一样,对最终的效果可能会有影响;同时把每一条数据复制了entity数量次,导致训练数据过多,效率比较地下。还有一个问题就是,模型得到的句向量的选择也会有一定的误差,baseline的方案中最后要么去cls或者所有token的embedding做meanPooling,这样也会对最后的结果产生一定的影响;最后就是那每个实体单独拼接,感觉有点弱化了每个实体间的联系,对最后的结果会产生一定的影响。
第一名的方案
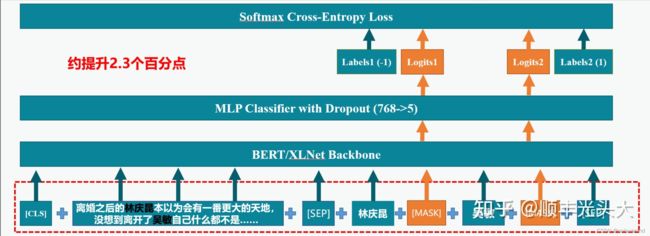
如上图(引用比赛作者方案分享中的图),把每条数据中的实体用[MASK]拼接起来,然后和content文本使用[SEP]拼接起来,这样就可以高效的在一条数据中构建一个分类任务,而不需要如果baseline那样对每一条数据重复多次。同时这里也避免了最后句向量的取舍问题,直接把[MASK]处对应的embedding作为每个实体情感的分类embedding。这个方案中[MASK]的引入,也有一点prompt learning的意味在里面,效果上作者说比较好。另一方面,它又不是严格的prompt learning,它不需要预测出[Mask]处具体的token是什么,然后做类别映射,也就是不需要做Prompt 答案空间映射(Verbalizer)的构造,只是做了一个Prompt 模版(Template)的构造。
总体行来说,这个方案确实比较优雅,当然效果也比较好,让人一看就有点耳目一新的感觉。当然看论文(prompt learning)比较多的话,应该也能想到类似的方案。代码上实现的一些细节——矩阵的维度变换,给一个更加清洗的说明,理解整个方案就更加的容易了。
数据维度变化
一个batch的数据
[CLS]content_0[SEP]entity_0_0[MASK]entity_0_1[MASK]entity_0_2[MASK][SEP]
[CLS]content_1[SEP]entity_1_0[MASK]entity_1_1[MASK][SEP]
[CLS]content_2[SEP]entity_2_0[MASK][SEP]
[CLS]content_3[SEP]entity_3_0[MASK]entity_3_1[MASK][SEP]
[CLS]content_4[SEP]entity_4_0[MASK]entity_4_1[MASK]entity_4_2[MASK][SEP]
......
[CLS]content_(batch_size-1)[SEP]entity_(batch_size-1)_0[MASK]entity_(batch_size-1)_1[MASK][SEP]
经过tokenizer后,就把token映射到词典对应的id上,需要记录每条数据的input_ids、attention_mask、mask_tokens、entity_count、label,对应的维度变化如下
input_ids:[batch,seq_length]
[
[101,******,102,**,103,**,103,102,,0,0,0,0,0],
[101,******,102,**,103,**,103,102],
[101,******,102,**,103,102,0,0,0,0,0],
......
[101,******,102,**,103,**,103,**,103,**,103,0,0]
]
attention_mask:[batch,seq_length]
[
[1,******,1,**,1,**,1,1,,0,0,0,0,0],
[1,******,1,**,1,**,1,1],
[1,******,1,**,1,1,0,0,0,0,0],
......
[1,******,1,**,1,**,1,**,1,**,1,0,0]
]
mask_tokens:[batch,seq_length]
[
[0,******,0,**,1,**,1,0,,0,0,0,0,0],
[0,******,0,**,1,**,1,0],
[0,******,0,**,1,0,0,0,0,0,0],
......
[0,******,0,**,1,**,1,**,1,**,1,0,0]
]
label用list维护
[
[-2,2],
[1,2],
[-2],
......
[2,-2,0,-1]
]
如果batch内的实体为m个那么label的矩阵就是[m]
[-2,2,1,2,......,2,-2,0,-1]
input_ids+attention_mask经过bert后得到的结果:
# m表示batch内有m个实体
is_masked = inputs['is_masked'].bool()
inputs = {k: v for k, v in inputs.items() if k in ["input_ids", "attention_mask"]}
outputs = self.bert(**inputs,return_dict=True, output_hidden_states=True)
# [batch, seq_length, 768]
outputs = outputs.last_hidden_state
# [m,768]
masked_outputs = outputs[is_masked]
# [m,5]
logits = self.classifier(masked_outputs)
二、代码实现
第一名代码
作者给出了基于pytorch-lightning的代码,我认为封装的比较高了,不太容易理解,在此基础上,我实现了一版基于torch的代码:
模型代码
from transformers import BertPreTrainedModel,BertModel
import torch.nn as nn
class SentiClassifyBertPrompt(BertPreTrainedModel):
def __init__(self,config):
super(SentiClassifyBertPrompt,self).__init__(config)
self.bert = BertModel(config=config)
self.classifier = nn.Sequential(
nn.Linear(config.hidden_size, config.hidden_size),
nn.LayerNorm(config.hidden_size),
nn.LeakyReLU(),
nn.Dropout(p=config.dropout),
nn.Linear(config.hidden_size, config.output_dim),
)
def forward(self,inputs):
# m表示batch内有m个实体
is_masked = inputs['is_masked'].bool()
inputs = {k: v for k, v in inputs.items() if k in ["input_ids", "attention_mask"]}
outputs = self.bert(**inputs,return_dict=True, output_hidden_states=True)
# [batch, seq_length, 768]
outputs = outputs.last_hidden_state
# [m,768]
masked_outputs = outputs[is_masked]
# [m,5]
logits = self.classifier(masked_outputs)
return logits数据加载代码
import torch
from torch.utils.data import Dataset
from tqdm import tqdm
import json
class DataReader(Dataset):
def __init__(self,file_path,tokenizer,max_langth):
self.file_path = file_path
self.tokenizer = tokenizer
self.max_length = max_langth
self.data_list = self.texts_tokeniztion()
self.allLength = len(self.data_list)
def texts_tokeniztion(self):
with open(self.file_path,'r',encoding='utf-8') as f:
lines = f.readlines()
res = []
for line in tqdm(lines,desc='texts tokenization'):
line_dic = json.loads(line.strip('\n'))
content = line_dic['content']
entity = line_dic['entity']
prompt_length = 0
prompts = ""
label = []
en_count = len(entity)
for k,v in entity.items():
prompt_length += len(k) + 1
#标签化为 0-4的整数
label.append(v+2)
prompts += k +"[MASK]"
#直接最大长度拼接
content = content[0:self.max_length-prompt_length-1-10]
text = content + "[SEP]" + prompts
input_ids,attention_mask,masks = self.text2ids(text)
input_ids = torch.tensor(input_ids,dtype=torch.long)
attention_mask = torch.tensor(attention_mask,dtype=torch.long)
masks = torch.tensor(masks, dtype=torch.long)
#记录每条数据有多少个实体,方便推理的时候batch推理
en_count = torch.tensor(en_count,dtype=torch.long)
temp = []
temp.append(input_ids)
temp.append(attention_mask)
temp.append(masks)
temp.append(label)
temp.append(en_count)
res.append(temp)
return res
def text2ids(self,text):
inputs = self.tokenizer(text)
input_ids = inputs['input_ids']
attention_mask = inputs['attention_mask']
masks = [ int(id==self.tokenizer.mask_token_id) for id in input_ids]
return input_ids, attention_mask, masks
def __getitem__(self, item):
input_ids = self.data_list[item][0]
attention_mask = self.data_list[item][1]
masks = self.data_list[item][2]
label = self.data_list[item][3]
en_count = self.data_list[item][4]
return input_ids, attention_mask, masks, label, en_count
def __len__(self):
return self.allLength模型训练代码
from data_reader.reader import DataReader
import torch
from torch.utils.data import DataLoader
from transformers import BertTokenizer,BertConfig
from torch.optim import AdamW
from model import SentiClassifyBertPrompt
from torch.optim.swa_utils import AveragedModel, SWALR
from torch.nn.utils.rnn import pad_sequence
from log.log import Logger
from tqdm import tqdm
import torch.nn.functional as F
import os
os.environ['CUDA_VISIBLE_DEVICES'] = "1"
def collate_fn(batch):
input_ids, attention_mask, masks, label, en_count = zip(*batch)
input_ids = pad_sequence(input_ids,batch_first=True,padding_value=0)
attention_mask = pad_sequence(attention_mask,batch_first=True,padding_value=0)
masks = pad_sequence(masks, batch_first=True, padding_value=0)
labels = []
for ele in label:
labels.extend(ele)
labels = torch.tensor(labels,dtype=torch.long)
en_count = torch.stack(en_count,dim=0)
return input_ids, attention_mask, masks, labels, en_count
def dev_validation(dev_loader,device,model):
total_correct = 0
total = 0
model.eval()
with torch.no_grad():
for step, batch in enumerate(tqdm(dev_loader, desc="dev_validation")):
batch = [t.to(device) for t in batch]
inputs = {"input_ids": batch[0], "attention_mask": batch[1], "is_masked": batch[2]}
label = batch[3]
logits = model(inputs)
preds = torch.argmax(logits,dim=1)
correct = (preds==label).sum()
total_correct += correct
total += label.size()[0]
acc = total_correct/total
return acc
def set_seed(seed = 1):
torch.cuda.manual_seed_all(seed)
torch.manual_seed(seed)
torch.backends.cudnn.deterministic = True
if __name__ == '__main__':
set_seed()
log_level = 10
log_path = "logs/train_bert_prompt_AdamW_swa.log"
logger = Logger(log_name='train_bert_prompt', log_level=log_level, log_path=log_path).logger
pretrain_model_path = "./pretrained_models/chinese-bert-wwm-ext"
batch_size = 16
epochs = 10
tokenizer = BertTokenizer.from_pretrained(pretrain_model_path)
config = BertConfig.from_pretrained(pretrain_model_path)
config.dropout = 0.2
config.output_dim = 5
config.batch_size = batch_size
device = "cuda" if torch.cuda.is_available() else "cpu"
model = SentiClassifyBertPrompt.from_pretrained(config=config,pretrained_model_name_or_path = pretrain_model_path)
model.to(device)
optimizer = AdamW(params=model.parameters(),lr=1e-6)
# 随机权重平均SWA,实现更好的泛化
swa_model = AveragedModel(model=model,device=device)
# SWA调整学习率
swa_scheduler = SWALR(optimizer, swa_lr=1e-6)
train_dataset = DataReader(tokenizer=tokenizer, max_langth=512, file_path='./data/train_split.txt')
train_loader = DataLoader(dataset=train_dataset, shuffle=True, batch_size=batch_size, collate_fn=collate_fn)
dev_dataset = DataReader(tokenizer=tokenizer, max_langth=512, file_path='./data/dev_split.txt')
dev_loader = DataLoader(dataset=dev_dataset, shuffle=True, batch_size=batch_size, collate_fn=collate_fn)
for epoch in range(epochs):
model.train()
for step,batch in enumerate(tqdm(train_loader,desc="training")):
batch = [ t.to(device) for t in batch]
inputs = {"input_ids":batch[0],"attention_mask":batch[1],"is_masked":batch[2]}
label = batch[3]
logits = model(inputs)
loss = F.cross_entropy(logits,label)
loss.backward()
optimizer.step()
optimizer.zero_grad()
swa_model.update_parameters(model)
swa_scheduler.step()
acc = dev_validation(dev_loader,device,model)
swa_acc = dev_validation(dev_loader,device,swa_model)
logger.info('Epoch %d acc is %.6f'%(epoch,acc))
logger.info('Epoch %d swa_acc is %.6f' % (epoch, swa_acc))
工程目录如下

swa——平均权重
以上训练代码中有一个训练的trick——swa——平均权重是我之前没有见过和使用过的,有必要提一提,其核心思想,是训练的过程中最后保留的模型,并不是验证集上效果最好的模型,而是所有epoch训练后的模型的权重平均值,这样训练出来的模型最具更好的泛化能力和最优的效果。我们也不用自己去实现怎么计算权重的平均,torch也已经有了规范化的流程和代码了,具体的效果怎么样,需要实验去验证(有人说过sgd+swa才有效)。
......
optimizer = AdamW(params=model.parameters(),lr=1e-6)
# 随机权重平均SWA,实现更好的泛化
swa_model = AveragedModel(model=model,device=device)
# SWA调整学习率
swa_scheduler = SWALR(optimizer, swa_lr=1e-6)
for epoch in range(epochs):
model.train()
for step,batch in enumerate(tqdm(train_loader,desc="training")):
......
#正常训练
logits = model(inputs)
loss = F.cross_entropy(logits,label)
loss.backward()
optimizer.step()
optimizer.zero_grad()
#每个epoch后swa_model模型更新参数
swa_model.update_parameters(model)
#调整学习率
swa_scheduler.step()baseline代码
为了简单验证一下效果怎么样,我也把baseline的方案跑出来了,代码如下:
import torch
from torch.utils.data import Dataset
from tqdm import tqdm
import json
from transformers import BertPreTrainedModel,BertModel
import torch.nn as nn
class SentiClassifyBert(BertPreTrainedModel):
def __init__(self,config):
super(SentiClassifyBert,self).__init__(config)
self.bert = BertModel(config=config)
self.classifier = nn.Sequential(
nn.Linear(config.hidden_size, config.hidden_size),
nn.LayerNorm(config.hidden_size),
nn.LeakyReLU(),
nn.Dropout(p=config.dropout),
nn.Linear(config.hidden_size, config.output_dim),
)
def forward(self,inputs):
inputs = {k: v for k, v in inputs.items() if k in ["input_ids", "attention_mask"]}
outputs = self.bert(**inputs,return_dict=True, output_hidden_states=True)
outputs = outputs.last_hidden_state
cls_output = outputs[:,0:1,:].squeeze()
logits = self.classifier(cls_output)
return logits
class DataReader(Dataset):
def __init__(self,file_path,tokenizer,max_langth):
self.file_path = file_path
self.tokenizer = tokenizer
self.max_length = max_langth
self.data_list = self.texts_tokeniztion()
self.allLength = len(self.data_list)
def texts_tokeniztion(self):
with open(self.file_path,'r',encoding='utf-8') as f:
lines = f.readlines()
res = []
for line in tqdm(lines,desc='texts tokenization'):
line_dic = json.loads(line.strip('\n'))
content = line_dic['content']
entity = line_dic['entity']
for k,v in entity.items():
# 直接最大长度拼接
content = content[0:self.max_length - len(k) - 1 - 10]
text = content + "[SEP]" + k
input_ids, attention_mask, masks = self.text2ids(text)
input_ids = torch.tensor(input_ids, dtype=torch.long)
attention_mask = torch.tensor(attention_mask, dtype=torch.long)
label = torch.tensor(v+2, dtype=torch.long)
temp = []
temp.append(input_ids)
temp.append(attention_mask)
temp.append(label)
res.append(temp)
return res
def text2ids(self,text):
inputs = self.tokenizer(text)
input_ids = inputs['input_ids']
attention_mask = inputs['attention_mask']
masks = [ int(id==self.tokenizer.mask_token_id) for id in input_ids]
return input_ids, attention_mask, masks
def __getitem__(self, item):
input_ids = self.data_list[item][0]
attention_mask = self.data_list[item][1]
label = self.data_list[item][2]
return input_ids, attention_mask, label
from data_reader.reader import DataReader
import torch
from torch.utils.data import DataLoader
from transformers import BertTokenizer,BertConfig
from torch.optim import AdamW,SGD
from model import SentiClassifyBert
from torch.optim.swa_utils import AveragedModel, SWALR
from torch.nn.utils.rnn import pad_sequence
from log.log import Logger
from tqdm import tqdm
import torch.nn.functional as F
import os
os.environ['CUDA_VISIBLE_DEVICES'] = "0"
def collate_fn(batch):
input_ids, attention_mask, label = zip(*batch)
input_ids = pad_sequence(input_ids,batch_first=True,padding_value=0)
attention_mask = pad_sequence(attention_mask,batch_first=True,padding_value=0)
label = torch.stack(label,dim=0)
return input_ids, attention_mask, label
def dev_validation(dev_loader,device,model):
total_correct = 0
total = 0
model.eval()
with torch.no_grad():
for step, batch in enumerate(tqdm(dev_loader, desc="dev_validation")):
batch = [t.to(device) for t in batch]
inputs = {"input_ids": batch[0], "attention_mask": batch[1]}
label = batch[2]
logits = model(inputs)
preds = torch.argmax(logits,dim=1)
correct = (preds==label).sum()
total_correct += correct
total += label.size()[0]
acc = total_correct/total
return acc
def set_seed(seed = 1):
torch.cuda.manual_seed_all(seed)
torch.manual_seed(seed)
torch.backends.cudnn.deterministic = True
if __name__ == '__main__':
set_seed()
log_level = 10
log_path = "logs/train_bert_adamW_swa_20220718.log"
logger = Logger(log_name='train_bert', log_level=log_level, log_path=log_path).logger
pretrain_model_path = "./pretrained_models/chinese-bert-wwm-ext"
batch_size = 16
epochs = 20
tokenizer = BertTokenizer.from_pretrained(pretrain_model_path)
config = BertConfig.from_pretrained(pretrain_model_path)
config.dropout = 0.2
config.output_dim = 5
config.batch_size = batch_size
device = "cuda" if torch.cuda.is_available() else "cpu"
model = SentiClassifyBert.from_pretrained(config=config,pretrained_model_name_or_path = pretrain_model_path)
model.to(device)
optimizer = AdamW(params=model.parameters(),lr=1e-6)
# optimizer = SGD(params=model.parameters(), lr=1e-5,momentum=0.9)
# 随机权重平均SWA,实现更好的泛化
swa_model = AveragedModel(model=model,device=device)
# SWA调整学习率
swa_scheduler = SWALR(optimizer, swa_lr=1e-6)
train_dataset = DataReader(tokenizer=tokenizer, max_langth=512, file_path='./data/train_split.txt')
train_loader = DataLoader(dataset=train_dataset, shuffle=True, batch_size=batch_size, collate_fn=collate_fn)
dev_dataset = DataReader(tokenizer=tokenizer, max_langth=512, file_path='./data/dev_split.txt')
dev_loader = DataLoader(dataset=dev_dataset, shuffle=True, batch_size=batch_size, collate_fn=collate_fn)
for epoch in range(epochs):
model.train()
for step,batch in enumerate(tqdm(train_loader,desc="training")):
batch = [ t.to(device) for t in batch]
inputs = {"input_ids":batch[0],"attention_mask":batch[1]}
label = batch[2]
logits = model(inputs)
loss = F.cross_entropy(logits,label)
loss.backward()
optimizer.step()
optimizer.zero_grad()
swa_model.update_parameters(model)
swa_scheduler.step()
acc = dev_validation(dev_loader,device,model)
swa_acc = dev_validation(dev_loader,device,swa_model)
logger.info('Epoch %d acc is %.6f'%(epoch,acc))
logger.info('Epoch %d swa_acc is %.6f' % (epoch, swa_acc))
训练中把约9W条数据的训练集切分出1W条数据作为验证集,使用chinese-bert-wwm-ext作为预训练模型,训练20个epochs;对比了SGD和AdamW优化器的效果;同时也对比了baseline和第一名方案的效果;当然swa的效果好不好不能给出一个结论,因为没有测试集。
三、效果展示
第一名的方案:
a、adamW + swa
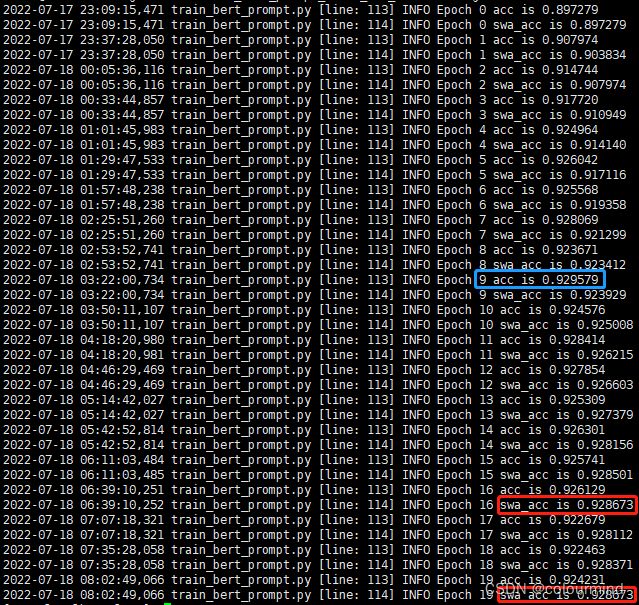
验证集上的准确率使用AdamW优化器20个epochs内最高准确率是0.929579;swa则是0.928673——它在测试集上表现如何就不太清楚了了。
b、sgd + swa
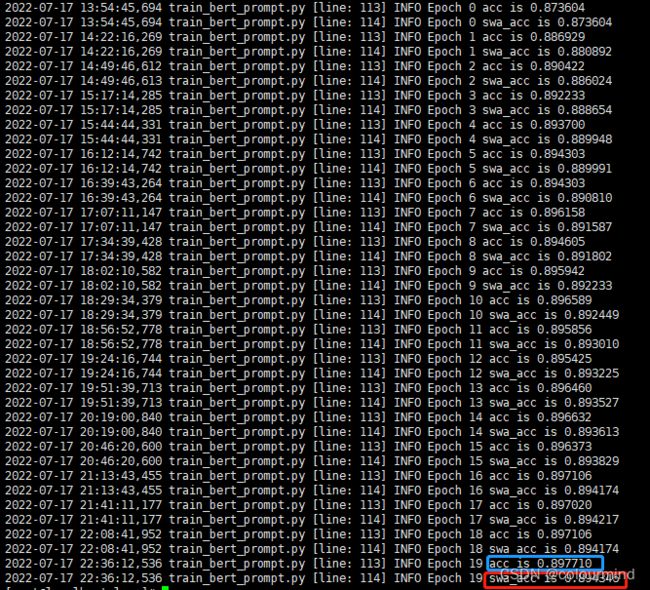
从准确率上来看sgd收敛的比较慢,再低19个epcoh准确率才到达最高值,而且准确率也没有AdamW高,才89.7,不过看来还没有完全收敛,继续训练还可以提升,不过要花很长时间;看来AdamW这种智能优化器还是比较适合我这种不太会调优化器参数的人呀。
baseline的方案

对比来看baseline的效果差的有点多,第一名的方案确实有效,主要的还是有两点,一是没有重复拼接,造成数据分布的改变,同时模型可能对于学习实体直接的关系更加擅长;二是句向量的选择更加的合适,没有选取cls也没有选取meanPooling的embedding,而是选取[MASK]对应的embedding更加的精确,这种本质上是把prompt learning做了改变应用到这里来了,预训练和微调的gap更小了,提取到的embedding更加准确,所有效果才好。
方案优雅,值得学习和借鉴!
参考文章
2022搜狐校园NLP算法大赛情感分析第一名方案分享
2022搜狐校园 情感分析 算法大赛