怒肝两万字 Java 中的 IO(详细篇)
文章目录
- Java IO 的演变之路
-
- I/O 模型
- BIO
-
- 基本介绍以及工作机制
- BIO 模式下多发和多收模式
- BIO 模式下接受多个客户端
- 伪异步 I/O 编程
- NIO 和 BIO 比较
- NIO(重点)
-
- 基本介绍(三大核心)
- 三大核心:Buffer(缓存区)
-
- 缓存区的基本属性
- Buffer中常见的方法
- 直接缓存与非直接缓存
- 三大核心:Channel(通道)
- 三大核心:Selector(选择器)
- AIO
- BIO、NIO、AIO总结
Java IO 的演变之路
I/O模型:就是用什么样的通道或者说是通信模式和架构进行数据的传输和接受,很大程度上决定了程序通信的性能,在Java 当中一种支持 3 种 IO模型。
BIO、NIO、AIO
在实际通信需求下,要根据不同的业务场景和性能需求决定选择不同的 IO 模型。
I/O 模型
Java BIO:同步并阻塞的(传统阻塞型),服务器实现模式为一个连接一个线程,即客户端有链接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情就会造成不必要的线程开销。
BIO 方式主要适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4之前的唯一选择,但程序方面简单易理解。
Java NIO:同步非阻塞。服务器实现模式为一个线程处理多个请求(连接),即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有 I/O 请求就进行处理。
NIO 方式只要适用于连接数目比较多且连接数据比较短(轻操作)的架构。比如:聊天服务器,弹幕系统,服务器间通信,JDK 1.4 开始支持这方面的了。
Java AIO:异步非阻塞(NIO.2),服务器实现模式为一个有效情趣一个线程,客户端的 I/O 请求都是由 OS 先完成了再通知服务器应用去启动线程进行处理,一般适用于连接数目较多并连接时间较长的应用。
AIO 方式主要适用于连接数目多且连接数据比较长(重操作)的结构。比如:相册服务器,充分调用 OS 参与并发操作,编程比较复杂,JDK 7之后开始支持。
BIO
基本介绍以及工作机制
Java BIO 就是传统的 Java IO 编程,其相关的类和接口是在 java.io 包中。
BIO(blocking I/O)同步阻塞,服务器实现模式为一个连接一个线程,即客户端游连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情就会造成不必要的线程开销,可以通过线程池机制来进行改善(实现多个客户连接服务器)
网络编程的基本模型是 Client/Server 模型,也就是两个进程之间进行相互的通信,其中服务端提供位置信息(绑定 IP 地址和端口),客户端通过连接操作向服务端监听的端口地址发起连接请求,基于 TCP 协议下进行三次握手连接,连接成功后,双方通过网络套接字(Socket)进行通信。
传统的同步阻塞模型开发中,服务端 ServerSocket 负责绑定 IP 地址,启动监听端口;客户端 Socket 负责发起连接操作。连接成功后,双方通过输入和输出流进行同步阻塞式通信。
基于 BIO 模式下的通信,客户端-服务端是完全同步的,完全耦合的。

BIO 模式下多发和多收模式
代码演示,代码说明一切
服务端:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.ServerSocket;
import java.net.Socket;
/**
* 服务端
* 可以反复的接收消息,客户端可以反复的发送消息
*/
public class Server {
public static void main(String[] args) {
try {
System.out.println("===服务端启动===");
//1.定义一个ServerSocket对象进行服务端的端口注册
ServerSocket ss = new ServerSocket(9999);
//2. 监听客户端的Socket连接请求
Socket socket = ss.accept();
//3.从socket管道中得到一个字节输入流对象
InputStream inputStream = socket.getInputStream();
//4.把字节输入改为字符输入流
InputStreamReader reader = new InputStreamReader(inputStream);
//4.把字符输入流包装成一个缓存字符输入流
BufferedReader br = new BufferedReader(reader);
String msg;
while ((msg = br.readLine()) != null) {
System.out.println("服务端接收到:" + msg);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
客户端:
import java.io.OutputStream;
import java.io.PrintStream;
import java.net.Socket;
import java.util.Scanner;
/**
* 客户端
* 用来发送数据
*/
public class Client {
public static void main(String[] args) {
try {
//1.创建Socket对象请求服务端的连接
Socket socket = new Socket("127.0.0.1",9999);
//2.从Socket对象中获取一个字节输出流
OutputStream os = socket.getOutputStream();
//3.把字节输出流包装成一个打印流
PrintStream ps = new PrintStream(os);
Scanner sc = new Scanner(System.in);
while (true) {
System.out.print("请说:");
String msg = sc.nextLine();
ps.println(msg);
ps.flush();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
在上面的通信当中,服务端会一直等待客户端的消息,如果客户端没有进行消息的发送,服务端将会一直处于阻塞状态。
同时服务端是按照行获取信息的,这就意味着客户端也必须按照进行消息的发送,否则服务端将进入等待消息的阻塞状态。
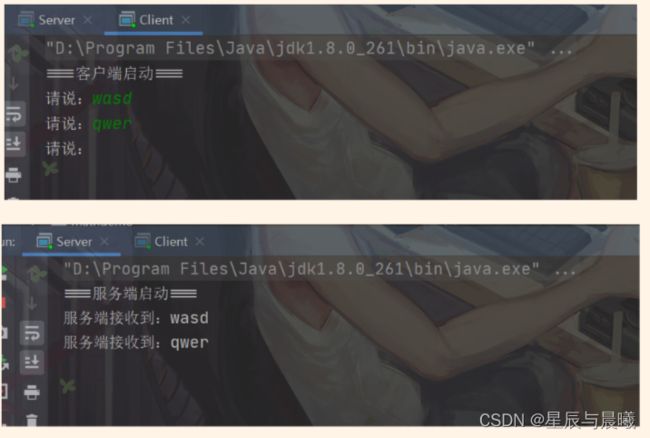
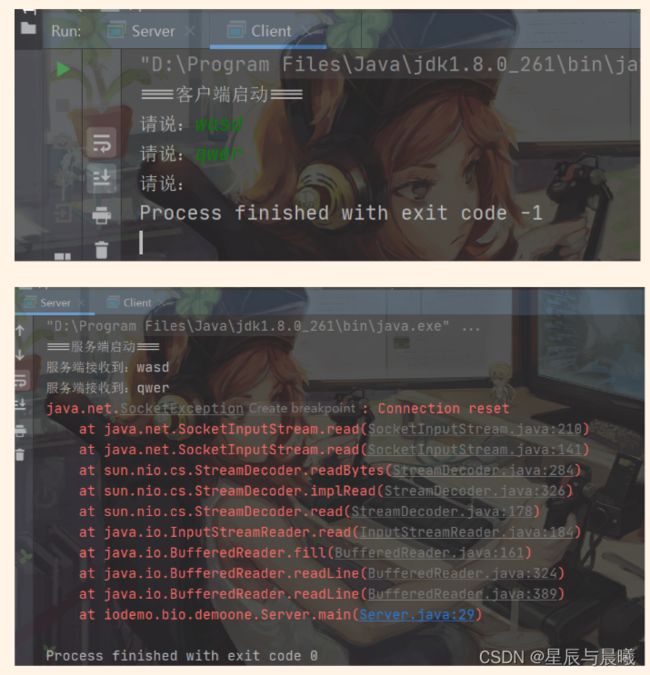
同时在这,若先关闭客户端,那么服务端就将会报错。Connection reset(连接重置的意思)
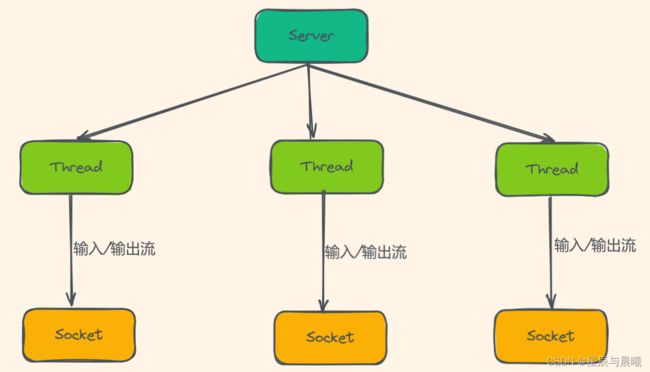
BIO 模式下接受多个客户端
上面的是一个服务端只能结束一个客户端的通信请求,那么如果服务端需要很多个客户端的信息通信请求应该如何处理,在这个时候我们就可以引入线程,也就是说客户端没发起一个请求,服务端就创建一个新的线程来处理这个客户端的请求,这样就实现了一个客户端一个线程的模型了。
代码说明:
服务端代码:
import java.net.ServerSocket;
import java.net.Socket;
/**
* 服务端
* 接受客户端发来的请求
* 因为服务端要求接受多个客户端的连接,所以以现场操作进行
*/
public class Server {
public static void main(String[] args) {
try {
System.out.println("===服务端启动===");
//1.注册端口
ServerSocket ss = new ServerSocket(9999);
//2.定义一个死循环,负责不断的接收客户端的Socket的连接请求
while (true) {
// 阻塞式的,当遇到一个客户端请求连接,通过,当没有的时候,阻塞
Socket socket = ss.accept();
//3.创建一个独立的线程来处理与这个客户端的socket通信的具体需求
new ServerThread(socket).start();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
服务端需要接受多个客户端,就要开启多线程。多线程代码:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.Socket;
/**
* 服务端创建的线程,服务端后执行的东西主要就是在这进行执行
*/
public class ServerThread extends Thread {
private Socket socket;
public ServerThread(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
// 在这执行具体的客户端的具体操作
try {
//从 socket 对象中得到字节的输入流
InputStream inputStream = socket.getInputStream();
// 使用缓存字符输入流包装字节的输入流
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
String msg;
while ((msg = reader.readLine()) != null) {
System.out.println("客户端接收到:" + msg);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
客户端代码,和上面比,没有什么变化:
import java.io.PrintStream;
import java.net.Socket;
import java.util.Scanner;
/**
* 客户端
* 向服务端发送数据的方向
*/
public class Client {
public static void main(String[] args) {
try {
System.out.println("===客户端启动===");
//1.请求与服务端的Socket对象连接
Socket socket = new Socket("127.0.0.1", 9999);
//2. 得到一个打印流
PrintStream ps = new PrintStream(socket.getOutputStream());
//3. 使用循环不断的发送消息给服务端接收
Scanner sc = new Scanner(System.in);
while (true) {
System.out.print("请说:");
String msg = sc.nextLine();
ps.println(msg);
ps.flush();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果:
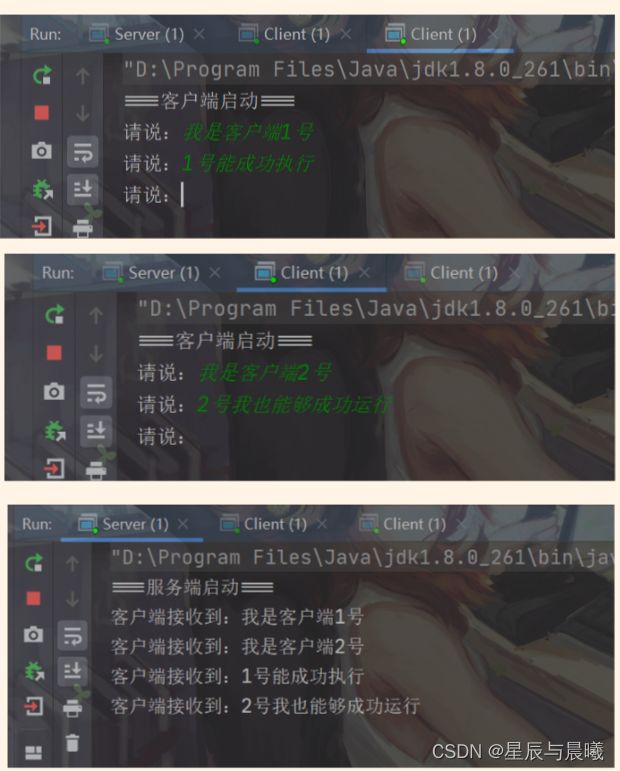
在这我们实现服务端接受多个客户端,使用的是多线程的方式。
而每个 Socket 接受的时候,都会创建一个线程,而线程的竞争、切换上下文都会影响性能。
每个线程都会占用栈的空间和 CPU 资源。
在这我们接受的是多个客户端,但并不是每个 socket 都在进行 IO 操作,所以这些无意义的线程也会造成性能的占用。
客户端的并发访问增加的时候,服务端将呈现的是 1:1 的线程开销,访问量越大,系统就将会发生线程栈溢出,线程创建失败,最终导致进程宕机或者死机,从而不能再提供服务。
伪异步 I/O 编程
在上面的使用的 接受多个客户端并发访问增加的时候。服务端将呈现 1:1 的现开销,访问量越大,系统发生线程栈溢出,最终导致栈溢出或者僵死,从而不能对外提供服务。所以在这我们就可以使用伪异步 I/O 的通信模式
采用线程池和任务队列实现,当客户端接入的时候,将客户端的 Socket 封装成一个 Task(该任务实现java.lang.Runnable(线程任务接口))交给后端的线程池中进行处理。 JDK的线程池维护一个消息队列和 N 个活跃的线程,对消息队列中 Socket 任务进行处理,由于线程池中可以设置消息队列的大小和最大线程数,因此,它的资源占用是可控的,无论多少个客户端并发访问,它会通过自身机制的处理从而不对导致资源的耗尽和宕机。
戳一下:===》了解线程池
代码说明:
服务端:
import java.net.ServerSocket;
import java.net.Socket;
/**
* 服务端
*/
public class Server {
public static void main(String[] args) {
try {
System.out.println("===服务端启动===");
// 1. 注册端口
ServerSocket serverSocket = new ServerSocket();
// 2. 定义一个死循环,负责不断循环接受客户端的请求
// 初始化一个线程池对象
HandlerSocketServerPool pool = new HandlerSocketServerPool(3,3, 10);
while (true){
// 阻塞式的,当遇到一个客户端请求连接,通过,当没有的时候,阻塞
Socket socket = serverSocket.accept();
// 把 socket 对象交给一个线程池进行处理
// 将 socket 封装为一个任务对象,然后交给线程池
ServerRunnable runnable = new ServerRunnable(socket);
pool.execute(runnable);
}
}catch (Exception e){
e.printStackTrace();
}
}
}
Socket任务类
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.Socket;
public class ServerRunnable implements Runnable {
private Socket socket;
public ServerRunnable(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
try {
// 处理接受到客户端 socket 需求
// 从socket管道中得到一个字节输入流对象
InputStream stream = socket.getInputStream();
// 把字节输入流包装成一个缓存字符输入流
BufferedReader reader = new BufferedReader(new InputStreamReader(stream));
String msg;
while ((msg = reader.readLine()) != null) {
System.out.println("服务端接受到:" + msg);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
线程池处理类
/**
* 将任务放到线程池里面
*/
public class HandlerSocketServerPool {
private ExecutorService executorService;
public HandlerSocketServerPool(int corePoolSize, int maxThreadNum, int queueSize) {
//定义线程池
/**
* public ThreadPoolExecutor(int corePoolSize, 核心线程池的大小
* int maximumPoolSize,线程池中最大的线程数量
* long keepAliveTime,线程在没有任务执行时最多保持多久时间会终止
* TimeUnit unit, keepAliveTime 的时间单位
* BlockingQueue workQueue 任务队列,也叫阻塞队列,用来存储等待执行任务
* ) {
* this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
* Executors.defaultThreadFactory(), defaultHandler);
*
*/
executorService = new ThreadPoolExecutor(corePoolSize, maxThreadNum, 120,
TimeUnit.SECONDS, new ArrayBlockingQueue<>(queueSize));
}
// 提供一个方法来提交任务给线程池的任务队列当中暂存,等待线程池来处理
public void execute(Runnable runnable) {
executorService.execute(runnable);
}
}
可以理解为 Runnable 用于将socket请求封装,但是Runnable线程暂时不执行,然后将封装好的线程交给线程池进行执行。
客户端还是上面代码的客户端:
import java.io.PrintStream;
import java.net.Socket;
import java.util.Scanner;
/**
* 客户端
* 向服务端发送数据的方向
*/
public class Client {
public static void main(String[] args) {
try {
System.out.println("===客户端启动===");
//1.请求与服务端的Socket对象连接
Socket socket = new Socket("127.0.0.1", 9999);
//2. 得到一个打印流
PrintStream ps = new PrintStream(socket.getOutputStream());
//3. 使用循环不断的发送消息给服务端接收
Scanner sc = new Scanner(System.in);
while (true) {
System.out.print("请说:");
String msg = sc.nextLine();
ps.println(msg);
ps.flush();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
结果演示:

当我们关闭客户端 2 号 的时候。
伪异步采用了线程池的设计思想,因此避免了为每一个独立线程造成线程资源耗尽的问题,但终归到底它的底层依然采用的是同步阻塞模型,在更本上是解决这个问题。
如果单个消息处理的缓慢,或者是服务器线程池中的全部线程都被阻塞,那么后续的 socket 的 I/O 消息都将被堵塞在消息队列中。新的 Socket 请求堵在消息队列当中,使得客户端发生大量的连接超时。
NIO 和 BIO 比较
BIO 是以流的方式处理数据的,而 NIO 是以块的方式处理数据的,块 I/O 的效率是比流 I/O 要高很多的。
BIO 是阻塞的,NIO 则是非阻塞的。
BIO 是基于字节流的字符流进行操作的;
而 NIO 是基于 Channel(通道)和 Buffer(缓冲区)进行操作的,数据总是从缓冲区写入到通道中,或者从通道读取到缓冲区中。 Selector(选择器)是用于监听多个通道的事件(比如:连接请求、数据到达等),因此使用单个线程就可以监听多个客户端通道。
| NIO | BIO |
|---|---|
| 面向缓存区(Buffer) | 面向流(Stream) |
| 非阻塞(Non Blocking IO) | 阻塞 IO(Blocking IO) |
| 选择器(Selector) |
NIO(重点)
基本介绍(三大核心)
Java NIO (new IO)也有人称为 java non-blocking IO 是java 1.4 版本开始引入的一个新的 IO API,它是可以替代标准的 java IO API。
NIO 与原来的 IO 是由同样的作用和目的,但是使用的方式完全不同,NIO 支持面向缓冲区的、基于通道的 IO 操作。
NIO 是可以以更高效的方式进行文件的续写操作 ,NIO 可以理解为非阻塞 IO ,传统的 IO 的 read 和 write 只能阻塞的进行,线程在读写期间是不能受其他事情干扰的。比如在执行 socket.read() 方法的时候,如果服务器一直没有数据传输过来,线程就一直处于阻塞,而 NIO 中就可以配置 socket 为非阻塞模式。
NIO 的相关类都是放在 java.nio 包以及子包之下的,并且是对原 java.io 包中的很多类进行改写的。
Java NIO 的非阻塞模式,使一个线程从某通道发送请求或者读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用的话,就什么都不会获取,而是保持线程的阻塞,所以直到数据变的可以读取之前,该线程可以继续做其他的事情。非阻塞的写操作也是如此,一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时是可以去做别的事情的。
NIO 有着三大核心部分:Channel(通道)、Buffer(缓冲区)、Selecot(选择器)Channel:通道。 Java NIO 的通道类似流,但又有一些不同,是既可以从通道中读取数据,又可以写数据到通道里的。但留的(input 或 output)读写通常是单向的。通道可以以非阻塞读取和写入通道,通道可以支持读取或写入缓冲区,也支持异步地读写。
Buffer:缓冲区。缓冲区本质上就是一块可以写入数据,然后可以从中读取数据的内存。这块内存被包装成 NIO Buffer 对象,并提供一组方法,用来方便的访问该块内存。相比较之下对数组的操作。 Buffer API 更加容易操作和管理。
Selecot:选择器。它是 Java NIO 的组件,可以检查一个或多个 NIO 通道,并确定哪些通道已经准备好进行读取或写入。这样一来一个单独的线程就可以管理多个 Channel,从而达到管理多个网络的连接,提高效率。

- 每个 Channel(通道) 都有一个它对应的 Buffer(缓存区)。
- 一个线程对应一个 Selector(选择器),一个 Selector 对应多个 Channel(通道)。
- 程序切换到那个 Channel 是由事件所决定的。
- Selector 会根据不同的事件在在各个通道上进行切换。
- Buffer(缓存区)就是一个内存块,底层是数组
- 数据的读取写入是通过 Buffer 完成的,BIO 中要么是输入流,或者是输出流,是不能双向的,但是 NIO 的 Buffer 即可以读也可以写的。
- Java NIO 系统的核心就是 通道(Channel)和缓存区(Buffer)。通道表示打开到 IO 设备(例如:文件、套接字)的连接。若需要使用 NIO 系统,那么就需要获取用于连接 IO 设备的通道以及用于容纳数据的缓存区,然后对缓存区进行操作以达到对数据的处理。
- 简而言之,Channel 负责传输,Buffer 负责存取数据。
三大核心:Buffer(缓存区)
就是一个用于特定基本数据类型的容器。是由 java.nio 包所定义的。所有具体的缓存区都是 Buffer 抽象类的子类。
Java NIO 中的 Buffer 主要用于与 NIO 的通道进行交互,数据是从通道读物缓存区或者从缓存区写入到通道中的。
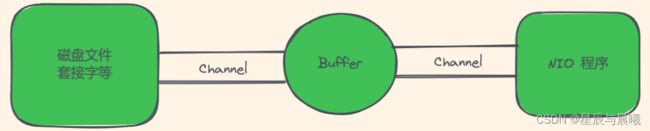
Buffer 就像一个数组,可以保存庽相同类型的数据。根据数据类型的不同,可以分为好几个 Buffer 的子类。(例如:ByteBuffer、CharBuffer、ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer)这些子类都采用了相似的方法进行数据的管理,只是管理的数据类型不同。
缓存区的基本属性
- 容量(capacity):作为一个内存块,Buffer 在初始化的时候就具有一定的固定大小,也称为“容量”,缓存区容量不能为负,并且创建好后就不能再更改了。
- 限制(limit):表示缓存区中可以操作数据的大小,是在容量大小里面动态变化的。在 limit 后的数据是不能再进行读写的。在写入模式下,limit 等于 Buffer 的容量。在读取模式下,limit等于容量里面实际数据的大小。
- 位置(position):表示下一个要读取或写入的数据索引。
- 标记(mark)与重置(reset):标记是一个索引,通过 Buffer 中的 mark() 方法指定 Buffer 中的一个特定的 position ,之后可以通过调用 reset() 方法直接恢复到这个 position。
标记、位置、限制、容量遵守以 T 不变式:0<=mark <=position <=limit <= capacity

Buffer中常见的方法
Buffer clear()清空缓存区并返回对缓存区的引用
Buffer flip()将缓存区的界限设置为当前位置,并将当前 pasition 位置防雨起始读写位置,将limit放与数据结束位置 ,就是改为可读模式
int capacity()返回 Buffer 中的 capacity 大小
boolean hasRemaining()判断缓存区中是否还有元素
int limit()返回 Buffer 的界限(limit)的位置
Buffer limit(int n)将设置缓存区界限为n,并返回一个具有新 limit 的缓存区对象
Buffer mark()对缓存区设置标记
int position()返回缓存区的当前位置position
Buffer position(int n)将设置缓存区的当前位置为n,并返回修改后的Buffer对象
int remaining()返回position和limit之间的元素个数
Buffer reset()将位置position转到以前设置的mark所在的位置
Buffer rewind();将位置设为为 0。取消设置的 mark
Buffer 所有子类提供了两个用于数据操作的方法:get() put()方法
获取 Buffer 中的数据
get():读取单个字节
get (byte[] dst):批量读取多个字节到dst中
get(int index):读取指定索引位置的字节(不会移动position)加入数据到 Buffer 中
put(byte b):将给定单个字节写入缓冲区的当前位置
put (byte[] src):将src中的字节写入缓存区的当前位置
put(int index,byte b)将指定字节写入缓存区的索引位置(不会移动position)
代码演示:
import java.nio.ByteBuffer;
/**
* 目标:对缓存区 Buffer 的常用 API 进行实现
*/
public class Demo01 {
public static void main(String[] args) {
// 分配了一个缓冲区,将容量设置为 10
ByteBuffer buffer = ByteBuffer.allocate(10);
System.out.println("起始位置为:" + buffer.position());//0
System.out.println("限制位置为:" + buffer.limit());//10
System.out.println("缓冲区容量:" + buffer.capacity());//10
System.out.println("---------------------");
// put 方法 往缓冲区里面添加数据
String name = "XiChen";
buffer.put(name.getBytes());
System.out.println("起始位置为:" + buffer.position());//6
System.out.println("限制位置为:" + buffer.limit());//10
System.out.println("缓冲区容量:" + buffer.capacity());//10
System.out.println("---------------------");
// flip 方法是将缓冲区的界限设置为当前位置0 可读模式
buffer.flip();
System.out.println("起始位置为:" + buffer.position());//0
System.out.println("限制位置为:" + buffer.limit());//6
System.out.println("缓冲区容量:" + buffer.capacity());//10
System.out.println("---------------------");
// get 数据的读取
char ch = (char) buffer.get();
System.out.println(ch);
System.out.println("起始位置为:" + buffer.position());//1
System.out.println("限制位置为:" + buffer.limit());//6
System.out.println("缓冲区容量:" + buffer.capacity());//10
System.out.println("---------------------");
// 读取数据
// 定义一个byte数组长为2的数组
byte[] bytes = new byte[2];
buffer.get(bytes);
String s = new String(bytes);
System.out.println(s);
System.out.println("起始位置为:" + buffer.position());//3
System.out.println("限制位置为:" + buffer.limit());//6
System.out.println("缓冲区容量:" + buffer.capacity());//10
System.out.println("---------------------");
// mark 标记此刻读取到的位置
buffer.mark(); // 此处标记的位置是 3
byte[] bs = new byte[2];
buffer.get(bs);
String st = new String(bs);
System.out.println(st);
//hasRemaining 返回 Boolean 值,表示缓存区是否还有数据
if (buffer.hasRemaining()) {
// remaining 返回 int 值,表示缓存区还有多少个数据
System.out.println("剩余元素为:" + buffer.remaining());//1
}
//回到标记位置
buffer.reset();
if (buffer.hasRemaining()) {
System.out.println("剩余元素为:" + buffer.remaining());//3
}
System.out.println("---------------------");
// clear 清除缓存区所有的数据
buffer.clear();
System.out.println("起始位置为:" + buffer.position());//0
System.out.println("限制位置为:" + buffer.limit());//10
System.out.println("缓冲区容量:" + buffer.capacity());//10
// clear 清除数据后,再读取 buffer 里面的数据,还能读取到
System.out.println((char) buffer.get()); // X
// 说明 clear 并不是将数据清除了,而只是改变了索引的指向位置
// 在后面进行添加数据的时候,才会覆盖这写数据
}
}
直接缓存与非直接缓存
根据官方文档,btye Buffer 是可以分为两种类型的,一种是基于直接内存(也就是非堆内存);另一种是非直接内存(也就是堆内存)。
对于直接内存来说,JVM 将会在 IO 操作上具有更高的性能,因为它直接作用于本地系统的 IO 操作;
而非直接内存,也就是堆内存,如果要作 IO 操作,会先从本进程内存复制到直接内存,在利用本地 IO 操作。
从数据流角度来分析来看至直接缓存和非直接缓存
本地 IO ----> 直接内存 — > 本地 IO
本地 IO ---->直接内存 —> 非直接内存—> 直接内存 —> 本地 IO
通过查看数据流,在做 IO 操作的时候,比如 网络发送大量的数据时,直接内存会具有更高的效率。直接内存使用 allocateDirect 创建,但是它比申请普通的堆内存来说是需要消耗更高的性能。不过,在这部分的数据是在 JVM 之外的,因此它不会占用应用的内存。只是一般来说,如果在不能带来很明显的性能提升下,还是推荐直接使用非直接内存模式。
字节缓存区是直接缓存区还是非直接缓存区 可以通过调用 isDirect() 方法来调用。
三大核心:Channel(通道)
通道:由 java.nio.channels 包定义的。 Channel 表示 IO 源与目标打开的连接。Channel 类似于传统的“流”。只不过 Channel 本身是不能直接访问数据的, Channel 只能与 Buffer 进行交互。
● NIO 的通道类似于流,但又有一些区别:
- 通道可以同时进行读写,而流只能读或者只能写。
- 通道可以实现异步读写数据。
- 通道可以从缓冲区读数据,也可以写数据到缓冲区。
● BIO 中的 stream 是单向的,例如 FileInputStream 对象只能进行读取数据的操作,而 NIO 中的通道(Channel)是双向的,可以读操作,也可以写操作。
● Channel 在 NIO 中实际只是一个接口。

常见的实现 Channel 类的子类:
FileChannel:用于读取、写入、映射和操作文件 的通道
DatagramChannel:通过 UDP 来读写网络中的数据通道。
SocketChannel:通过 TCP 来读写网络中的数据通道。
ServerSocketChannel:可以监听新进来的 TCP 连接,对每一个新进来的连接都创建一个 SocketChannel。【ServerSocketChannel类似ServerSocket,SocketChannel类似Socket】。
获取通道
在获取通道的一种方式是对支持通道的对象调用 getChannel() 方法.支持的通道的类都有:
FileInputStream、FileOutputStream、RandomAccessFile、DatagramSocket、Socket、ServerSocket。
获取通道的其他方式是使用 Files 类的静态方法 newByteChannel() 获取字节通道。或通过通道的静态方法 open() 打开并返回指定通道。
FileChannel 通道常用的方法:
● int read(ByteBuffer dst) 从Channel当中读取数据至
● ByteBuffer long read(ByteBuffer[] dsts)将channel当中的数据“分散”至ByteBuffer[]
● int write(Bytesuffer src)将ByteBuffer当中的数据写入到Channel
● long write(ByteBuffer[] srcs)将Bytesuffer[]当中的数据“聚集”到Channel
● long position()返回此通道的文件位置
● FileChannel position(long p)设置此通道的文件位置 long size()返回此通道的文件的当前大小
● FileChannel truncate(long s)将此通道的文件截取为给定大小
● void force(boolean metaData)强制将所有对此通道的文件更新写入到存储设备中
代码演示:
写入数据:
import java.io.FileOutputStream;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
public class Demo02 {
public static void main(String[] args) {
try {
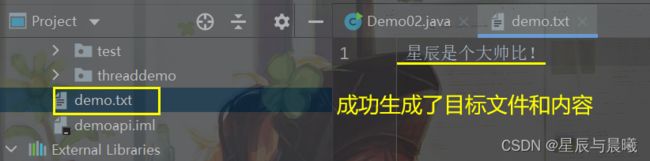
//1.字节输出流通向目标文件
FileOutputStream fos = new FileOutputStream("demo.txt");
//2.得到字节输出流对应的通道Channel
FileChannel channel = fos.getChannel();
//3.分配缓存区
ByteBuffer buffer = ByteBuffer.allocate(1024);
buffer.put("星辰是个大帅比!".getBytes());
//4.把缓存区切换为写模式
buffer.flip();
// 通过通道写入缓存区的数据
channel.write(buffer);
// 关闭通道
channel.close();
System.out.println("写数据到文件中!");
} catch (Exception e) {
e.printStackTrace();
}
}
}
成功生成了这个文档:
读取数据:
import java.io.FileInputStream;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
public class Demo03 {
public static void main(String[] args) {
try {
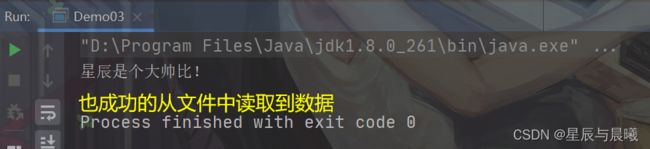
// 定义一个文件字节输入流与源文件接通
FileInputStream inputStream = new FileInputStream("demo.txt");
// 需要得到文件字节输入流的文件通道
FileChannel channel = inputStream.getChannel();
// 定义一个缓存区
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 读取数据到缓存区
channel.read(buffer);
// buffer.flip();//归位
// 读取出缓存区中的数据并输出即可
String string = new String(buffer.array());
//String string = new String(buffer.array(),0,buffer.remaining());
System.out.println(string);
} catch (Exception e) {
e.printStackTrace();
}
}
}
三大核心:Selector(选择器)
选择器(Selector)是 SelectableChannle 对象的多路复用器,Selector 是可以同时监控多个 SelectorChannel 的 IO 状况,也就是说,利用 Selector 可使一个单独的线程管理多个 Channel 。
Selector 是非阻塞 IO 的核心。

Java 的 NIO ,用非阻塞的 IO 方式,可以用一个线程,处理多个的客户端连接,就会使用到的 Selector (选择器)
Selector 能够坚持到多个注册的通道上若有事件发生(注意:多个Channel 以事件的方式可以注册到同一个 Select() ,如果有事件发生,便获取事件后然后针对每个事件进行相应的处理。这样就可以只用一个单线程去管理多个通道,也就是管理多个连接和请求。)
只有在连接/通道 真正有读写事件发生的时候,才会进行读写,就大大减少了系统的开销,并且不必为每个连接都创建一个线程,不用于维护多个线程,避免了多线程之间的上下文导致的开销。
选择器的应用
创建 Selector:通过 Selector.open() 方法创建出一个 Selector。
Selector selector = Selector.open();
向选择器注册通道:SelectableChannle.register(Selector sel,int ops);
//1.获取通道
ServerSocketChannel socketChannel = ServerSocketChannel.open();
//2.切换非阻塞模式
socketChannel.configureBlocking(false);
// 3.绑定连接
socketChannel.bind(new InetSocketAddress(9898));
// 4.获取选择器
socketChannel selector = Selector.open();
// 5.将通道注册到选择器上,并且指定“监听接收事件”
socketChannel.register(select,SelectionKey.OP_ACCEPT);
当调用register(Selector sel, mt ops)将通道注册选择器时,选择器对通道的监听事件,需要通过第二个参数。ops指定。可以监听的事件类型(用可使用Selection Key的四个常量表示):
读:SelectionKey.OP_READ (1)
写:SelectionKey.OP_WRITE (4)
连接:SelectionKey.OP_CONNECT (8)
接收:SelectionKey.OP_ACCEPT (16)
若注册时不止监听一个事件,则可以使用‘位或”操作符连接
int interestSet = selectionKey.OP_READ | SelectionKey.OP_WERITE
AIO
Java AIO (也叫做NIO.2):异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的 I/O 请求都是由 OS 先完成了再通知服务器应用去启动线程进行处理。
AIO是异步非阻塞,基于NIO,所以也将其称之为NIO2.0。
| BIO | NIO | AIO |
|---|---|---|
| Socket | SocketChannel | AsynchronousSocketChannel |
| ServerSocket | ServerSocketChannel | AsynchronousServerSocketChannel |
与 NIO 不同的是,当 AIO 进行读写操作时,只须直接调用 API 的 read 或 write 方法即可,这两种方法均为异步的,对于读操作而言,当有流可读的时候,操作系统会将可读的流传入 read 方法的缓冲区,对于写操作而言,当操作系统将 write 方法传递的流写入完毕时,操作系统主动通知应用程序。
即可以理解为,read/write 方法都是异步的,完成后会主动调用回调函数。在JDK1.7中,这部分内容被称作 NIO.2,主要在java.nio.channel包下增加了下面四个异步通道:
AsynchronousSocketChannel
AsynchronousServerSocketChannel
AsynchronousFileChannel
AsynchronousDatagramChannel
BIO、NIO、AIO总结
BIO:同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动 一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
BlO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中, JDK1.4以前的唯一选择,但程序直观简单易理解。
NIO:同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较 复杂,JDK1 .4开始支持。
AIO:异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由 OS 先完成了再通知服务器应用去启动线程进行处理。
AlO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编 程比较复杂,JDK7开始支持。
本篇写的也比较多,有出入的地方,欢迎大家在评论区讨论。嘿嘿
番篇:===》 操作系统的中的 IO