Pytorch:卷积神经网络-GoogLeNet
Pytorch: 含并行连结的网络-GoogLeNet
Copyright: Jingmin Wei, Pattern Recognition and Intelligent System, School of Artificial and Intelligence, Huazhong University of Science and Technology
Pytorch教程专栏链接
文章目录
-
-
- Pytorch: 含并行连结的网络-GoogLeNet
- @[toc]
-
-
- Reference
- 纵横交错:GoogLeNet(Inception)
- 从 NiN 开始
- Inception-V1 网络基本结构
-
- 主要贡献
- 动机
- Inception 块与并行连接
- 核心理论
- 网络结构
- 总结
- 代码实现
-
- 构建一个Inception类
- 构建GooLeNet,将多个Inception Block连接起来
- Inception-V2 网络(BN-Inception)
- Inception-V3 网络
- Inception-V4 网络
文章目录
-
-
- Pytorch: 含并行连结的网络-GoogLeNet
- @[toc]
-
-
- Reference
- 纵横交错:GoogLeNet(Inception)
- 从 NiN 开始
- Inception-V1 网络基本结构
-
- 主要贡献
- 动机
- Inception 块与并行连接
- 核心理论
- 网络结构
- 总结
- 代码实现
-
- 构建一个Inception类
- 构建GooLeNet,将多个Inception Block连接起来
- Inception-V2 网络(BN-Inception)
- Inception-V3 网络
- Inception-V4 网络
-
-
本教程不商用,仅供学习和参考交流使用,如需转载,请联系本人。
Reference
Inception V1 论文链接
Inception V2 论文链接
Inception V3 论文链接
Inception V4 论文链接
import torch
import torch.nn as nn
纵横交错:GoogLeNet(Inception)
在 2014 年的 ImageNet 图像识别挑战赛中,一个名叫 GoogLeNet 的网络结构大放异彩。它虽然在名字上向 LeNet 致敬,但在网络结构上已经很难看到 LeNet 的影子。GoogLeNe t吸收了 NiN 中网络串联网络的思想,并在此基础上做了很大改进。在随后的几年里,研究人员对 GoogLeNet 进行了数次改进,本节将介绍这个模型系列的三个版本 Inception-V1, V2, V3。
从 NiN 开始
前言(网络中的网络 NiN :串联多个由卷积层和“全连接”层构成的小网络来构建一个深层网络):
NiN 块:将微型 mlp 结构引入 conv 来提取更加复杂的特征。
1 × 1 1\times 1 1×1 卷积层。它可以看成全连接层,其中空间维度(高和宽)上的每个元素相当于样本,通道相当于特征。因此,NiN 使用 1 × 1 1\times 1 1×1 卷积层来替代全连接层,从而使空间信息能够自然传递到后面的层中去。
Reference: Inception-V1: Going Deeper with Convolutions
The main hallmark of this architecture is the improved utilization of the computing resources inside the network. By a carefully crafted design, we increased the depth and width of the network while keeping the computational budget constant. To optimize quality, the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing.
Inception-V1 网络基本结构
主要贡献
在保证算力要求不变的前提下,增加网络深度和广度。
基于 Hebbian 原则和多尺度处理直觉来优化网络的质量。
提出了并行连接的 Inception 块,借鉴 NiN 的思想,添加 1 × 1 1\times1 1×1 卷积优化了 Inception 块。
使用平均池化层( GAP )代替全连接层,减少参数。
输出了一个辅助的 softmax ,可以增强低层网络的判别能力,增强反向传播的梯度的大小,提供额外的正则化能力。
动机
一是更深的网络意味着会有更多的参数,这样很容易导致过拟合;二是更深的网络会带来更多计算上的开支,减缓训练周期。而参数又主要集中在全连接层,于是就想到了用稀疏连接来取代全连接层的方法,是解决这两个问题的关键。
Inception 块与并行连接
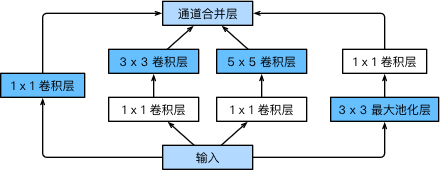
GoogLeNet 中的基础卷积块叫作 Inception 块,得名于同名电影《盗梦空间》(Inception)。与上一节介绍的 NiN 块相比,这个基础块在结构上更加复杂,如图所示。
优化后的 Inception 块里有 4 4 4 条并行的线路。前 3 3 3 条线路使用窗口大小分别是 1 × 1 1\times 1 1×1、 3 × 3 3\times 3 3×3 和 5 × 5 5\times 5 5×5 的卷积层来抽取不同空间尺寸下的信息,其中中间 2 2 2 个线路会对输入先做 1 × 1 1\times 1 1×1 卷积来减少输入通道数,以降低模型复杂度。第四条线路则使用 3 × 3 3\times 3 3×3 最大池化层,后接 1 × 1 1\times 1 1×1 卷积层来改变通道数。 4 4 4 条线路都使用了合适的填充来使输入与输出的高和宽一致。最后我们将每条线路的输出在通道维上连结,并输入接下来的层中去。
Inception 块相当于一个有 4 4 4 条线路的子网络。它通过不同窗口形状的卷积层和最大池化层来并行抽取信息,并使用 1 × 1 1\times 1 1×1 卷积层减少通道数从而降低模型复杂度( NiN 的思想)。值得一提的是,使用 1 × 1 1\times1 1×1 模块对特征图进行降维的思想,在一些轻量网络中也会用到。
Inception 块中可以自定义的超参数是每个层的输出通道数,我们以此来控制模型复杂度。
核心理论
通过加宽网络来使网络更深。
1.赫布学习理论: 两个神经元处于激发状态时,它们之间的连接强度将得到加强。
w i j ( k + 1 ) = w i j ( k ) + α I i I j 其 中 , 神 经 元 激 活 水 平 : I i = ( x i ( n ) − x ‾ i ) , I j = ( x j ( n ) − x ‾ j ) x ‾ i , x ‾ j 为 神 经 元 i , j 在 一 段 时 间 内 的 平 均 值 \begin{aligned} &w_{ij}(k+1)=w_{ij}(k)+\alpha I_iI_j\\ &其中,神经元激活水平:\\ &I_i=(x_i(n)-\overline{x}_i),\ I_j=(x_j(n)-\overline{x}_j)\\ &\overline{x}_i,\overline{x}_j为神经元i,j在一段时间内的平均值 \end{aligned} wij(k+1)=wij(k)+αIiIj其中,神经元激活水平:Ii=(xi(n)−xi), Ij=(xj(n)−xj)xi,xj为神经元i,j在一段时间内的平均值
Their main result states that if the probability distribution of the dataset is representable by a large, very sparse deep neural network, then the optimal network topology can be constructed layer after layer by analyzing the correlation statistics of the preceding layer activations and clustering neurons with highly correlated outputs. Although the strict mathematical proof requires very strong conditions, the fact that this statement resonates with the well known Hebbian principle – neurons that fire together, wire together – suggests that the underlying idea is applicable even under less strict conditions, in practice.
2.视觉的多尺度处理直觉: 视觉信息应该在不同的尺度上进行处理,然后进行聚合,以便下一阶段可以同时从不同的尺度上提取特征。
A useful aspect of this architecture is that it allows for increasing the number of units at each stage significantly without an uncontrolled blow-up in computational complexity at later stages. This is achieved by the ubiquitous use of dimensionality reduction prior to expensive convolutions with larger patch sizes. Furthermore, the design follows the practical intuition that visual information should be processed at various scales and then aggregated so that the next stage can abstract features from the different scales simultaneously.
网络结构
Inception V1 一共有 9 9 9 个 Inception 块,一共 22 22 22 层网络,最后的 Inception 模块使用了 torch.nn 教程中提到的 Global Average Pooling 全局平均池化来代替。
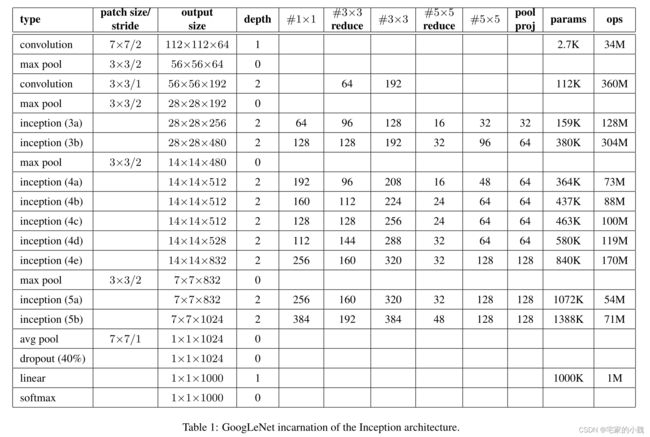
为了避免梯度消失,作者还引入了两个辅助的分类器。在第 3 3 3 个和第 6 6 6 个 Inception 模块后执行 Softmax 并计算损失,在训练时和最后的损失一并回传。
总结
1.使用并行连接 Inception ,将卷积层换成更稀疏的连接方式可以降低参数数量。
2.使用平均池化层(GAP)代替全连接层, t o p − 1 top-1 top−1 准确率有 0.6 % 0.6\% 0.6% 的提升,虽然移除了全连接层,但还是在 GAP 后使用了 dropout ;
3.网络的中间部位还输出了一个辅助的 softmax ,可以增强低层网络的判别能力,增强反向传播的梯度的大小,提供额外的正则化能力。
训练过程中,损失值是最后层的 softmax loss 加 0.3 × 0.3\times 0.3× 中间输出的 softmax loss 。
测试过程时,忽略中间的这个 softmax 输出。
相比 VGG , GoogLeNet 拥有更深的网络结构和更少的参数(\frac{1}{12})和计算量,主要归功于在卷积网络中大量使用了 1 × 1 1\times1 1×1 卷积,以及用 Gobal Average Pooling 取代了传统网络架构中的全连接层 FCN 。
代码实现
GoogLeNet 跟 VGG 一样,在主体卷积部分中使用 5 5 5 个模块(block),每个模块之间使用步幅为 2 2 2 的 3 × 3 3×3 3×3 最大池化层来减小输出高宽。第一模块使用一个64通道的 7 × 7 7×7 7×7 卷积层。
第二模块使用 2 2 2 个卷积层:首先是 64 64 64 通道的 1 × 1 1×1 1×1 卷积层,然后是将通道增大 3 3 3 倍的 3 × 3 3×3 3×3 卷积层。它对应 Inception 块中的第二条线路。
第三模块串联 2 2 2 个完整的 Inception 块。第一个 Inception 块的输出通道数为 64 + 128 + 32 + 32 = 256 64+128+32+32=256 64+128+32+32=256 ,其中 4 4 4 条线路的输出通道数比例为 64 : 128 : 32 : 32 = 2 : 4 : 1 : 1 64:128:32:32=2:4:1:1 64:128:32:32=2:4:1:1 。其中第二、第三条线路先分别将输入通道数减小至 96 / 192 = 1 / 2 96/192=1/2 96/192=1/2 和 16 / 192 = 1 / 12 16/192=1/12 16/192=1/12 后,再接上第二层卷积层。第二个Inception块输出通道数增至 128 + 192 + 96 + 64 = 480 128+192+96+64=480 128+192+96+64=480 ,每条线路的输出通道数之比为 128 : 192 : 96 : 64 = 4 : 6 : 3 : 2 128:192:96:64=4:6:3:2 128:192:96:64=4:6:3:2 。其中第二、第三条线路先分别将输入通道数减小至 128 / 256 = 1 / 2 128/256=1/2 128/256=1/2 和 32 / 256 = 1 / 8 32/256=1/8 32/256=1/8 。
第四模块更加复杂。它串联了 5 5 5 个 Inception 块,其输出通道数分别是 192 + 208 + 48 + 64 = 512 192+208+48+64=512 192+208+48+64=512 、 160 + 224 + 64 + 64 = 512 160+224+64+64=512 160+224+64+64=512 、 128 + 256 + 64 + 64 = 512 128+256+64+64=512 128+256+64+64=512、 112 + 288 + 64 + 64 = 528 112+288+64+64=528 112+288+64+64=528 和 256 + 320 + 128 + 128 = 832 256+320+128+128=832 256+320+128+128=832 。这些线路的通道数分配和第三模块中的类似,首先含 3 × 3 3×3 3×3 卷积层的第二条线路输出最多通道,其次是仅含 1 × 1 1×1 1×1 卷积层的第一条线路,之后是含 5 × 5 5×5 5×5 卷积层的第三条线路和含 3 × 3 3×3 3×3 最大池化层的第四条线路。其中第二、第三条线路都会先按比例减小通道数。这些比例在各个 Inception 块中都略有不同。
第五模块有输出通道数为 256 + 320 + 128 + 128 = 832 256+320+128+128=832 256+320+128+128=832 和 384 + 384 + 128 + 128 = 1024 384+384+128+128=1024 384+384+128+128=1024 的两个 Inception 块。其中每条线路的通道数的分配思路和第三、第四模块中的一致,只是在具体数值上有所不同。需要注意的是,第五模块的后面紧跟输出层,该模块同 NiN 一样使用全局平均池化层来将每个通道的高和宽变成1。最后我们将输出变成二维数组后接上一个输出个数为标签类别数的全连接层。
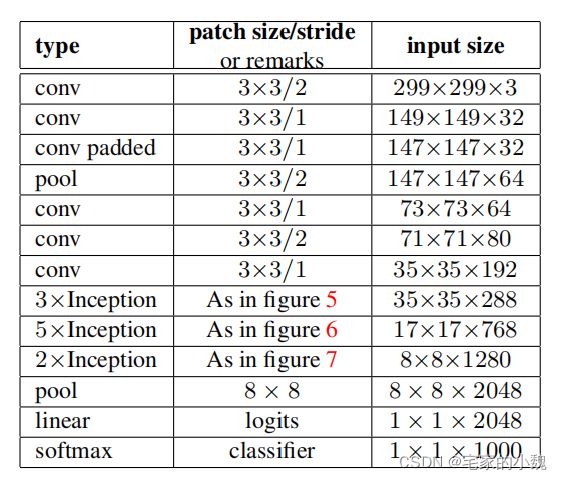
GoogLeNet 模型的计算复杂,而且不如 VGG 那样便于修改通道数。本节里我们将输入的高和宽从 224 224 224 降到 96 96 96 来简化计算。下面演示各个模块之间的输出的形状变化。
构建一个Inception类
# 定义一个包含conv和ReLU的基础卷积类
class conv_relu(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(conv_relu, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride=stride, padding=padding)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
output = self.relu(x)
return output
# 定义Inception-V1类
# 模块分为四个部分,1*1卷积; 1*1卷积+3*3卷积; 1*1卷积+5*5卷积; 3*3最大池化+1*1卷积
class InceptionV1(nn.Module):
def __init__(self, in_channels, hid_1_1, hid_2_1, hid_2_3, hid_3_1, out_3_5, out_4_1):
super(InceptionV1, self).__init__()
# 分别定义这四个模块
self.branch1x1 = conv_relu(in_channels, hid_1_1, 1) # 1*1卷积
self.branch3x3 = nn.Sequential(
conv_relu(in_channels, hid_2_1, 1), # 1*1卷积
conv_relu(hid_2_1, hid_2_3, 3, padding=1) # 3*3卷积
)
self.branch5x5 = nn.Sequential(
conv_relu(in_channels, hid_3_1, 1), # 1*1卷积
conv_relu(hid_3_1, out_3_5, 5, padding=2) # 5*5卷积
)
self.branch_pool = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1), # 池化后D2=D1
conv_relu(in_channels, out_4_1, 1) # 1*1卷积
)
def forward(self, x):
b1 = self.branch1x1(x)
b2 = self.branch3x3(x)
b3 = self.branch5x5(x)
b4 = self.branch_pool(x)
# 沿通道方向并行连接
output = torch.cat((b1, b2, b3, b4), dim=1)
return output
# 测试上述模块
my_inception = InceptionV1(3, 64, 32, 64, 64, 96, 32).cuda()
# 测试输入输出
input = torch.randn(1, 3, 256, 256).cuda()
output = my_inception(input)
output.shape
torch.Size([1, 256, 256, 256])
from torchsummary import summary
# D*W*H (D=in_channels=3)
summary(my_inception, input_size=(3, 256, 256))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 256, 256] 256
ReLU-2 [-1, 64, 256, 256] 0
conv_relu-3 [-1, 64, 256, 256] 0
Conv2d-4 [-1, 32, 256, 256] 128
ReLU-5 [-1, 32, 256, 256] 0
conv_relu-6 [-1, 32, 256, 256] 0
Conv2d-7 [-1, 64, 256, 256] 18,496
ReLU-8 [-1, 64, 256, 256] 0
conv_relu-9 [-1, 64, 256, 256] 0
Conv2d-10 [-1, 64, 256, 256] 256
ReLU-11 [-1, 64, 256, 256] 0
conv_relu-12 [-1, 64, 256, 256] 0
Conv2d-13 [-1, 96, 256, 256] 153,696
ReLU-14 [-1, 96, 256, 256] 0
conv_relu-15 [-1, 96, 256, 256] 0
MaxPool2d-16 [-1, 3, 256, 256] 0
Conv2d-17 [-1, 32, 256, 256] 128
ReLU-18 [-1, 32, 256, 256] 0
conv_relu-19 [-1, 32, 256, 256] 0
================================================================
Total params: 172,960
Trainable params: 172,960
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.75
Forward/backward pass size (MB): 529.50
Params size (MB): 0.66
Estimated Total Size (MB): 530.91
----------------------------------------------------------------
构建GooLeNet,将多个Inception Block连接起来

# 定义一个googlenet网络类,让很多个inception从串联起来
class GooLeNet(nn.Module):
def __init__(self, in_channels, num_classes, verbose=False):
super(GooLeNet, self).__init__()
self.verbose = verbose
self.block1 = nn.Sequential(
conv_relu(in_channels, out_channels=64, kernel_size=7, stride=2, padding=3),
nn.MaxPool2d(kernel_size=3, stride=2)
)
self.block2 = nn.Sequential(
conv_relu(64, 192, 3, 1, 1),
nn.MaxPool2d(3, 2)
)
self.block3 = nn.Sequential(
InceptionV1(192, 64, 96, 128, 16, 32, 32),
InceptionV1(256, 128, 128, 192, 32, 96, 64),
nn.MaxPool2d(3, 2)
)
self.block4 = nn.Sequential(
InceptionV1(480, 192, 96, 208, 16, 48, 64),
InceptionV1(512, 160, 112, 224, 24, 64, 64),
InceptionV1(512, 128, 128, 256, 24, 64, 64),
InceptionV1(512, 112, 144, 288, 32, 64, 64),
InceptionV1(528, 256, 160, 320, 32, 128, 128),
nn.MaxPool2d(3, 2)
)
self.block5 = nn.Sequential(
InceptionV1(832, 256, 160, 320, 32, 128, 128),
InceptionV1(832, 384, 182, 384, 48, 128, 128)
)
self.block6 = nn.Sequential(
nn.AvgPool2d(7, 1), # 全局池化
nn.Dropout(p=0.4),
)
self.classifier = nn.Sequential(
nn.Linear(1024, num_classes),
nn.Softmax(dim=1)
)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = self.block6(x)
x = x.view(x.shape[0], -1)
output = self.classifier(x)
return output
mygooglenet = GooLeNet(3, 1000)
from torchsummary import summary
# 输入 D*W*H=3*256*256
summary(mygooglenet, input_size=(3, 256, 256), device = 'cpu')
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 128, 128] 9,472
ReLU-2 [-1, 64, 128, 128] 0
conv_relu-3 [-1, 64, 128, 128] 0
MaxPool2d-4 [-1, 64, 63, 63] 0
Conv2d-5 [-1, 192, 63, 63] 110,784
ReLU-6 [-1, 192, 63, 63] 0
conv_relu-7 [-1, 192, 63, 63] 0
MaxPool2d-8 [-1, 192, 31, 31] 0
Conv2d-9 [-1, 64, 31, 31] 12,352
ReLU-10 [-1, 64, 31, 31] 0
conv_relu-11 [-1, 64, 31, 31] 0
Conv2d-12 [-1, 96, 31, 31] 18,528
ReLU-13 [-1, 96, 31, 31] 0
conv_relu-14 [-1, 96, 31, 31] 0
Conv2d-15 [-1, 128, 31, 31] 110,720
ReLU-16 [-1, 128, 31, 31] 0
conv_relu-17 [-1, 128, 31, 31] 0
Conv2d-18 [-1, 16, 31, 31] 3,088
ReLU-19 [-1, 16, 31, 31] 0
conv_relu-20 [-1, 16, 31, 31] 0
Conv2d-21 [-1, 32, 31, 31] 12,832
ReLU-22 [-1, 32, 31, 31] 0
conv_relu-23 [-1, 32, 31, 31] 0
MaxPool2d-24 [-1, 192, 31, 31] 0
Conv2d-25 [-1, 32, 31, 31] 6,176
ReLU-26 [-1, 32, 31, 31] 0
conv_relu-27 [-1, 32, 31, 31] 0
InceptionV1-28 [-1, 256, 31, 31] 0
Conv2d-29 [-1, 128, 31, 31] 32,896
ReLU-30 [-1, 128, 31, 31] 0
conv_relu-31 [-1, 128, 31, 31] 0
Conv2d-32 [-1, 128, 31, 31] 32,896
ReLU-33 [-1, 128, 31, 31] 0
conv_relu-34 [-1, 128, 31, 31] 0
Conv2d-35 [-1, 192, 31, 31] 221,376
ReLU-36 [-1, 192, 31, 31] 0
conv_relu-37 [-1, 192, 31, 31] 0
Conv2d-38 [-1, 32, 31, 31] 8,224
ReLU-39 [-1, 32, 31, 31] 0
conv_relu-40 [-1, 32, 31, 31] 0
Conv2d-41 [-1, 96, 31, 31] 76,896
ReLU-42 [-1, 96, 31, 31] 0
conv_relu-43 [-1, 96, 31, 31] 0
MaxPool2d-44 [-1, 256, 31, 31] 0
Conv2d-45 [-1, 64, 31, 31] 16,448
ReLU-46 [-1, 64, 31, 31] 0
conv_relu-47 [-1, 64, 31, 31] 0
InceptionV1-48 [-1, 480, 31, 31] 0
MaxPool2d-49 [-1, 480, 15, 15] 0
Conv2d-50 [-1, 192, 15, 15] 92,352
ReLU-51 [-1, 192, 15, 15] 0
conv_relu-52 [-1, 192, 15, 15] 0
Conv2d-53 [-1, 96, 15, 15] 46,176
ReLU-54 [-1, 96, 15, 15] 0
conv_relu-55 [-1, 96, 15, 15] 0
Conv2d-56 [-1, 208, 15, 15] 179,920
ReLU-57 [-1, 208, 15, 15] 0
conv_relu-58 [-1, 208, 15, 15] 0
Conv2d-59 [-1, 16, 15, 15] 7,696
ReLU-60 [-1, 16, 15, 15] 0
conv_relu-61 [-1, 16, 15, 15] 0
Conv2d-62 [-1, 48, 15, 15] 19,248
ReLU-63 [-1, 48, 15, 15] 0
conv_relu-64 [-1, 48, 15, 15] 0
MaxPool2d-65 [-1, 480, 15, 15] 0
Conv2d-66 [-1, 64, 15, 15] 30,784
ReLU-67 [-1, 64, 15, 15] 0
conv_relu-68 [-1, 64, 15, 15] 0
InceptionV1-69 [-1, 512, 15, 15] 0
Conv2d-70 [-1, 160, 15, 15] 82,080
ReLU-71 [-1, 160, 15, 15] 0
conv_relu-72 [-1, 160, 15, 15] 0
Conv2d-73 [-1, 112, 15, 15] 57,456
ReLU-74 [-1, 112, 15, 15] 0
conv_relu-75 [-1, 112, 15, 15] 0
Conv2d-76 [-1, 224, 15, 15] 226,016
ReLU-77 [-1, 224, 15, 15] 0
conv_relu-78 [-1, 224, 15, 15] 0
Conv2d-79 [-1, 24, 15, 15] 12,312
ReLU-80 [-1, 24, 15, 15] 0
conv_relu-81 [-1, 24, 15, 15] 0
Conv2d-82 [-1, 64, 15, 15] 38,464
ReLU-83 [-1, 64, 15, 15] 0
conv_relu-84 [-1, 64, 15, 15] 0
MaxPool2d-85 [-1, 512, 15, 15] 0
Conv2d-86 [-1, 64, 15, 15] 32,832
ReLU-87 [-1, 64, 15, 15] 0
conv_relu-88 [-1, 64, 15, 15] 0
InceptionV1-89 [-1, 512, 15, 15] 0
Conv2d-90 [-1, 128, 15, 15] 65,664
ReLU-91 [-1, 128, 15, 15] 0
conv_relu-92 [-1, 128, 15, 15] 0
Conv2d-93 [-1, 128, 15, 15] 65,664
ReLU-94 [-1, 128, 15, 15] 0
conv_relu-95 [-1, 128, 15, 15] 0
Conv2d-96 [-1, 256, 15, 15] 295,168
ReLU-97 [-1, 256, 15, 15] 0
conv_relu-98 [-1, 256, 15, 15] 0
Conv2d-99 [-1, 24, 15, 15] 12,312
ReLU-100 [-1, 24, 15, 15] 0
conv_relu-101 [-1, 24, 15, 15] 0
Conv2d-102 [-1, 64, 15, 15] 38,464
ReLU-103 [-1, 64, 15, 15] 0
conv_relu-104 [-1, 64, 15, 15] 0
MaxPool2d-105 [-1, 512, 15, 15] 0
Conv2d-106 [-1, 64, 15, 15] 32,832
ReLU-107 [-1, 64, 15, 15] 0
conv_relu-108 [-1, 64, 15, 15] 0
InceptionV1-109 [-1, 512, 15, 15] 0
Conv2d-110 [-1, 112, 15, 15] 57,456
ReLU-111 [-1, 112, 15, 15] 0
conv_relu-112 [-1, 112, 15, 15] 0
Conv2d-113 [-1, 144, 15, 15] 73,872
ReLU-114 [-1, 144, 15, 15] 0
conv_relu-115 [-1, 144, 15, 15] 0
Conv2d-116 [-1, 288, 15, 15] 373,536
ReLU-117 [-1, 288, 15, 15] 0
conv_relu-118 [-1, 288, 15, 15] 0
Conv2d-119 [-1, 32, 15, 15] 16,416
ReLU-120 [-1, 32, 15, 15] 0
conv_relu-121 [-1, 32, 15, 15] 0
Conv2d-122 [-1, 64, 15, 15] 51,264
ReLU-123 [-1, 64, 15, 15] 0
conv_relu-124 [-1, 64, 15, 15] 0
MaxPool2d-125 [-1, 512, 15, 15] 0
Conv2d-126 [-1, 64, 15, 15] 32,832
ReLU-127 [-1, 64, 15, 15] 0
conv_relu-128 [-1, 64, 15, 15] 0
InceptionV1-129 [-1, 528, 15, 15] 0
Conv2d-130 [-1, 256, 15, 15] 135,424
ReLU-131 [-1, 256, 15, 15] 0
conv_relu-132 [-1, 256, 15, 15] 0
Conv2d-133 [-1, 160, 15, 15] 84,640
ReLU-134 [-1, 160, 15, 15] 0
conv_relu-135 [-1, 160, 15, 15] 0
Conv2d-136 [-1, 320, 15, 15] 461,120
ReLU-137 [-1, 320, 15, 15] 0
conv_relu-138 [-1, 320, 15, 15] 0
Conv2d-139 [-1, 32, 15, 15] 16,928
ReLU-140 [-1, 32, 15, 15] 0
conv_relu-141 [-1, 32, 15, 15] 0
Conv2d-142 [-1, 128, 15, 15] 102,528
ReLU-143 [-1, 128, 15, 15] 0
conv_relu-144 [-1, 128, 15, 15] 0
MaxPool2d-145 [-1, 528, 15, 15] 0
Conv2d-146 [-1, 128, 15, 15] 67,712
ReLU-147 [-1, 128, 15, 15] 0
conv_relu-148 [-1, 128, 15, 15] 0
InceptionV1-149 [-1, 832, 15, 15] 0
MaxPool2d-150 [-1, 832, 7, 7] 0
Conv2d-151 [-1, 256, 7, 7] 213,248
ReLU-152 [-1, 256, 7, 7] 0
conv_relu-153 [-1, 256, 7, 7] 0
Conv2d-154 [-1, 160, 7, 7] 133,280
ReLU-155 [-1, 160, 7, 7] 0
conv_relu-156 [-1, 160, 7, 7] 0
Conv2d-157 [-1, 320, 7, 7] 461,120
ReLU-158 [-1, 320, 7, 7] 0
conv_relu-159 [-1, 320, 7, 7] 0
Conv2d-160 [-1, 32, 7, 7] 26,656
ReLU-161 [-1, 32, 7, 7] 0
conv_relu-162 [-1, 32, 7, 7] 0
Conv2d-163 [-1, 128, 7, 7] 102,528
ReLU-164 [-1, 128, 7, 7] 0
conv_relu-165 [-1, 128, 7, 7] 0
MaxPool2d-166 [-1, 832, 7, 7] 0
Conv2d-167 [-1, 128, 7, 7] 106,624
ReLU-168 [-1, 128, 7, 7] 0
conv_relu-169 [-1, 128, 7, 7] 0
InceptionV1-170 [-1, 832, 7, 7] 0
Conv2d-171 [-1, 384, 7, 7] 319,872
ReLU-172 [-1, 384, 7, 7] 0
conv_relu-173 [-1, 384, 7, 7] 0
Conv2d-174 [-1, 182, 7, 7] 151,606
ReLU-175 [-1, 182, 7, 7] 0
conv_relu-176 [-1, 182, 7, 7] 0
Conv2d-177 [-1, 384, 7, 7] 629,376
ReLU-178 [-1, 384, 7, 7] 0
conv_relu-179 [-1, 384, 7, 7] 0
Conv2d-180 [-1, 48, 7, 7] 39,984
ReLU-181 [-1, 48, 7, 7] 0
conv_relu-182 [-1, 48, 7, 7] 0
Conv2d-183 [-1, 128, 7, 7] 153,728
ReLU-184 [-1, 128, 7, 7] 0
conv_relu-185 [-1, 128, 7, 7] 0
MaxPool2d-186 [-1, 832, 7, 7] 0
Conv2d-187 [-1, 128, 7, 7] 106,624
ReLU-188 [-1, 128, 7, 7] 0
conv_relu-189 [-1, 128, 7, 7] 0
InceptionV1-190 [-1, 1024, 7, 7] 0
AvgPool2d-191 [-1, 1024, 1, 1] 0
Dropout-192 [-1, 1024, 1, 1] 0
Linear-193 [-1, 1000] 1,025,000
Softmax-194 [-1, 1000] 0
================================================================
Total params: 6,951,502
Trainable params: 6,951,502
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.75
Forward/backward pass size (MB): 108.88
Params size (MB): 26.52
Estimated Total Size (MB): 136.15
----------------------------------------------------------------
# 模型加载选择
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = torch.device('cpu')
print(device)
# print(torch.cuda.device_count())
# print(torch.cuda.get_device_name(0))
cpu
from torchviz import make_dot
x = torch.randn(1, 3, 256, 256).requires_grad_(True)
y = mygooglenet(x.to(device))
myCNN_vis = make_dot(y, params=dict(list(mygooglenet.named_parameters()) + [('x', x)]))
myCNN_vis.render('google_model', view=False) # 会自动保存为一个 espnet.pdf,第二个参数为True,则会自动打开该PDF文件,为False则不打开
myCNN_vis
Inception-V2 网络(BN-Inception)
主要贡献为,通过卷积分解和正则化实现了更高效的运算,且提出了 Batch Normalization 层(第二篇论文)。
在 Inception V1 块的基础上,每一个 branch 都增加了 BN 层。
详细的 BN 层参见 torch.nn 章节。

Inception-V3 网络
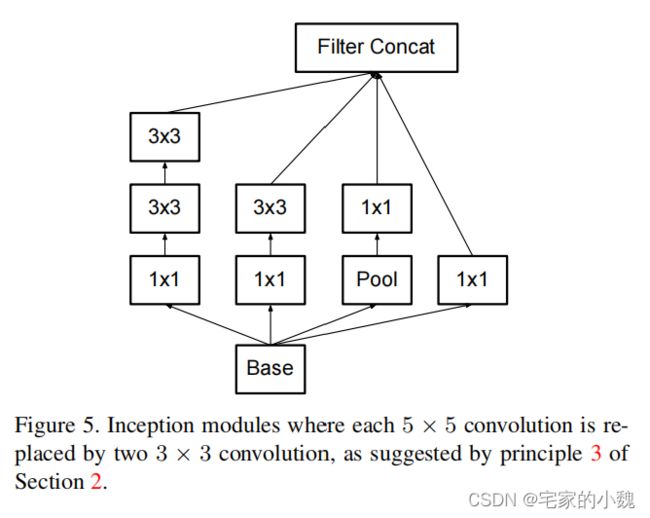
它主要修改了 Inception 的结构,比如说,利用两个级联的 3 × 3 3\times3 3×3 的卷积取代了 Inception-V1 中的 5 × 5 5\times5 5×5 卷积,减少了卷积参数,增加了网络的非线性能力(第三篇论文)。
# 定义一个包含conv, BN和ReLU的基础卷积类
class conv_BN_relu(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(conv_BN_relu, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride=stride, padding=padding)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001) # eps为公式里的epsilon参数
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
output = self.relu(x)
return output
# 定义Inception-V3的第1种block
# 模块分为四个部分,1*1卷积; 1*1卷积+3*3卷积; 1*1卷积+3*3卷积+3*3卷积; 3*3平均池化+1*1卷积
class InceptionV3_1(nn.Module):
def __init__(self, in_channels, hid_1_1=96, hid_2_1=48, hid_2_3=64, hid_3_1=64, hid_3_3=96, out_3_3=96, out_4_1=64):
super(InceptionV3_1, self).__init__()
# 分别定义这四个模块
self.branch1 = conv_BN_relu(in_channels, hid_1_1, 1) # 1*1卷积
self.branch2 = nn.Sequential(
conv_BN_relu(in_channels, hid_2_1, 1), # 1*1卷积
conv_BN_relu(hid_2_1, hid_2_3, 3, padding=1) # 3*3卷积
)
self.branch3 = nn.Sequential(
conv_BN_relu(in_channels, hid_3_1, 1), # 1*1卷积
conv_BN_relu(hid_3_1, hid_3_3, 3, padding=1),
conv_BN_relu(hid_3_3, out_3_3, 3, padding=1) # 2个3*3卷积级联
)
self.branch_pool = nn.Sequential(
nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False), # 池化后D2=D1
conv_BN_relu(in_channels, out_4_1, 1) # 1*1卷积
)
def forward(self, x):
b1 = self.branch1(x)
b2 = self.branch2(x)
b3 = self.branch3(x)
b4 = self.branch_pool(x)
# 沿通道方向并行连接
output = torch.cat((b1, b2, b3, b4), dim=1)
return output
# 测试上述模块
my_inception3 = InceptionV3_1(3, 96, 48, 64, 64, 96, 96, 64).cuda()
# 测试输入输出
input = torch.randn(1, 3, 256, 256).cuda()
output = my_inception3(input)
output.shape
torch.Size([1, 320, 256, 256])
from torchsummary import summary
# D*W*H (D=in_channels=3)
summary(my_inception3, input_size=(3, 256, 256))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 96, 256, 256] 384
BatchNorm2d-2 [-1, 96, 256, 256] 192
ReLU-3 [-1, 96, 256, 256] 0
conv_BN_relu-4 [-1, 96, 256, 256] 0
Conv2d-5 [-1, 48, 256, 256] 192
BatchNorm2d-6 [-1, 48, 256, 256] 96
ReLU-7 [-1, 48, 256, 256] 0
conv_BN_relu-8 [-1, 48, 256, 256] 0
Conv2d-9 [-1, 64, 256, 256] 27,712
BatchNorm2d-10 [-1, 64, 256, 256] 128
ReLU-11 [-1, 64, 256, 256] 0
conv_BN_relu-12 [-1, 64, 256, 256] 0
Conv2d-13 [-1, 64, 256, 256] 256
BatchNorm2d-14 [-1, 64, 256, 256] 128
ReLU-15 [-1, 64, 256, 256] 0
conv_BN_relu-16 [-1, 64, 256, 256] 0
Conv2d-17 [-1, 96, 256, 256] 55,392
BatchNorm2d-18 [-1, 96, 256, 256] 192
ReLU-19 [-1, 96, 256, 256] 0
conv_BN_relu-20 [-1, 96, 256, 256] 0
Conv2d-21 [-1, 96, 256, 256] 83,040
BatchNorm2d-22 [-1, 96, 256, 256] 192
ReLU-23 [-1, 96, 256, 256] 0
conv_BN_relu-24 [-1, 96, 256, 256] 0
AvgPool2d-25 [-1, 3, 256, 256] 0
Conv2d-26 [-1, 64, 256, 256] 256
BatchNorm2d-27 [-1, 64, 256, 256] 128
ReLU-28 [-1, 64, 256, 256] 0
conv_BN_relu-29 [-1, 64, 256, 256] 0
================================================================
Total params: 168,288
Trainable params: 168,288
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.75
Forward/backward pass size (MB): 1057.50
Params size (MB): 0.64
Estimated Total Size (MB): 1058.89
----------------------------------------------------------------
更进一步,Inception V3 将 n × n n\times n n×n 的卷积运算分解为 1 × n 1\times n 1×n 和 n × 1 n\times1 n×1 两个卷积,可以使计算成本降低 33 % 33\% 33% 。

此外,Inception V3 还将模块中的卷积核变得更宽而不是更深,形成第三个模块,已解决表征能力瓶颈的问题。
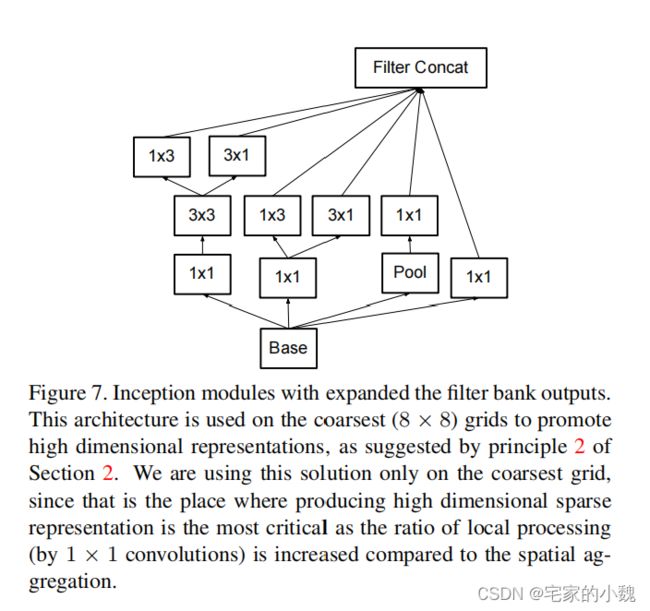
GooLeNet-3 网络正是由上述的 3 3 3 种不同类型的模块组成的,其计算也更加高效。
同时,Inception V3 还使用了 RMSProp 优化器。
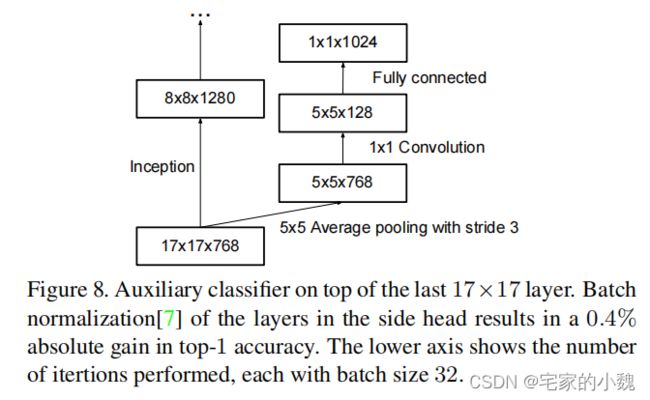
它也使用了辅助分类器,并将 7 × 7 7\times7 7×7 卷积分解成 3 3 3 个 3 × 3 3\times3 3×3 的卷积。
Inception-V4 网络
它将 Inception 和残差网络进行了结合,显著提升了训练速度和模型准确率,残差网络的相关教程请查看下一章。