pytorch入门:现代神经网络模型,pytroch实现CIFAR-10 分类
现代神经网络
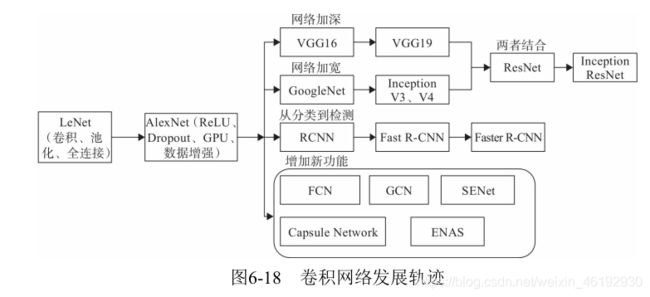
LetNet 系统的提出了卷积层,池化层,全连接层的概念。在2012 年提出了AlexNet ,提出了训练深度网络的重要技巧:Dropout ,Relu ,GPU, 数据增强方法等。然后卷积神经网络迎来了爆炸式发展。
LetNet-5 模型
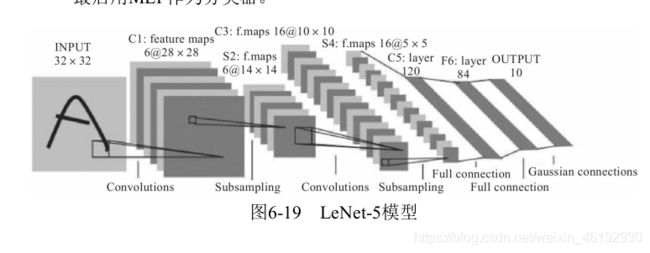 就是经典的手写数字识别的网络,结构为:输入层,卷积层,池化层,全连接层,全连接层,输出。
就是经典的手写数字识别的网络,结构为:输入层,卷积层,池化层,全连接层,全连接层,输出。
每个卷积层包括:卷积,池化,非线性的激活。使用卷积提取空间特征,采用降采样的平均池化层。使用Tanh 为激活含税,最后使用 MLP 作为分类器。
AlexNet 模型
 - 8 层神经网络,5层卷积,3层全连接,不计LRN 层和池化层。输入图像为3通道 224 *224 的大小
- 8 层神经网络,5层卷积,3层全连接,不计LRN 层和池化层。输入图像为3通道 224 *224 的大小
- 使用ReLU 激活函数
- 使用Dropout ,可以作为正则项防止过拟合,提升模型鲁棒性
- 有一些很好的训练技巧,数据曾广,学习率策略, weight Decay 等。
VGG 模型
可以认为是加深版的AlexNet 。都是卷积加全连接。
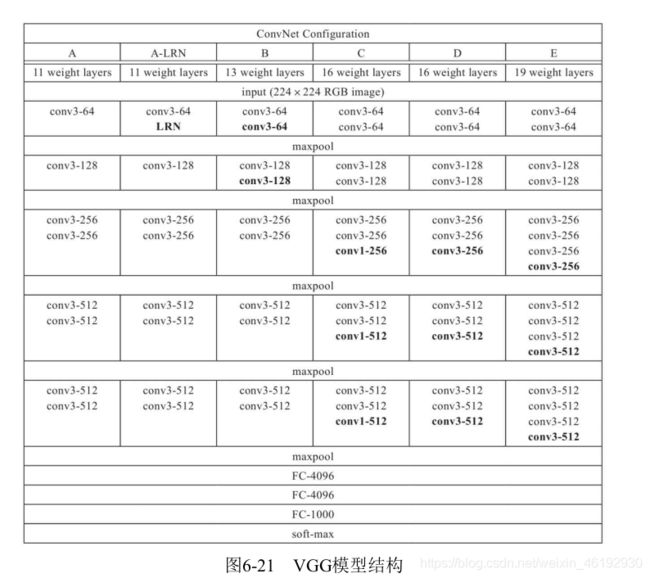
- 具有更深的网络结构,16 - 19层,更深的网络意味着更强的网络能力。
- 使用较小的 3 * 3的卷积核,因为两个33 的感受野相当于一个 55 ,同时参数量更少,以后的网络一般都是这样。
GoogleNet 模型
VGG 是增加网络的深度,但深度也是一个瓶颈,GoogleNet 从另一个维度增强网络的能力,每单元有很多层并行计算,让网络更宽。
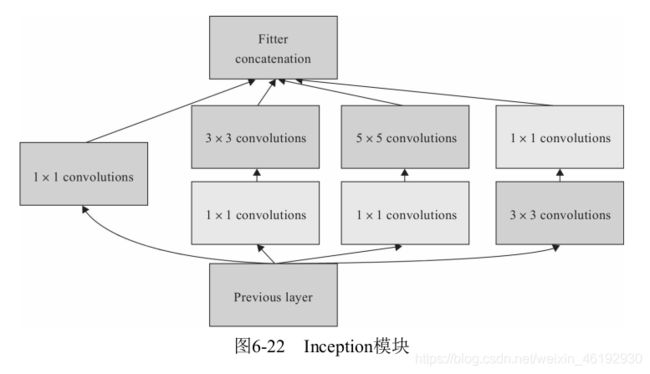
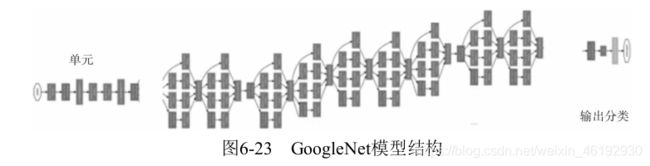
- 引入了Inception 结构,这是一种网中网的结构,通过让网络的水平排布,可以让较浅的网络得到较好的模型能力,并进行多特征的融合,同时更容易训练,为了减少计算量,使用了 1*1 的卷积来先对特征通道进行降维,堆叠 inception 模块就叫 Inception 网络,而 GoogleNet 就是一个性能良好的 Inception 网络实例(Inception v1)。
- 采用了全局平均池化层:后面的全连接替换为更简单的全局平均池化,在最后参数会变得更少。也不会影响结果的精度。
ResNet 模型
残差网络,核心思想就是输出的是两个连续的卷积层,并且输入时绕到下一层去。

通过引入残差,Identitly 恒等映射,相当于一个梯度高速通道,可以更容易的训练避免梯度消失的问题。所以可以得到很深的网络。以前研究的都忘了。。。哎
- 层数可以非常的深
- 引入残差单元解决网络退化问题。
胶囊网络简介
CapsNet,与当前的卷积神经网络相比,胶囊网络有很多优点。克服了卷积神经网络的一些不足:
- 训练卷积神经网络一般需要较大数据量,而胶囊网络使用较少数据就能泛化。
- 卷积神经网络因池化层,全连接层会丢失大量的信息,从而降低了空间位置的分辨率,而胶囊网络对很多细节的姿态信息(如对象的准确位置,旋转,厚度,倾斜度,尺寸等)能在网络里被保存,这就可以避免一些错误。
- 卷积神经网络不能很好的应对模糊性,但胶囊网络可以,所以在非常拥挤的场景中也表现得很好。
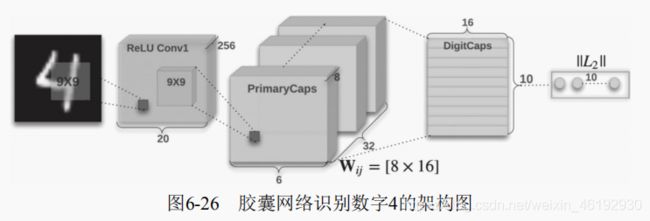
- 这个架构由两个卷积层和一个全连接层组成,其中第一个为一般的卷积层,第二个卷积相当于为Capsule层(胶囊层)做准备,并且该层得输出为向量。所以这个维度比一般得卷积层再高;一个维度。最后就是通过向量的输入与与路由(Routing)过程等构建出10个向量。每个向量的长度都直接表示某个类别的概率。
- 每个胶囊输出的一组向量,不是传统的神经元输出一个单独的数值
- 采用动态路由机制,为了解决向量向更高层的神经元传输的问题,动态路由让胶囊神经网络可以识别图像中的多个图形,这是CNN 不具有的功能
但是目前的研究还处于起步阶段,再简单的MNIST 数据集上表现了良好的性能,但在复杂的数据集中就不咋样了。所以仍处于研究开发阶段,但毫无疑问这个概念是合理的(虽然看不懂)。。。。
PyTorch 实现CIFAR-10 分类
数据集说明
由10个类的 60000 个32 * 32 彩色图形构成,每个类有6000 个图像,有50000个训练图像和 10000 个测试图像。
数据集分为5 个训练批次,和1 个测试批次,每个批次 10000 个图像.测试批次包含来自各个类别的恰好1000 个随机选择的图像,训练批次以随机顺序包含剩余图像,但由于一些训练批次可能包含来自一个类别的图像比另一个更多,但总体来说,5个训练批次之和包含来自各个种类的正好 5000 张图像。
这十个类彼此独立,不会出现重叠,就是多分类但标签的问题。
开始
# 解决:OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll alread
# 终于解决jupyter notebook 使用matplotlib老是服务终止的问题了。。。
# 应该是版本冲突的原因吧。。。
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 随机查看部分数据
import matplotlib.pyplot as plt
import numpy as np
# %matplotlib inline
# 显示图像
def imshow(img):
img = img / 2 + 0.5 # 反向归一化
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0))) # (C,H,W)->(H.W.C)
plt.show()
# 随机获取部分训练数据
dataiter = iter(trainloader)
images, labels = dataiter.next() # 返回迭代器的下一个项目
# 显示图像
imshow(torchvision.utils.make_grid(images))
# 打印标签
print(' '.join('%5s' % classes[labels[j]] for j in range(4))) # 这人都分不清楚啊
print(images.shape) # 4,3,32,32

import torch.nn as nn
import torch.nn.functional as F
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class CNNNet(nn.Module):
def __init__(self):
super(CNNNet,self).__init__() # 这个size变换也好算
self.conv1 = nn.Conv2d(in_channels=3,out_channels=16,kernel_size=5,stride=1)
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
self.conv2 = nn.Conv2d(in_channels=16,out_channels=36,kernel_size=3,stride=1)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(36*6*6,128)
self.fc2 = nn.Linear(128,10)
def forward(self,x):
x=self.pool1(F.relu(self.conv1(x)))
x=self.pool2(F.relu(self.conv2(x)))
#print(x.shape)
x=x.view(-1,36*6*6)
x=F.relu(self.fc2(F.relu(self.fc1(x))))
return x
net = CNNNet()
net=net.to(device)
# numel() 张量元素的个数
print("net have {} paramerters in total".format(sum(x.numel() for x in net.parameters())))
# net have 173742 paramerters in total
input = torch.rand(4,3,32,32)
from tensorboardX import SummaryWriter
with SummaryWriter(log_dir='logs',comment='Net') as w:
w.add_graph(net, (input, ))
import torch.optim as optim # 优化器和损失函数
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
print(net)
CNNNet(
(conv1): Conv2d(3, 16, kernel_size=(5, 5), stride=(1, 1))
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(16, 36, kernel_size=(3, 3), stride=(1, 1))
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=1296, out_features=128, bias=True)
(fc2): Linear(in_features=128, out_features=10, bias=True)
)
#取模型中的前四层
nn.Sequential(*list(net.children())[:4])
Sequential(
(0): Conv2d(3, 16, kernel_size=(5, 5), stride=(1, 1))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(16, 36, kernel_size=(3, 3), stride=(1, 1))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
# 训练模型
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 获取训练数据
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# 权重参数梯度清零
optimizer.zero_grad()
# 正向及反向传播
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 显示损失值
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 正确率有点低啊。。。但毕竟使用的网络很简单啊。。也没有进行优化。
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
# Accuracy of the network on the 10000 test images: 68 %
# 各种类别的正确率
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
Accuracy of plane : 72 %
Accuracy of car : 74 %
Accuracy of bird : 53 %
Accuracy of cat : 49 %
Accuracy of deer : 72 %
Accuracy of dog : 54 %
Accuracy of frog : 64 %
Accuracy of horse : 73 %
Accuracy of ship : 83 %
Accuracy of truck : 82 %
pytroch显示初始化参数
for m in net.modeles():
if isinstance(m,nn.Conv2d):
nn.init.normal_(m.weight)
nn.init.xavier_normal_(m.weight)
nn.init.kaiming_normal_(m.weight) # 卷积层参数初始化
nn。init.constand_(m,bias,0)
elif isinstance(m,nn.Linear):
nn.init.normal_(m.weight) # 全连接层参数初始化
采用全局平均池化
import torch.nn as nn
import torch.nn.functional as F
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 36, 5)
#self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.pool2 = nn.MaxPool2d(2, 2)
#使用全局平均池化层代替全连接层
self.aap=nn.AdaptiveAvgPool2d(1)
self.fc3 = nn.Linear(36, 10)
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = self.aap(x)
x = x.view(x.shape[0], -1)
x = self.fc3(x)
return x
net = Net()
net=net.to(device)
print("net_gvp have {} paramerters in total".format(sum(x.numel() for x in net.parameters())))
# net_gvp have 16022 paramerters in total 可以看到参数少了 10 倍
循环相同的次数精度会低一些,这是因为收敛速度慢,可以增加循环次数来弥补。
像 Keras 一样显示各层的参数
模型参数和结构详细且完整的显示,虽然没见过。。
import collections
import torch
def paras_summary(input_size, model):
def register_hook(module):
def hook(module, input, output):
class_name = str(module.__class__).split('.')[-1].split("'")[0]
module_idx = len(summary)
m_key = '%s-%i' % (class_name, module_idx+1)
summary[m_key] = collections.OrderedDict()
summary[m_key]['input_shape'] = list(input[0].size())
summary[m_key]['input_shape'][0] = -1
summary[m_key]['output_shape'] = list(output.size())
summary[m_key]['output_shape'][0] = -1
params = 0
if hasattr(module, 'weight'):
params += torch.prod(torch.LongTensor(list(module.weight.size())))
if module.weight.requires_grad:
summary[m_key]['trainable'] = True
else:
summary[m_key]['trainable'] = False
if hasattr(module, 'bias'):
params += torch.prod(torch.LongTensor(list(module.bias.size())))
summary[m_key]['nb_params'] = params
if not isinstance(module, nn.Sequential) and \
not isinstance(module, nn.ModuleList) and \
not (module == model):
hooks.append(module.register_forward_hook(hook))
# check if there are multiple inputs to the network
if isinstance(input_size[0], (list, tuple)):
x = [torch.rand(1,*in_size) for in_size in input_size]
else:
x = torch.rand(1,*input_size)
# create properties
summary = collections.OrderedDict()
hooks = []
# register hook
model.apply(register_hook)
# make a forward pass
model(x)
# remove these hooks
for h in hooks:
h.remove()
return summary
net = CNNNet()
input_size=[3,32,32]
paras_summary(input_size,net)
OrderedDict([('Conv2d-1', # 真的很直观啊。
OrderedDict([('input_shape', [-1, 3, 32, 32]),
('output_shape', [-1, 16, 28, 28]),
('trainable', True),
('nb_params', tensor(1216))])),
('MaxPool2d-2',
OrderedDict([('input_shape', [-1, 16, 28, 28]),
('output_shape', [-1, 16, 14, 14]),
('nb_params', 0)])),
('Conv2d-3',
OrderedDict([('input_shape', [-1, 16, 14, 14]),
('output_shape', [-1, 36, 12, 12]),
('trainable', True),
('nb_params', tensor(5220))])),
('MaxPool2d-4',
OrderedDict([('input_shape', [-1, 36, 12, 12]),
('output_shape', [-1, 36, 6, 6]),
('nb_params', 0)])),
('Linear-5',
OrderedDict([('input_shape', [-1, 1296]),
('output_shape', [-1, 128]),
('trainable', True),
('nb_params', tensor(166016))])),
('Linear-6',
OrderedDict([('input_shape', [-1, 128]),
('output_shape', [-1, 10]),
('trainable', True),
('nb_params', tensor(1290))]))])