YOLOV5训练自己的数据集(详细教程,经验之谈)
导言:
最近学习了yolov5训练自己数据集的知识,在闲暇时间写下这篇小白笔记,希望可以帮助到大家,欢迎大家在评论区发表自己的建议和看法!
一、前期准备
YOLOV5的代码链接(GitHub官方下载 ):https://github.com/ultralytics/yolov5
进入GitHub官方网站后点击Download ZIP就可以下载到本地了。

本教程所用环境:
· PyTorch版本:torch 1.7.0,官方要求torch >= 1.7.0
· CUDA: 10.2(要是cudn版本过低,升级一下)
· Python版本:python 3.8.8,官方要求python >=3.8
· zip文件解压后,打开requirements.txt直接查看所需的其他包,通过pip install -r requirements.txt安装依赖包
二、处理、制作自己的数据集
1)首先需要有数据,本文用的数据总共有7个类别,由于电脑硬件显存不足的,所以仅对2948张图片训练。(本人建议收集类别少的图片,因为类别太多,图片数量不是很多的话,各个类别的分布也会对训练有一定的影响)
2)使用LabelImg工具对收集的图片进行标注。
LabelImg常用的快捷键:w 创建标注框
a 前一张, d 后一张
Ctrl + s 保存图片
3)生成labels。labelImg工具可以生成yolo格式,也可以生成xml格式。本文生成xml格式,然后用脚本把xml格式转换成yolo格式。代码如下:
import cv2
import os
import xml.etree.ElementTree as ET
def convert(size, box):
# convert xmin, xmax, ymin, ymax to yolo format
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
xml_folfer = 'E:/XuHuiScreenshot/xmls/'
img_folder = 'E:/XuHuiScreenshot/images/'
txt_folder = 'E:/XuHuiScreenshot/labels/'
img_names = os.listdir(img_folder)
xml_names = os.listdir(xml_folfer)
#box_classes = ["boxNotClosed", "boxBroken", "boxFenceNotClose", "boxFenceNormal", "boxNoSign", "boxNormal"]
classes = ["safenet_destory", "unset_safenet", "oxygen_bottle", "acetylene_bottle", "gas_bottle","box","boxFence"]
#classes = ["safenet_destory", "unset_safenet"]
# print(classes.index("safenet_destroy"))
# print(a)
for name in img_names:
img_path = img_folder + name
# img_path = '/home/wu/Documents/safe/datasets/ai_shigong/boxNotClosed/boxNotClosed_v1/试标注/电箱未关门送标--原图/1961496.jpeg'
img = cv2.imread(img_path)
img_h, img_w, _ = img.shape
#print(img_path)
name_without_ex = name.split('.')[0:-1][0]
# name_without_ex = '2304097'
txt_path = txt_folder + name_without_ex + '.txt'
txt_f = open(txt_path, 'w')
print(name_without_ex + '.xml')
if name_without_ex + '.xml' in xml_names:
xml_path = xml_folfer + name_without_ex + '.xml'
print(xml_path)
xml_f = open(xml_path)
tree = ET.parse(xml_f)
root = tree.getroot()
for obj in root.iter('object'):
cls = obj.find('name').text
if cls in classes:
cls_id = classes.index(cls)
else:
continue
# if cls == 'safenet_destroy':
# cls_id = 0
# else:
# cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
#print(cls)
bb = convert((img_w, img_h), b)
txt_f.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
else:
txt_f.write("")
continue
注意一下,根据自己的数据集调整classes里面的内容,以及路径。
生成yolo格式即txt文件,每个图像对应一个txt文件,文件每一行为一个目标的信息,包括class, x_center, y_center, width, height格式。内容如下图所示:

4)训练集,测试集的划分。用脚本划分数据集,代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
Copyright ©Glodon Company Limited, All Rights Reserved
Authors: wens([email protected])
Date: 2021/2/20
File: step4_split_train_test.py
"""
import numpy as np
import os
import os.path as osp
import shutil
def is_image(filename):
""" whether filename is an image or not """
img_ext = ['.bmp', '.jpg', '.jpeg', '.png', '.tif']
basename = osp.basename(filename)
basename_ext = osp.splitext(basename)[-1]
return (basename_ext in img_ext) and (not basename.startswith("."))
def scan_image_dir(image_dir):
all_images = os.listdir(image_dir)
all_images = [x for x in all_images if is_image(x)]
id_2_name = [(osp.splitext(x)[0], x) for x in all_images]
res = dict(id_2_name)
return res
def generate_images_file(image_dir, output_filename):
img_id2name = scan_image_dir(image_dir)
lines = list(img_id2name.values())
write_lines_to_file(output_filename, lines)
def readlines_from_file(filename):
with open(filename, 'r') as f:
lines = f.readlines()
lines = [x.strip() for x in lines]
return lines
def write_lines_to_file(filename, lines):
# str="data/images/"
with open(filename, 'w') as f:
for x in lines:
x = x.strip() + "\n"
f.write(x)
print("done write to: ", filename)
def split_train_test(name_list_file, test_ratio, out_dir):
name_list = np.asarray(readlines_from_file(name_list_file))
num_total = len(name_list)
np.random.seed(7)
np.random.shuffle(name_list)
num_test = int(num_total * test_ratio)
num_train = num_total - num_test
test_list = name_list[:num_test]
train_list = name_list[num_test:]
write_lines_to_file(osp.join(out_dir, "test.txt"), test_list)
write_lines_to_file(osp.join(out_dir, "train.txt"), train_list)
def main():
root_dir = "/home/huangy-l/workspace/huangz/YOLOv5/yolov5-master/data/images"
# generate all_images.txt
name_list_file = "/home/huangy-l/workspace/huangz/YOLOv5/yolov5-master/data/all_images.txt"
# generate_images_file(osp.join(root_dir),
# name_list_file)
out_dir = "/home/huangy-l/workspace/huangz/YOLOv5/yolov5-master/data"
ratio = 0.15
split_train_test(name_list_file, ratio, out_dir)
if __name__ == '__main__':
main()注意一下:这个随机划分的代码的总体思想是:先运行函数generate_images_file()生成存放所有图片名的txt,然后再从这个txt里随机划分写入train.txt和test.txt。
到此为止生成的文件如下:
然后把这些文件放在从github下载的YOLOV5文件下的data文件中。
三、配置文件
1)修改yaml文件--数据集的配置文件
在YOLOV5目录下的data文件夹下新建一个jianzhu.yaml文件(可以自定义命名),用来存放训练集和测试集的划分文件(train.txt和test.txt),jianzhu.yaml内容如下: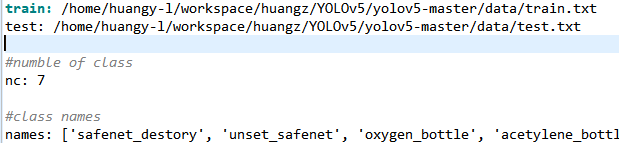
其中,nc表示目标的类别数目;names表示具体类别列表。
注:也可以在data目录下的coco.yaml上修改自己的路径、类别数和类别名称。在其他博客中看到,若在训练时报错,解决方法是:冒号后面需要加空格,否则会被认为是字符串而不是字典。
2)修改模型的配置文件
在YOLOV5目录下的models文件下选择需要的一个模型,四种模型(s、m、x、l)逐渐增大,随着架构的增大,训练时间也逐渐增大:
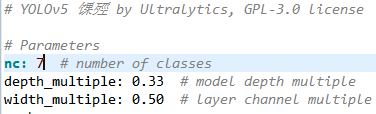
在现有的硬件条件下,本文选择的是yolo5s版本。打开yolo5s.yaml文件,只需将nc类别数改为自己需要的即可。
到此为止,自定义的数据集修改完毕,接下来是训练模型了。
四、训练模型
·首先在YOLOV5目录下创建一个weigths文件夹,然后把data/scripts文件下的download_weights.sh放在weights文件下。
·因为官方的权重文件下载太慢了,分享给大家yolov5s和yolov5m的权重文件,把此文件放到weigths文件下
分享链接:https://pan.baidu.com/s/1ITueTH2L_HXzgukv8WGvbQ
提取码:4c6w
在weights文件下有如下内容:
·修改train.py文件的参数:
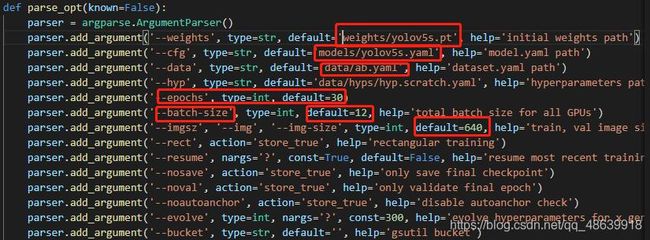
'--weigths':选择自己的权重文件路径,本文选择的是yolov5s.pt文件。
'--cfg':选择自己模型所在的路径。
'--data':之前配置文件时修改的yaml文件所在的路径。
'--epochs':指的是训练过程中整个数据集将被迭代多少次,显卡不行需要调小点。
'--batch-size':一次看完多少张图片才进行权重更新,显卡不行需要调小点。
'--images-size':输入图片宽高,同样显卡不行需要调小点。
根据自己的硬件配置修改参数。若参数调得过高,硬件跟不上会出现cuda内存溢出的问题,即内存占用过高电脑带动不了,跑不了。
修改完成后,点击运行代码就可以了。如下图表示运行成功:

运行结束后会告诉你把结果保存在哪个文件下,根据运行结果找到文件即可。
一般而言,训练好的模型会被保存在yolov5目录下的runs/train/exp0/weights/last.pt和best.pt,每一次迭代的详细训练数据保存在runs/train/exp0/results.csv文件中。
五、测试模型
在val.py文件中指定数据集配置文件和训练最优结果模型,如下图所示:
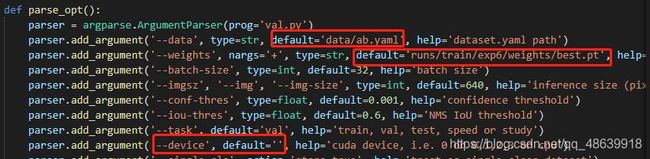
注: '--device':cuda device, i.e. 0 or 0,1,2,3 or cpu,是指在哪个服务器上训练模型。
'--conf-thres':置信度可自行修改
修改完成后,点击运行代码会出现错误如下:
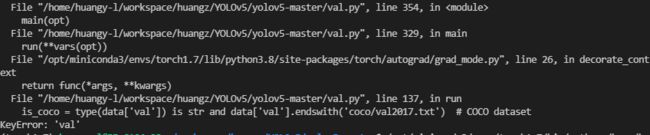
这是因为之前在创建jianzhu.yaml文件的时候没有加上val.txt的路径,加上之后如图就不会报错了。注意这里的test.txt与val.txt的路径一样。

模型测试运行结果如图:

评估模型好坏就是在有标注的测试集或者验证集上进行模型效果的评估。评估模型的二级指标:

图片在runs/val/exp0下运行结果:
六、推理模型
最后,在没有标注的数据集上进行推理,在YOLOV5目录下的detect.py文件下修改参数即可:

weights使用最满意的训练模型,source则提供一个包含所有测试图片的文件夹路径;置信度自己设置;命令中save_txt选项用于生成结果的txt标注文件,不指定则只会生成结果图像。
测试完毕后会在runs/detect/exp0/下生成图片以及对应的labels:

结语:
第一次写博客有些不熟练,可能有些代码及过程没有很详细的叙述出来,我以后继续努力。这就是用YOOV5训练自己数据集的整个过程:处理数据集-->模型训练-->模型测试-->模型推理。如果这篇博客能够帮助到大家,是我的荣幸!别忘了给我点个赞(⊙o⊙)哦!欢迎大家在评论区提出意见,我看到会及时回复的。
转载请注明出处。