Mongdb 基础学习、多种集群方式笔记
MongoDB
2022年6月17日, 星期五,14:40:50
文章目录
- MongoDB
-
- 1.NoSQL 数据库分类
- 2.MongoDB概念
- 3.数据库基本操作
- 4.CRUD操作
-
- 1.增
- 2.删
- 3.改
- 4.查
- 5.聚合操作
- 6.Mongdb集群
-
- 1.主从复制(Master-Slaver)
- 2.副本集(Relica Set)
-
- 1.创建副本集的存储文件,和数据库日志文件
- 2.创建配置文件
- 3.启动任意节点,执行副本集初始化
- 4.启动其他节点
- 5.添加副本从节点
- 6.更改副本集从节点读操作
- 3.分片集群(Sharding)
-
- 1.搭建shard1的副本集
- 2.搭建shard2的副本集
- 3.搭建配置服务器的副本集
- 4.搭建路由mongos
- 5.在mongos加入分片信息
- 6.创建分片集合
MongoDB 是一个基于 分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
NoSQL,指的是非关系型的数据库。NoSQL用于超大规模数据的存储。MongoDB是非关系型数据库
1.NoSQL 数据库分类
| 类型 | 部分代表 | 特点 |
|---|---|---|
| 列存储 | Hbase Cassandra Hypertable |
顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势。 |
| 文档存储 | MongoDB、CouchDB | 文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有机会对某些字段建立索引,实现关系数据库的某些功能。 |
| key-value存储 | Tokyo Cabinet / TyrantBerkeleyDB、MemcacheDB、Redis | 可以通过key快速查询到其value。一般来说,存储不管value的格式,照单全收。(Redis包含了其他功能) |
| 图存储 | Neo4J、FlockDB | 图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方便。 |
| 对象存储 | db4oVersant | 通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据。 |
| xml数据库 | Berkeley DB、XMLBaseX | 高效的存储XML数据,并支持XML的内部查询语法,比如XQuery,Xpath。 |
官网下载地址:https://www.mongodb.com/download-center#community
2.MongoDB概念
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
在linux启动命令:
mongod -f mongod.conf
关闭命令:
# 方式1
mongod -f mongod.conf --shutdown
# 方式2 在客户端里面执行命令关闭
3.数据库基本操作
1.显示数据库
show dbs
# 或
show databases
> show databases
admin 0.000GB
config 0.000GB
local 0.000GB
2.使用数据库
use local
> use local
switched to db local
3.查看当前所在数据库
show db
> db
local
4.删除数据库
use test
db.dropDatabase()
# 删除集合
db.collectionName.drop()
5.删除集合
db.createCollection("Collectionname")
show collections
db.Collectionname.drop()
数据库说明
show databases
admin 0.000GB
config 0.000GB
local 0.000GB
- admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
- local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
- config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
4.CRUD操作
原子性:MongoDB中的所有写操作都是单个文档级别的原子操作。
1.增
insert: 可以插入单条也可以多条
# 一条
db.august.insert({"_id":"1","name":"xaio1"})
# 多条需要数组包
db.august.insert([
{"_id":"1","name":"xaio1"},
{"_id":"2","name":"xaio2"},
{"_id":"3","name":"xaio3"},
{"_id":"4","name":"xaio4"},
{"_id":"5","name":"xaio5"}
])
insertOne: 插入单条
db.august.insertOne({"_id":"6","name":"xaio6"})
insertMany: 插入多条
db.collection.insertMany(
[ , , ... ],
{
writeConcern: ,
ordered:
}
)
参数说明:
ordered: (可选),默认值为true,指定插入为有序还是无序插入.
db.august.insertMany([{"_id":"7","name":"xaio7"}],
{ordered:true})
使用inser插入有相同 _id 时,会报错…
save:通过传入的文档来替换已有文档,_id 主键存在就更新,不存在就插入(不能同时插入–>[{xx:xx},{xx:xx}])。语法格式如下:
db.collection.save(
,
{
writeConcern:
}
)
参数说明:
- document : 文档数据。
- writeConcern :可选,抛出异常的级别。
db.august.save({"_id":"3","name":"肖3"})
> Updated 1 existing record(s) in 2ms
2.删
remove: 删除文档
db.collection.remove(
,
{
justOne: ,
writeConcern:
}
)
参数说明:
- query :(可选)删除的文档的条件。
- justOne : (可选)默认值 false,如为 true 或 1,则只删除一个文档,若为false则删除所有匹配条件的文档。
- writeConcern :(可选)抛出异常的级别。
简化方法:
删除1个:
db.集合名.deleteOne( … )
db.collection.deleteOne(
,
{
writeConcern: ,
collation: ,
hint: // Available starting in MongoDB 4.4
}
)
删除所有:
db.集合名.deleteMany( … )
db.collection.deleteMany(
,
{
writeConcern: ,
collation:
}
)
3.改
update:
db.collection.update(
,
,
{
upsert: ,
multi: ,
writeConcern:
}
)
参数说明:
query查询条件,类似mysql后面的whereupdate更新的对象和一些更新的操作符(如 , , ,inc…)等,也可以理解为sql update查询内set后面的内容- {} 可选
upsert可选,如果不存在update的记录,是否插入数据,true为插入,默认是false,不插入。multi可选,默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。writeConcern可选,抛出异常的级别。
db.august.update(
{"name":"xiao1"},
{$set:{"name":"肖1"}}
)
#翻译 查找 name = xiao的改为 肖1,只修改第一条查到的数据
updateOne:
db.collection.updateOne(
,
,
{
upsert: ,
writeConcern: ,
collation: ,
arrayFilters: [ , ... ],
hint: // Available starting in MongoDB 4.2.1
}
)
参数说明:
filter,同query,当为{}时,默认更新第一个update更新的对象和一些更新的操作符(如 , , ,inc…)等,也可以理解为sql update查询内set后面的内容- 同上
https://www.mongodb.com/docs/manual/reference/method/db.collection.updateOne/#db.collection.updateOne
db.august.updateOne({"_id":"1"},{$set:{"name":"肖肖1"},
$inc:{"age":1}})
updateMany:
db.collection.updateMany(
,
,
{
upsert: ,
writeConcern: ,
collation: ,
arrayFilters: [ , ... ],
hint: // Available starting in MongoDB 4.2.1
}
)
参数说明:
同updateOne
db.august.updateMany({"name":"肖肖1"},{$set:{"name":"肖肖8888"}})
添加列: 直接 $set:{"sex":"男"}
db.august.updateOne({"_id":"1"},{$set:{"age":0}})
删除列: $unset:{"sex":""}
db.august.updateOne({"_id":"1"},{$unset:{"age":0}})
4.查
find:
db.august.find(query,projection)
// 查询是否包含
db.inventory.find({item:{$exists:true}})
// 按类型
db.inventory.find({item:{$type:2}})
db.august.find()
5.聚合操作
聚合操作处理数据记录并返回计算结果(诸如统计平均值,求和等)。聚合操作组值来自多个文档,可以对
分组数据执行各种操作以返回单个结果。聚合操作包含三类:单一作用聚合、聚合管道、MapReduce。
- 单一作用聚合:提供了对常见聚合过程的简单访问,操作都从单个集合聚合文档。
- 聚合管道是一个数据聚合的框架,模型基于数据处理流水线的概念。文档进入多级管道,将文档转
换为聚合结果。 - MapReduce操作具有两个阶段:处理每个文档并向每个输入文档发射一个或多个对象的map阶
段,以及reduce组合map操作的输出阶段。
单一聚合:
db.inventory.count({tags:{$size:2}})
db.inventory.count({qty:{$gte:100}})
db.inventory.estimatedDocumentCount()
db.inventory.distinct("item")
检索books集合中所有文档的计数
b.books.estimatedDocumentCount()
#计算与查询匹配的所有文档
db.books.count({favCount:{$gt:50}})
#返回不同type的数组
db.books.distinct("type")
#返回收藏数大于90的文档不同type的数组
db.books.distinct("type",{favCount:{$gt:90}})
聚合管道操作语法
pipeline = [$stage1, $stage2, ...$stageN];
db.collection.aggregate(pipeline, {options})
- pipelines:(数组) 一组数据聚合阶段。除 o u t 、 out、 out、Merge和$geonear阶段之外,每个阶段都可以在管道中
出现多次。 - options:(文档) 可选,聚合操作的其他参数。包含:查询计划、是否使用临时文件、 游标、最大操作时
间、读写策略、强制索引等等
聚合管道包含非常丰富的聚合阶段,下面是最常用的聚合阶段 :
| 阶段 | 描述 | SQL等价运算符 |
|---|---|---|
| $match | 筛选条件 | WHERE |
| $project | 投影 | AS |
| $lookup | 左外连接 | LEFT OUTER JOIN |
| $sort | 排序 | ORDER BY |
| $group | 分组 | GROUP BY |
| s k i p / skip/ skip/limit | 分页 | |
| $unwind | 展开数组 | |
| $graphLookup | 图搜索 | |
| f a c e t / facet/ facet/bucket | 分面搜索 |
导入json 文件命令
mongoimport -h 192.168.10.102 -d demo -c zip --file C:\Users\19327\Desktop\zip.json
6.Mongdb集群
MongoDB 有三种集群方案部署模式,分别为主从复制(Master-Slaver)、副本集(Replica Set)和分片(Sharding)模式。
- Master-Slaver 是一种主从副本的模式,目前已经不推荐使用。
- Replica Set 模式取代了 Master-Slaver 模式,是一种互为主从的关系。Replica Set 将数据复制多份保存,不同服务器保存同一份数据,在出现故障时自动切换,实现故障转移,在实际生产中非常实用。
- Sharding 模式适合处理大量数据,它将数据分开存储,不同服务器保存不同的数据,所有服务器数据的总和即为整个数据集。
Sharding 模式追求的是高性能,而且是三种集群中最复杂的。在实际生产环境中,通常将 Replica Set 和 Sharding 两种技术结合使用。
1.主从复制(Master-Slaver)
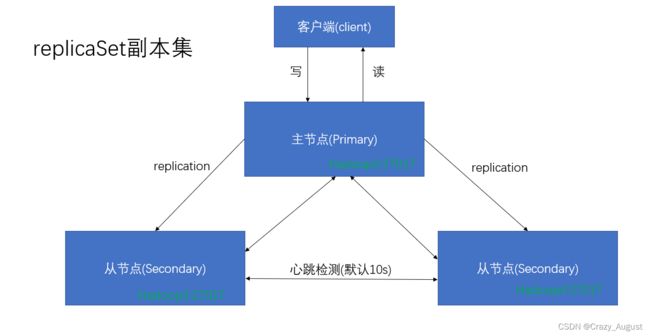
主从复制是 MongoDB 中最简单的数据库同步备份的集群技术,其基本的设置方式是建立一个主节点(Primary)和一个或多个从节点(Secondary),如下图所示。

- 主(Master): 可读可写,当数据有修改的时候,会将oplog操作日志同步到所有连接的salve上去。
- 从(Slave): 只读不可写,自动从Master同步数据
Master-Slave不支持链式结构,Slave只能直接连接Master。Redis的Master-Slave支持链式结构,Slave可以连接Slave,成为Slave的Slave。
优点:简单
缺点:主节点出现故障,只能人工介入,指定新的主节点.
2.副本集(Relica Set)
副本集提供冗余和高可用性,对于不同数据库服务器上的多个数据副本,复制提供了一定程度的容错能力,防止丢失单个数据库服务器。
副本集的集群架构如下图所示。

大部分和主从模式类似,但是副本集与主从复制的区别在于:当集群中主节点发生故障时,副本集可以自动投票,选举出新的主节点,并引导其余的从节点连接新的主节点,而且这个过程对应用是透明的。
但为了维持数据一致性,只能有一个主节点.
可以说,MongoDB 的副本集是自带故障转移功能的主从复制。
维持数据一致性的方式:主节点在写入更新数据的同时,还会将操作信息写入到oplog日志中,从节点会定时轮询读取oplog日志,根据日志内容同步更新自身的数据,保持与主节点一致。
主节点还负责指定其他节点为从节点,并设置从节点数据的可读性(默认情况下,从节点不支持外部读取),从而让从节点来分担集群读取数据的压力。
在副本集中还有一个额外的仲裁节点(不需要使用专用的硬件设备),负责在主节点发生故障时,参与选举新节点作为主节点。
副本集中的各节点会通过心跳信息来检测各自的健康状况,当主节点出现故障时,多个从节点会触发一次新的选举操作,并选举其中一个作为新的主节点。为了保证选举票数不同,副本集的节点数保持为奇数。
实操:
- 创建副本集的存储文件,和数据库日志文件
- 创建配置文件
- 启动任意节点,执行副本集初始化
- 启动其他节点
- 添加副本从节点
- 更改副本集从节点读操作
准备工作:
3台虚拟机都分别安装好Mongdb,版本最好要一致
1.创建副本集的存储文件,和数据库日志文件
在三台虚拟机分别执行创建命令
mkdir -p /usr/local/mongodb/data/replicasetdb
mkdir -p /usr/local/mongodb/logs
touch /usr/local/mongodb/logs/replicaset.log
2.创建配置文件
在三台虚拟机分别执行操作如下:
mkdir -p /usr/local/mongodb/conf
touch /usr/local/mongodb/confreplicaset.conf
vim replicaset.conf
replicaset.conf 配置文件
systemLog:
#MongoDB发送所有日志输出的目标指定为文件
destination: file
#mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径
path: /usr/local/mongodb/logs/replicaset.log
#当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。
logAppend: true
storage:
#mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。
dbPath: /usr/local/mongodb/data/replicasetdb
journal:
#启用或禁用持久性日志以确保数据文件保持有效和可恢复。
enabled: true
processManagement:
#启用在后台运行mongos或mongod进程的守护进程模式
fork: true
#指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID
net:
#服务实例绑定的IP
bindIp: 0.0.0.0
#绑定的端口
port: 27017
replication:
#副本集的名称(自定义,但是主从名称要一致)
replSetName: myrs
3.启动任意节点,执行副本集初始化
这里启动 hadoop2 作为演示:
3.1 这里用过守护进程方式进行启动,执行命令:
mongod -f /usr/local/mongodb/conf/replicasetyaml.conf
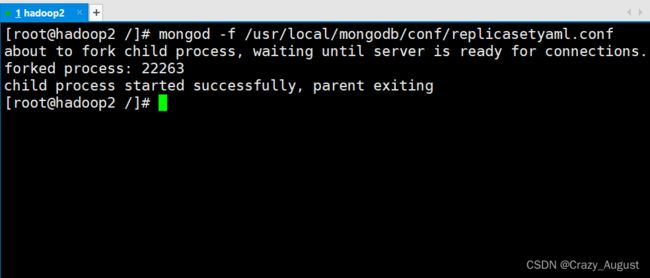
出现这个界面表示启动服务成功!
tag: 可以通过如下命令检查
ps -ef | grep mong

3.2进入mongdb-shell
mongo

3.3 连入后必须初始化副本才行
rs.initiate() #可加参数configuration
初始化之后按一下回车从secondary变为primary
可以通过rs.conf()和rs.status()来查看相应的信息
4.启动其他节点
mongod -f /usr/local/mongodb/conf/replicasetyaml.conf
mongo
关闭服务命令:
mongod -f /usr/local/mongodb/conf/replicasetyaml.conf --shutdown
5.添加副本从节点
在主节点(hadoop2)添加从节点,将其他成员加入到副本集中
rs.add(host,arbiterOnly)
参数说明:
- host: 要添加到副本集的新成员,如果是一个字符串,则需要指定新成员的主机名和可选的端口号,可以是域名
- arbiterOnly:boolean(可选),仅在值为字符串时适用。如果为true,则添加的主机是仲裁者。
示例:
将 hadoop3 和 hadoop4 的节点加添加到副本集:
rs.add("hadoop3")
rs.add("hadoop4")
#或者使用
rs.add("ip地址:端口")
如果有仲裁者进行如下操作:本示例用没有使用到仲裁者
rs.add(host,true)
或
rs.addArb(host)
例子:
rs.addArb("ip:端口")
添加完毕后在终端回车,就可以看到如下:
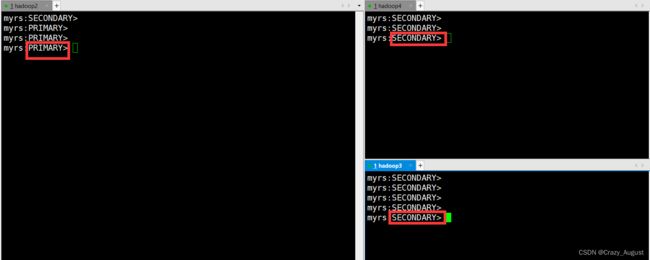
6.更改副本集从节点读操作
- 在主节点窗口执行插入数据命令
myrs:PRIMARY> db
test
# 插入数据
myrs:PRIMARY>
db.demo.insertOne({"name":"august"})
{
"acknowledged" : true,
"insertedId" : ObjectId("62b569d5d780eeffa205f772")
}
# 查询
myrs:PRIMARY>
db.demo.find({})
{ "_id" : ObjectId("62b569d5d780eeffa205f772"), "name" : "august" }
在主节点插入查询数据都可行
- 在从节点(hadoop3或者hadoop4)任意窗口执行同样操作:
执行db.demo.insertOne({"name":"august"})出现如下图错误
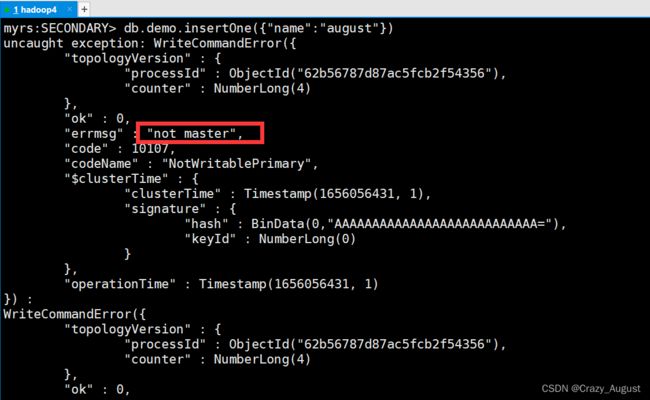
表示不是主节点不能插入数据,这是为了防止mongdb的数据一致性问题
- 执行
db.demo.fend({})出现如下图错误
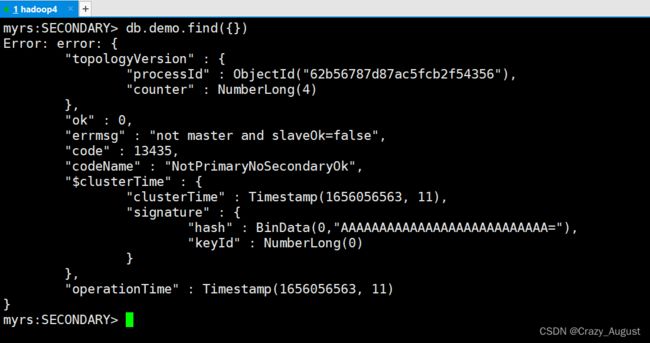
**重点:**这是mongdb默认配置从节点数据不可读.要先数据可以读取需要进行如下操作:
rs.secondaryOk()
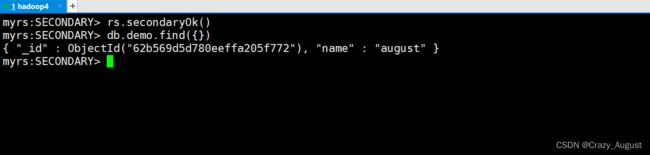
取消读取
rs.secondaryOk(false)
副本集搭建完毕
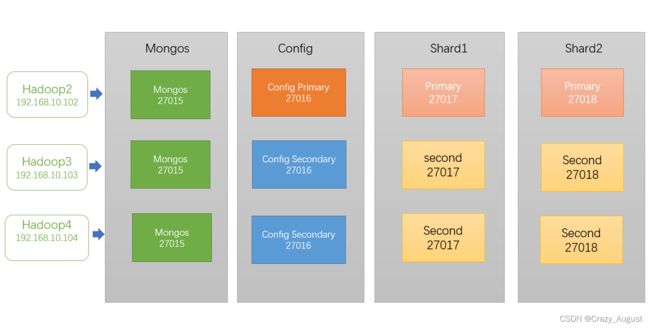
3.分片集群(Sharding)
分片是一种跨多台机器分布数据的方法,MongoDB使用分片来支持具有非常大的数据集和高吞吐量操作的部署。
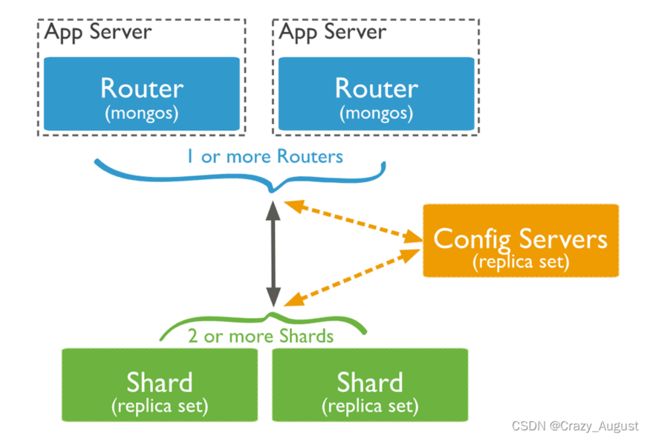
分片集群的组件:
- 分片(shard):每个分片都包含分片数据的一个子集。每个分片都可以部署为副本集。真正的数据存储位置
- 配置服务器(config serves):配置服务器存储群集的元数据和配置设置(每个数据库,集合、特定数据的范围的位置,以及保存了跨片数据迁移历史的修改日志)。所有存、取数据的方式,所有shard节点的信息,分片功能的一些配置信息.从MongoDB 3.4开始,配置服务器必须部署为副本集(CSRS)。
- 路由器(mongos):充当查询路由器,在客户端应用程序和分片集群之间提供接口。mongos本身没有任何数据,请求分发,直接转发所有读、写命令到正确的分片上.mongos进程是轻量级的、不持久化的.所以需要config serves 来保存存储集群的元数据
实操:
- 搭建shard1的副本集
- 搭建shard2的副本集
- 搭建配置服务器的副本集
- 搭建mongos
- 在mongos加入分片信息
- 创建分片集合
准备工作:
3台虚拟机都分别安装好Mongdb,版本最好要一致

1.搭建shard1的副本集
1.1 创建文件夹
#创建存储分片的数据文件夹
mkdir -p /usr/local/mongodb/data/shard1/db
# 日志
mkdir -p /usr/local/mongodb/logs/shardrs
touch /usr/local/mongodb/logs/shardrs/shard1.log
1.2 配置文件
vim /usr/local/mongodb/conf/shard1.conf
文件内容如下:
shard1.conf
systemLog:
#MongoDB发送所有日志输出的目标指定为文件
destination: file
#mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径
path: /usr/local/mongodb/logs/shardrs/shard1.log
#当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日>志文件的末尾。
logAppend: true
storage:
#mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。
dbPath: /usr/local/mongodb/data/shard1/db
journal:
#启用或禁用持久性日志以确保数据文件保持有效和可恢复。
enabled: true
wiredTiger:
engineConfig:
cacheSizeGB: 0.5
processManagement:
#启用在后台运行mongos或mongod进程的守护进程模式
fork: true
#指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod>将写入其PID
net:
#服务实例绑定的IP
bindIp: 0.0.0.0
#绑定的端口
port: 27017
replication:
#副本集的名称
replSetName: shard1
sharding:
#分片角色
clusterRole: shardsvr
1.3 分别启动mong服务
mongod -f /usr/local/mongodb/conf/shard1.conf
1.4 进入mongo
mongo hadoop2:27017
1.5 初始化第一个分片副本集
rs.initiate()
rs.add("hadoop3:27017")
rs.add("hadoop4:27017")
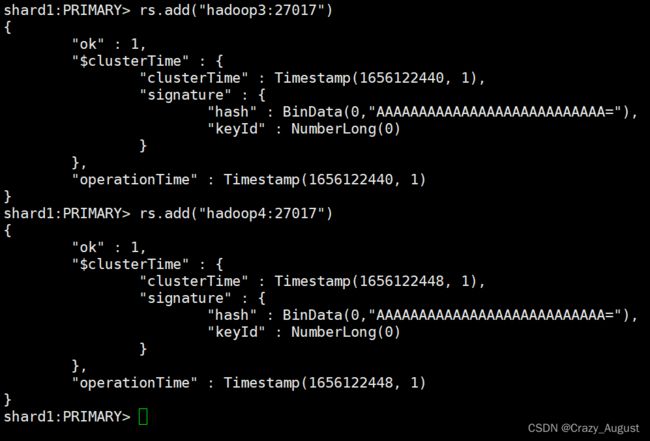
第一套副本集搭建完成
2.搭建shard2的副本集
搭建步骤和shard1步骤一致
#创建存储分片的数据文件夹
mkdir -p /usr/local/mongodb/data/shard2/db
# 日志
mkdir -p /usr/local/mongodb/logs/shardrs
touch /usr/local/mongodb/logs/shardrs/shard2.log
#创建配置文件
vim /usr/local/mongodb/conf/shard2.conf
文件内容如下:
shard2.conf
systemLog:
#MongoDB发送所有日志输出的目标指定为文件
destination: file
#mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径
path: /usr/local/mongodb/logs/shardrs/shard2.log
#当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日>志文件的末尾。
logAppend: true
storage:
#mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。
dbPath: /usr/local/mongodb/data/shard2/db
journal:
#启用或禁用持久性日志以确保数据文件保持有效和可恢复。
enabled: true
wiredTiger:
engineConfig:
cacheSizeGB: 0.5
processManagement:
#启用在后台运行mongos或mongod进程的守护进程模式
fork: true
#指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod>将写入其PID
net:
#服务实例绑定的IP
bindIp: 0.0.0.0
#绑定的端口
port: 27018
replication:
#副本集的名称
replSetName: shard2
sharding:
#分片角色
clusterRole: shardsvr
这里和配置文件 shard1.conf 只有副本集名称不一致
mongod -f /usr/local/mongodb/conf/shard2.conf
mongo hadoop2:27018
初始化第二个副本集节点
rs.initiate()
rs.add("hadoop3:27017")
rs.add("hadoop4:27017")
第二套分片副本集搭建完成
3.搭建配置服务器的副本集
1.创建存储文件
#创建存储分片的数据文件夹
mkdir -p /usr/local/mongodb/data/config/db
# 日志
mkdir -p /usr/local/mongodb/logs/config
touch config.log
2.配置集配置文件
touch /usr/local/mongodb/conf/config/config.conf
内容如下:
config.conf
systemLog:
#MongoDB发送所有日志输出的目标指定为文件
destination: file
#mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径
path: /usr/local/mongodb/logs/config/config.log
#当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日>志文件的末尾。
logAppend: true
storage:
#mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。
dbPath: /usr/local/mongodb/data/config/db
journal:
#启用或禁用持久性日志以确保数据文件保持有效和可恢复。
enabled: true
wiredTiger:
engineConfig:
cacheSizeGB: 0.5
processManagement:
#启用在后台运行mongos或mongod进程的守护进程模式
fork: true
#指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod>将写入其PID
net:
#服务实例绑定的IP
bindIp: 0.0.0.0
#绑定的端口
port: 27016
replication:
#副本集的名称
replSetName: config
sharding:
#分片角色
clusterRole: configsvr
注意:配置集的内容和分片集类似,只是分配角色不同
分别启动配置集服务
mongod -f /usr/local/mongodb/conf/config/config.conf
mongo ip:27016
初始化配置集节点
rs.initiate()
rs.add("hadoop3:27016")
rs.add("hadoop4:27016")
配置集搭建完成
4.搭建路由mongos
路由集是mongos的服务,不是mongod的服务,路由节点不存放数据,所以不需要存放数据的目录
1.准备存放日志的目录:
mkdir -p /usr/local/mongodb/logs/mongos
touch /usr/local/mongodb/logs/mongos/mongos.log
配置文件
mongos.conf
systemLog:
#MongoDB发送所有日志输出的目标指定为文件
destination: file
#mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径
path: /usr/local/mongodb/logs/mongos/mongos.log
#当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日>志文件的末尾。
logAppend: true
processManagement:
#启用在后台运行mongos或mongod进程的守护进程模式
fork: true
#指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod>将写入其PID
net:
#服务实例绑定的IP
bindIp: 0.0.0.0
#绑定的端口
port: 27015
sharding:
#指定配置节点副本集 配置 节点集名称/ip:端口
configDB: config/hadoop2:27016,hadoop3:27016,hadoop4:27016
分别启动服务
mongos -f /usr/local/mongodb/conf/mongos/mongos.conf
此时所有的服务启动完成
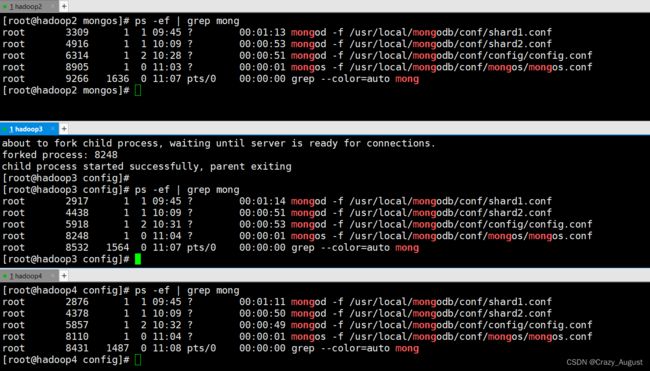
5.在mongos加入分片信息
#连接mongos
mongo -port 27015
添加第一个分片
语法:sh.addShard("IP:Port")
sh.addShard("shard1/hadoop2:27017,hadoop3:27017,hadoop3:27017")
#查看分片状况情况
sh.status()
添加第二个分片
sh.addShard("shard2/hadoop2:27018,hadoop3:27018,hadoop3:27018")
#查看分片状况情况
sh.status()
6.创建分片集合
为了使集合支持分片,需要先开启database的分片功能
sh.enableSharding("库名")
sh.shardCollection("库名.集合名",{"key":"存储策略"})
创建第一个分片集合
sh.enableSharding("demo")
sh.shardCollection("demo.emp",{"_id":"hashed"})
sh.status()
mongos>
use demo
for(var i = 0;i<1000;i++){db.emp.insert({name:i})}
# 查看数据分布情况
mongos>
db.emp.getShardDistribution()
Shard shard1 at shard1/hadoop2:27017,hadoop3:27017,hadoop4:27017
data : 35KiB docs : 1001 chunks : 2
estimated data per chunk : 17KiB
estimated docs per chunk : 500
Totals
data : 35KiB docs : 1001 chunks : 2
Shard shard1 contains 100% data, 100% docs in cluster, avg obj size on shard : 36B
加入第二个分片信息之后:
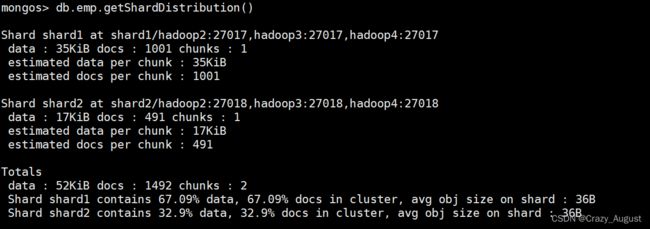
在连接另一台mongos,发现,第二个路由无需配置,因为分片配置都保存到了配置服务器中.
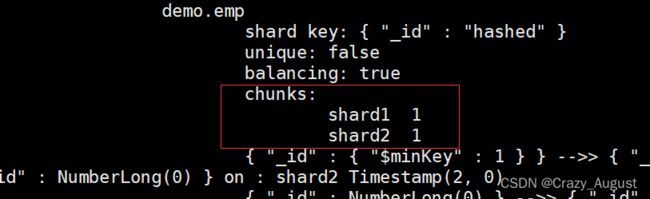
表示分片集群搭建完毕!