性能测试中问题反思和心得
前言:
笔者在实际工作中,经常会遇到更换硬件物料的情况,其中比较多的是EMCP。包括项目刚开始时的选型,多种物料对比测试。或者项目迭代过程中,老物料不再生产,验证新物料是否可以满足。这里笔者根据自己的实际工作经验和学习,总结了一下在测试过程中使用的方法和问题思考。
一、关于EMCP

eMCP是相较eMMC更高阶的存储器件,它将eMMC与LPDDR封装为一体,在减小体积的同时还减少了电路链接设计,主要应用于千元以上的智能手机中。
二、性能测试及问题反思
关于io读写速度的测试方法有很多,如:linux下常用的dd指令、iozone、fio,windows下的H2testw等。下面介绍几种常见的测试工具的使用中,遇到的问题和思考,以及适用的场景和分析方法等。
dd指令使用及问题反思
dd指令是比较常用的测试io的指令,优势是方便快捷,不需要下载或者push测试工具,可以很快的摸底。所以可以用来测试硬盘的顺序读写能力。可以写文件,可以写裸设备。
/mnt/sdcard # dd --help
Usage: dd [OPERAND]...
or: dd OPTION
Copy a file, converting and formatting according to the operands.
bs=BYTES read and write up to BYTES bytes at a time (default: 512);
overrides ibs and obs
cbs=BYTES convert BYTES bytes at a time
conv=CONVS convert the file as per the comma separated symbol list
count=N copy only N input blocks
ibs=BYTES read up to BYTES bytes at a time (default: 512)
if=FILE read from FILE instead of stdin
iflag=FLAGS read as per the comma separated symbol list
obs=BYTES write BYTES bytes at a time (default: 512)
of=FILE write to FILE instead of stdout
oflag=FLAGS write as per the comma separated symbol list
seek=N skip N obs-sized blocks at start of output
skip=N skip N ibs-sized blocks at start of input
status=LEVEL The LEVEL of information to print to stderr;
'none' suppresses everything but error messages,
'noxfer' suppresses the final transfer statistics,
'progress' shows periodic transfer statistics
详解:
if=xxx 从xxx读取,如if=/dev/zero,该设备无穷尽地提供0,(不产生读磁盘IO)
of=xxx 向xxx写出,可以写文件,可以写裸设备。如of=/dev/null,“黑洞”,它等价于一个只写文件. 所有写入它的内容都会永远丢失. (不产生写磁盘IO)
bs=1M 每次读或写的大小,即一个块的大小。
count=xxx 读写块的总数量。
再熟悉两个特殊的设备:
/dev/null:回收站、无底洞。
/dev/zero:产生字符
根据–help的提示,我们可以总结出一个常用的测试模板:
# 写速率
dd if=/dev/zero of=/sdcard/test bs=1M count=1000
# 读速率
dd if=/sdcard/test of=/dev/null bs=1M count=1000
初步测试
# 写速度测试 1GB
/mnt/sdcard # dd if=/dev/zero of=/sdcard/test bs=1M count=1000
1000+0 records in
1000+0 records out
1048576000 bytes (1.0 GB, 1000 MiB) copied, 89.1365 s, 11.8 MB/s
# 写速度测试 100M
/mnt/sdcard # dd if=/dev/zero of=/sdcard/test bs=1M count=100
100+0 records in
100+0 records out
104857600 bytes (105 MB, 100 MiB) copied, 3.11532 s, 33.7 MB/s
这里发现了测试速度差距过大的问题。
问题反思
问题一:同样的设备,写1GB测试的速度和100M速度差距过大,究竟哪个才是我们需要的测试结果?
出现这个问题,首先我们要理解内存缓存机制,简单的说,就是dd命令完成前有没有让系统真正把文件写到磁盘上。
那么我们可以进行如下测试:
/mnt/sdcard # free -h
total used free shared buff/cache available
Mem: 958M 257M 505M 2.0M 196M 684M
Swap: 255M 0B 255M
/mnt/sdcard # dd if=/dev/zero of=/sdcard/test bs=1M count=100
100+0 records in
100+0 records out
104857600 bytes (105 MB, 100 MiB) copied, 1.88379 s, 55.7 MB/s
/mnt/sdcard # free -h
total used free shared buff/cache available
Mem: 958M 257M 393M 2.0M 307M 683M
Swap: 255M 0B 255M
所以以上命令只是单纯地把这128MB的数据读到内存缓冲当中(写缓存[write cache])。所以你得到的将是一个超级快的速度。因为其实dd给你的只是读取速度,直到dd完成后系统才开始真正往磁盘上写数据,但这个速度你是看不到了。
这时候我们查找–help 会发现这个参数
fdatasync physically write output file data before finishing
加入这个参数后,dd命令执行到最后会真正执行一次“同步(sync)”操作,所以这时候你得到的是读取这128M数据到内存并写入到磁盘上所需的时间,这样算出来的时间才是比较符合实际的。
/mnt/sdcard # dd bs=1M count=128 if=/dev/zero of=test conv=fdatasync
128+0 records in
128+0 records out
134217728 bytes (134 MB, 128 MiB) copied, 8.65137 s, 15.5 MB/s
问题二:通过上述加入参数 conv=fdatasync 的方法,是否也用到了写缓存(write cache)?
那么我们可以进行如下测试:
/mnt/sdcard # free -h
total used free shared buff/cache available
Mem: 958M 258M 504M 2.0M 196M 683M
Swap: 255M 0B 255M
/mnt/sdcard # dd bs=1M count=128 if=/dev/zero of=test conv=fdatasync
128+0 records in
128+0 records out
134217728 bytes (134 MB, 128 MiB) copied, 7.93997 s, 16.9 MB/s
/mnt/sdcard # free -h
total used free shared buff/cache available
Mem: 958M 258M 360M 2.0M 339M 682M
Swap: 255M
从测试结果上来看,cache是明显增加的。也就是说,也用到了写缓存。
问题三:究竟怎样可以跳过写缓存(write cache)?
我从网上找了两种不同的答案进行如下测试:
oflag=direct
oflag=dsync
我们先看一下–help的解释
direct use direct I/O for data
dsync use synchronized I/O for data
从解释上看似乎差不多,我们进行一下测试:
测试一:
/mnt/sdcard # free -h
total used free shared buff/cache available
Mem: 958M 257M 503M 2.0M 197M 683M
Swap: 255M 0B 255M
/mnt/sdcard # dd bs=1M count=128 if=/dev/zero of=test oflag=direct
128+0 records in
128+0 records out
134217728 bytes (134 MB, 128 MiB) copied, 8.62906 s, 15.6 MB/s
/mnt/sdcard # free -h
total used free shared buff/cache available
Mem: 958M 257M 502M 2.0M 198M 683M
Swap: 255M 0B 255M
测试二:
/mnt/sdcard # free -h
total used free shared buff/cache available
Mem: 958M 258M 504M 2.0M 196M 683M
Swap: 255M 0B 255M
/mnt/sdcard # dd bs=1M count=128 if=/dev/zero of=test oflag=dsync
128+0 records in
128+0 records out
134217728 bytes (134 MB, 128 MiB) copied, 9.72236 s, 13.8 MB/s
/mnt/sdcard # free -h
total used free shared buff/cache available
Mem: 958M 258M 361M 2.0M 338M 682M
Swap: 255M 0B 255M
从测试结果上来看,oflag=direct 跳过了内存缓存。oflag=dsync并没有。但是速度的确比较慢。因为每次都同步了IO,每次读取1M后就要先把这1M写入磁盘,然后再读取下面这1M,一共重复128次。所以速度很慢,基本上没有用到写缓存。
问题四:我们在实际测试过程中,究竟用哪条指令比较合理?
这个主要取决于我们的测试目的,总结一下就是:
# 测试最接近真实的文件写速度
dd bs=50M count=100 if=/dev/zero of=test conv=fdatasync
# 测试cache写缓存速度
dd if=/dev/zero of=/sdcard/test bs=1M count=100
# (bs count 值根据实际设备Mem情况而定)
# 跳过了内存缓存
dd bs=1M count=128 if=/dev/zero of=test oflag=direct
知识延伸
关于内存中的buff/cache
我们再看一下上面free命令的输出结果:
/mnt/sdcard # free -h
total used free shared buff/cache available
Mem: 958M 259M 475M 2.0M 224M 682M
Swap: 255M 0B 255M
刚刚通过dd指令写文件的方式,细节的看出了buff/cache的变化,但是要区分出Buffer和cache,并不像物理内存Mem、交换分区Swap那样好理解。
从网上查百科的话,给出的解释是 Buffer 是 缓冲区,cache 是缓存。从字面上来理解的话,并不是那么好区分。我们可以利用/proc/meminfo去拆解。
/mnt/sdcard # cat /proc/meminfo
MemTotal: 981744 kB
MemFree: 486620 kB
MemAvailable: 698236 kB
Buffers: 10532 kB
Cached: 187600 kB
SwapCached: 0 kB
Active: 166944 kB
Inactive: 267388 kB
Active(anon): 102548 kB
Inactive(anon): 135700 kB
Active(file): 64396 kB
Inactive(file): 131688 kB
Unevictable: 0 kB
Mlocked: 0 kB
SwapTotal: 262140 kB
SwapFree: 262140 kB
Dirty: 65580 kB
Writeback: 0 kB
AnonPages: 236288 kB
Mapped: 49336 kB
Shmem: 2060 kB
Slab: 44112 kB
SReclaimable: 31368 kB
SUnreclaim: 12744 kB
KernelStack: 3280 kB
PageTables: 1856 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 753012 kB
Committed_AS: 805532 kB
VmallocTotal: 258867136 kB
VmallocUsed: 0 kB
VmallocChunk: 0 kB
通过man free 的解释
buffers Memory used by kernel buffers (Buffers in /proc/meminfo)
cache Memory used by the page cache and slabs (Cached and SReclaimable in /proc/meminfo)
buff/cache Sum of buffers and cache
所以 free中的 buff/cache 指的是 Buffers + Cached + SReclaimable 。数据来自于 /proc/meminfo。
我们继续man proc可以得到 proc 文件系统的详细文档。翻译过来就是:
Buffers 是对原始磁盘块的临时存储,也就是用来缓存磁盘的数据,通常不会特别大(20MB 左右)。这样,内核就可以把分散的写集中起来,统一优化磁盘的写入,比如可以把多次小的写合并成单次大的写等等。
Cached 是从磁盘读取文件的页缓存,也就是用来缓存从文件读取的数据。这样,下次访问这些文件数据时,就可以直接从内存中快速获取,而不需要再次访问缓慢的磁盘。
SReclaimable 是 Slab 的一部分。Slab 包括两部分,其中的可回收部分,用 SReclaimable 记录;而不可回收部分,用 SUnreclaim 记录。
测试
清理系统缓存
/ # free -h
total used free shared buff/cache available
Mem: 958M 259M 475M 2.0M 224M 682M
Swap: 255M 0B 255M
/ # echo 3 > /proc/sys/vm/drop_caches
/ # free -h
total used free shared buff/cache available
Mem: 958M 259M 635M 2.0M 64M 681M
Swap: 255M 0B 255M
/ #
执行 dd if=/dev/zero of=./test bs=1M count=500 观察内存和 I/O 的变化情况
/mnt/sdcard # vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 650608 948 64324 0 0 3 284 216 248 5 21 71 3 0
1 0 0 650444 948 64460 0 0 0 0 1581 2006 5 20 75 0 0
2 0 0 650640 948 64460 0 0 0 0 1518 1958 5 20 74 0 0
1 0 0 650428 948 64460 0 0 0 0 1542 1997 5 21 74 0 0
2 0 0 624732 1716 85624 0 0 1873 12 7329 7395 6 32 58 4 0
2 0 0 566844 1772 145052 0 0 10 12606 8838 6537 7 51 43 0 0
1 1 0 558848 1780 153820 0 0 2 0 3158 2955 5 25 51 19 0
2 0 0 554000 1780 158068 0 0 0 4154 2968 3202 5 23 55 17 0
3 0 0 508076 1876 203236 0 0 6 41184 14093 11562 6 47 44 3 0
2 0 0 470896 1932 241664 0 0 6 37030 15177 13524 6 43 45 5 0
3 0 0 441828 2060 270680 0 0 4 66952 9652 8827 5 37 46 11 0
1 1 0 422600 2144 289128 0 0 4 0 6529 6307 5 30 49 16 0
1 1 0 422836 2144 289252 0 0 0 0 1607 2018 4 21 59 15 0
2 0 0 408664 2204 303516 0 0 2 0 5927 5979 5 28 56 11 0
2 0 0 376776 2332 334372 0 0 4 24951 9138 8448 5 37 47 11 0
1 1 0 346608 2456 364596 0 0 4 61496 10138 9400 5 38 45 12 0
1 1 0 317600 2572 393880 0 0 4 0 9780 7435 5 36 49 10 0
1 1 0 313608 2592 397736 0 0 2 0 3583 2077 5 22 56 17 0
3 0 0 311068 2604 400984 0 0 0 0 2822 2039 5 22 59 14 0
2 1 0 281004 2728 430792 0 0 4 24936 10050 2339 5 37 47 11 0
1 1 0 248652 2852 462240 0 0 4 61232 10412 2503 6 38 46 10 0
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 0 0 218376 2976 492816 0 0 4 0 10352 2458 5 37 47 11 0
1 1 0 202648 3048 508664 0 0 4 12594 9724 2328 5 31 47 18 0
2 1 0 202540 3048 508712 0 0 0 0 1667 2036 5 21 52 23 0
2 0 0 181996 3132 528780 0 0 2 12340 7030 2365 5 32 49 14 0
3 0 0 150736 3256 559900 0 0 4 64516 10444 2636 6 38 46 9 0
3 1 0 121148 3380 589640 0 0 4 0 9142 2480 5 36 47 11 0
1 1 0 93292 3500 617276 0 0 6 16700 9393 2441 6 35 47 12 0
2 1 0 93404 3500 617400 0 0 0 0 1679 2057 5 20 60 14 0
3 0 0 85224 3528 625472 0 0 0 16458 4177 2116 5 25 59 11 0
2 0 0 80896 3548 630980 0 0 0 54360 9587 2263 5 26 66 2 0
1 0 0 81052 3548 630980 0 0 0 0 9283 2170 5 23 72 0 0
1 0 0 81520 3548 630980 0 0 0 0 9882 4969 5 23 72 0 0
1 0 0 81444 3548 630980 0 0 0 0 4509 2089 5 21 74 0 0
1 0 0 81364 3548 630980 0 0 0 0 1614 1997 5 21 75 0 0
1 0 0 81524 3548 630992 0 0 16 0 5823 2135 5 21 73 1 0
Buffer 和 Cache 都在增长,但显然 Cache 的增长快很多。这说明写文件时,数据缓存到了 Cache 中。
多次 I/O 写的结果加起来,才是 dd 要写的 500M 的数据。写完之后,才是我们实际要测试写速度。
Cached更大的优势会在iozone的重写测试中体现
iozone经验总结和问题反思
关于iozone
iozone是一个文件系统的benchmark工具,可以测试不同的操作系统中文件系统的读写性能。可以测试 Read, write, re-read,re-write, read backwards, read strided, fread, fwrite, random read, pread, mmap, aio_read, aio_write 等等不同的模式下的硬盘的性能。测试的时候请注意,设置的测试文件的大小一定要大过你的内存(最佳为内存的两倍大小),不然linux会给你的读写的内容进行缓存。会使数值非常不真实。(摘自百科)
iozone的安装和使用,网上有太多的解释,这里就不占用过多的篇幅了,直接上干货。
常用的测试指令
# 写速率
./iozone -i0 -Rab ./test-iozone-write.xls -g 2G -n 1M -w -e -C
# 读速率
./iozone -i1 -Rab ./test-iozone-write.xls -g 1G -n 1M -w -e -C
测试脚本
因为测试量级较多,一般建议自己整理一个测试脚本。方便大量的测试任务
clear
echo "a. automatic mode"
echo "b. write/rewrite "
echo "c. read/re-read"
echo "d. random-read/write"
echo "e. fwrite"
echo "f. fread"
echo "please input (a-e) to select function"
read letter
case $letter in
"a")
iozone -Rab /tmp/test-iozone-auto.xls -g 2G -n 1M -w -e -C
;;
"b")
iozone -i0 -Rab /tmp/test-iozone-write.xls -g 2G -n 1M -w -e -C
;;
"c")
perf_proc/iozone -i1 -Rab /tmp/test-iozone-read.xls -g 2G -n 1M -w -e -C
;;
"d")
perf_proc/iozone -i2 -Rab /tmp/test-iozone-random-rw.xls -g 2G -n 1M -w -e -C
;;
"e")
perf_proc/iozone -i3 -Rab /tmp/test-iozone-fwrite.xls -g 2G -n 1M -w -e -C
;;
"f")
perf_proc/iozone -i4 -Rab /tmp/test-iozone-fread.xls -g 2G -n 1M -w -e -C
;;
*)
;;
esac
;;
测试分析
这里列举 write report的一次自动测试结果,列(文件大小 KB),行(reclenKB)
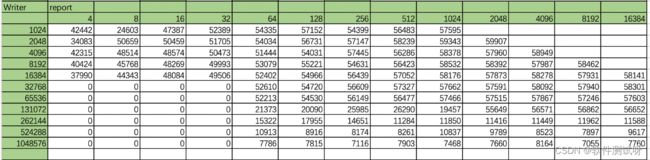
问题一:实际测试时,设置的测试范围更大,数据量大,如何更好的分析?
为了更直观的感受趋势,我们可以画一个曲面图,简单分析,可以直接使用Excel的画图功能,选择曲面图。也可以借助其他工具,如:gnuplot。笔者这边使用的是Excel的画图功能。

当文件小于262M的时候实际测试为 从磁盘读入内存过程,就是写缓存过程,等同于上述:
dd if=/dev/zero of=/sdcard/test bs=1M count=100
当文件大于524M时候,实际测试结果接近真实的磁盘IO性能。
接下来看看re-writer的测试记录:
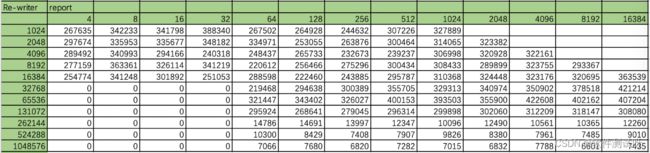

速度差距这点在重写上更加明显,当文件小于262M的时候直接在缓存中读取,速度达到巅峰,当大于等于524M之后,写和重写速度上几乎没有差异。
问题二:我们在实际测试过程中,这么多值,究竟看那个值?
答:都要关注,更换eMCP的测试中,两个性能值都要关注。如果更换eMMC,一般更关注磁盘IO性能(具体看测试总结)
测试总结:
在更换eMCP的测试中,在完成了IO、Mem等压力测试、性能测试之后,最终还要回归到功能上。在功能测试都OK的情况下,在实际功能中去对比性能。如:
OTA升级速度;
刷机速度;
恢复出厂设置速度;
设备其他核心功能性能;
实际测试中遇到过 物料A 的磁盘性能优于 物料B,但是OTA升级速度远低于 物料B 的情况。所以对比测试需要从多个纬度评价分析。
附上测试大纲:
房子要一层一层盖,知识要一点一点学。大家在学习过程中要好基础,多上手实操,话不多说,这里狠狠上一次干货!我熬夜整理好的各阶段(功能、接口、自动化、性能、测开)技能学习资料+实操讲解,非常适合私下里学习,比找资料自学高效多了,分享给你们。
领取关 w/x/g/z/h:软件测试小dao
敲字不易,如果此文章对你有帮助的话,点个赞收个藏来个关注,给作者一个鼓励。也方便你下次能够快速查找。