前言
本文主要基于在Uber的Go monorepo中发现的各种数据竞争模式,分析了其背后的原因与分类,希望能够帮助更多的Go开发人员,去关注并发代码的编写,考虑不同的语言的特性、以及避免由于自身编程习惯所引发的并发错误。
近年来,Uber已经开始采用Golang(简称Go)作为开发微服务的主要编程语言。目前,其Go monorepo(译者注:包含多个不同项目的单个仓库)包含了大约5,000万行代码,以及大约2,100个独特的Go服务。而且,它们都还在持续增长中。
为了实现并发,我们通常会使用go关键字,为函数调用添加前缀,以实现异步式的运行调用。在Go中,此类异步函数调用被称为goroutine。开发人员可以通过创建goroutine(例如,对其他服务的IO或RPC调用),来隐藏延迟。不同的goroutine可以通过消息传递,以及共享内存的方式,来传递数据。其中,共享内存恰好是Go中最常用的数据通信方式之一。
由于goroutineGo很容易被程序员创建和使用,因此它被认为属于“轻量级” 。同时,由Go编写的程序通常会比由其他语言编写的程序具有更强的并发性。例如,通过扫描数十万个运行在数据中心的微服务实例,我们发现Go微服务的并发性可达Java微服务的8倍。
当然,更高的并发性也意味着更多潜在的并发错误。我们常用数据竞争(data race)来描述当两个或多个goroutine访问相同的数据,而且至少有一个处于写入状态时,由于它们之间并没有排序,因此就会发生并发错误。总的来说,根据Go自身的相互作用等特点,数据竞争之类的隐蔽错误非常容易出现,因此我们应该尽量避免。
最近,我们使用动态数据竞争检测技术开发了一个系统,专门用来检测Uber的数据竞争。它在上线的六个月时间内,在我们的Go代码库中,检测到了大约2,000个数据竞争。其中已被开发人员着手修复了的数据竞争约有1,100个。下面,我将向您展示我们已发现的各种常见数据竞争模式。
Go在goroutine中通过引用来透明地捕获自由变量
Go中的嵌套函数(又名closure)通过引用的方式,透明地捕获所有自由的变量。程序员通常无需明确指定在closure语法中,需要捕获哪些自由变量。
这种方式是有别于Java和C++的。Java的lambda仅会根据数值去捕获,而且他们会有意识地避免并发缺陷。而C++则要求开发人员明确地指明是使用数值、还是引用的捕获方式。
当closure较大时,开发人员并不知道closure内使用的变量是否自由,可否通过引用来捕获。而由于引用的捕获、以及goroutine都是并发的,因此Go程序最终可能会因为没能显式地执行同步,而对自由变量进行无序的访问。我们可以通过如下三个示例来证明这一点:
示例1:由循环索引的变量捕获,而导致数据竞争
图1A中的代码显示了迭代Go的切片作业,并通过ProcessJob函数来处理每个元素的作业。

图1A:由循环索引的变量捕获,而导致数据竞争。
在此,开发人员会将厚重的ProcessJob包装在一个匿名的goroutine中。但是,循环索引变量的作业是通过goroutine内部被引用捕获的。当goroutine为首次循环迭代而启动,并访问作业的变量时,父goroutine中的for循环将在切片中更新相同的循环索引变量作业,并指向切片中的第二个元素,这就会导致数据竞争的出现。此类数据竞争可能发生在数值和引用类型上;切片、数组和映射上;以及循环体中的读和写的访问中。为此,Go推荐了一种编码习惯,来隐藏和私有化循环体中循环索引的变量。不过,开发人员并不总是能够遵循这一点。
示例2:由err变量的捕获,所导致的数据竞争

图1B:由err变量的捕获,所导致的数据竞争。
Go一直提倡函数有多个返回值。图1B展示了一种常见的通过返回实际值和错误对象,来指示是否存在错误的用法。可见,当且仅当错误值为nil(空)时,实际的返回值才会被认为是有意义的。因此,我们的通常做法是:将返回的错误对象,分配给名为err的变量,然后检查其是否为空(nilness)。不过,由于我们可以在函数体内调用多个返回错误的函数,因此程序每次都会对err变量进行多次赋值,然后进行是否为空的检查。当开发人员将这个习惯用法与goroutine混合使用时,错误变量就会在closure中被引用捕获。结果,程序对于goroutine中err的读写访问,与随后对封闭函数(或goroutine的多个实例)中相同的err变量的读写操作,就会同时运行。这便导致了数据竞争。
示例3:由已命名的返回变量捕获,所导致的数据竞争
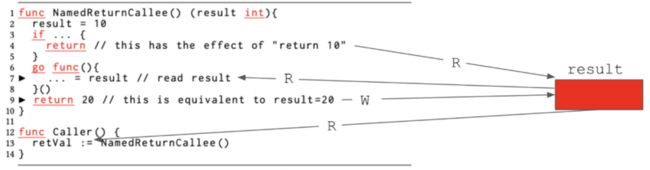
图1C:由已命名的返回变量捕获,所导致的数据竞争。
Go引入了一种被称为已命名返回值的语法块。已命名的返回变量被视为在函数顶部定义的变量,其作用域超出了函数体。而没有参数的return语句,被称为“裸”命名返回值。由于closure的存在,如果将正常(非裸)的返回与已命名的返回相混合、或在具有命名返回的函数中使用延迟返回,那么就可能会引发数据竞争。
在上图1C中的NamedReturnCallee函数返回了一个整数,而且返回变量被命名为result。根据该语法,函数体的其余部分可以对结果进行直接读写,而无需额外声明。如果函数在第4行返回的是一个裸返回,而由于在第2行被赋值为result=10,那么第13行的调用者将看到其返回值为10。编译器则会安排将结果复制到retVal。同时,已命名的返回函数也可以使用如第9行所示的标准返回语法。该语法会让编译器复制return语句中的返回值20,以分配给已命名的返回变量结果。第6行创建了一个goroutine,它会捕获已命名的返回变量的结果。在设置该goroutine时,即使是并发专家也可能认为读取第7行的结果中是安全的,毕竟不存在对同一变量的写入,而且第9行的语句返回的20是一个常量,它似乎并没有触及到已命名的返回变量结果。不过,如前所述,代码在生成的过程中,会将return 20的语句转换为写入结果。此时,一旦我们突然对共享的结果变量进行并发读写,就会产生数据竞争的情况。
切片会产生难以诊断的数据竞争
切片(Slices)实际上是一些动态数组和引用类型。在其内部,切片包含了一个指向底层数组的指针、它的当前长度、以及底层数组可以扩展的最大容量。为了便于讨论,我们将这些变量统称为切片的元字段(meta field)。切片上的一种常见操作便是通过追加操作(append operation)来使其增长。当达到其容量限制时,代码会进行新的分配(例如,对当前的容量翻倍),并更新其对应的元字段。而当一个切片被goroutine并发访问时,Go会通过互斥锁(mutex),来保护对它的访问。

图2:即使使用锁,切片仍会出现数据竞争。
在图2中,开发人员往往以为已经对第6行的切片进行了锁定保护,便可防止数据竞争的出现。而实际上,当第14行将切片作为参数传递给没有锁保护的goroutine时,就会产生数据竞争。具体而言,goroutine的调用导致了切片中的元字段从调用处(第14行)被复制到被调用者(第11行)处。考虑到切片属于引用类型,我们认为在将其传递(复制)到被调用者时,会导致数据竞争的发生。不过,由于切片与指针类型不同,毕竟元字段是按照数值复制的,因此该数据竞争的发生概率非常低。
并发访问Go内置的、不安全的线程映射会导致频繁的数据竞争
哈希表(或称映射)是Go中的内置语言功能。不过,它对于线程是不安全的。如果多个goroutine同时访问同一张哈希表,而且其中至少有一个试图去修改哈希表(插入或删除某项)的话,就会产生数据竞争。开发人员往往认为他们可以同时访问哈希表中的不同项。而实际上,与数组或切片不同,映射(哈希表)是一种稀疏的数据结构,访问某一个元素就可能会导致访问另一个元素,如果在同一过程中发生了另一种插入或删除,那么它将会因为修改了稀疏的数据结构,而导致了数据竞争。
我们甚至观察到了更为复杂的、由并发映射访问产生的数据竞争。其原因是同一个哈希表被传递到了深度调用路径,而开发人员忘记了这些调用路径是通过异步goroutine去改变哈希表的事实。图3便显示了此类数据竞争的示例。
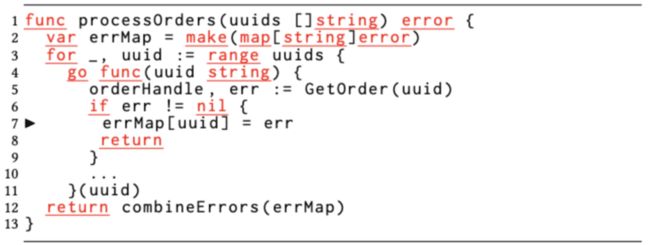
图3:由于并发映射访问导致的数据竞争。
虽然导致数据竞争的哈希表并非Go独有,但是以下原因会让Go更容易发生数据竞争:
- 由于映射是一种内置的语言结构,因此Go开发人员会比其他语言的开发者更频繁地使用映射。例如,在我们的Java存储库中,每MLoC(Millions of Lines Of Code,数百万行代码)里有4,389个映射结构;而在Go中,每MLoC里就有5,950个映射,足足高出了1.34倍。
- 不同于Java的get和put API,哈希表的访问语法类似数组访问语法,虽然易于使用,但是也会意外地与随机访问数据结构相混淆。在Go中,我们可以使用table[key]的语法,轻松查询那些不存在(non-existing)的映射元素。该语法能够简单地返回默认值,而不会产生任何错误。这种容错性对于开发者在使用Go的映射时是非常友好的。
Go开发人员常在pass-by-value时犯错并导致non-trivial的数据竞争
Go建议使用pass-by-value的语义,以简化逃逸分析,并为变量提供更好的栈上分配的机会,进而减少垃圾收集器的压力。
与所有对象皆为引用类型的Java不同,在Go中,对象可以是数值类型(如:结构),也可以是引用类型(如:接口)。由于没有了语法差异,这会导致诸如:sync.Mutex和sync.RWMutex等数值类型,在同步构造中被错误地使用。如果一个函数创建了一个互斥体结构,并通过数值传递(pass-by-value)给多个goroutine调用,那么这些goroutine在并发执行时,不同的互斥对象是不会在操作过程中共享内部状态的。这也就破坏了对于受保护的共享内存区域的互斥访问特性。请参见如下图4所示的代码。

图4A:
由by-reference或by-pointer的方法调用所引起的数据竞争
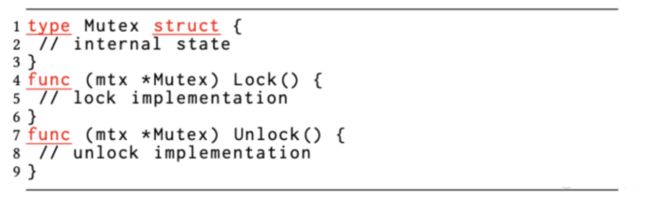
图4B:sync.Mutex的Lock/Unlock签名。
由于Go语法在指针和数值上调用方法是相同的,因此开发人员往往会忽视m.Lock()正在处理互斥锁的副本并非指针这一问题。调用者仍然可以在互斥的数值上调用这些API。而且编译器也会透明地安排传递数值的地址。相反,如果没有此类透明度,该错误就能够会被检测到,并认定为编译器类型不匹配的错误。
据此,当开发人员意外地实现了一个方法,其中的接收者是指向结构的指针,而不是结构的数值或副本时,那么就会发生与此相反的情况。也就是说,调用该方法的多个goroutine,最终会意外地共享结构相同的内部状态。而且,调用者也不会意识到数值类型在接收者处被透明地转换为了指针类型。显然,这都是开发人员所不愿发生的。
消息传递(通道)和共享内存的混合使用使代码变得复杂且易受数据竞争的影响

图5:将消息传递与共享内存混合时的数据竞争。
图5展示了开发人员使用一个专门为信号和等待准备的通道,通过Future来实现的示例。我们可以通过调用Start()方法来启动Future,并通过调用Future的Wait()方法,来阻止Future的完成。Start()方法会创建一个goroutine,以执行一个注册到Future的函数,并记录其返回值(如:response和err)。如第6行所示,goroutine通过在通道ch上发送一条消息,以向Wait()方法发出Future完成的信号。对称地,如第11行所示,Wait()方法块会从通道中获取相应的消息。
在Go中,上下文携带了跨越API边界和进程之间的截止日期、取消信号和其他请求范围的数值。这是在微服务中为任务设置时间线的常见模式。由此,Wait()阻止了被取消(第13行)的上下文、或已完成的Future(第11行)。此外,Wait()被包装在一个select语句(第10行)中,并处于阻止状态,直到至少有一个选择arm准备就绪。
如果上下文超时,则相应的案例将Future的err字段,在第14行上记录为ErrCancelled。此时,对于err的写入与第5行对Future的相同变量的写入操作,便形成了竞争。
Add和Done方法的错误放置会导致数据竞争
sync.WaitGroup结构是Go的组同步结构。与C++的barrier的barrier、以及latch的构造不同,WaitGroup中参与者的数量不是在构造时被确定的,而是动态更新的。在WaitGroup对象上,Go允许进行Add(int)、Done()和Wait()三种操作。其中,Add()会增加参与者的计数,而Wait()会处于阻止状态,直到Done()被调用为count的次数(通常每个参与者一次)。由于在Go中,组同步的使用程度比Java高出1.9倍,因此WaitGroup在Go中常被广泛地使用。
在下图6中,开发人员打算创建与切片itemId里的元素数量相同的goroutine,且并发处理它们。每个goroutine在不同索引的结果切片、以及在第12行对父功能块中,记录其成功或失败的状态,直到所有的goroutine已完成。接着,它会依次访问结果中的所有元素,以计算出被成功处理的数量。

图6A:
由于WaitGroup.Add()的错误放置,导致了数据竞争
为了使该代码能够正常工作,我们需要在第12行调用Wait()时,保证wg.Add(1)在调用wg.Wait()之前所执行的次数,也就是注册参与者的数量,必须等于itemIds的长度。这就意味着wg.Add(1)应该在每个goroutine之前被放置在第5行调用。但是,如果开发人员在第7行错误地将wg.Add(1)放置在了goroutine的主体中,它就无法保证在外部函数WaitGrpExample调用Wait()时,完整地执行。据此,在调用Wait()时,被注册到WaitGroup的itemId的长度就可能会变短。正是出于该原因,Wait()会被提前解除阻止。据此,WaitGrpExample函数则可以从切片结果中开始读取(即:第13行),而一些goroutine则开始并发写入同一个切片。
此外,我们还发现过早地在Waitgroup上调用wg.Done(),也会导致数据竞争。下图6B展示了wg.Done()与Go的defer语句交互的结果。当遇到多个defer语句时,代码会按照“后进先出”的顺序去执行。其中,第9行的wg.Wait()会在doCleanup()运行之前完成。即,父goroutine会在第10行去访问locationErr,而子goroutine可能仍然在延迟的doCleanup()函数内写入locationErr(为简洁起见,在此并未显示)。

图6B:由于WaitGroup.Done()的错误放置
延迟语句排序,并导致了数据竞争。
并发运行测试会导致产品或测试代码中的数据竞争
测试是Go的内置功能。在那些后缀为_test.go的文件里,任何前缀为Test的函数,都可以测试由Go构建的系统。如果测试代码调用了API--testing.T.Parallel(),那么它将与其他同类测试并发运行。我们发现此类并发测试有时会在测试代码中、有时也会在产品代码中产生大量的数据竞争。
此外,在单个以Test为前缀的函数中,Go开发人员经常会编写许多子测试,并通过由Go提供的套件包去执行它们。Go推荐开发人员通过表驱动的测试套件习语(table-driven test suite idiom)去编写和运行测试套件。据此,我们的开发人员在同一个测试中就编写了数十、甚至数百个可供系统并发运行的子测试。开发人员以为代码会执行串行测试,而忘记了在大型复杂测试套件中使用共享对象。此外,当产品级API在缺少线程安全(可能是因为没有需要)的情况下,被并发调用时,情况就会更加恶化。
小结
在上文中,我们分析了Go语言里的各种数据竞争模式,并对其背后的原因进行了分类。当然,不同的原因也可能会相互作用与影响。下表是对各种问题的汇总。
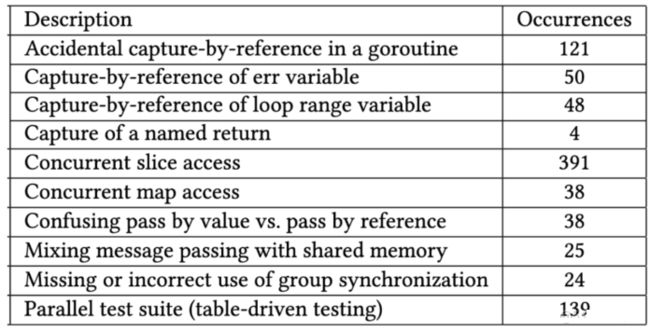
图7:数据竞争待分类。
上面讨论的主要是基于我们在Uber的Go monorepo中发现的各种数据竞争模式,难免有些挂一漏万。其实,代码的交错覆盖也可能产生数据竞争模式。希望上述提到的各种经验能够帮助更多的Go开发人员,去关注并发代码的编写,考虑不同的语言的特性、以及避免由于自身编程习惯所引发的并发错误。
到此这篇关于Go语言中的数据竞争模式详解的文章就介绍到这了,更多相关Go数据竞争模式内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!