【深度学习】神经网络基础:反向传播算法

作者:Simona Ivanova
AI/ML 专家
就职于 Science 杂志
导读
反向传播(Backpropagation,简称 BP)是目前用来训练人工神经网络(Artificial Neural Network,简称 ANN)算法最常用、最有效的方法。
反向传播最早出现于 20 世纪 70 年代,但直到 Geoffrey Hinton(杰佛里·辛顿)在1986 年发表了论文《Learning Representations by Back-Propagating Errors》后才得到各界重视。
杰佛里·辛顿:反向传播算法的发明人之一

Geoffrey Hinton(杰弗里•辛顿)
杰佛里·辛顿是一位英国出生的加拿大计算机学家和心理学家,在类神经网络领域贡献颇多,是反向传播算法的发明人之一,也是深度学习的积极推动者,被称为神经网络和深度学习之父。
此外,辛顿还是伦敦大学盖茨比计算神经科学中心创始人,目前担任加拿大多伦多大学计算机科学系教授。他的主要研究方向是人工神经网络在机器学习、记忆、感知和符号处理等领域的应用。目前,辛顿正在探索如何将神经网络运用到无监督学习算法中。
不过,在辛顿众多科研成果中,反向传播是最为著名的,也是目前大部分有监督学习神经网络算法的基础,建立在梯度下降法之上。其主要工作原理为:
ANN 算法在实际运行过程中一般分为输入层、隐藏层和输出层三类,当算法输出结果与目标结果出现误差时,算法会对误差值进行计算,然后通过反向传播将误差值反馈到隐藏层,通过修改相关参数进行调整,并不断重复此步骤,直到得出与预期相符的结果。
通过反向传播可以让 ANN 算法推导更接近目标的结果,不过,在了解反向传播如何应用于 ANN 算法之前,需要先弄清 ANN 的工作原理。
ANN 的工作原理
ANN 是一种基于人脑神经网络的数学模型或者计算模型,由大量节点(可以理解为生物神经元)相互连接而成。
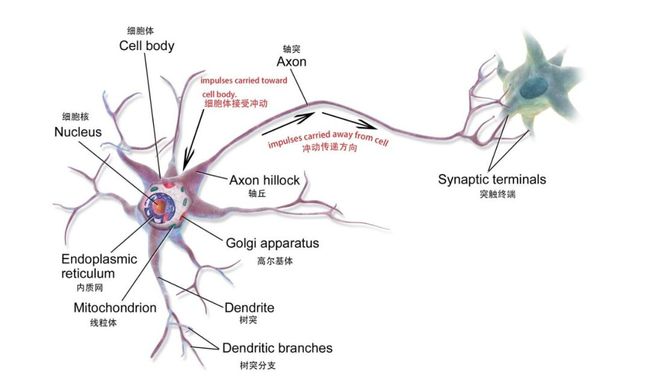
生物神经元

数学模型中的单个节点
每个节点代表一种特定的输出函数,称为激励函数(activation function);两个节点间的连接就代表一个加权值,也叫权重值。在 ANN 算法运行过程中,每个连接会对应一个权重 w 和偏移量 b(又称为 ANN 参数)。输出值则跟节点、权重值和偏移量有关。

单个神经元模型图
(其中a1~an 为输入向量的各个分量;w1~wn 为权重值;b为偏移量;σ 为激励函数,例如 tanh、Sigmoid、ReLU 等)
一个完整 ANN 一般包含一个输入层、多个隐藏层和一个输出层。其中隐藏层主要由神经元组成,承担最主要的运算工作,在实际运行过程中,每一层的神经元都会做出决策,并将决策传导至下一个隐藏层的神经元,直至输出最终结果。
因此,隐藏层层数越多,ANN 就越复杂,结果也就越准确。举例来讲,假如现在要通过一个 ANN 确定输入的动物「是猫」或者「不是猫」,输入这个动物,每个隐藏层内的神经元都对其会进行一次判定,得出结果,并将结果向下传导,直到最后一层神经元输出结果。
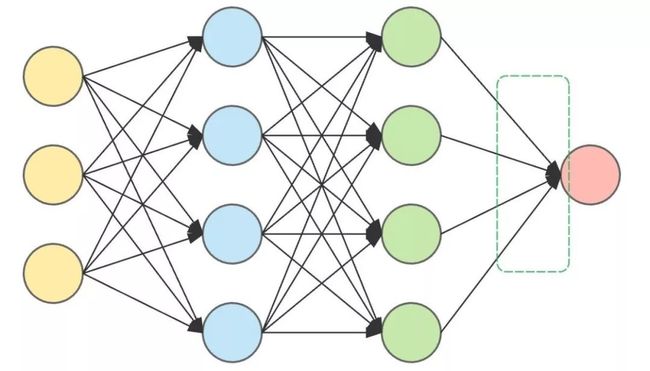
这是一个具有两个隐藏层的 ANN 架构,
两边分别为输入层(左)和输出层(右),中间为两个隐藏层
如果这只动物从生物学上来看是一只猫,但 ANN 显示它「不是猫」,则证明 ANN 输出结果有误。现在,唯一能做的就是返回隐藏层,对权重值和偏移量进行调整,而这个返回并调整数据的过程就是反向传播。
但是要实现反向传播,还需要依赖一类重要的算法——梯度下降算法(Gradient descent),梯度下降极大地加快了学习过程,可以简单理解为:从山顶下山时,挑一条梯度最陡的路最快。
梯度下降算法:反向传播得以实现的关键
因为我们需要不断计算输出与实际值的偏差来修改参数(相差越多修改的幅度越大),所以我们需要用误差函数(Error function,也称损失函数,loss function)来衡量训练集所有样本最终预测值与实际值的误差大小。

其中 y^i 为预测结果,yi 为实际结果。
这个表达式衡量的是训练集所有样本最终预测值与实际值的误差大小,仅与输出层的预测类别有关,但这个预测值取决于前面几层中的参数。如果我们不想将狗认为是猫,就需要让这个误差函数达到最小值。
梯度下降算法是其中一种使误差函数最小化的算法,也是 ANN 模型训练中常用的优化算法,大部分深度学习模型都是采用梯度下降算法来进行优化训练。给定一组函数参数,梯度下降从一组初始参数值开始,迭代移向一组使损失函数最小化的参数值。这种迭代最小化是使用微积分实现的,在梯度的负方向上采取渐变更改。使用梯度下降的典型例子是线性回归。随着模型迭代,损失函数逐渐收敛到最小值。
由于梯度表达的是函数在某点变化率最大的方向,通过计算偏导数得到,所以使用梯度下降方式,会极大地加快学习进程。

梯度下降
在实际操作中,理论上要先检查最后一层中的权重值和偏移量会如何影响结果。将误差函数 E 求偏导,就能看出权重值和偏移量对误差函数的影响。

可以通过链式求导法则来计算这些偏导数,得出这些参数变化对输出的影响。求导公式如下:

为得到上述表达式中的未知量,将 zi 分别对 wi 和 bi 求偏导:
 然后反向计算误差函数关于每一层权重值和偏移量的偏导数,并通过梯度下降法来更新调整后的权重值和偏移量,直到出错的最初层为止。
然后反向计算误差函数关于每一层权重值和偏移量的偏导数,并通过梯度下降法来更新调整后的权重值和偏移量,直到出错的最初层为止。
这个过程就是反向传播算法,又称 BP 算法,它将输出层的误差反向逐层传播,通过计算偏导数来更新网络参数使得误差函数最小化,从而让 ANN 算法得出符合预期的输出。
目前,反向传播主要应用于有监督学习下的 ANN 算法。
超神经 延伸阅读
机器学习基础——偏导数:
https://blog.csdn.net/qq_37527163/article/details/78171002
理解反向传播:https://blog.csdn.net/u012223913/article/details/68942581
杰佛里辛顿简介:
https://zh.wikipedia.org/wiki/%E6%9D%B0%E5%BC%97%E9%87%8C%C2%B7%E8%BE%9B%E9%A1%BF
http://www.cs.toronto.edu/~hinton/
损失函数:https://en.wikipedia.org/wiki/Loss_function
生物神经元:
ttps://en.wikipedia.org/wiki/Neuron#Histology_and_internal_structure
梯度下降算法简述:https://blog.csdn.net/u013709270/article/details/78667531
人工神经网络算法原理:http://www.elecfans.com/rengongzhineng/579673.html
梯度下降法如何实现:https://www.jianshu.com/p/c7e642877b0e
往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载中国大学慕课《机器学习》(黄海广主讲)机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑
AI基础下载机器学习交流qq群955171419,加入微信群请扫码: