NLP—5.word2vec论文精读
- word2vec论文代码复现链接:word2vec论文代码复现
文章目录
-
-
- 一、储备知识
-
- 1. 语言模型的概念
- 2. 语言模型的发展
- 3.语言模型的平滑操作
- 4. 语言模型的评价指标
- 二、研究背景
-
- 1. 词的表示方式
- 三、研究意义
- 四、论文精读
-
- 1. 摘要核心
- 2.Introduction-介绍
- 3. 对比模型
-
- 3.1 前馈神经网络语言模型(NNLM)
- 3.2 循环神经网络语言模型(RNNLM)
- 4.word2vec模型的两种模型架构
-
- 4.1 Skip-gram
- 4.2 CBOW
- 4.3 关键技术
- 5.模型复杂度
- 6.实验结果
-
- 6.1 与对比模型的直接对比实验
- 6.2 不同模型的效率分析
- 7.总结
-
一、储备知识
1. 语言模型的概念
语言模型是用于计算一个句子出现的概率,即语言模型可以判断某一句话从语法上是否通顺(是不是人话),从语义上是否有歧义。在很多时候,我们都要度量一句话的出现概率,一句话的出现概率等同于一句话语法的流畅程度。
2. 语言模型的发展
- 基于专家语法规则的语言模型
语言学家企图总结出一套通用的语法规则,比如形容词后面接名词等 - 基于统计学的语言模型
通过概率计算来刻画语言模型
P L M ( s ) = P L M ( w 1 , w 2 , . . . , w n ) = P L M ( w 1 ) P L M ( w 2 ∣ w 1 ) . . . P L M ( w n ∣ w 1 w 2 . . . w n − 1 ) P_{LM}(s)=P_{LM}(w_1,w_2,...,w_n)=P_{LM}(w_1)P_{LM}(w_2|w_1)...P_{LM}(w_n|w_1w_2...w_{n-1}) PLM(s)=PLM(w1,w2,...,wn)=PLM(w1)PLM(w2∣w1)...PLM(wn∣w1w2...wn−1)
基于马尔科夫假设,假设:任意一个词,它的出现概率只与前面出现的一个词(或者几个词)有关,则可以将语言模型简化如下:
Unigram Model:
P L M ( w ) = ∏ i = 1 n P L M ( w i ) P_{LM}(w)=\prod_{i=1}^nP_{LM}(w_i) PLM(w)=i=1∏nPLM(wi)
Bigram Model:
P L M ( s ) = P L M ( w 1 ) P L M ( w 2 ∣ w 1 ) P L M ( w 3 ∣ w 2 ) . . . P L M ( w n ∣ w n − 1 ) P_{LM}(s)=P_{LM}(w_1)P_{LM}(w_2|w_1)P_{LM}(w_3|w_2)...P_{LM}(w_n|w_{n-1}) PLM(s)=PLM(w1)PLM(w2∣w1)PLM(w3∣w2)...PLM(wn∣wn−1)
Trigram Model:
P L M ( s ) = P L M ( w 1 ) P L M ( w 2 ∣ w 1 ) P L M ( w 3 ∣ w 2 , w 1 ) . . . P L M ( w n ∣ w n − 1 , w n − 2 ) P_{LM}(s)=P_{LM}(w_1)P_{LM}(w_2|w_1)P_{LM}(w_3|w_2,w_1)...P_{LM}(w_n|w_{n-1},w_{n-2}) PLM(s)=PLM(w1)PLM(w2∣w1)PLM(w3∣w2,w1)...PLM(wn∣wn−1,wn−2)
3.语言模型的平滑操作
有一些词或者词组在语料中没有出现过,但是这不能代表它不可能存在。平滑操作就是给那些没有出现过的词或者词组也给一个比较小的概率。
平滑概念指的是试图给没有出现的N-gram分配一个比较合理的数值出来,不至于直接为0。下面介绍多种平滑策略:
- Add-one Smoothing—拉普拉斯平滑
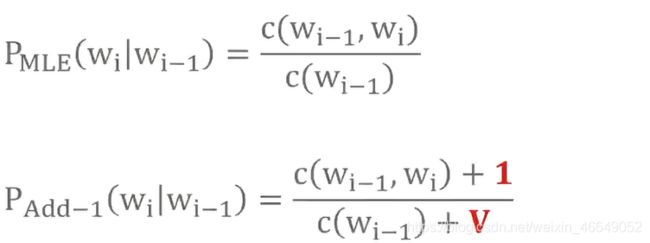
V V V指的是词库的大小。 - Add-K Smoothing—拉普拉斯平滑

k是一个超参数,需要训练
4. 语言模型的评价指标
语言模型实质上是一个多分类问题(这只是一种理解方式,类别是每个词)。 下面介绍一种新的评价指标—perplexity(困惑度)

perplexity越低,表明语言模型认为这句话出现的概率越高,这句话越有可能出现。困惑度最小是1。句子概率越大,语言模型越好,困惑度越小。
二、研究背景
1. 词的表示方式
- one-hot编码
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
表示简单,
问题:词越多,维数越高(词表大小V)无法表示词和词之间关系 - 分布式表示(稠密表示)
维度D(D<
通过词与词之间的余弦相似度来表示词和词之间的关系
三、研究意义
-
衡量词向量之间的相似程度

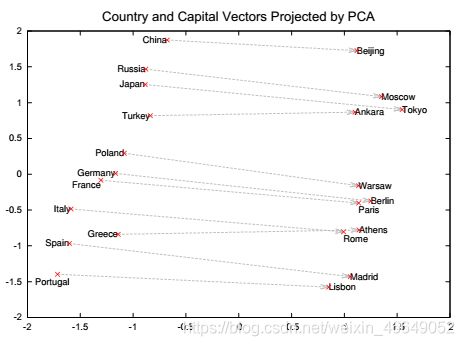
-
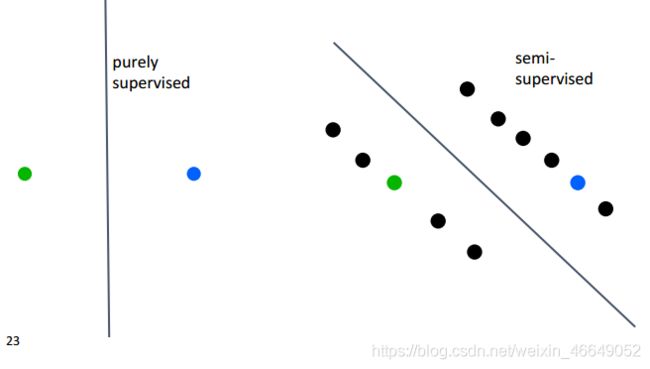
作为预训练模型提升nlp任务
应用到诸如:命名实体识别、文本分类下游任务中

也可以应用到其他NLP任务上,相当于半监督训练
-
双语单词嵌入
四、论文精读
以如下两篇word2vec文章进行精读,第二篇文章是对第一篇文章细节部分的补充。

向 量 空 间 中 词 表 示 的 有 效 估 计 向量空间中词表示的有效估计 向量空间中词表示的有效估计

单 词 和 短 语 的 分 布 式 表 示 及 其 组 成 单词和短语的分布式表示及其组成 单词和短语的分布式表示及其组成
1. 摘要核心
- 提出了两种新颖的模型结构Skipgram和CBOW用来在大规模的预料上计算词向量
- 采用一种词相似度的任务来评估对比词向量质量,比以前的神经网络工作相比有非常大的提升
词对的类比实验来评估对比词向量质量 - 大量降低模型计算量可以提升词向量质量
- 进一步,在我们的语义和句法的词相似度任务上,我们的词向量是当前最好的效果
2.Introduction-介绍
- 传统NLP把词当成最小单元处理,没有词相似度的概念,并且能够在大语料上得到很好的结果,其中好的模型是N-gram模型
- 然而,很多自然语言任务只能提供很小的语料,如语音识别、机器翻译,所以简单的扩大数据规模来提升简单模型的表现在这些任务上不再适用,所以我们必须寻找更加先进的模型
- 数据量较大时,可以采用分布式表示方法,在大语料上,分布式表示的语言模型的效果会超过N-gram模型
3. 对比模型
本文与前馈神经网络语言模型(NNLM)和循环神经网络语言模型(RNNLM)进行对比。
3.1 前馈神经网络语言模型(NNLM)

这个模型也就是所谓的N-gram模型。根据前n-1个单词,预测第n个位置单词的概率,使用梯度下降法优化模型,使得输出的正确的单词概率最大化。

语言模型是无监督任务(不需要标注语料)。那么没有标注的语料是如何做监督学习的呢?根据前n-1个单词,预测第n个位置单词,这样就可以利用无标注语料进行监督学习。
- 输入层
将词映射成向量,相当于一个 1 × V 1×V 1×V的one-hot向量乘以一个 V × D V×D V×D的向量得到一个 1 × D 1×D 1×D的向量

在上图 前馈神经网络语言模型中,可以使用 1 × [ ( n − 1 ) × V ] × [ ( n − 1 ) × V ] × D = 1 × D 1×[(n-1)×V]×[(n-1)×V]×D=1×D 1×[(n−1)×V]×[(n−1)×V]×D=1×D并行计算加速。 - 隐藏层
一个以tanh为激活函数的全连接层
a = t a n h ( d + W x ) a=tanh(d+Wx) a=tanh(d+Wx) - 输出层
一个全连接层,后面接一个softmax函数来生成概率分布。
y = b + U a y=b+Ua y=b+Ua
其中y是一个 1 × V 1×V 1×V的向量,使用softmax进行归一化
P ( w t ∣ w t − n + 1 , . . . , w t − 1 ) = e x p ( y w t ) ∑ i e x p ( y w t ) P(w_t|w_{t-n+1},...,w_{t-1})=\frac{exp(y_{w_t})}{\sum_iexp(y_{w_t})} P(wt∣wt−n+1,...,wt−1)=∑iexp(ywt)exp(ywt)
语言模型困惑度和Loss关系:
多分类的交叉熵损失函数如下:T表示句子中词的个数
L o s s : L = − 1 T ∑ i = 1 T l o g ( P ( w t ∣ w t − n + 1 , . . . , w t − 1 ) ) Loss: L=-\frac{1}{T}\sum_{i=1}^Tlog(P(w_t|w_{t-n+1},...,w_{t-1})) Loss:L=−T1i=1∑Tlog(P(wt∣wt−n+1,...,wt−1))
P P ( s ) = e L PP(s)=e^L PP(s)=eL
3.2 循环神经网络语言模型(RNNLM)

- 输入层
和 NNLM一 样 ,需要将当前时间步的输入转化为词向量 - 隐藏层
对输入和上一时间步的隐藏输出进行全连接层操作
s ( t ) = U w ( t ) + W s ( t − 1 ) + d s(t)=Uw(t)+Ws(t-1)+d s(t)=Uw(t)+Ws(t−1)+d - 输出层
一个全连接层,后面接一个softmax函数来生成概率分布
y ( t ) = b + V s ( t ) y(t)=b+Vs(t) y(t)=b+Vs(t)
其中 y y y是一个 1 × V 1×V 1×V的向量:
P ( w t ∣ w t − n + 1 , . . . , w t − 1 ) = e x p ( y w t ) ∑ i e x p ( y w t ) P(w_t|w_{t-n+1},...,w_{t-1})=\frac{exp(y_{w_t})}{\sum_iexp(y_{w_t})} P(wt∣wt−n+1,...,wt−1)=∑iexp(ywt)exp(ywt)
直观展示如下:
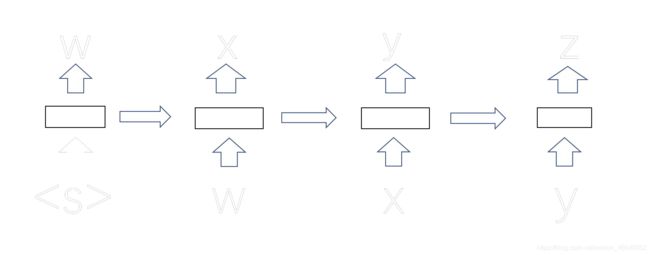
每个时间步预测一个词,在预测第n个词时使用了前n-1个词的信息。
L o s s : L = − 1 T ∑ i = 1 T l o g ( P ( w t ∣ w t − n + 1 , . . . , w t − 1 ) ) Loss: L=-\frac{1}{T}\sum_{i=1}^Tlog(P(w_t|w_{t-n+1},...,w_{t-1})) Loss:L=−T1i=1∑Tlog(P(wt∣wt−n+1,...,wt−1))
4.word2vec模型的两种模型架构
定义Log Linear Models:将语言模型的建立看成一个多分类问题,相当于线性分类器加上softmax
Y = s o f t m a x ( w x + b ) Y=softmax(wx+b) Y=softmax(wx+b)
语言模型基本思想:句子中下一个词的出现和前面的词是有关系的,所以可以使用前面的词预测下一个词。Word2vec可以看作是语言模型的简化。
Word2vec的基本思想:句子中相近的词之间是有联系的,比如今天后面经常出现上午、下午和晚上。所以Word2vec的基本思想是用词来预测词,skip-gram使用中心词预测周围词,cbow使用周围词预测中心词。
4.1 Skip-gram
下面来介绍Skip-gram模型的原理,图中以window=2为例,一个中心词产生4个训练样本
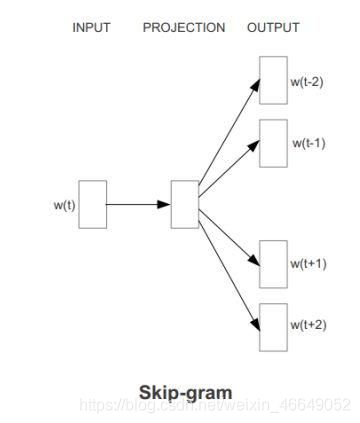
可以得到四个概率
p ( w t − 1 ∣ w t ) p ( w t − 2 ∣ w t ) p ( w t + 1 ∣ w t ) p ( w t + 2 ∣ w t ) p(w_{t-1}|w_t)\\p(w_{t-2}|w_t)\\p(w_{t+1}|w_t)\\p(w_{t+2}|w_t) p(wt−1∣wt)p(wt−2∣wt)p(wt+1∣wt)p(wt+2∣wt)
那么,Skip-gram模型是如何求概率以及如何学习词向量?
如果求 p ( w t − 1 ∣ w t ) p(w_{t-1}|w_t) p(wt−1∣wt)的概率大小,输入是 w t w_t wt,输出是 w t − 1 w_{t-1} wt−1,相当于词表大小的多分类模型。

-
w i w_i wi相当于将index映射成 1 × V 1×V 1×V的one-hot向量
-
W W W为中心词的词向量矩阵,大小为 V × D V×D V×D, w i w_i wi与 W W W矩阵相乘得到一个 1 × D 1×D 1×D的词向量。
-
W ∗ W^* W∗为周围词的词向量矩阵,将词向量矩阵与周围词矩阵 W ∗ W^* W∗相乘得到 1 × V 1×V 1×V的向量,将向量softmax就可以得到概率。
p ( w i − 1 ∣ w i ) = e x p ( u w i − 1 T v w i ) ∑ w = 1 V e x p ( u w T v w i ) p(w_{i-1}|w_i)=\frac{exp(u_{w_{i-1}}^Tv_{w_{i}})}{\sum_{w=1}^Vexp(u_{w}^Tv_{w_{i}})} p(wi−1∣wi)=∑w=1Vexp(uwTvwi)exp(uwi−1Tvwi)
(如果按这个公式理解的话, W ∗ W^* W∗是 V × D V×D V×D) -
目标是使得对应位置的概率越大越好,通过梯度反向传播训练 W ∗ W^* W∗与 W W W, W ∗ W^* W∗与 W W W就是所谓的词向量,那么,我们要选择哪一个作为最终词向量,可以采用如下手段:
- W W W-中心词向量相对来说效果较好
- ( W + W ∗ ) / 2 (W+W^*)/2 (W+W∗)/2(如果按这个公式理解的话, W ∗ W^* W∗是 V × D V×D V×D)
-
Skip-gram的损失函数
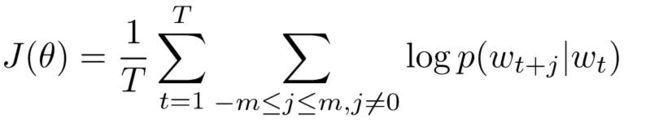
m m m是窗口的大小,损失函数越大越好
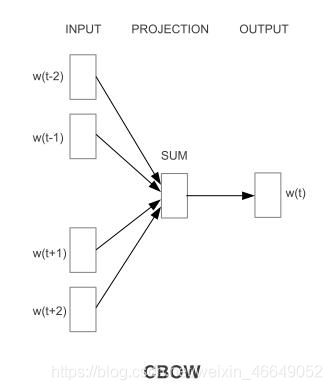
4.2 CBOW
下面来介绍CBOW模型的原理,图中以window=2为例,一个中心词只产生1个训练样本
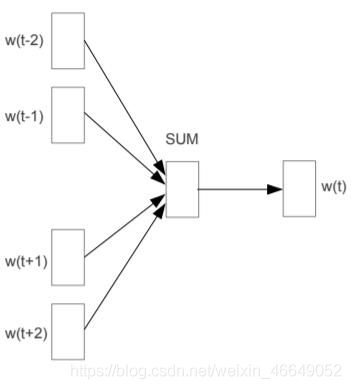
可以得到概率:
p ( w t ∣ w t − 2 , w t − 1 , w t + 1 , w t + 2 ) p(w_t|w_{t-2},w_{t-1},w_{t+1},w_{t+2}) p(wt∣wt−2,wt−1,wt+1,wt+2)
那么,CBOW模型是如何求概率以及如何学习词向量?
如果求 p ( w t ∣ w t − 2 , w t − 1 , w t + 1 , w t + 2 ) p(w_t|w_{t-2},w_{t-1},w_{t+1},w_{t+2}) p(wt∣wt−2,wt−1,wt+1,wt+2)的概率大小,输入是 w t − 2 、 w t − 1 、 w t + 1 、 w t + 2 w_{t-2}、w_{t-1}、w_{t+1}、w_{t+2} wt−2、wt−1、wt+1、wt+2,输出是 w t w_{t} wt,相当于词表大小的多分类模型。
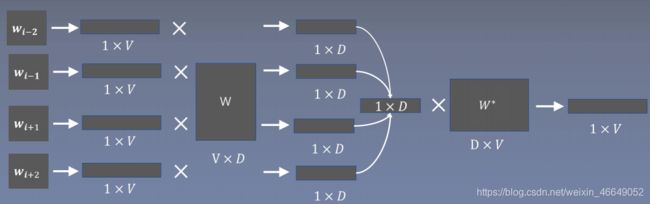
- w t − 2 、 w t − 1 、 w t + 1 、 w t + 2 w_{t-2}、w_{t-1}、w_{t+1}、w_{t+2} wt−2、wt−1、wt+1、wt+2将index映射成 1 × V 1×V 1×V的one-hot向量
- W W W为周围词矩阵,大小为 V × D V×D V×D,将one-hot向量与中心词矩阵相乘得到4个 1 × D 1×D 1×D的词向量,将这4个词向量作求和或者平均,得到1个 1 × D 1×D 1×D的词向量
- W ∗ W^* W∗为中心词矩阵,大小为 D × V D×V D×V,将 1 × D 1×D 1×D的词向量与中心词矩阵相乘得到 1 × V 1×V 1×V的向量,将向量softmax就可以得到概率。
- 目标是使得对应位置的概率越大越好,通过梯度反向传播训练 W ∗ W^* W∗与 W W W, W ∗ W^* W∗与 W W W就是所谓的词向量,那么,我们要选择哪一个作为最终词向量,可以采用如下手段:
- W W W-中心词向量相对来说效果较好
- ( W + W ∗ ) / 2 (W+W^*)/2 (W+W∗)/2(如果按这个公式理解的话, W ∗ W^* W∗是 V × D V×D V×D)
- 损失函数
J ( θ ) = 1 T ∑ t = 1 T p ( w t ∣ w t − 2 , w t − 1 , w t + 1 , w t + 2 ) J(\theta)=\frac{1}{T}\sum_{t=1}^Tp(w_t|w_{t-2},w_{t-1},w_{t+1},w_{t+2}) J(θ)=T1t=1∑Tp(wt∣wt−2,wt−1,wt+1,wt+2)
J ( θ ) = 1 T ∑ t = 1 T e x p ( u w s u m T v w i ) ∑ w = 1 V e x p ( u s u m T v w j ) J(\theta)=\frac{1}{T}\sum_{t=1}^T\frac{exp(u_{w_{sum}}^Tv_{w_{i}})}{\sum_{w=1}^Vexp(u_{sum}^Tv_{w_{j}})} J(θ)=T1t=1∑T∑w=1Vexp(usumTvwj)exp(uwsumTvwi)
损失函数越大越好
4.3 关键技术
softmax涉及到 1 × D 1×D 1×D的 U U U矩阵与 D × V D×V D×V的V的矩阵相乘,得做V次相乘, V V V是特别大的,所以,全连接层也是特别大的。那么,应该如何降低softmax的复杂度呢?下面介绍两种方法:层次softmax与负采样
-
Hierarchical softmax(层次softmax)
层次softmax的基本思想就是将softmax的计算转化成求多个sigmoid的计算,并且少于 l o g 2 V log_2V log2V
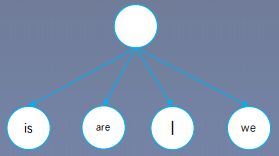
转化为二叉树的结构

所以,如果是满二叉树,只需要计算 l o g 2 V log_2V log2V个sigmoid。softmax需要做V个指数相乘,而sigmoid只需要做一次指数相乘, l o g 2 V < V log_2Vlog2V<V
加速了softmax的运算。
满二叉树需要计算 l o g 2 V log_2V log2V个sigmoid,那么构建带权重路径最短二叉树-Huffman树可以计算少于 l o g 2 V log_2V log2V个sigmoid。
Skip-gram的层次softmax如下:

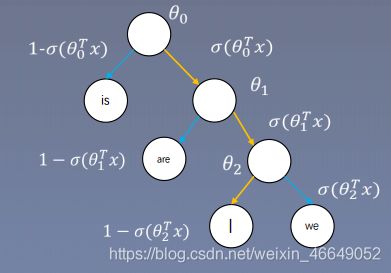
p ( I ∣ c ) = σ ( θ 0 T v c ) σ ( θ 1 T v c ) σ ( 1 − θ 2 T v c ) = σ ( θ 0 T v c ) σ ( θ 1 T v c ) σ ( − θ 2 T v c ) p(I|c)=\sigma(\theta_0^Tv_c)\sigma(\theta_1^Tv_c)\sigma(1-\theta_2^Tv_c)=\sigma(\theta_0^Tv_c)\sigma(\theta_1^Tv_c)\sigma(-\theta_2^Tv_c) p(I∣c)=σ(θ0Tvc)σ(θ1Tvc)σ(1−θ2Tvc)=σ(θ0Tvc)σ(θ1Tvc)σ(−θ2Tvc)
v c v_c vc是中心词向量
推广开来,

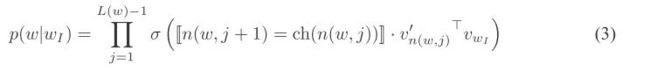
其中, [ ∣ x ∣ ] = 1 o r − 1 [|x|]=1 or -1 [∣x∣]=1or−1
c h ( n ( w , j ) ) = n ( w , j + 1 ) ch(n(w,j))=n(w,j+1) ch(n(w,j))=n(w,j+1)是用来判断是否是右孩子节点
v w 1 v_{w1} vw1是中心词的词向量
v n ′ ( w , j ) v^{'}_n(w,j) vn′(w,j)是词 w w w在树上刀得第 j j j个节点的参数
CBOW的层次softmax如下:
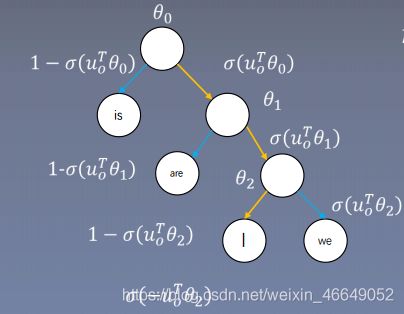
p ( I ∣ c ) = σ ( u o T θ o ) σ ( u o T θ 1 ) σ ( 1 − u o T θ 2 ) = σ ( u o T θ o ) σ ( u o T θ 1 ) σ ( − u o T θ 2 ) p(I|c)=\sigma(u_o^T\theta_o)\sigma(u_o^T\theta_1)\sigma(1-u_o^T\theta_2)=\sigma(u_o^T\theta_o)\sigma(u_o^T\theta_1)\sigma(-u_o^T\theta_2) p(I∣c)=σ(uoTθo)σ(uoTθ1)σ(1−uoTθ2)=σ(uoTθo)σ(uoTθ1)σ(−uoTθ2)
u o u_o uo是窗口内上下文词向量的平均 -
Negative Sampling(负采样)
softmax之所以慢,是因为进行了词表大小V的多分类,所以,我们尝试舍弃多分类,提升速度。一个正样本,选取 k k k个负样本,对于每个词,一次要输出一个概率,总共 k + 1 k+1 k+1个, k < < V k<k<<V 。负采样的优化就是增大正样本的概率,减小负样本的概率

公 式 : S k i p − g r a m 的 负 采 样 公式:Skip-gram的负采样 公式:Skip−gram的负采样
v c v_c vc是中心词向量
u o u_o uo是窗口内上下文词向量
u k u_k uk是负采样上下文词向量
这里还是需要每个词的上下文词向量,总的参数比HS多(每次计算量不多),经过实验结果,可以发现,负采样比层次softmax快,这是因为负采样比层次softmax需要计算更少的概率
那么,应该如何负采样呢?论文中提到一种方法:减少频率大的词抽样概率,增加频率小的词抽样概率。这样做不仅能加速训练,而且能得到更好的结果。
抽样概率计算方法如下:
P ( w ) = U ( w ) 3 4 Z P(w)=\frac{U(w)^{\frac{3}{4}}}{Z} P(w)=ZU(w)43
U ( w ) U(w) U(w)是词 w w w在数据集中出现的概率, Z Z Z为归一化的参数,使得求解之后的概率和为1
J ( θ ) = l o g σ ( u o T v c ) + ∑ i = 1 T E j − P ( w ) [ l o g σ ( − u o T v j ) ] J(\theta)=log\sigma(u_o^Tv_c)+\sum_ {i=1}^TE_{j-P(w)}[log\sigma(-u_o^Tv_j)] J(θ)=logσ(uoTvc)+i=1∑TEj−P(w)[logσ(−uoTvj)]
公 式 : C B O W 的 负 采 样 公式:CBOW的负采样 公式:CBOW的负采样
u o u_o uo是窗口内上下文词向量avg
v c v_c vc是正确的中心词向量
v j v_j vj是错误的中心词向量 -
重采样(subampling of Frequent Words)
自然语言中有这样的共识:文档或者数据集中出现频率高的词往往携带信息较少,而出现频率低的词往往携带信息多。重采样的原因:- 想更多地训练重要的词对,比如训练“France”和“Paris”之间的关系比训练“France”和“the”之间的关系要有用。
- 高频词很快就训练好了,而低频次需要更多的轮次
重采样的方法如下:
P ( w i ) = 1 − t f ( w i ) P(w_i)=1-\sqrt{\frac{t}{f(w_i)}} P(wi)=1−f(wi)t
其中, f ( w i ) f(w_i) f(wi)为词 w i w_i wi在数据集中出现的概率。论文中 t t t选取为 1 0 − 5 10^{-5} 10−5,训练集中的词 w i w_i wi会以 P ( w i ) P(w_i) P(wi)的概率被删除,词频越大, f ( w i ) f(w_i) f(wi)越大, P ( w i ) P(w_i) P(wi)越大,那么词 w i w_i wi就有更大的概率被删除,如果词 w i w_i wi的词频小于等于 t t t,那么 w i w_i wi则不会被剔除,这样就会对高频词少采一些,低频词多采一些
重采样的优点是:加速训练,能够得到更好的词向量
5.模型复杂度
模型复杂度的概念:论文中以计算所需要的参数的数目来代替模型复杂度。
NNML的模型复杂度:

x x x维度 N ∗ D N*D N∗D
U 维 度 V ∗ H U维度V*H U维度V∗H
W 维 度 N ∗ D ∗ H W维度N*D*H W维度N∗D∗H
Q = V ∗ H + N ∗ D + N ∗ D ∗ H Q=V*H+N*D+N*D*H Q=V∗H+N∗D+N∗D∗H
RNNML的模型复杂度:

Q = H ∗ H + H ∗ V Q=H*H+H*V Q=H∗H+H∗V
Skip-gram的模型复杂度:

H S : Q = C ( D + D ∗ l o g 2 V ) N e g : Q = C ( D + D ∗ ( K + 1 ) ) HS:Q=C(D+D*log_2V)\\Neg:Q=C(D+D*(K+1)) HS:Q=C(D+D∗log2V)Neg:Q=C(D+D∗(K+1))
CBOW的模型复杂度:
H S : Q = N ∗ D + D ∗ l o g 2 V N e g : Q = N ∗ D + D ∗ ( K + 1 ) HS:Q=N*D+D*log_2V\\Neg:Q=N*D+D*(K+1) HS:Q=N∗D+D∗log2VNeg:Q=N∗D+D∗(K+1)
模型复杂度对比来看,CBOW的模型复杂度小于Skip-gram的模型复杂度小于循环神经网路语言模型的模型复杂度小于前馈神经网络语言模型的时间复杂度。并且使用负采样要比使用层次softmax更快。
6.实验结果
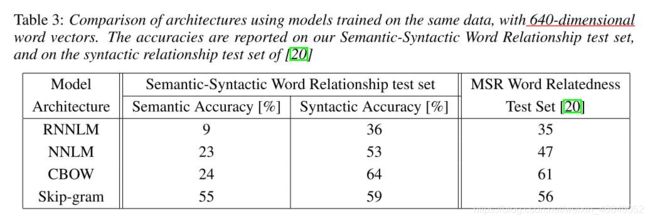
实验采用词对推理数据集,其中有5个语义类、9个语法类

6.1 与对比模型的直接对比实验
6.2 不同模型的效率分析

7.总结
word2vec包括skip-gram(利用中心词预测周围词)与CBOW(利用周围词预测中心词)两种模型架构,还有两种加速softmax训练的关键技术,分别是层次softmax与负采样。层次softmax基本思想就是将softmax转化为多次sigmoid,使用Huffman树的结构;负采样的基本思想是将多分类问题转化为二分类问题:一个中心词与一个周围词就是正样本,一个中心词与一个随机采样得到的词就是负样本。还有第三种技术-重采样(针对自然语言处理中的共识),基本思想就是将高频词删去一些,将低频词尽可能保留,这样就可以加速训练,并且得到更好的词向量。
word2vec相比于语言模型用前面的词来预测词,简化为用词预测词,简化了结构,大大减小了计算量,从而可以使用更高的维度,更大的数据量。
关键点:
- 更简单的预测模型—word2vec
- 更快的分类方案—HS和NEG
创新点:
- 使用词对的预测来代替语言模型的预测
- 使用HS和NEG降低分类复杂度
- 使用重采样加快训练
- 新的词对推理数据集来评估词向量的质量
超参数选择:利用genism做word2vec的时候,词向量的维度和单词数目有没有一个比较好的对照范围呢?
- dim(vector_size)一般在100-500之间选择
可以按照以下标准来确定dim:初始值词典大小V的1/4次方 - min_count一般在2-10之间选择
控制词表的大小
如果对您有帮助,麻烦点赞关注,这真的对我很重要!!!如果需要互关,请评论或者私信!

参考:
-
Efficient Estimation of Word Representations in Vector Space
-
深度之眼带读paper课程