redis 字典(dict)深入分析(抓住两个核心要点)
文章目录
- 前言
- 一、字典
-
- 1、字典是什么?
- 2、字典在 redis 中的应用
-
- 2.1 哈希算法
- 2.2 解决键冲突
- 2.3 rehash
- 2.4 渐进式 rehash
- 3、redis 哪些地方在使用字典?
- 二、底层实现
-
- 1、数据结构
- 2、常用API
- 3、基本操作
-
- 3.1 字典初始化:
- 3.2 添加元素:
- 3.3 查找元素:
- 3.4 删除元素:
- 3.5 _dictRehashStep
- 总结
前言
本文参考源码版本为 redis6.2
字典又称散列表,是用来存储键值(key-value)对的一种数据结构,在很多高级语言中都有实现,如 PHP 的数组。但是 C 语言没有这种数据结构,Redis 是 K-V 型数据库,整个数据库是用字典来存储的,对 Redis 数据库进行任何增、删、改、查操作,实际就是对字典中的数据进行增、删、改、查操作。
根据 Redis 数据库的特点,便可知字典有如下特征。
- 可以存储海量数据,键值对是映射关系,可以根据键以 O(1) 的时间复杂度取出或插入关联值。
- 键值对中键的类型可以是字符串、整型、浮点型等,且键是唯一的。例如:执行 set test “hello world” 命令,此时的键 test 类型为字符串,如 test 这个键存在数据库中,则为修改操作,否则为插入操作。
- 键值对中值的类型可为 String、Hash、List、Set、SortedSet。
一、字典
1、字典是什么?
字典又称散列表,英文叫 “Hash Table”,我们平时也叫它“哈希表”或者“Hash 表”,
散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表。
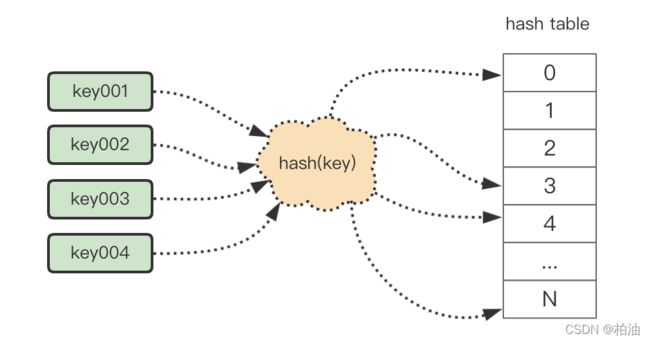
简单来说,为了将我们的 key 映射到 hash table 上,中间通过散列计算,尽可能均匀的映射到 hash table 上。
散列函数:
散列函数,顾名思义,它是一个函数。我们可以把它定义成 hash(key),其中 key 表示元素的键值,hash(key) 的值表示经过散列函数计算得到的散列值。
上图中,将 key001 映射为散列表的下标 0 的 hash(key),便是我们的散列函数。
散列冲突:
虽然散列函数会尽可能的使数据均匀分布在 hash 表中,但仍然存在将多个不同的 key 映射到同一个 hash 表的下标上。这就是散列冲突,主要有以下几种解决方式:
1)开放寻址法:
核心思想:如果出现散列冲突,就重新探测一个空闲位置,将其插入。
经典的探测算法有线性探测法、二次探测、双重散列三种;这里,我们以 线性探测 为例,简单讲讲其原理。
线性探测的原理是,当我们往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。

可以看到, key001、key002 经过 hash 计算都映射到了 hash[3],即同一个索引下标 3 上,产生了 hash 冲突。

最终,处理 hash 冲突之后,数据映射在下标 3、4。当然,这是在理想的情况下,经过一步操作就能找到合适位置,当 hash 表元素很多并且装载较满时,可能经过很多步都无法找到合适位置的时候,这时,性能将急剧下降。
开放寻执法适用场景:当数据量比较小、装载因子小的时候,适合采用开放寻址法。这也是 Java 中的 ThreadLocalMap 使用开放寻址法解决散列冲突的原因。
2)链表法:
相较于开放寻址法的顺位寻找可用 hash 槽的做法,链表法直接摒弃了这一做法,而是在映射的 hash 槽位上处理;这样一来,同一个 hash 槽位上可能出现多个元素,这个时候,采用链表将其串联起来。

适用场景:基于链表的散列冲突处理方法比较适合存储大对象、大数据量的散列表,而且,比起开放寻址法,它更加灵活,支持更多的优化策略,比如用红黑树代替链表。
如何设计散列函数?
在极端情况下,所有的数据经过散列函数之后,都散列到同一个槽里。如果我们使用的是基于链表的冲突解决方法,那这个时候,散列表就会退化为链表,查询的时间复杂度就从 O(1) 急剧退化为 O(n)。
如果散列表中有 10 万个数据,退化后的散列表查询的效率就下降了 10 万倍。更直接点说,如果之前运行 100 次查询只需要 0.1 秒,那现在就需要 1 万秒。这样就有可能因为查询操作消耗大量 CPU 或者线程资源,导致系统无法响应其他请求,从而达到拒绝服务攻击(DoS)的目的。这也就是散列表碰撞攻击的基本原理。
散列函数的设计上要考虑两个原则:
-
首先,散列函数的设计
不能太复杂。过于复杂的散列函数,势必会消耗很多计算时间,也就间接地影响到散列表的性能。 -
其次,散列函数生成的值要尽可能
随机并且均匀分布,这样才能避免或者最小化散列冲突,而且即便出现冲突,散列到每个槽里的数据也会比较平均,不会出现某个槽内数据特别多的情况。
装载因子过大了怎么办?
装载因子越大,说明散列表中的元素越多,空闲位置越少,散列冲突的概率就越大。不仅插入数据的过程要多次寻址或者拉很长的链,查找的过程也会因此变得很慢。
针对数组的扩容,数据搬移操作比较简单。但是,针对散列表的扩容,数据搬移操作要复杂很多。因为散列表的大小变了,数据的存储位置也变了,所以我们需要通过散列函数重新计算每个数据的存储位置。
插入一个数据,最好情况下,不需要扩容,最好时间复杂度是 O(1)。最坏情况下,散列表装载因子过高,启动扩容,我们需要重新申请内存空间,重新计算哈希位置,并且搬移数据,所以时间复杂度是 O(n)。用摊还分析法,均摊情况下,时间复杂度接近最好情况,就是 O(1)。
装载因子阈值需要选择得当。如果太大,会导致冲突过多;如果太小,会导致内存浪费严重。
装载因子阈值的设置要权衡时间、空间复杂度。如果内存空间不紧张,对执行效率要求很高,可以降低负载因子的阈值;相反,如果内存空间紧张,对执行效率要求又不高,可以增加负载因子的值,甚至可以大于 1。
如何避免低效扩容?
大部分情况下,动态扩容的散列表插入一个数据都很快,但是在特殊情况下,当装载因子已经到达阈值,需要先进行扩容,再插入数据。这个时候,插入数据就会变得很慢,甚至会无法接受。
如果我们的业务代码直接服务于用户,尽管大部分情况下,插入一个数据的操作都很快,但是,极个别非常慢的插入操作,也会让用户崩溃。这个时候,“一次性”扩容的机制就不合适了。
为了解决一次性扩容耗时过多的情况,我们可以将扩容操作穿插在插入操作的过程中,分批完成。当装载因子触达阈值之后,我们只申请新空间,但并不将老的数据搬移到新散列表中。
当有新数据要插入时,我们将新数据插入新散列表中,并且从老的散列表中拿出一个数据放入到新散列表。每次插入一个数据到散列表,我们都重复上面的过程。经过多次插入操作之后,老的散列表中的数据就一点一点全部搬移到新散列表中了。这样没有了集中的一次性数据搬移,插入操作就都变得很快了。
这期间的查询操作怎么来做呢?对于查询操作,为了兼容了新、老散列表中的数据,我们先从新散列表中查找,如果没有找到,再去老的散列表中查找。
通过这样均摊的方法,将一次性扩容的代价,均摊到多次插入操作中,就避免了一次性扩容耗时过多的情况。这种实现方式,任何情况下,插入一个数据的时间复杂度都是 O(1)。
2、字典在 redis 中的应用
在第一部分,我们已经介绍了字典的基本原理,以及在解决实际问题中需要去处理的几大关键问题。因此,我们接下来看看,redis 如何结合自身场景去解决这几大问题。
还是这张图,redis 的字典实现本质上就是这种模式,即,链表法。

2.1 哈希算法
相信你也已经明白,这里的哈希算法对应我们上面的 hash(key),需要解决与 hash 表的映射关系。同时,hash 算法的优劣程度基本决定了 hash 表的性能关键。
当字典被用作数据库的底层实现,或者哈希键的底层实现时,Redis 使用 MurmurHash2 算法来计算键的哈希值。
MurmurHash 算法最初由 Austin Appleby 于 2008 年发明,这种算法的优点在于,即使输入的键是有规律的,算法仍能给出一个很好的随机分布性,并且算法的计算速度也非常快。
MurmurHash 算法目前的最新版本为 MurmurHash3,而 Redis 使用的是 MurmurHash2,关于 MurmurHash 算法的更多信息可以参考该算法的主页:http://code.google.com/p/smhasher/。
2.2 解决键冲突
在上面我们已经介绍过散列冲突,以及两大类解决方案及其应用场景。相信你也很清楚,针对 redis 这种大量数据的场景,可以使用我们说到的 链表法 解决冲突。
没错,redis 正是使用 链地址法 解决冲突。
redis 的哈希表使用链地址法(separate chaining)来解决键冲突,每个哈希表节点都有一个next 指针,多个哈希表节点可以用 next 指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向链表连接起来,这就解决了键冲突的问题。
2.3 rehash
通俗的说,hash 表在使用的过程中,数据越来越密集,这个时候会考虑进行扩容以维持 hash 表的高效性;反之为缩容。
其中,习惯性将控制 hash 表元素疏密程度的,叫做 负载因子,需要考虑将其维持在一个合理的范围之内,当哈希表保存的键值对数量太多或者太少时,程序需要对哈希表的大小进行相应的扩展或者收缩。
扩展和收缩哈希表的工作可以通过执行 rehash(重新散列)操作来完成,Redis对字典的哈希表执行 rehash 的步骤如下:
1)为字典的 ht[1] 哈希表分配空间,这个哈希表的空间大小取决于要执行的操作,以及 ht[0]当前包含的键值对数量(也即是 ht[0].used 属性的值):
- 如果执行的是扩展操作,那么 ht[1] 的大小为第一个大于等于 ht[0].used * 2 的 2^n(2的n次方幂);
- 如果执行的是收缩操作,那么 ht[1] 的大小为第一个大于等于 ht[0].used 的 2^n。
直接看源码,更清晰。
/* Our hash table capability is a power of two */
static unsigned long _dictNextPower(unsigned long size)
{
unsigned long i = DICT_HT_INITIAL_SIZE;
if (size >= LONG_MAX) return LONG_MAX + 1LU;
while(1) {
if (i >= size)
return i;
i *= 2;
}
}
2)将保存在 ht[0] 中的所有键值对 rehash 到 ht[1] 上面:rehash 指的是重新计算键的哈希值和索引值,然后将键值对放置到ht[1]哈希表的指定位置上。
3)当 ht[0] 包含的所有键值对都迁移到了 ht[1] 之后(ht[0] 变为空表),释放 ht[0],将 ht[1]设置为 ht[0],并在 ht[1] 新创建一个空白哈希表,为下一次 rehash 做准备。
哈希表的扩展与收缩
当以下条件中的任意一个被满足时,程序会自动开始对哈希表执行扩展操作:
- 服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且哈希表的负载因子大于等于 1。
- 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且哈希表的负载因子大于等于 5。
根据 BGSAVE 命令或 BGREWRITEAOF 命令是否正在执行,服务器执行扩展操作所需的负载因子并不相同,这是因为在执行 BGSAVE 命令或 BGREWRITEAO F命令的过程中,Redis 需要创建当前服务器进程的子进程,而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率。
所以在子进程存在期间,服务器会提高执行扩展操作所需的负载因子,从而尽可能地避免在子进程存在期间进行哈希表扩展操作,这可以避免不必要的内存写入操作,最大限度地节约内存。
另一方面,当哈希表的负载因子小于 0.1 时,程序自动开始对哈希表执行收缩操作。
2.4 渐进式 rehash
扩展或收缩哈希表需要将 ht[0] 里面的所有键值对 rehash 到 ht[1] 里面,但是,这个 rehash 动作并不是一次性、集中式地完成的,而是分多次、渐进式地完成的。
这样做的原因在于,如果 ht[0] 里只保存着四个键值对,那么服务器可以在瞬间就将这些键值对全部 rehash 到 ht[1];但是,如果哈希表里保存的键值对数量不是四个,而是四百万、四千万甚至四亿个键值对,那么要一次性将这些键值对全部 rehash 到 ht[1] 的话,庞大的计算量可能会导致服务器在一段时间内停止服务。
因此,为了避免 rehash 对服务器性能造成影响,服务器不是一次性将 ht[0] 里面的所有键值对全部 rehash 到 ht[1],而是分多次、渐进式地将 ht[0] 里面的键值对慢慢地 rehash 到ht[1]。
以下是哈希表渐进式 rehash 的详细步骤:
- 为 ht[1] 分配空间,让字典同时持有 ht[0] 和 ht[1] 两个哈希表。
- 在字典中维持一个索引计数器变量 rehashidx,并将它的值设置为
0,表示 rehash 工作正式开始。 - 在 rehash 进行期间,每次对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1],当 rehash 工作完成之后,程序将 rehashidx 属性的值增一。
- 随着字典操作的不断执行,最终在某个时间点上,ht[0] 的所有键值对都会被 rehash 至 ht[1],这时程序将 rehashidx 属性的值设为
-1,表示rehash操作已完成。
渐进式 rehash 的好处在于它采取分而治之的方式,将 rehash 键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上,从而避免了集中式 rehash 而带来的庞大计算量。
渐进式 rehash 执行期间的哈希表操作因为在进行渐进式 rehash 的过程中,字典会同时使用ht[0] 和 ht[1] 两个哈希表,所以在渐进式 rehash 进行期间,字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行。
例如,要在字典里面查找一个键的话,程序会先在 ht[0] 里面进行查找,如果没找到的话,就会继续到 ht[1] 里面进行查找,诸如此类。
另外,在渐进式 rehash 执行期间,新添加到字典的键值对一律会被保存到 ht[1] 里面,而ht[0] 则不再进行任何添加操作,这一措施保证了 ht[0] 包含的键值对数量会只减不增,并随着 rehash 操作的执行而最终变成空表。
3、redis 哪些地方在使用字典?
字典结构在 redis 中使用比较广泛,比如我们常说 redis 是 K-V 存储结构,其中,这个主数据库就是用字典来存储 K-V 结构。
除此之外,还有很多其他地方会用到。例如,Redis 的哨兵模式,就用字典存储管理所有的Master 节点及 Slave 节点;
再如,数据库中键值对的值为 Hash 类型时,存储这个 Hash 类型的值也是用的字典。在不同的应用中,字典中的键值对形态都可能不同,而 dictType 结构体,则是为了实现各种形态的字典而抽象出来的一组操作函数。
二、底层实现
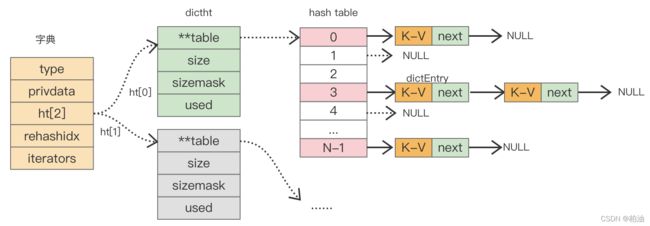
redis 字典实现依赖的数据结构主要包含了三部分:字典、hash表、hash表节点。字典中嵌入了两个 hash 表,hash 表中的 table 字段存放着 hash 表节点,hash 表节点对应存储的是键值对。整体结构如下:
1、数据结构
1)字典
其主要作用是对散列表再进行一层封装,当字典需要进行一些特殊操作时要用到里面的辅助字段。
typedef struct dict {
dictType *type; // 该字典对应的特定操作函数
void *privdata; // 该字典依赖的数据
dictht ht[2]; // hash 表,存储真实数据
long rehashidx; /* 默认 rehashidx == -1 表面目前没有进行rehashing */
unsigned long iterators; /* 当前运行的迭代器数 */
} dict;
在不同的应用中,字典中的键值对形态都可能不同,而 dictType 结构体,则是为了实现各种形态的字典而抽象出来的一组操作函数。
- privdata 字段,私有数据,配合 type 字段指向的函数一起使用。
- ht 字段,是个大小为 2 的数组,该数组存储的元素类型为 dictht,虽然有两个元素,但一般情况下只会使用 ht[0],只有当该字典扩容、缩容需要进行 rehash 时,才会用到ht[1]。
- rehashidx 字段,用来标记该字典是否在进行 rehash,没进行rehash时,值为-1,否则,该值用来表示 hash 表 ht[0] 执行 rehash 到了哪个元素,并记录该元素的数组下标值。
- iterators 字段,用来记录当前运行的安全迭代器数,当有安全迭代器绑定到该字典时,会暂停 rehash 操作。redis 很多场景下都会用到迭代器,例如:执行 keys 命令会创建一个安全迭代器,此时 iterators 会加 1,命令执行完毕则减 1,而执行 sort 命令时会创建普通迭代器,该字段不会改变。
2)hash 表:
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
hash 表的结构体整体占用 32 字节,其中 table 字段是数组,作用是存储键值对,该数组中的元素指向的是 dictEntry 的结构体,每个 dictEntry 里面存有键值对。size 表示 table 数组的总大小。used 字段记录着 table 数组已存键值对个数。
sizemask 字段用来计算键的索引值,sizemask 的值恒等于 size-1。
3)hash 表节点:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
hash 表中元素结构体和我们前面自定义的元素结构体类似,整体占用 24 字节,key 字段存储的是键值对中的键。v 字段是个联合体,存储的是键值对中的值,在不同场景下使用不同字段。
例如,用字典存储整个 redis 数据库所有的键值对时,用的是 *val字段,可以指向不同类型的值;再比如,字典被用作记录键的过期时间时,用的是s64字段存储;
当出现了 hash 冲突时,next 字段用来指向冲突的元素,通过头插法,形成单链表。
2、常用API
// 创建字典
dict *dictCreate(dictType *type, void *privDataPtr);
// 字典扩容
int dictExpand(dict *d, unsigned long size);
// 添加键值对,已存在则不添加
int dictAdd(dict *d, void *key, void *val);
// 添加或查找
dictEntry *dictAddOrFind(dict *d, void *key);
// 添加键值对,若存在则修改,反之,添加
int dictReplace(dict *d, void *key, void *val);
// 删除节点
int dictDelete(dict *d, const void *key);
// 删除节点,但不释放内存
dictEntry *dictUnlink(dict *ht, const void *key);
// 释放字典
void dictRelease(dict *d);
// 查找
dictEntry * dictFind(dict *d, const void *key);
// 收缩字典
int dictResize(dict *d);
// 开启 ressize
void dictEnableResize(void);
// 渐进式 rehash, n 为执行几步
int dictRehash(dict *d, int n);
3、基本操作
3.1 字典初始化:
在 redis-server 启动中,整个数据库会先初始化一个空的字典用于存储整个数据库的键值对。初始化一个空字典,调用的是dict.h文件中的 dictCreate 函数,对应源码为:
static dict *dictCreate(dictType *type, void *privDataPtr) {
dict *ht = hi_malloc(sizeof(*ht));
if (ht == NULL)
return NULL;
_dictInit(ht,type,privDataPtr);
return ht;
}
/* Initialize the hash table */
static int _dictInit(dict *ht, dictType *type, void *privDataPtr) {
_dictReset(ht);
ht->type = type;
ht->privdata = privDataPtr;
return DICT_OK;
}
static void _dictReset(dict *ht) {
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}
dictCreate 函数初始化一个空字典的主要步骤为:申请空间、调用_dictInit 函数,给字典的各个字段赋予初始值。
3.2 添加元素:
1)dictAdd:
int dictAdd(dict *d, void *key, void *val)
{
// 执行添加操作,并返回 dictEntry 结构
dictEntry *entry = dictAddRaw(d,key,NULL);
if (!entry) return DICT_ERR;
// 设置值
dictSetVal(d, entry, val);
return DICT_OK;
}
dictAdd函数主要作用是,添加键值对,执行步骤如下。
1)调用 dictAddRaw 函数,添加键,字典中键已存在则返回 NULL,否则添加键至 hash 表中,并返回新加的 hash 节点。
2)给返回的新节点设置值,即更新其 val 字段。
2)dictAddRaw:
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);
// 获取新元素在 hash 表中的索引下标。如果已存在,则返回-1
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;
// 分配新元素空间,并且采用`头插法`插入链表,因为新增的元素一般被访问的频次更高
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}
dictAddRaw 函数主要作用是添加或查找键,添加成功返回新节点,查找成功返回 NULL 并把旧节点存入 existing 字段。
该函数中比较核心的是调用 _dictKeyIndex 函数,作用是得到键的索引值,有这么两步:
- 先将 key 做 hash 计算
- 再将上一步的 hash 值与 hash 表的的掩码做
与操作,即可得到对应索引下标。
1.字典扩容
随着 redis 数据库添加操作逐步进行,存储键值对的字典会出现容量不足,达到上限,此时就需要对字典的 hash 表进行扩容,扩容对应的源码是 dict.h 文件中的 dictExpand 函数。
// 创建 hash 表或者收缩、扩容 hash 表
int _dictExpand(dict *d, unsigned long size, int* malloc_failed)
{
if (malloc_failed) *malloc_failed = 0;
// 正确性校验
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
dictht n; // 新 hash 表
// 重新计算扩容后的值,始终为 2 的 n 次方幂
unsigned long realsize = _dictNextPower(size);
// 扩容前后,容量一致肯定不行
if (realsize == d->ht[0].size) return DICT_ERR;
// 分配新的 hashtable,并初始化
n.size = realsize;
n.sizemask = realsize-1;
if (malloc_failed) {
n.table = ztrycalloc(realsize*sizeof(dictEntry*));
*malloc_failed = n.table == NULL;
if (*malloc_failed)
return DICT_ERR;
} else
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
// 如果是首次初始化,也就意味着并非 rehash,因此,直接赋值 ht[0]即可
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
// 如果是 rehash 的话,采用 ht[1] 进行操作
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
扩容主要流程为:
- 申请一块新内存,初次申请时默认容量大小为 4 个dictEntry;非初次申请时,申请内存的大小则为当前 hash 表容量的一倍。
- 把新申请的内存地址赋值给 ht[1],并把字典的 rehashidx 标识由 -1 改为 0,
表示之后需要进行rehash操作。
当然,这里不仅可以将空间扩大,也可以缩小。
2.渐进式rehash
rehash 除了扩容时会触发,缩容时也会触发。redis 整个 rehash 的实现,主要分为如下几步完成。
- 给 hash 表 ht[1] 申请足够的空间;
扩容时空间大小为当前容量 * 2,即 d->ht[0].used*2;当使用量不到总空间 10% 时,则进行缩容。缩容时空间大小则为能恰好包含 d->ht[0].used 个节点的 2^N 次方幂整数,并把字典中字段 rehashidx 标识为0。 - 进行
rehash操作调用的是dictRehash函数,重新计算 ht[0] 中每个键的 hash 值与索引值(重新计算就叫rehash),依次添加到新的 hash 表 ht[1],并把旧 hash 表中该键值对删除。把字典中字段 rehashidx 字段修改为 hash 表 ht[0] 中正在进行 rehash 操作节点的索引值。
3)rehash 操作后,清空 ht[0],然后对调一下 ht[1] 与 ht[0] 的值,并把字典中 rehashidx 字段标识为-1。
redis 优化的思想很巧妙,利用分而治之的思想了进行 rehash 操作,大致的步骤如下。
执行插入、删除、查找、修改等操作前,都先判断当前字典 rehash 操作是否在进行中,进行中则调用 dictRehashStep 函数进行 rehash 操作(每次只对1个节点进行rehash操作,共执行1次)。
除这些操作之外,当服务空闲时,如果当前字典也需要进行 rehsh 操作,则会调用incrementallyRehash 函数进行批量r ehash 操作(每次对100个节点进行rehash操作,共执行1毫秒)。
在经历 N 次 rehash 操作后,整个 ht[0] 的数据都会迁移到 ht[1] 中,这样做的好处就把是本应集中处理的时间分散到了上百万、千万、亿次操作中,所以其耗时可忽略不计。
3.3 查找元素:
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
uint64_t h, idx, table;
if (dictSize(d) == 0) return NULL; /* dict is empty */
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
while(he) {
// 定位到特定的 hash 槽,再尝试从链表中匹配
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}
查找键的源码,整个过程比较简单,主要分如下几个步骤。
- 根据键调用 hash 函数取得其 hash 值。
- 根据 hash 值取到索引值。
- 遍历字典的两个 hash 表,读取索引对应的元素。
- 遍历该元素单链表,如找到了与自身键匹配的键,则返回该元素。
- 找不到则返回 NULL。
3.4 删除元素:
dict.h 文件中的 dictDelete 函数,其主要的执行过程为:
int dictDelete(dict *ht, const void *key) {
return dictGenericDelete(ht,key,0) ? DICT_OK : DICT_ERR;
}
static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree) {
uint64_t h, idx;
dictEntry *he, *prevHe;
int table;
if (d->ht[0].used == 0 && d->ht[1].used == 0) return NULL;
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
prevHe = NULL;
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) {
/* Unlink the element from the list */
if (prevHe)
prevHe->next = he->next;
else
d->ht[table].table[idx] = he->next;
if (!nofree) {
dictFreeKey(d, he);
dictFreeVal(d, he);
zfree(he);
}
d->ht[table].used--;
return he;
}
prevHe = he;
he = he->next;
}
if (!dictIsRehashing(d)) break;
}
return NULL; /* not found */
}
主要流程:
- 查找该键是否存在于该字典中;
- 存在则把该节点从单链表中剔除;
- 释放该节点对应键占用的内存、值占用的内存,以及本身占用的内存;
给对应的 hash 表的 used 字典减1操作。
当字典中数据经过一系列操作后,使用量不到总空间<10% 时,就会进行缩容操作,将 redis 数据库占用内存保持在合理的范围内,不浪费内存。
void tryResizeHashTables(int dbid) {
if (htNeedsResize(server.db[dbid].dict)) // 判断是否需要缩容,used/size < 10%
dictResize(server.db[dbid].dict); // 执行缩容操作
if (htNeedsResize(server.db[dbid].expires))
dictResize(server.db[dbid].expires);
}
dictResize 缩容函数:
int dictResize(dict *d)
{
unsigned long minimal;
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht[0].used;
if (minimal < DICT_HT_INITIAL_SIZE) // 容量最小值为4
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal); // 将容量调整到指定大小
}
整个缩容的步骤大致为:判断当前的容量是否达到最低阈值,即 used/size < 10%,达到了则调用 dictResize 函数进行缩容,缩容后的函数容量实质为 used 的最小 2^N 整数。缩容操作和扩容操作实质差不多,最终调用的都是 dictExpand 函数,之后的操作与扩容一致。
3.5 _dictRehashStep
从 redis 的源码中我们可以看到,有多个地方通过调用 _dictRehashStep 函数,进而调用 dictRehash 函数,来执行 rehash,它们分别是:dictAddRaw,dictGenericDelete,dictFind,dictGetRandomKey,dictGetSomeKeys。
不管是增删查哪种操作,这 5 个函数调用的 _dictRehashStep 函数,给 dictRehash 传入的循环次数变量 n 的值都为 1:
static void _dictRehashStep(dict *d) {
// 给 dictRehash 传入的循环次数参数为1,表明每迁移完一个 hash槽 ,就执行正常操作
if (d->iterators == 0) dictRehash(d,1);
}
这样一来,每次迁移完一个 hash 槽,hash 表就会执行正常的增删查请求操作,这就是在代码层面实现渐进式 rehash 的方法。
总结
在实现 rehash 时,都需要解决哪些问题?主要有以下三点:什么时候触发 rehash?rehash 扩容扩多大?rehash 如何执行? 结合文章,你可以自己思考总结下。
实现一个高性能的 hash 表不仅是 redis 的需求,也是很多计算机系统开发过程中的重要目标。而要想实现一个性能优异的 hash 表,就需要重点解决哈希冲突和 rehash 开销这两个问题。
好,至此,你已经理解了本文两大核心:哈希冲突 和 rehash 开销,你以为就结束了吗?
答案是否定的,均摊法思维引入的渐进式 rehash 解决了高效扩容问题的同时,也给字典的遍历带来了一定困难;关于字典的遍历问题,咱们下篇接着聊~
Redis 5设计与源码分析 【陈雷】
Redis 设计与实现 【黄健宏】