【高级数据处理技术】数据过滤,高级数据填补,初,高级数据转化
数据过滤:
有些单一变量虽然对整体客群具有鉴别力,但不一定对特定客群亦具有鉴别力
案例:比如年龄,在申请评分的时候,年龄这个字段是具有一定程度的鉴别力的,年龄越大违约率(坏件率)越低。但如果将样本按收入区分为高收入分群和低收入分群,可以看出坏件率(bad%)在高收入分群中,年龄的差异非常不明显,
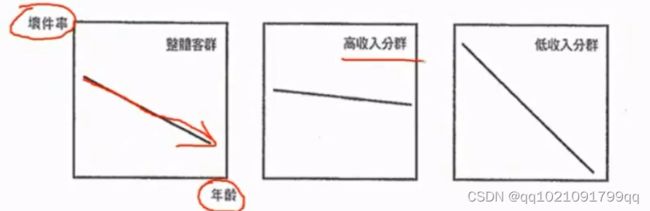
如果能用客群区隔化模型,替每个不同的客群找出适合它的变量,可以大幅度提升整体模型的鉴别力。
案例:信用卡行为评分模型
往来期间不足五个月予以排除,因无足够期间的历史数据作为自变量来源
延滞客群适用催收评分模型,予以排除
根据我们业务知识和统计实证皆指出全清户(Transactor)与循环使用户(Revolver)在风险程度与风险形态是均有显著差异,故选择客户【是否使用循环】作为主要分群方式
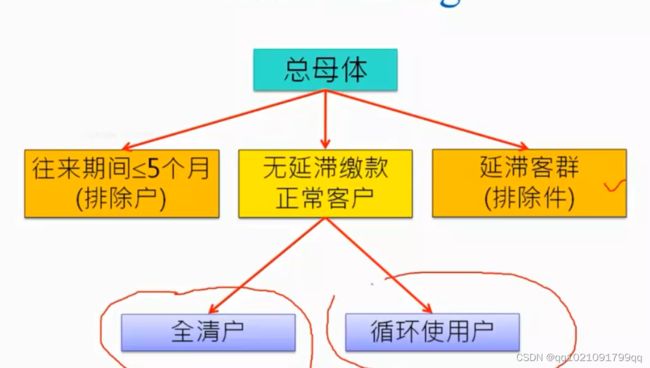
全清户和循环使用户切割开来,用不同的字段进行建模学习。
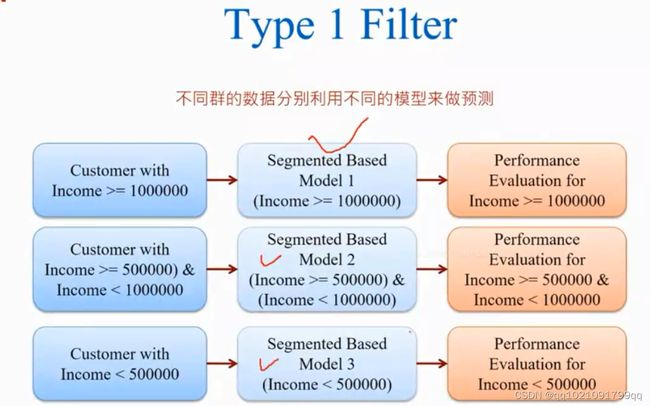
类型1:数据过滤模式1
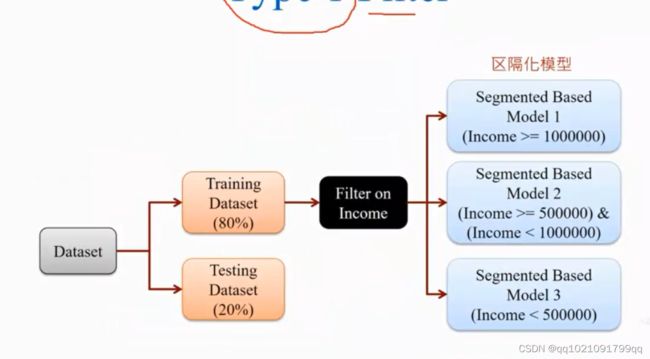
将数据分为训练集和测试集,8:2左右,用收入给数据进行区隔。对3个客群建不同的模型。
然后将测试集也进行同样的分群。
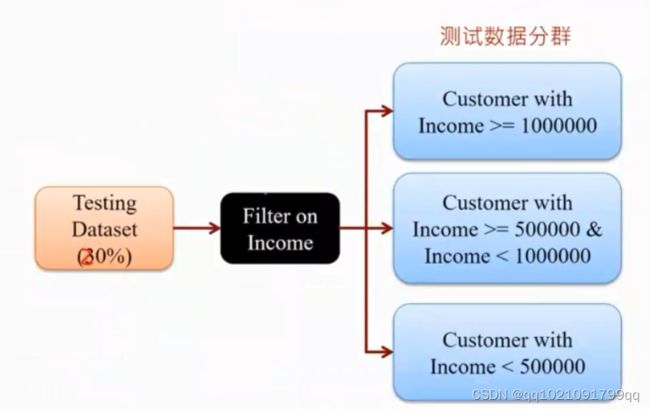
不同群的数据,用不同模型来进行预测。
类型2:数据过滤模式2
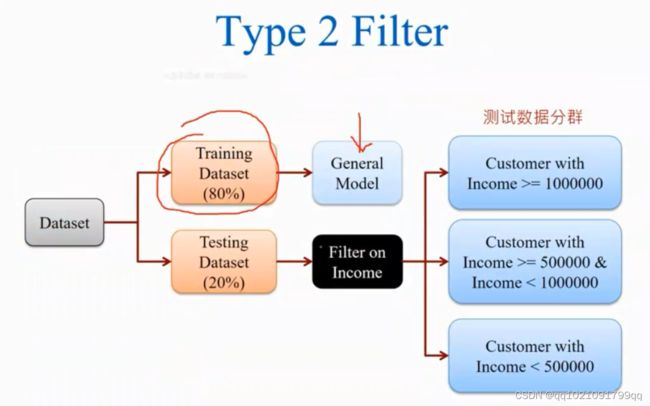
将数据分为训练集,测试集。这次不对百分之80的训练集进行分群。对他继续普通的建模。然后我们对测试集的3个群都做预估
了解模型对不同群的效能。决定下一波的营销重点,例如建模之后,小于50万收入的群体建模效果不好,营销重点就放在前两者身上,
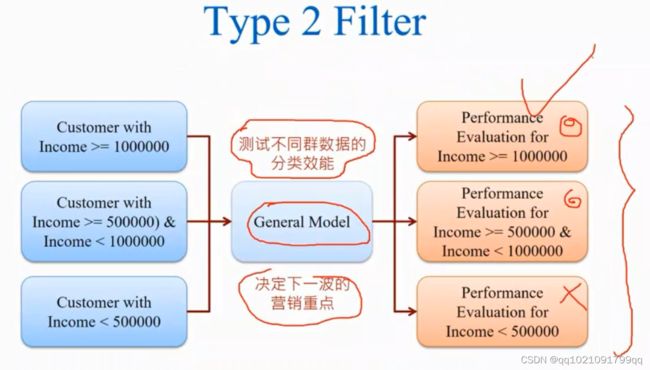
然后营销后复盘营销效果,再决定下一波的营销策略。
-
-
- 缺失值的高级填补技术
-
首先谈谈简单的处理方法
数据缺失的简单处理方法:
1直接忽略法:将整笔数据删除,
是处理数据缺失最简单的方法
(1)当收集的数据量很多,而缺失数据仅仅只占其中一部分时,就可以使用该方法
(2)或者当进行分类建模时,若数据的分类标记(class lable)为空,这笔数据因无法被正确分类,便可直接删除。(唯一处理方法,机器学习不允许目标字段有空值。必须要有目标字段,不然无法学习会报错)
(3)当字段中缺失数据大于百分之五十时,直接删除
*(4)还有一种特殊情况,当你认为空值也是行为的另一种呈现时,(空值也有意义时),可以采用指示变量的方法(indicator variable)也就是哑变量。处理数据缺失的特殊方法,也是当字段中缺失数据大于百分之50时直接删除。
直接忽略法的缺点:数据缺失比例较大时,会造成大量数据流失
2人工填补法:
(1)当某会员数据的生日字段有缺失时,直接让员工打电话给会员询问其生日字段。
(2)了解数据为何缺失,缺失原因,然后用适当的值进行填补。比如性别就可以用身份证号来填补,一些比例型字段,可能是因为没有消费,所以导致了控制,。
准确率很高
人工填补法的缺点:数据缺失较多时,会消耗大量的时间和人力负担严重。
3(机器)自动填补法:
如果是类别型字段,比如婚姻情况,教育程度等等。
(1)可以填入一个通用的常数值:比如未知(unknown)成为一个新的类别

1为本科下,2为本科以上,0为空,3为未知,456为异常值,使用吧0,456
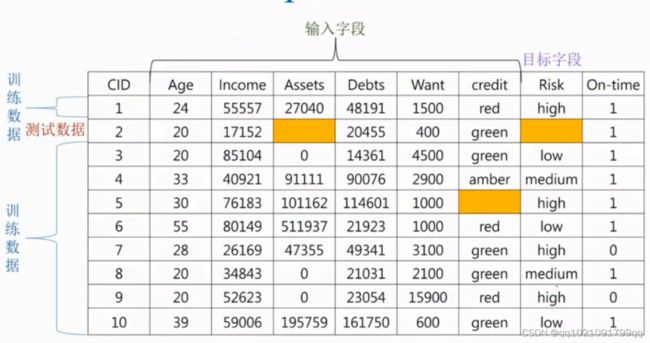
(2)填入该字段的众数:但该方法不够客观,可以用分群的方式,使用分群里的群体众数(下图就可以根据credit来分群进行众数填补)
(3)更精确的方法是利用模型求出比较可能的数值:也就是把填补缺失值的问题当做预测分类类别的问题来求解。
算法是需要能接受输入字段有空值,还能建模的算法
可以采取KNN填补,随机森林填补,XGboosting填补
数值型字段
(1)填入一个通用的常数:如填入0(但需要检查(check)它的含义)
(2)填入平均值,也可以使用分群(比如使用年龄分群填补资产的平均值)
(3)更精确的方法是利用模型求出比较可能的数值:也就是把填补缺失值的问题当做预测数值类别的问题来求解。
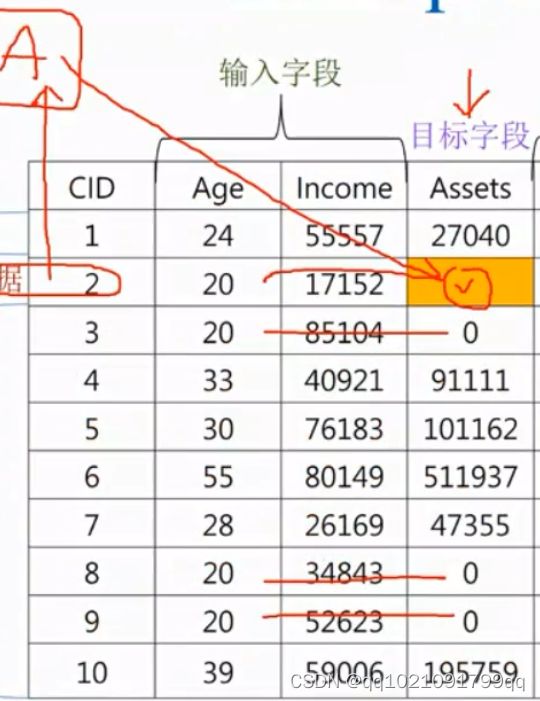
需要能接受输入字段有空值。算法同样是KNN填补,随机森林填补,XGboosting填补
数据清洗都是用训练集来进行清洗。
-
-
- 初级数据转化技术
-
类别型字段的编码,顺序型字段的编码
分类性变量编码方法:
One-hot encoding(机器学习里的编码叫法)
Dummy(统计学里的编码叫法)

使用虚拟变量时会出现虚拟变量陷阱,也就是变量之间会出现高度的多元共线性或者高度相关性。比如Male和female两个虚拟变量做one-hot encoding编码的话就会出现高度相关性,比如性别,01,10,有一个字段会多余。所以一般都会要删除一行字段。确保不会出现高度相关性
如果一个字段有多种描述的特征标签的情况就应该按下图编码。
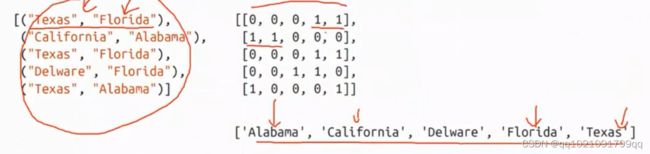
顺序型变量编码方法:

看成数值变量,同间隔编码。
编码缺点。数值的大小不能直接用1234编码,要考虑程度,比如图中的high就应该是3.但是由于中间多了个比medium多一点的程度,变成4了,效果就会不那么理想。
-
-
- 高级数据转化技术
-
类别型字段泛化分类变量(等级变量)
数据一般化:一般用于住址等,住址太细了,可以转化为城市,或者区域
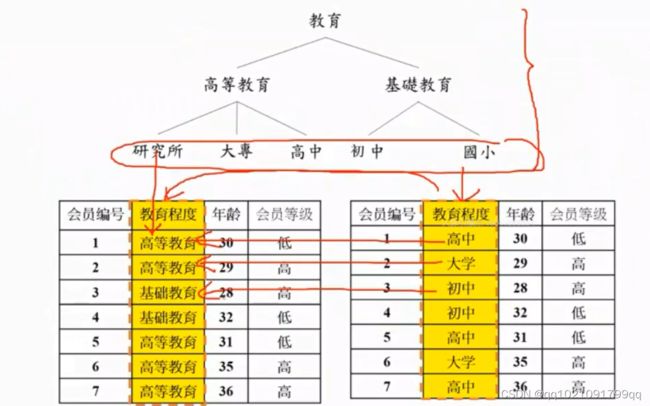
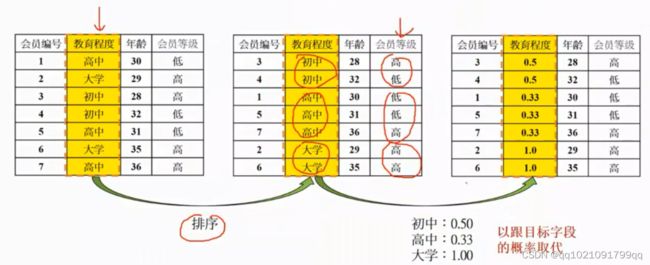
数据一般化2:当需要把分类变量转化为数值时。可以用目标字段的概率取代类别
数值型字段趋势离散化:
为什么要进行数值型数据的离散化呢?
建模经验让我们发现,通常数值型数据的不稳定容易导致模型的错误。
经常会出现一种情况,训练数据的预测值非常准确,但是测试数据集的预测变的非常不准确。
原因很大部分是因为训练数据集的字段分布和测试数据集的字段概率分布的不一致。
如图,在25岁上,训练数据集的逾期概率为0.1,但是在测试数据集是百分之100.
皮尔森相关系数表明,二者不仅不习惯,甚至还有相反的倾向。

如果年龄是建模的重要输入字段所以二者的模型准确度肯定大不相同
所以数值型字段离散化,有助于我们建立模型。
数值型字段离散化的优点:
1.使数据精简,降低数据的复杂度,让数据更容易被解释
2.可以支持许多无法处理数值型字段的算法
比如关联规则(Association Rules)算法
3.可以提高分类器的稳定性,进而提升分类模型得到准确度
4.可以找到该输入字段在目标字段是的趋势(TREND)性有助于未来解读(所以我们离散化的最好结果就是能体现出目标字段的趋势)
利用离散化,切割出数个区间,来取代值域上的众多数据数值
1.人工分离法:
根据经验,专家建议,对数据进行切割,比如年龄这些
2.基本装箱法(binning Method):
等宽(Equal-Width-Interval)装箱法,每个箱内范围相同
等频(Equal-Frequency-interval)装箱法,每个箱内频数相同
若我们将前图的分布进行等宽(8个区间,每个间隔6.125)区隔,可以得到皮尔森相关系数为0.711正相关,稳定性和准确性都大幅提升。
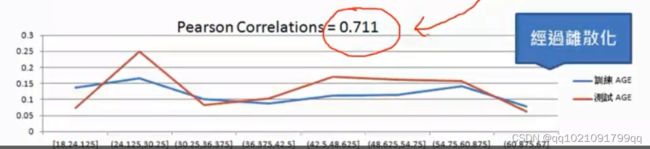
主要是结果还能让人易于理解与解释也是非常重要的
一个好的易于理解和解释的离散化结果,输入字段和目标字段会有明显的趋势性
下图x轴是额度使用率,y轴是变坏客户的概率
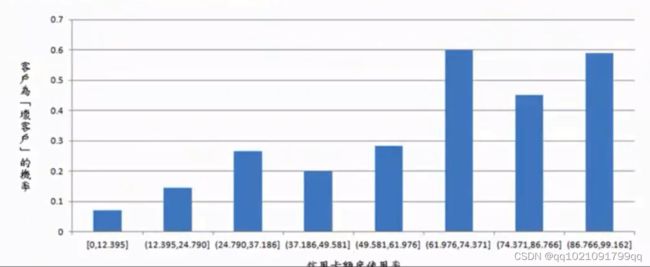
按业务经验来说,信用卡额度的使用率变高,客户坏账的概率也会变高,但是离散化的结果体现的却是有波动,高高低低的起伏现象。如果我们进行业务建模,即使加入该字段会让模型效果更好,企业也不敢使用该字段,(因为不能确定未来数据变化是不是会出现不同的趋势)也就是与业务经验不符。
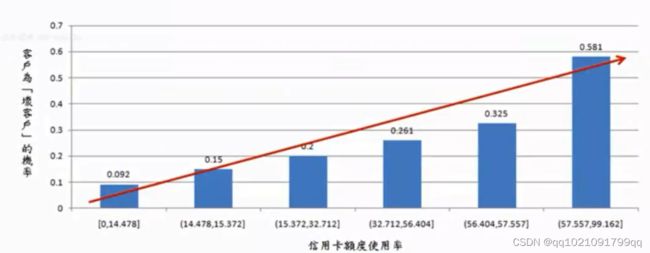
一个好的离散化结果就应该如上图所示,x轴与y轴呈现单调递增的情况,与业务经验符合。
可行的做法:先用等宽或者等频将数值型字段的值分为15~20个小区间,然后按照呈现的分布情况适当的加以合并。
案例:

先进行分为15~20个小区间,
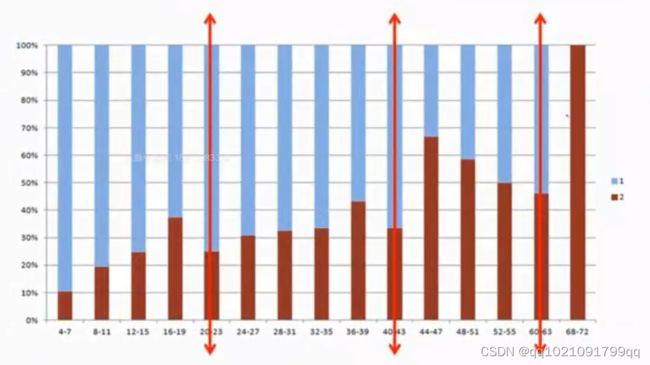
当违约率从高到低时就是我们的一个切割点,该图就可以合并为4个区间。
4-21,22-41,42-61,62-72
因为62-72这个区间只有一笔数字,所以再额外合并为42-72
最终切割为3个区间
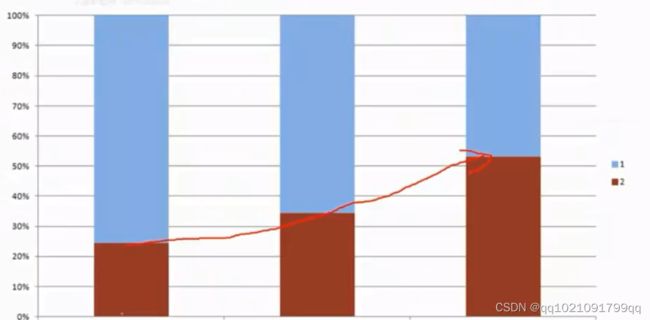
这上图中就可以看出,结果相当理想,违约率逐步递增,符合业务常识。
这就是一个比较好的