【OpenCV实战】OpenCV实现人脸检测详解(含代码)
OpenCV中有许多可以进行人脸、人眼检测的特征文件,今天我们利用OpenCV中自带的特征文件haarcascade_frontalface_default.xml来进行人脸检测。
【OpenCV实战】OpenCV实现人脸检测“超详解”(含代码)
- 1、整体思路
- 2、代码详解
-
- 2.1从百度爬取图片
- 2.2训练数据
- 2.3测试,绘制框和标签
- 3、总结
- 4、参考
1、整体思路
第一:利用Python根据特征词从百度爬取人物图片
第二:训练
第三:测试,绘制框和标签
2、代码详解
2.1从百度爬取图片
本段代码实现的功能:根据特征词从百度爬取一定数量的图片
import requests
import os
import re
# word是要爬的图片名字;max_num 是要爬取的数量
word = input("请输入关键词:")
max_num = input("请输入图片最大数量:")
# j用来标记图片数量
j = 1
#爬取图片的类
class PaChong:
def __init__(self, word, i):
# path是图片存放的地方
self.path = "./xqImg/" + word + "/"
# 第几页
self.page = i / 10 + 1
# 如果文件夹不存在,则创建文件夹
if not os.path.exists(self.path):
os.mkdir(self.path)
# 发出requests请求
def requests_get(self, url):
req = requests.get(url, timeout=30)
req.encoding = "utf-8"
self.req = req.text
# 正则找到图片链接
def get_imgurl(self):
imgurls = re.findall('"objURL":"(.*?)"', self.req, re.S)
self.imgurls = imgurls
print(self.imgurls)
# 下载图片到本地
def download(self):
global j
for imgurl in self.imgurls:
path = self.path + str(j)
#try可以防止因网络不好造成的错误
try:
# 写入文件
with open(path + "2.jpg", "wb") as f:
r = requests.get(imgurl)
f.write(r.content)
print("%s下载成功" % path)
j += 1
if j >= int(max_num):
break
except Exception as e:
print(e)
# 当发生异常时,直接跳过
continue
print("第{}页下载结束!".format(self.page))
# 通过pn参数实现翻页,第一页为0,,间隔为20
for i in range(0, 30, 10):
url = "https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word={0}&pn={1}&gsm=50&ct=&ic=0&lm=-1&width=0&height=0".format(
word, i)
Run = PaChong(word, i)
Run.requests_get(url)
Run.get_imgurl()
Run.download()
这里我从百度上爬取了黄渤和孙红雷的各25张图片(只是训练一个小demo),效果图如下。为了方便以后的训练过程,将文件夹的名称改为“01”和“02”,作为相应类别的标签。


2.2训练数据
首先从OpenCV官网下载对应版本的Sources,data文件夹中有是特征文件,我们一般选用haarcascade_frontalface_default.xml。

我们要创建一个cv2.CascadeClassifier对象,该对象可以用来检测人脸。代码如下:
face_detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
下面是训练的代码:
import cv2
import os
import numpy
from imutils import paths
import random
root_path = "./xqImg"
def getFacesAndLabels():
"""读取图片特征和标签"""
global root_path
faces = []
lables = []
# 获取人脸检测器
face_detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 获取图片路径
imagePaths = sorted(list(paths.list_images(root_path)))
print(imagePaths)
for path in imagePaths:
#修改文件路径,防止在读取文件时cv2报错
path = path.replace('\\','/')
# 读取图片
im = cv2.imread(path)
# 转换灰度
grey = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
# 读取人脸数据,获得人脸的位置信息
face = face_detector.detectMultiScale(grey)
for x, y, w, h in face:
# 获得标签,文件夹的名称为类别(1和2)
label = path.split("/")[-2]
lables.append(int(label))
# 图像分割获得人脸数据
faces.append(grey[y:y+h, x:x+w])
return faces, lables
# 调用方法获取人脸信息及标签
faces, labels = getFacesAndLabels()
# 获取训练对象
recognizer = cv2.face.LBPHFaceRecognizer_create()
# 训练数据
recognizer.train(faces, numpy.array(labels))
# 保存训练数据
recognizer.write('./trainer/trainer.yml')
2.3测试,绘制框和标签
利用训练好的文件trainer.yml进行人脸检测,通过predict函数返回人脸标签和置信度,
import cv2
#对应的类别标签
Name ={'1':'huang','2':'sun'}
# 加载训练数据集
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.read('./trainer/trainer.yml')
# 准备识别的图片
im = cv2.imread('32.jpg')
grey = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
# 检测人脸
face_detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
face = face_detector.detectMultiScale(grey)
for x, y, w, h in face:
# 返回人脸标签和可信度,可信度数值越低,可信度越高(用词不当,不要在意)
label, confidence = recognizer.predict(grey[y:y+h, x:x+w])
# 这里将60作为界限,当检测检测值为60时,我们就确定人物
if confidence <= 60:
# 绘制预测框
cv2.rectangle(im, (x, y), (x + w, y + h), (255, 255, 0), 2)
Label = Name[str(label)]
# 显示标签
cv2.putText(im,Label,(x, y),cv2.FONT_HERSHEY_COMPLEX, 0.7, (0, 255, 225), 2)
else:
print("未匹配到数据")
cv2.imshow('im', im)
cv2.waitKey(0)
# 销毁窗口
cv2.destroyAllWindows()
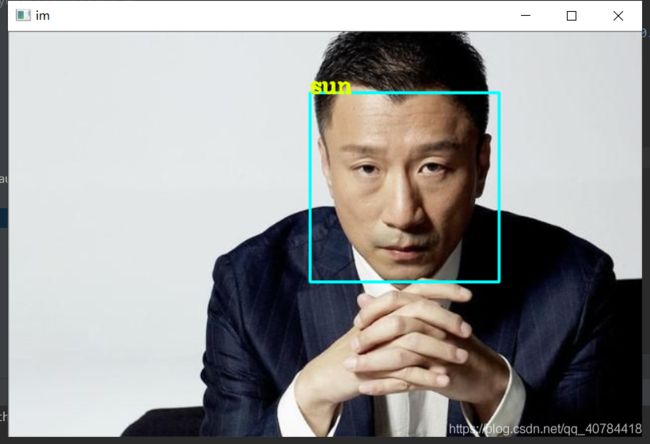

大功告成!!!!
3、总结
face_detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# face为脸部位置信息(用于绘制预测框)
face = face_detector.detectMultiScale(grey)
recognizer = cv2.face.LBPHFaceRecognizer_create()
以上三行代码获取人脸检测器对象,可以用来检测人脸
#训练
recognizer.train(faces, numpy.array(labels))
#测试,返回人脸标签和可信度
label, confidence = recognizer.predict(grey[y:y+h, x:x+w])
4、参考
https://blog.csdn.net/ZackSock/article/details/103889360