使用pycaret来进行数据挖掘:关联规则挖掘
关联规则用于发现大型数据库中变量之间的有趣关系。它旨在使用一些有趣的方法来识别在数据库中发现的强规则。通过对关联规则的挖掘我们可以发现超市或者电商的大规模交易数据中商品之间的规律性,最著名的案例是“啤酒与尿布”的故事,20世纪90年代的美国超市中,超市管理人员分析销售数据时发现了一个令人难于理解的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮中。还比如人们在超市的销售数据中发现,如果顾客同时购买面包和牛奶,他们也会购买黄油。这样的信息可以为企业营销活动的决策带来帮助。
下面我们解释一些关于关联规则的基础理论知识,首先我们定义:
![]() ,其中 I 表示所有物品的集合,
,其中 I 表示所有物品的集合, ![]() 表示第1,第2,第...个商品。
表示第1,第2,第...个商品。
![]() ,其中D表示数据库中所有的交易(订单)记录,
,其中D表示数据库中所有的交易(订单)记录,![]() 表是第1,第2,第...个订单记录。
表是第1,第2,第...个订单记录。
每笔交易在D具有唯一的交易 ID 并且其中包含商品集合I的子集。
关联规则是通过在数据库中搜索频繁 if-then 模式的强关联物品的组合,这种组合称为频繁项集。但是在数据库中找到所有频繁项集并不是一件容易的事,因为它涉及遍历所有数据以便从所有可能的项集中找到所有可能的项集组合。可能项集的集合是物品集合I的幂集,并且具有大小是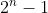 ,当然这意味着排除不被认为是有效项集的空集,但是幂集的大小将随着幂集内的项目n的数量呈指数增长通过使用支持的向下闭合属性(也称为反单调性),可以进行有效的搜索。这将保证频繁项集及其所有子集也是频繁的,因此不会将不频繁项集作为频繁项集的子集。利用这一特性,一些高效的算法(例如,Apriori 和 Eclat)可以找到所有频繁项集。
,当然这意味着排除不被认为是有效项集的空集,但是幂集的大小将随着幂集内的项目n的数量呈指数增长通过使用支持的向下闭合属性(也称为反单调性),可以进行有效的搜索。这将保证频繁项集及其所有子集也是频繁的,因此不会将不频繁项集作为频繁项集的子集。利用这一特性,一些高效的算法(例如,Apriori 和 Eclat)可以找到所有频繁项集。
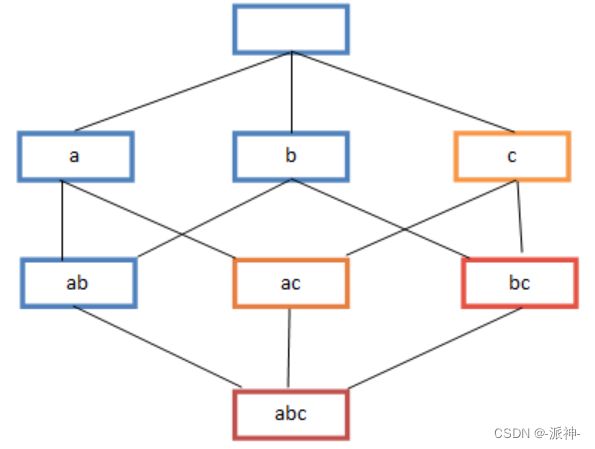
上图物品集:{a,b,c}的幂集为所有子集的集合(包含空集在内)其子集的数量为 ,而频繁项集的数量为(排除空集)。
,而频繁项集的数量为(排除空集)。
关联规则被定义为:
![]() ,其中
,其中 ![]() ,这里X,Y都是 I 的子集,可以这样理解如果用户买了1个或多个商品,那么也会购买另外1个或多个商品。这里X,Y是 I 的子集因此它们各种都包含了1个或者多个商品。这是关联规则的一般定义,但是在实际的应用场景中一般会定义商品的子集和单个商品之间的关联规则:
,这里X,Y都是 I 的子集,可以这样理解如果用户买了1个或多个商品,那么也会购买另外1个或多个商品。这里X,Y是 I 的子集因此它们各种都包含了1个或者多个商品。这是关联规则的一般定义,但是在实际的应用场景中一般会定义商品的子集和单个商品之间的关联规则:
![]() ,其中
,其中![]() 。这个规则可以这么理解:如果客户购买了一个或多个商品,那也会购买另外一个商品。其中
。这个规则可以这么理解:如果客户购买了一个或多个商品,那也会购买另外一个商品。其中![]() 含义是“如果...那么...”,即英语中的 if... then.
含义是“如果...那么...”,即英语中的 if... then.
在这里我们使用support(支持度) 、confidence(置信度)、lift(提升度)、conviction(出错率)等评估指标来衡量频繁项集的强关联程度。
support (支持度)表示两种物品在数据集中同时出现的概率:
support (X,Y)=![]()
即强关联的物品组合在给定数据集中出现的频率,可以这么理解,同时购买过面包和牛奶这两种商品的订单在所有订单中所占比例。
confidence(置信度)他表示一个条件概率:![]() 可以这么理解,在所有购买面包的订单中又购买过牛奶的订单所占的比例。我们可以利用条件概率的公式来计算置信度:
可以这么理解,在所有购买面包的订单中又购买过牛奶的订单所占的比例。我们可以利用条件概率的公式来计算置信度:

lift(提升度),它可以用来比较预期的 Confidence 和实际的 Confidence,表示在含有X的条件下同时含有Y的可能性与无条件下含有Y的可能性之比,即在Y自身出现的可能性P(Y)的基础上,X的出现对于Y的“出镜率”P(Y|X)的提升程度:
![]() 。
。
如果 lift = 1,表示X与Y相互独立,X对Y出现的可能性没有提升作用,其值越大(lift >1)表示X对Y的提升程度越大,也表示关联性越强。
conviction(出错率) ,它的作用于度量关联规预测错误的概率,表⽰X出现⽽Y不出现的概率。
![]()
下面我们举一个简单的例子来加深我们对support,confidence,lift,conviction等评价指标的理解:下面显示了数据库中的5笔交易记录其中包含了7种商品。
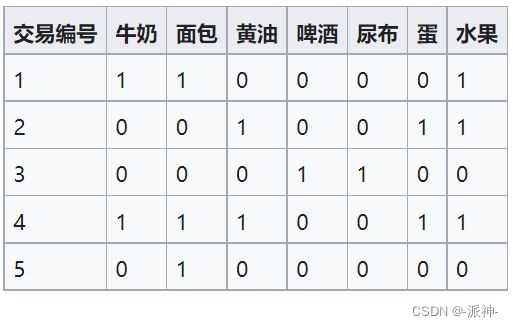
我们来算一下{啤酒,尿布}的support(支持度),
supp(啤酒,尿布)=1/5=0.2 ,在所有的5个订单中,只有一个订单购同时买过啤酒和尿布(第3个订单)。
supp(牛奶,面包,黄油)=1/5=0.2 ,在所有的5个订单中,只有一个订单同时购买过牛奶,面包和黄油(第4个订单)。
conf({黄油,面包}![]() {牛奶})=P(牛奶|黄油,面包)=P(牛奶∩黄油∩面包)/P(黄油∩面包)=1, 这里表示在所有购买过黄油和面包的订单中有多个订单也购买了牛奶,从数据表中我们可以发现只有一个订单购买过黄油和面包(第4个订单)并且在这个订单中也购买了牛奶,所以P(牛奶∩黄油∩面包)/P(黄油∩面包)=1/1=1.
{牛奶})=P(牛奶|黄油,面包)=P(牛奶∩黄油∩面包)/P(黄油∩面包)=1, 这里表示在所有购买过黄油和面包的订单中有多个订单也购买了牛奶,从数据表中我们可以发现只有一个订单购买过黄油和面包(第4个订单)并且在这个订单中也购买了牛奶,所以P(牛奶∩黄油∩面包)/P(黄油∩面包)=1/1=1.
conf(水果![]() 鸡蛋)=P(鸡蛋|水果)=P(鸡蛋∩水果)/P(水果)=2/3=0.67 这里表示有3个订单购买过水果,在这3个购买水果的订单中又有两个订单购买过鸡蛋所以概率是2/3.
鸡蛋)=P(鸡蛋|水果)=P(鸡蛋∩水果)/P(水果)=2/3=0.67 这里表示有3个订单购买过水果,在这3个购买水果的订单中又有两个订单购买过鸡蛋所以概率是2/3.
lift({牛奶,面包}![]() {黄油})=P(黄油|牛奶,面包) / P(黄油)=0.5/0.4=1.25,这里lift>1 说明购买面包,牛奶对购买黄油是有帮助的,在这里需要说明的是:如果 lift (Y|X)= 1,表示X与Y相互独立,X对Y出现的可能性没有提升作用,其值越大(lift >1)表示X对Y的提升程度越大,也表示关联性越强。
{黄油})=P(黄油|牛奶,面包) / P(黄油)=0.5/0.4=1.25,这里lift>1 说明购买面包,牛奶对购买黄油是有帮助的,在这里需要说明的是:如果 lift (Y|X)= 1,表示X与Y相互独立,X对Y出现的可能性没有提升作用,其值越大(lift >1)表示X对Y的提升程度越大,也表示关联性越强。
conv({牛奶,面包}![]() {黄油})=
{黄油})=

=(1-0.4)/(1-0.5)=0.6/0.5=1.2
这表明含有现牛奶和面包但不含有黄油的概率增加了20%。
Apriori 算法
Apriori 由 R. Agrawal 和 R. Srikant 在 1994 年给出,用于频繁项集挖掘和关联规则学习。它通过识别数据库中频繁出现的单个项目并将它们扩展到越来越大的项目集,只要这些项目集出现得足够频繁。该算法的名称是 Apriori,因为它使用了频繁项集属性的先验知识。
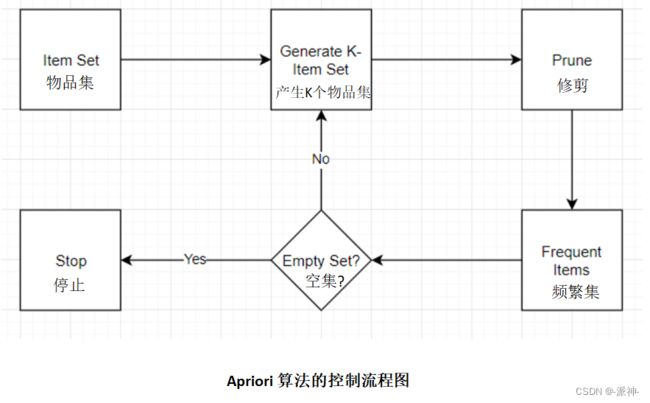
Apriori算法使用“自下而上”的方法,其中频繁子集一次扩展一项(称为候选生成的步骤),并针对数据测试候选组。当没有找到进一步的成功扩展时,算法终止。Apriori 使用广度优先搜索和哈希树结构来有效地计算候选项目集。它从长度的项目集生成候选长度的项目集。然后它修剪具有不常见子模式的候选者。根据向下闭合定理,候选集包含所有频繁长度项集。之后,它扫描数据库以确定候选中的频繁项集。
下面是一个癌症数据集的样本,其中字母代表的特定突变组合,我们要重这些组合中搜索频繁项集:

首先计算每个字母的support (支持度),然后设置一个最小阈值:3 来修剪项目集:

由于所有字母的支持度都大于等于3,因此不做修剪。频繁项集是 {a}、{b}、{c} 和 {d},接下来我们我们在{a}、{b}、{c} 和 {d}的基础上计算二元组(任意两个字母的组合在一起)的支持度:

现在我们设置二元组最小支持度阈值为 4,因此在修剪后只有 {a, d} 和 {c, d} 将被保留。接下来我们在 {a, d} 和 {c, d}的基础上计算三元组(任意三个字母的组合在一起)的支持度:

因为最后我们只剩一个三元组,所以下一轮四元组是空的,所以算法将停止。最后保留的频繁项集为:{a}、{b}、{c} 、{d}、{a, d} 、 {c, d}、{a,c,d}。
利用pycaret来实现数据关联规则挖掘
PyCaret 是 Python 中的一个开源、低代码机器学习库,它可以自动执行机器学习工作流。它是一种端到端的机器学习和模型管理工具,它可成倍的提高您的工作效率。与其他开源机器学习库相比,PyCaret 是一个低代码的机器学习框架,可用于仅用几行代码替换您之前写的几百行代码。这使得开发过程以指数方式快速和高效。PyCaret 本质上是几个机器学习库和框架的 Python 包装器,例如 scikit-learn、XGBoost、LightGBM、CatBoost、spaCy、Optuna、Hyperopt、Ray 等等。今天我们通过一个简单的关联规则挖掘的例子来看看pycaret有多么强大!
pycaret来实现关联规则挖掘一般有下面几个步骤:
- Getting Data:从 PyCaret 存储库导入模拟数据,或者也可以读取外部真实数据
- Setting up Environment:在 PyCaret 中设置算法环境并准备开始实现关联规则挖掘
- Create Model:创建关联规则挖掘的算法模型
- Plot Model:使用各种绘图分析模型性能
数据
我们将使用来自 UCI 数据集的一个小样本,称为在线零售数据集。这是一个交易数据集,其中包含 2010年1月12日至 2011年9月12 日之间发生的交易。下面简单描述一下数据字段的含义:
- InvoiceNo:发票编号,一个 6 位的唯一整数。如果此代码以字母“c”开头,则表示取消。
- StockCode: 商品代码,一个 5 位整数,每个商品都有一个唯一的代码。
- Description:商品的描述信息。
- Quantity:每笔交易的每个商品的数量。
- InvoiceDate: 发票日期和时间,生成每笔交易的日期和时间。
- UnitPrice: 商品的单价,以英镑为单位的商品价格。
- CustomerID: 客户编号,每个客户唯一分配的 5 位整数。
- Country: 国家名称,每个客户所在国家的名称。
1.Getting Data
由于pycaret已经内置了这个零售数据集,因此你可以使用pycaret提供的get_data方法来获取数据:
from pycaret.datasets import get_data
data = get_data('france')
print('唯一发票数量:',data.InvoiceNo.nunique())
print('唯一商品数量:',data.Description.nunique()) 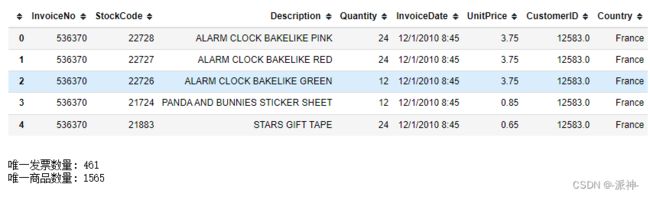
我们发现数据集中唯一的发票数量是461,唯一的商品数量是1565.
2.Setting up Environment
这里我们将使用setup() 函数,它的作用是初始化 PyCaret 中的环境,并将数据集转换为 Apriori 算法可接受的形状。 setup() 需要三个强制参数:pandas的dataframe、transaction_id,它是表示事务 id 的列的名称(本例中是发表编号),将用于对矩阵进行透视; item_id 是用于创建规则的列的名称(本例中是Description)。 通常,这将是感兴趣的变量。 您还可以传递可选参数 ignore_items 以忽略item_id 中的某些值。
from pycaret.arules import *
exp=setup(data=data,transaction_id='InvoiceNo',item_id = 'Description')
成功执行setup()后,它会打印包含少量重要信息的信息网格:
- Transactions :数据集中的唯一交易数。 在这种情况下,唯一的 InvoiceNo的数量。
- Items :数据集中的唯一项目的数量。
- Ignore Items :规则挖掘中要忽略的项目。 很多时候,频繁项集的组合没有意义,所以可能要忽略它们。 例如:许多交易数据集将包含运费,很多其他的商品可能和运费有着强关联,所以为了忽略这种无意义的频繁项集可以在 setup() 中使用 ignore_items 参数忽略。 后面我们将再运行 setup() 一次,后面我们将忽略某些特定无意义的物品。
这里统计出来的Transactions和Items的数量和我们前面统计的结果一样。
3.Create a Model
创建关联规则模型很简单, create_model() 不需要强制参数。 它有 4 个可选参数,如下所示:
- metric: 设置评估指标: 'confidence','support', 'lift', 'leverage', 'conviction',默认值为‘confidence’
- threshold:评估指标的最小阈值, 默认设置为 0.5。
- min_support:0 到 1 之间的浮点数,用于返回的项目集的最小支持度为0.05
- round:评估结果中的分数中的小数位数指标将四舍五入
下面我们将创建一个使用默认参数的关联规则模型,最终将挖掘出所有的频繁项集{![]() }:
}:
model1 = create_model()
print('频繁项集数量:',len(model1))
model1.head()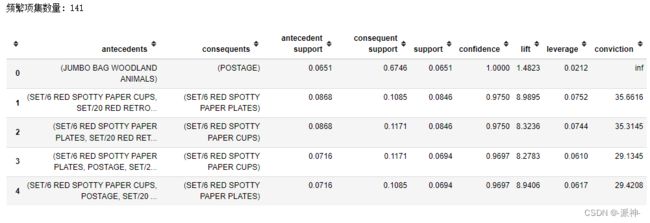 这里关联规则模型挖掘出了141个频繁项集{
这里关联规则模型挖掘出了141个频繁项集{![]() },并计算出 'confidence','support', 'lift', 'leverage', 'conviction'等评估指标。
},并计算出 'confidence','support', 'lift', 'leverage', 'conviction'等评估指标。
4.Setup with ignore_items
我们发现在上述的频繁项集的结果中antecedents和consequents中存在很多的POSTAGE, 而POSTAGE表示运费,所以大多数和运费组合在一起的频繁项集没有意义,所以我们要排除掉POSTAGE。下面我们要在setup()方法中使用Ignore Items参数来排除POSTAGE。
exp=setup(data=data,
transaction_id='InvoiceNo',
item_id = 'Description',
ignore_items = ['POSTAGE'])
model2 = create_model()
print('频繁项集数量:',len(model2))
model2.head() 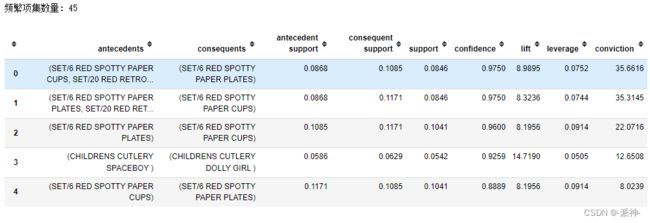
排除掉后POSTAGE关联规则模型挖掘出了45个频繁项集。
5.Plot Model
下面我们用二维及三维可视化的方法来分别展示每一组频繁项集的评估分数在平面和空间中的分布:
plot_model(model2) 
plot_model(model2, plot = '3d') 
参考资料
Association rule learning
pycaret官方文档