论文阅读笔记_《基于知识图嵌入的协同过滤推荐算法_张屹晗》
文章目录
- 论文阅读笔记_《基于知识图嵌入的协同过滤推荐算法_张屹晗》
-
-
- 知识储备
- 摘要
- 关键词
- 0 引言
-
- 本文贡献
- 1 相关工作
-
- 基于知识图谱的推荐系统存在两个关键问题
- 知识图嵌入算法(Knowledge Graph Embedding,KGE)
- 2 KGECF 算法
-
- 结构化知识特征提取
- 联合学习
- 推荐列表生成
- 3 实验结果与分析
-
- 评价指标
- 与基准算法比较
- 向量嵌入维数的影响
- 负采样率的影响
- 4 结束语
-
论文阅读笔记_《基于知识图嵌入的协同过滤推荐算法_张屹晗》
知识储备
1、Freebase是一个由元数据组成的大型合作知识库,结构化数据,结构分为三层:Domain -> Type -> Topic,全部数据迁移至Wikidata(Freebase 是已经被废弃的知识库)
2、TransR 空间投影,创新点是将 TransH 的投影到超平面更进一步——投影到空间,本质是将投影向量换为投影矩阵,实体还是用一个向量表示,关系用一个向量和一个矩阵表示。效果提升并不大,但计算量显著增大。TransR 的 R 代表 relation space
3、Top-N推荐是指寻找一组最有可能引起特定用户兴趣的N个物品并将其以列表的形式推荐给该用户的任务
4、Adam 是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重(参考:Adam优化算法)
5、性能评估指标:准确率Precision、召回率Recall、F1是Precision 和 Recall的调和平均值和 NDCG为标准化折现累积收益,是一种衡量排名质量的指标,通过归一化的得分来评估测试集中每一个用户得到的推荐列表结果。
摘要
针对如何获取项目的结构化知识并对其进行语义特征提取这一问题,提出了一种基于知识图嵌入的协同过滤推荐算法(Knowledge Graph Embedding based Collaborative Filtering,KGECF),
首先从 Freebase 知识图谱中提取与项目相关的知识信息,并与历史交互项目进行链接,构建子知识库;
然后通过基于 TransR 的 Xavier-TransR 方法得到子知识库中实体、关系表征;
设计一种端到端的联合学习模型,将结构化信息与历史偏好信息嵌入到统一的向量空间中;
最后利用协同过滤方法进一步计算这些向量并生成精确的推荐列表。
在 Movielens-1M 和 Amazon-book 两个公开数据集上的实验表明,该算法在推荐准确率、召回率、F1 值和 NDCG 四个指标上均优于基线方法,能够集成大规模的结构化和非结构化数据,同时获得高精度的推荐结果。
关键词
推荐系统;协同过滤;知识图嵌入;联合学习
0 引言
本文贡献
a) 将丰富的异构信息引入推荐系统,其中包括来自Freebase 知识图谱中外部知识的项目信息以及来自用户隐式反馈的交互信息;采用改进的知识图嵌入方法从知识库中提取项目的语义特征,挖掘项目之间深层次的关联。
b) KGECF 算法将推荐系统数据集中的项目和 Freebase知识图谱中的实体进行链接,通过联合训练知识图嵌入和协同过滤的方法,将实体、关系的嵌入向量融入到协同过滤推荐过程中,在对结构化数据提取特征的同时,实现对历史交互数据的建模。
c) 基于电影和图书两个不同场景的公开数据集,将提出的算法与 BPR、LINE、CFKG 和 KTUP 四个基准算法进行了对比分析,实验结果证明 KGECF 算法具有合理性和有效性。
1 相关工作
基于知识图谱的推荐系统存在两个关键问题
(1)如何为推荐项目获取丰富的结构化知识信息
a)通过搜集各种辅助信息来制作结构化的项目知识;
b) 使用外部构建好的知识图谱来丰富项目的语义特征。
(2)如何发掘知识图谱定义的用户特定项目和图中实体之间的语义关联性
a)基于嵌入的方法:关注历史交互数据中的用户-项 目对和知识图谱中的三元组之间的一阶连通性,利用知识图嵌入技术获得图谱中实体的嵌入向量,然后将其作为项目的先验信息或上下文信息来辅助推荐模型。比如:CKE 模型、DKN 模型
b)基于路径的方法:通过探索项目间的连接方式(元路径或元图)为推荐提供额外指导。比如:个性化实体推荐算法(PER)、基于元路径的推荐算法
知识图嵌入算法(Knowledge Graph Embedding,KGE)
侧重于建模严格的语义关联,旨在学习知识图谱中实体、关系的嵌入向量,同时保持图形的原始结构。KGE 算法一般包括以下两类:
a) 翻译模型,在学习实体和关系表示时使用了基于距离的评分函数。如 TransE和 TransR
b) 语义相似性模型,通过匹配实体和关系之间的潜在语义来衡量知识三元组的合理性。如DisMult和ComplEx
基于嵌入的方法在结构化语义特征提取方面表现出高度的灵活性,而基于翻译的 KGE 算法也广泛的应用于知识图谱的嵌入训练。
2 KGECF 算法

模型主要由结构化知识特征提取、联合学习和推荐列表生成 3 个阶段构成:
结构化知识特征提取
以推荐系统中用户-项目历史交互和 Freebase 知识图谱作为输入,提取与项目相关的实 体来构建子知识图谱(Sub-graph),并使用改进的知识图嵌入方法(Xavier-TransR)从子图中寻找结构化知识的潜在向量表示,以此获得具有知识感知的项目表征。
可信性评分公式:

基于 Xavier 的TransR 算法(本文命名为 Xavier-TransR 算法),在初始嵌入向量时,

ni和ni+1表示模型嵌入层中第 i 层输入和第 i +1层输出的特征数量
Xavier-TransR 算法在训练过程中综合考虑了正样例三元组与负样例三元组之间的相对顺序,并使用 BPR 算法的损失函数来对两者进行区分。

为了避免该算法在训练过程中损失值趋于 0,每次在实体、关系的嵌入向量更新之前进行归一化处理

本文提出的算法使用 sigmoid 函数计算知识图谱中实体-关系三元组的成对(pair-wise)排序概率,并使用 Xavier初始化的方式对参数进行赋值,提高了模型的表达能力,可以从知识图谱中获得高质量的语义表征
联合学习
(联合训练知识图嵌入和协同过滤算法的损失函数)
将知识图谱中的结构化嵌入向量和非结构化项目特征向量以按元素位置相加的方式集成在一起,构建项目最终的潜在向量表征。采用协同过滤的推荐方法,通过优化项目之间的成对排序函数,将结构化与非结构的信息嵌入到统一的向量空间中
协同过滤推荐算法,定义 ui为用户 i 的潜在向量表示, v j为项目 j 的潜在向量表示,引入结构化知识特征来丰富项目的语义信息

为了优化推荐模型,使用 BPR 算法中的损失函数来重建用户的历史交互
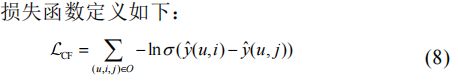
联合(3)式和(8)式,通过最小化如下损失函数来学习模型参数

采用小批量 Adam 算法来优化(9)式中的损失函数,对模型参数进行更新。
推荐列表生成
使用最终得到的用户、项目潜在向量表征的内积作为用户的偏好概率值,并以此为目标用户生成个性化的推荐列表。
3 实验结果与分析
评价指标
准确率Precision、召回率Recall、F1是Precision 和 Recall的调和平均值和 NDCG
与基准算法比较
与BPR、LINE、CFKG、KTUP比较发现,KGECF 算法能获得更高的推荐性能和更精确的实体表征,可以更好地处理稀疏性问题,验证了稀疏性问题是影响推荐质量的关键因素,且知识图谱可以在一定程度上提高推荐的性能。
向量嵌入维数的影响
增加嵌入向量的维数可以使模型从知识图谱中获得更精确的实体、关系表征。
负采样率的影响
使用负采样策略可以平衡正负样本比例,降低模型的计算复杂度,提高推荐性能。但增加过多的负采样个数又可能会使模型的鲁棒性变差,很难取得最优的结果,并且抽取较多的负样本也会消耗大量的时间来训练模型。综上所述,模型负采样率的最佳范围为 1 到 3。
4 结束语
实验表明 KGECF在两个数据集上的指标均优于对比算法,能为用户提供更准确的推荐结果,在融合异构数据方面也具有较强的灵活性。KGECF 算法使用结构化的知识信息来增强项目端的表征,缺乏对用户端辅助信息的使用。在未来的研究中,将考虑融入用户的属性、评论等辅助信息,以丰富用户的潜在特征,进一步缓解协同过滤算法的稀疏性问题。
参考文献:[1]张屹晗,王巍,刘华真,谷壬倩,郝亚奇.基于知识图嵌入的协同过滤推荐算法[J/OL].计算机应用研究:1-8[2021-09-28].https://doi.org/10.19734/j.issn.1001-3695.2021.05.0181.