day17:HashMap、LinkedHashMap、泛型、Collections、斗地主
一、 回顾
1.Set集合特点:无序 没有索引 唯一重复
2.遍历方式: A.使用迭代器 B.使用增强for循环
3.hashCode值
A.hashcode值根据内存地址生成的一个十进制的整数
B.不是根据hashcode值来判断两个对象是同一个对象 hashcode 是可以重写
C.public int hashCode() 返回该对象的哈希码值
D.字符串重写了hashcode方法 如果两个字符串的内容相同 hash是一样 但是字符串会 出现hash冲突的问题:内容不相同但是hashcode值一样(重地 通话)
4.数据结构红黑树:趋近于平衡二叉树 查询效率快
5.HashSet的数据结构:hash表结构 在jdk1.8之前 数组+链表 在jdk1.8之后 数组+链表+红黑树
6.HashSet 存储数据唯一的原因:使用equlas() 与hashcode方法进行验证 hashcode值一样 内容也一样 是不存
7.TreeSet 排序
排序规则:
A.数值是按照升序进行排列
B.字符串是按照首字母的ascamll表来进行排列
C.引用数据类型 没有进行默认排列 需要执行其规则
自定义的引用数据类型
A.自定义的类实现 Comparable
this > 0 升序
this =0 表示是相同
this < 0降序
B.实例化解集合的时候传递比较的规则 Comparator
7.LinkedHashSet
A.具有可预知迭代顺序的 Set 接口
B.哈希表
C.双重链表
8.Map
A.概念:以键值对存储的集合 数据结构只针对与键 键是唯一
B.常用的方法
C.map集合两种遍历方式
a.获取的键 通过键来获取值
b.将键值对封装成一个对象 调用对象的方法 getKey() getValue()
二、作业1
step01 需求

step02 代码
//定义数组
String [] arrays={"王昭君","王昭君","西施","貂蝉","杨玉环"};
//实例化集合
LinkedHashSet link = new LinkedHashSet();
//使用增强for循环
for (String array : arrays) {
link.add(array);
}
//使用迭代器遍历
Iterator iterator = link.iterator();
while (iterator.hasNext()){
Object next = iterator.next();
System.out.println(next);
}
王昭君
西施
貂蝉
杨玉环三 作业2
step01 需求

step01 代码
public static void main(String[] args) {
String[] array1 = new java.lang.String[]{"黑龙江","浙江省","江西省","广东省","福建省"};
String[] array2 = new java.lang.String[]{"哈尔滨","杭州","南昌","广州","福州"};
Map map = new HashMap();
for (int i = 0; i < array2.length; i++) {
map.put(array1[i],array2[i]);
}
System.out.println(map);
}
{黑龙江=哈尔滨, 福建省=福州, 浙江省=杭州, 江西省=南昌, 广东省=广州}七、HashMap
7.1简介
1.特点:
- 数据结构基于哈希表
- 此类不保证映射的顺序 无序
- 并允许使用null值和null键
- 此实现不是同步的在多线程中是不安全
- 默认初始化容量是16
7.2 HashMap与HashSet比较
相同点:都是以hash表结构来进行存储
不同点:
A.HashMap 数据结构只针对与键 HashSet的数据结构针对于是元素
B.HashSet集合的底层也是使用HashMap来进行存储 只能用于HashMap键的数据结构
八 LinkedHashMap
8.1简介
A.Map 接口的哈希表和链接列表实现 数据结构 hash表结构 与链表进行存储
B.具有可预知的迭代顺序
C.此实现不是同步的 多线程中是不安全的
代码
LinkedHashMap map = new LinkedHashMap();
map.put("a","吴奇隆");
map.put("c","刘亦菲");
map.put("d","刘逝世");
map.put("b","大苏打");
System.out.println(map);
System.out.println("==============LinkedHashMap");
HashMap map1 = new HashMap();
map1.put("a","吴奇隆");
map1.put("c","刘亦菲");
map1.put("d","刘逝世");
map1.put("b","大苏打");
System.out.println(map1);
System.out.println("==============HashMap");
{a=吴奇隆, c=刘亦菲, d=刘逝世, b=大苏打}
==============LinkedHashMap
{a=吴奇隆, b=大苏打, c=刘亦菲, d=刘逝世}
==============HashMap九 泛型
9.1 泛型的概念
1.使用的场景:定义的集合的时候 不确定其数据数据类型 就可以使用泛型
泛型可以理解为是一个变量 变量用于接收数据类型
2.泛型的使用
在实例化对象的时候可以确定其数据类型
例子:List<数据类型> li = new ArrayList<数据类型>();
注意点:
A.前后的泛型必须是一致
B.在jdk1.7之后出现了菱形的泛型 后面的泛型数据类型可以不写
C.泛型只能使用引用数据类型 不能使用基本数据类型
3.好处:
A.避免进行强制类型转换
B.将运行时的错误提前编译期间
4.泛型使用的符号
一般泛型使用的符号都是大写的符号..........任意的大写字母都是可以的
E V K W T Z ......
9.2 定义泛型类
1.语法:
访问修饰符 class 类名<泛型> {
类中的所有的成员都可以使用其泛型
}
2.例子:public class ArrayList
{}
代码-定义泛型类
public class MyArrayList{
//实例化集合
ArrayList list = new ArrayList<>();
//获取集合的值
public T get(int index){
return list.get(index);
}
//设置集合中值
public void set(T t){
list.add(t);
} 代码-测试类
public static void main(String[] args) {
MyArrayList list = new MyArrayList<>();
list.set("詹姆斯");
list.set("字母歌");
System.out.println(list.get(0));
System.out.println(list.get(1));
MyArrayList m = new MyArrayList<>();
m.set(222);
System.out.println(m.get(0));
}
詹姆斯
字母歌
222 9.3 定义泛型方法
1.语法:
访问修饰符 <泛型> 返回值类型 方法的名称(参数列表) {
方法体
return 返回值
}
2.说明:可以给普通方法加泛型 也可以给静态的方法加泛型
3.注意点:
A.普通的成员方法是可以使用类定义的泛型
B.静态方法不能使用类的泛型 因为静态资源优先进行加载
代码-泛型类
public class My {
public void showInfo(T t){
System.out.println(t);
}
public void showIn(T t){
System.out.println(t);
}
public static void show(W t){
}
} 代码-测试类
public static void main(String[] args) {
My my = new My<>();
my.showInfo("123");
// my.showInfo(123);//报错,上面定义的是string类型
my.showIn(123);//没报错,应为这是自定义泛型的方法,public,与类的泛型无关
//静态方法
My.show("普京大帝俄罗斯不存在 地球就没有存在的意义");
}
} 9.4 案例
step01 需求

step03 代码
泛型对应的是引用数据类型,所有不能定义int数组,要定义interger数组
public static void main(String[] args) {
String [] arrays1 = new String[]{"1","2","3"};
Integer [] arrays2 = new Integer[]{1,2,3};
change(arrays1,1,2);
change(arrays2,1,2);
}
public static T[] change(T[] temp ,int index1,int index2){
T t = temp[index1];
temp[index1]=temp[index2];
temp[index2]=t;
return temp;
}
[1, 3, 2]
[1, 3, 2] 9.5 定义泛型接口
1.体现:A.实现类确定其泛型 B.实现类不确定其泛型
2.例子:实现类确定其泛型
public interface Iterator
{ E next()
}
public final class Scanner implements Iterator
{//这里自己定义泛型 public String next()
}
3.例子:实现类也不确定其泛型
public interface List
{ boolean add(E e)
}
public class ArrayList
implements List { //这里加个 实例化的时候再实现 public boolean add(E e)
}
第一种情况 实现类确定其泛型
接口
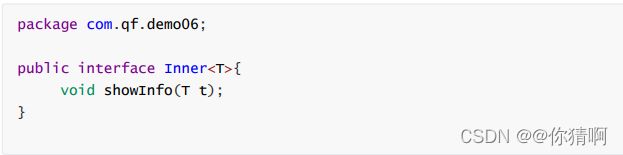
实现类

测试类

第二种情况实现类也不确定其泛型
接口
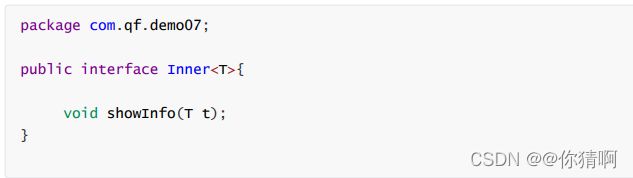
实现类

测试类

9.6 泛型通配符
1.概念:泛型通配符可以表示任意的数据类型 泛型的统配符号使用 ?来表示
泛型通配符一般作为方法的参数使用 实例化集合对象的时候不能使用通配符表示 泛型是没有继承的概念
2.解释特殊的通配符
E本身或者是其子类
T本身或者是其父类
代码

9.7 案例
step01 需求 千锋两种主流学科 HTML5 与java 使用Map集合存储Html的学员以及java的学员 遍历集合中所有的学员
step02 分析

step03 -学生类-代码
public class Student{
private Integer id;
private String name;
private Integer age;
public Student(Integer id, String name, Integer age) {
this.id = id;
this.name = name;
this.age = age;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}step03 代码-测试类
public static void main(String[] args) {
Map map1 = new HashMap();
map1.put(1001,new Student(1001,"李家森1",20));
map1.put(1002,new Student(1002,"李家森2",20));
map1.put(1003,new Student(1003,"李家森3",20));
Map map2 = new HashMap();
map2.put(1004,new Student(1004,"李家森4",20));
map2.put(1005,new Student(1005,"李家森5",20));
map2.put(1006,new Student(1006,"李家森6",20));
Map> map3 = new HashMap<>();
map3.put("java",map1);
map3.put("web",map2);
//第一种遍历
Set strings = map3.keySet();
for (String string : strings) {
System.out.println(string);
Map map = map3.get(string);
Set integers = map.keySet();
for (Integer integer : integers) {
System.out.println(integer+"\t"+map.get(integer));
}
}
//第二种遍历
Set>> entries = map3.entrySet();
Iterator>> iterator = entries.iterator();
while (iterator.hasNext()){
Map.Entry> next = iterator.next();
System.out.println(next.getKey());
Set> entries1 = next.getValue().entrySet();
Iterator> iterator1 = entries1.iterator();
while (iterator1.hasNext()){
Map.Entry next1 = iterator1.next();
System.out.println(next1.getKey()+"\t"+next1.getValue());
}
}
十 Collections单例集合工具类
| 方法名称 | 方法的描述 |
| public static int binarySearch(List> list, T key) | 查找指定元素在集合中的索引值(集合需要按照升序进行排列) |
| public static void copy(List dest, List src) | 将所有元素从一个列表复制到另一个列表 |
| public static void fill(List list, T obj) | 使用指定元素替换指定列表中的所有元素 |
| public static int frequency(Collection c, Object o) | 返回指定 collection 中等于指定对象的元素数 |
| public static |
集合中的最大值 |
| public static |
获取集合中最小值 |
| public static void reverse(List list) | 反转指定列表中元素的顺序 |
| public static void shuffle(List list) | 使用默认随机源对指定列表进行置换 |
| public static |
按照升序进行排列 |
| public static void swap(List list, int i, int j) | 交换集合中指定索引的元素 |