Hexagon_V65_Programmers_Reference_Manual(3)
Hexagon_V65_Programmers_Reference_Manual(3)
- 3 指令
-
- 3.1 指令语法
- 3.2 指令类
- 3.3 指令包
-
- 3.3.1 包执行语义
- 3.3.2 排序语义
- 3.3.3 资源限制
- 3.3.4 分组约束
- 3.3.5 依赖约束
- 3.3.6 排序约束
- 3.3.7 对齐约束
- 3.4 指令内联函数
- 3.5 复合指令
- 3.6 双工指令
3 指令
本章涵盖以下主题:
- 指令语法
- 指令类
- 指令包
- 指令内联函数
- 复合指令
- 双工指令
指令编码在第 10 章中描述(还在很后面)。
有关 Hexagon 处理器指令的详细说明,请参见第 11 章(这个也还在很后面)。
3.1 指令语法
大多数 Hexagon 处理器指令具有以下语法:
dest = instr_name(source1,source2,...)[:option1][:option2]...
等式左侧 (LHS) 指定的项目被赋予右侧 (RHS) 指定的值。 例如:
R2 = add(R3,R1) // Add R3 and R1, assign result to R2
表 3-1 列出了 Hexagon 处理器指令中常用的符号。
表 3-1 指令符号
| 符号 | 示例 | 含义 |
|---|---|---|
| = | R2 = R3 | Assignment of RHS to LHS |
| # | R1 = #1 | Immediate value |
| 0x | 0xBABE | Hexadecimal number prefix |
| memXX | R2 = memub(R3) | Memory access XX specifies access size and type |
| ; | R2 = R3; R4 = R5; | Instruction delimiter, or end of instruction |
| { … } | {R2 = R3; R5 = R6} | Instruction packet delimiter |
| ( … ) | R2 = memw(R0 + #100) | Source list delimiter |
| :endloopX | :endloop0 | Loop end X specifies loop instruction (0 or 1) |
| :t | if (P0.new) jump:t target | Direction hint (jump taken) |
| :nt | if (!P1.new) jump:nt target | Direction hint (jump not taken) |
| :sat | R2 = add(R1,R2):sat | Saturate result |
| :rnd | R2 = mpy(R1.H,R2.H):rnd | Round result |
| :carry | R5:4=add(R1:0,R3:2,P1):carry | Predicate used as carry input and output |
| :<<16 | R2 = add(R1.L,R2.L):<<16 | Shift result left by halfword |
| :mem_noshuf | {memw(R5) = R2; R3 = memh(R6)}:mem_noshuf |
Inhibit load/store reordering (Section 5.5) |
3.2 指令类
Hexagon 处理器指令分配给特定的指令类别。 类决定了可以并行编写的指令组合(第 3.3 节)。
指令类在逻辑上与指令类型相对应。 例如,ALU32 类包含对 32 位操作数进行操作的 ALU 指令。
表 3-2 列出了指令类和子类。
表 3-2 指令类
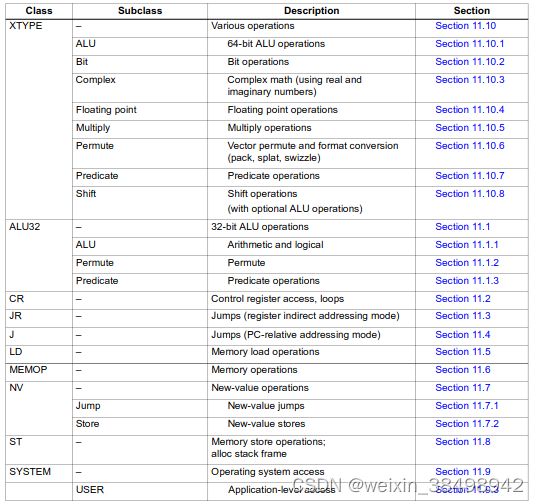
3.3 指令包
指令可以组合在一起以形成并行执行的独立指令包。 数据包可以包含 1、2、3 或 4 条指令。
指令包必须在软件中明确指定。 它们通过用花括号括起来的指令组以汇编语言表达。 例如:
{ R0 = R1; R2 = R3}
对于可以将哪些类型的指令组合在一起以及它们在数据包中出现的顺序存在各种规则和限制。 特别是,数据包的形成受到以下约束:
- 资源限制决定了一个数据包中可以出现多少特定类型的指令。 Hexagon 处理器有固定数量的执行单元:每条指令在特定类型的单元上执行,每个单元一次最多可以处理一条指令。 因此,例如,因为Hexagon处理器仅包含两个加载单元,具有三个加载指令的指令包是无效的。 资源限制在第 3.3.3 节中描述
- 分组约束是在资源约束之上和之外应用的一小组规则。 这些规则在第 3.3.4 节中描述。
- 依赖约束确保数据包中不存在写后写危险。这些规则在第 3.3.5 节中描述。
- 排序约束规定了数据包内指令的排序。 这些规则在第 3.3.6 节中描述。
- 对齐约束决定了数据包在内存中的位置。 这些规则在第 3.3.7 节中描述。
注意 Hexagon 处理器将单个指令(未明确分组在数据包中)作为包含单个指令的数据包执行。
3.3.1 包执行语义
数据包被定义为具有并行执行语义。 具体来说,一个数据包的执行行为定义如下:
- 首先,数据包中的所有指令并行读取它们的源寄存器。
- 接下来,数据包中的所有指令都将执行。
- 最后,数据包中的所有指令并行写入它们的目标寄存器。
例如,考虑以下数据包:
{ R2 = R3; R3 = R2; }
在第一阶段,从寄存器文件中读取寄存器 R3 和 R2。 然后,在执行之后,R2 被写入 R3 的旧值,R3 被写入 R2 的旧值。 实际上,这个数据包的结果是交换了 R2 和 R3 的值。
注:双重存储(5.4 节)、双重跳转(7.7 节)、新值存储(5.6 节)、新值比较跳转(7.5.1 节)和点新谓词(6.1.4 节)具有非并行执行语义。
3.3.2 排序语义
任何长度的数据包都可以在代码中自由混合。 一个数据包被认为是一个原子单元:本质上,一个单一的大“指令”。 从程序的角度来看,一个数据包要么执行完成,要么根本不执行; 它永远不会仅部分执行。 例如,如果一个数据包导致内存异常,则在该数据包之前建立异常点。
包含多个加载/存储指令的数据包可能需要来自外部系统的服务。 例如,考虑一个数据包执行两个在缓存中都未命中的加载操作的情况。 数据包需要内存系统提供的数据:
- 从内存系统的角度来看,两个产生的加载请求是串行处理的。
- 然而,从程序的角度来看,两个加载操作都必须在数据包完成之前完成。
因此,从程序的角度来看,数据包是原子的。
数据包有一个单独的 PC 地址,它是数据包的起始地址。 不能在数据包中间执行分支。
从架构上讲,数据包在下一个数据包开始之前执行完成——包括更新所有寄存器和内存。 因此,应用程序不会暴露于任何管道工件。
3.3.3 资源限制
一个数据包使用的硬件资源不能超过处理器上物理可用的资源。 例如,由于 Hexagon 处理器只有两个加载单元,一个包含三个加载指令的数据包是无效的。 这种数据包的行为是未定义的。 汇编器自动拒绝超额订阅硬件资源的数据包。
该处理器最多支持四个并行指令。 指令在称为插槽的四个并行管道中执行。四个插槽分别命名为插槽 0、插槽 1、插槽 2 和插槽 3。(有关详细信息,请参阅第 1.2 节。)
注意 endloopN 指令(第 7.2.2 节)不使用任何插槽。
每条指令都属于一个特定的指令类(第 3.2 节)。 例如,跳转属于指令类 J,而加载属于指令类 LD。 指令的类决定了它可以在哪个槽中执行。
图 3-1 显示了可以为四个插槽中的每一个分配哪些指令类。

图 3-1 包分组组合
3.3.4 分组约束
少量的限制决定了有效数据包的构成。 汇编器确保所有数据包都遵循有效的分组规则。 如果执行违反分组规则的数据包,则行为未定义。 必须遵守以下规则:
-
dot-new 条件指令(第 6.1.4 节)必须与生成 dot-new 谓词的指令组合在一个数据包中。
-
ST 类指令可以放在插槽 1 中。在这种情况下,插槽 0 通常必须包含第二条 ST 类指令(第 5.4 节)。
-
J 类指令可以放置在插槽 2 或 3 中。但是,只有某些程序流指令(J 或 JR)的组合可以组合在一个数据包中(第 7.7 节)。 否则,一个数据包中最多允许一个程序流指令。 一些 Jump 和 Compare-Jump 指令可以在插槽 0 或 1 上执行,不包括调用,例如:
- 指令形式: “Pd=cmp.xx(); if(Pd.new)jump:hint ”
- 指令形式: “If(Pd[.new]) jump[:hint] ”
- 指令形式: “jump”
-
JR 类指令可以放置在插槽 2 中。但是,当在双工 jumpr R31 编码时,可以放置在插槽 0 中(第 10.3 节)。
-
存在限制可以在硬件循环的设置或结束时出现在数据包中的指令(第 7.2.4 节)。
-
用户控制寄存器传输到控制寄存器 USR 不能与浮点指令组合(第 2.2.3 节)。
-
SYSTEM 类指令包括预取、高速缓存操作、总线操作、加载锁定和存储条件指令(第 5.10 节)。 这些指令具有以下分组规则:
- brkpt、trap、pause、icinva、isync 和 syncht 是单独的指令。 它们不得与数据包中的其他指令组合在一起。
- memw_locked、memd_locked、l2fetch 和 trace 必须在 Slot 0 上执行。它们只能与 ALU32 或(非 FP)XTYPE 指令组合在一起。
- dccleana、dcinva、dccleaninva 和 dczeroa 必须在插槽 0 上执行。插槽 1 必须为空或 ALU32 指令。
3.3.5 依赖约束
数据包中的指令不能写入相同的目标寄存器。 汇编器自动将此类数据包标记为无效。 如果处理器对同一个通用寄存器执行两次写入操作,则会引发错误异常。
如果处理器执行的数据包对同一谓词或控制寄存器执行多次写入,则行为未定义。 此规则存在三种特殊情况:
- 仅当最多实际执行一次写入时,才允许条件写入以相同的目标寄存器为目标(第 6.1.5 节)。
- 状态寄存器中的溢出标志在多条指令写入时定义了行为(第 2.2.3 节)。 请注意,写入整个用户状态寄存器(例如,USR=R2)的指令不允许与写入用户状态寄存器中某个位的任何指令组合在一个数据包中。
- 允许多个比较指令以相同的谓词寄存器为目标,以便对结果执行逻辑与(第 6.1.3 节)。
3.3.6 排序约束
在汇编代码中,指令可以任何顺序出现在数据包中(双跳转除外——第 7.7 节)。 汇编器以正确的顺序自动对数据包中的指令进行编码。
在数据包的二进制编码中,指令必须从插槽 3 到插槽 0 进行排序。如果数据包包含的指令少于四个,则跳过任何未使用的插槽——不需要 NOP,因为硬件会处理适当的指令间距。
在内存中,包中的指令必须以严格的槽降序出现。 此外,如果一条指令可以进入更高编号的插槽,并且该插槽是空的,则必须将它移到更高编号的插槽中。
例如,如果一个数据包包含三个指令并且没有使用 Slot 1,那么指令应该在数据包中编码如下:
- 最低地址的插槽 3 指令
- 插槽 2 指令遵循插槽 3 指令
- 最后(最高)地址的插槽 0 指令
如果数据包包含单个加载或存储指令,则该指令必须进入插槽 0,即最高地址。 例如,必须对包含 LD 和 ALU32 指令的数据包进行排序,以便 LD 位于插槽 0 中,而 ALU32 位于另一个插槽中。
3.3.7 对齐约束
数据包在内存中的放置或对齐有以下限制:
- 数据包必须是字对齐的(32 位)。 如果处理器执行了一个不正确对齐的数据包,它将引发错误异常(第 7.10 节)。
- 数据包不应包装 4GB 地址空间。 如果发生地址回绕,则处理器行为未定义。
代码放置或对齐不存在其他基于内核的限制。
如果处理器分支到一个跨越 16 字节地址边界的数据包,则生成的指令获取将停止一个周期。 作为跳转目标或循环主体条目的数据包可以明确对齐以确保不会发生这种情况(第 9.5.2 节)。
3.4 指令内联函数
为了支持对程序的时间关键部分进行有效编码(不求助于汇编语言),C 编译器支持用于从 C 代码中直接表达 Hexagon 处理器指令的内在函数。
以下示例显示了如何使用内部指令来表达 XTYPE 指令“Rdd = vminh(Rtt,Rss)”:
#include
int main()
{
long long v1 = 0xFFFF0000FFFF0000LL;
long long v2 = 0x0000FFFF0000FFFFLL;
long long result;
// find the minimum for each half-word in 64-bit vector
result = Q6_P_vminh_PP(v1,v2);
}
为以下类中的指令提供了内在函数:
- ALU32
- XTYPE
- CR (仅重定向操作)
- SYSTEM (仅 dcfetch)
有关内联函数的更多信息,请参阅第 11 章。
3.5 复合指令
Hexagon 处理器支持复合指令,在一条指令中编码成对的常用操作。 例如,以下每一条都是一条复合指令:
dealloc_return // deallocate frame and return
R2 &= and(R1, R0) // and and and
R7 = add(R4, sub(#15, R3)) // subtract and add
R3 = sub(#20, asl(R3, #16)) // shift and subtract
R5 = add(R2, mpyi(#8, R4)) // multiply and add
{ // compare and jump
P0 = cmp.eq (R2, R5)
if (P0.new) jump:nt target
}
{ // register transfer and jump
R2 = #15
jump target
}
使用复合指令可以减少代码大小并提高代码性能。
注意 复合指令(X-and-jump 除外,如上所示)与它们所组成的指令有不同的汇编语法。
3.6 双工指令
为了减少代码大小,Hexagon 处理器支持双工指令,将常用指令对编码到 32 位指令容器中。
与复合指令(第 3.5 节)不同,双工指令没有独特的语法——在汇编代码中,它们看起来与组成它们的指令相同。 汇编器负责识别何时可以将一对指令编码为单个双工而不是一对常规指令字。
为了将两条指令放入单个 32 位字中,双工仅限于最常见指令(加载、存储、分支、ALU)和最常见寄存器操作数的子集。
有关双工的更多信息,请参阅第 10.2 节和第 10.3 节(后面在写)。