1. Neural Networks: MNIST image classification
import numpy as np
import matplotlib.pyplot as plt
import math
MAX_POOL_SIZE = 5
CONVOLUTION_SIZE = 4
CONVOLUTION_FILTERS = 2
def forward_softmax(x):
"""
Compute softmax function for a single example.
The shape of the input is of size # num classes.
Important Note: You must be careful to avoid overflow for this function. Functions
like softmax have a tendency to overflow when very large numbers like e^10000 are computed.
You will know that your function is overflow resistent when it can handle input like:
np.array([[10000, 10010, 10]]) without issues.
x: A 1d numpy float array of shape number_of_classes
Returns:
A 1d numpy float array containing the softmax results of shape number_of_classes
"""
x = x - np.max(x,axis=0)
exp = np.exp(x)
s = exp / np.sum(exp,axis=0)
return s
def backward_softmax(x, grad_outputs):
"""
Compute the gradient of the loss with respect to x.
grad_outputs is the gradient of the loss with respect to the outputs of the softmax.
Args:
x: A 1d numpy float array of shape number_of_classes
grad_outputs: A 1d numpy float array of shape number_of_classes
Returns:
A 1d numpy float array of the same shape as x with the derivative of the loss with respect to x
"""
return forward_softmax(x) - 1.0 * (grad_outputs!=0)
def forward_relu(x):
"""
Compute the relu function for the input x.
Args:
x: A numpy float array
Returns:
A numpy float array containing the relu results
"""
x[x<=0] = 0
return x
def backward_relu(x, grad_outputs):
"""
Compute the gradient of the loss with respect to x
Args:
x: A numpy array of arbitrary shape containing the input.
grad_outputs: A numpy array of the same shape of x containing the gradient of the loss with respect
to the output of relu
Returns:
A numpy array of the same shape as x containing the gradients with respect to x.
"""
grad_outputs[x<=0] = 0
return grad_outputs
def get_initial_params():
"""
Compute the initial parameters for the neural network.
This function should return a dictionary mapping parameter names to numpy arrays containing
the initial values for those parameters.
There should be four parameters for this model:
W1 is the weight matrix for the convolutional layer
b1 is the bias vector for the convolutional layer
W2 is the weight matrix for the output layers
b2 is the bias vector for the output layer
Weight matrices should be initialized with values drawn from a random normal distribution.
The mean of that distribution should be 0.
The variance of that distribution should be 1/sqrt(n) where n is the number of neurons that
feed into an output for that layer.
Bias vectors should be initialized with zero.
Returns:
A dict mapping parameter names to numpy arrays
"""
size_after_convolution = 28 - CONVOLUTION_SIZE + 1
size_after_max_pooling = size_after_convolution // MAX_POOL_SIZE
num_hidden = size_after_max_pooling * size_after_max_pooling * CONVOLUTION_FILTERS
return {
'W1': np.random.normal(size = (CONVOLUTION_FILTERS, 1, CONVOLUTION_SIZE, CONVOLUTION_SIZE), scale=1/ math.sqrt(CONVOLUTION_SIZE * CONVOLUTION_SIZE)),
'b1': np.zeros(CONVOLUTION_FILTERS),
'W2': np.random.normal(size = (num_hidden, 10), scale = 1/ math.sqrt(num_hidden)),
'b2': np.zeros(10)
}
def forward_convolution(conv_W, conv_b, data):
"""
Compute the output from a convolutional layer given the weights and data.
conv_W is of the shape (# output channels, # input channels, convolution width, convolution height )
conv_b is of the shape (# output channels)
data is of the shape (# input channels, width, height)
The output should be the result of a convolution and should be of the size:
(# output channels, width - convolution width + 1, height - convolution height + 1)
Returns:
The output of the convolution as a numpy array
"""
conv_channels, _, conv_width, conv_height = conv_W.shape
input_channels, input_width, input_height = data.shape
output = np.zeros((conv_channels, input_width - conv_width + 1, input_height - conv_height + 1))
for x in range(input_width - conv_width + 1):
for y in range(input_height - conv_height + 1):
for output_channel in range(conv_channels):
output[output_channel, x, y] = np.sum(
np.multiply(data[:, x:(x + conv_width), y:(y + conv_height)], conv_W[output_channel, :, :, :])) + conv_b[output_channel]
return output
def backward_convolution(conv_W, conv_b, data, output_grad):
"""
Compute the gradient of the loss with respect to the parameters of the convolution.
See forward_convolution for the sizes of the arguments.
output_grad is the gradient of the loss with respect to the output of the convolution.
Returns:
A tuple containing 3 gradients.
The first element is the gradient of the loss with respect to the convolution weights
The second element is the gradient of the loss with respect to the convolution bias
The third element is the gradient of the loss with respect to the input data
"""
grad_bias = output_grad.sum(axis=(1, 2))
conv_channels, _, conv_width, conv_height = conv_W.shape
input_channels, input_width, input_height = data.shape
grad_weights = np.zeros(conv_W.shape)
grad_data = np.zeros(data.shape)
for x in range(conv_width):
for y in range(conv_height):
for output_channel in range(conv_channels):
grad_weights[output_channel, :, :, :] += output_grad[output_channel, x, y] * data[:, x:(x + conv_width), y:(y + conv_height)]
grad_data[:, x:(x + conv_width), y:(y + conv_height)] += output_grad[output_channel, x, y] * conv_W[output_channel, :, :, :]
return grad_weights, grad_bias, grad_data
def forward_max_pool(data, pool_width, pool_height):
"""
Compute the output from a max pooling layer given the data and pool dimensions.
The stride length should be equal to the pool size
data is of the shape (# channels, width, height)
The output should be the result of the max pooling layer and should be of size:
(# channels, width // pool_width, height // pool_height)
Returns:
The result of the max pooling layer
"""
input_channels, input_width, input_height = data.shape
output = np.zeros((input_channels, input_width // pool_width, input_height // pool_height))
for x in range(0, input_width, pool_width):
for y in range(0, input_height, pool_height):
output[:, x // pool_width, y // pool_height] = np.amax(data[:, x:(x + pool_width), y:(y + pool_height)], axis=(1, 2))
return output
def backward_max_pool(data, pool_width, pool_height, output_grad):
"""
Compute the gradient of the loss with respect to the data in the max pooling layer.
data is of the shape (# channels, width, height)
output_grad is of shape (# channels, width // pool_width, height // pool_height)
output_grad is the gradient of the loss with respect to the output of the backward max
pool layer.
Returns:
The gradient of the loss with respect to the data (of same shape as data)
"""
grad_data = np.zeros(data.shape)
input_channels, input_width, input_height = data.shape
for i in range(input_channels):
for x in range(0, input_width, pool_width):
for y in range(0, input_height, pool_height):
data_temp = data[i, x:(x + pool_width), y:(y + pool_height)]
grad_data[i, x:(x + pool_width), y:(y + pool_height)][np.unravel_index(data_temp.argmax(), data_temp.shape)] = output_grad[i, x // pool_width, y // pool_height]
return grad_data
def forward_cross_entropy_loss(probabilities, labels):
"""
Compute the output from a cross entropy loss layer given the probabilities and labels.
probabilities is of the shape (# classes)
labels is of the shape (# classes)
The output should be a scalar
Returns:
The result of the log loss layer
"""
result = 0
for i, label in enumerate(labels):
if label == 1:
result += -np.log(probabilities[i])
return result
def backward_cross_entropy_loss(probabilities, labels):
"""
Compute the gradient of the cross entropy loss with respect to the probabilities.
probabilities is of the shape (# classes)
labels is of the shape (# classes)
The output should be the gradient with respect to the probabilities.
Returns:
The gradient of the loss with respect to the probabilities.
"""
return -labels / probabilities
def forward_linear(weights, bias, data):
"""
Compute the output from a linear layer with the given weights, bias and data.
weights is of the shape (input # features, output # features)
bias is of the shape (output # features)
data is of the shape (input # features)
The output should be of the shape (output # features)
Returns:
The result of the linear layer
"""
return data.dot(weights) + bias
def backward_linear(weights, bias, data, output_grad):
"""
Compute the gradients of the loss with respect to the parameters of a linear layer.
See forward_linear for information about the shapes of the variables.
output_grad is the gradient of the loss with respect to the output of this layer.
This should return a tuple with three elements:
- The gradient of the loss with respect to the weights
- The gradient of the loss with respect to the bias
- The gradient of the loss with respect to the data
"""
return (data.reshape(-1, 1) @ output_grad.reshape(1, -1), output_grad, (weights @ output_grad.reshape(-1, 1)))
def forward_prop(data, labels, params):
"""
Implement the forward layer given the data, labels, and params.
Args:
data: A numpy array containing the input (shape is 1 by 28 by 28)
labels: A 1d numpy array containing the labels (shape is 10)
params: A dictionary mapping parameter names to numpy arrays with the parameters.
This numpy array will contain W1, b1, W2 and b2
W1 and b1 represent the weights and bias for the hidden layer of the network
W2 and b2 represent the weights and bias for the output layer of the network
Returns:
A 2 element tuple containing:
1. A numpy array The output (after the softmax) of the output layer
2. The average loss for these data elements
"""
W1 = params['W1']
b1 = params['b1']
W2 = params['W2']
b2 = params['b2']
first_convolution = forward_convolution(W1, b1, data)
first_max_pool = forward_max_pool(first_convolution, MAX_POOL_SIZE, MAX_POOL_SIZE)
first_after_relu = forward_relu(first_max_pool)
flattened = np.reshape(first_after_relu, (-1))
logits = forward_linear(W2, b2, flattened)
y = forward_softmax(logits)
cost = forward_cross_entropy_loss(y, labels)
return y, cost
def backward_prop(data, labels, params):
"""
Implement the backward propagation gradient computation step for a neural network
Args:
data: A numpy array containing the input for a single example
labels: A 1d numpy array containing the labels for a single example
params: A dictionary mapping parameter names to numpy arrays with the parameters.
This numpy array will contain W1, b1, W2, and b2
W1 and b1 represent the weights and bias for the convolutional layer
W2 and b2 represent the weights and bias for the output layer of the network
Returns:
A dictionary of strings to numpy arrays where each key represents the name of a weight
and the values represent the gradient of the loss with respect to that weight.
In particular, it should have 4 elements:
W1, W2, b1, and b2
"""
W1 = params['W1']
b1 = params['b1']
W2 = params['W2']
b2 = params['b2']
first_convolution = forward_convolution(W1, b1, data)
first_max_pool = forward_max_pool(first_convolution, MAX_POOL_SIZE, MAX_POOL_SIZE)
first_after_relu = forward_relu(first_max_pool)
flattened = np.reshape(first_after_relu, (-1))
logits = forward_linear(W2, b2, flattened)
y = forward_softmax(logits)
grad_cross_entropy = backward_cross_entropy_loss(y, labels)
grad_softmax = backward_softmax(logits, grad_cross_entropy)
grad_W2, grad_b2, grad_logits = backward_linear(W2, b2, flattened, grad_softmax)
grad_relu = backward_relu(first_max_pool, grad_logits.reshape(first_max_pool.shape))
grad_max_pool = backward_max_pool(first_convolution, MAX_POOL_SIZE, MAX_POOL_SIZE, grad_relu)
grad_W1, grad_b1, grad_convolution = backward_convolution(W1, b1, data, grad_max_pool)
return {
'W1': grad_W1,
'b1': grad_b1,
'W2': grad_W2,
'b2': grad_b2
}
def forward_prop_batch(batch_data, batch_labels, params, forward_prop_func):
"""Apply the forward prop func to every image in a batch"""
y_array = []
cost_array = []
for item, label in zip(batch_data, batch_labels):
y, cost = forward_prop_func(item, label, params)
y_array.append(y)
cost_array.append(cost)
return np.array(y_array), np.array(cost_array)
def gradient_descent_batch(batch_data, batch_labels, learning_rate, params, backward_prop_func):
"""
Perform one batch of gradient descent on the given training data using the provided learning rate.
This code should update the parameters stored in params.
It should not return anything
Args:
batch_data: A numpy array containing the training data for the batch
train_labels: A numpy array containing the training labels for the batch
learning_rate: The learning rate
params: A dict of parameter names to parameter values that should be updated.
backward_prop_func: A function that follows the backwards_prop API
Returns: This function returns nothing.
"""
total_grad = {}
for i in range(batch_data.shape[0]):
grad = backward_prop_func(
batch_data[i, :, :],
batch_labels[i, :],
params)
for key, value in grad.items():
if key not in total_grad:
total_grad[key] = np.zeros(value.shape)
total_grad[key] += value
params['W1'] = params['W1'] - learning_rate * total_grad['W1']
params['W2'] = params['W2'] - learning_rate * total_grad['W2']
params['b1'] = params['b1'] - learning_rate * total_grad['b1']
params['b2'] = params['b2'] - learning_rate * total_grad['b2']
return
def nn_train(
train_data, train_labels, dev_data, dev_labels,
get_initial_params_func, forward_prop_func, backward_prop_func,
learning_rate=5.0, batch_size=16, num_batches=400):
m = train_data.shape[0]
params = get_initial_params_func()
cost_dev = []
accuracy_dev = []
for batch in range(num_batches):
print('Currently processing {} / {}'.format(batch, num_batches))
batch_data = train_data[batch * batch_size:(batch + 1) * batch_size, :, :, :]
batch_labels = train_labels[batch * batch_size: (batch + 1) * batch_size, :]
if batch % 100 == 0:
output, cost = forward_prop_batch(dev_data, dev_labels, params, forward_prop_func)
cost_dev.append(sum(cost) / len(cost))
accuracy_dev.append(compute_accuracy(output, dev_labels))
print('Cost and accuracy', cost_dev[-1], accuracy_dev[-1])
gradient_descent_batch(batch_data, batch_labels,
learning_rate, params, backward_prop_func)
return params, cost_dev, accuracy_dev
def nn_test(data, labels, params):
output, cost = forward_prop(data, labels, params)
accuracy = compute_accuracy(output, labels)
return accuracy
def compute_accuracy(output, labels):
correct_output = np.argmax(output,axis=1)
correct_labels = np.argmax(labels,axis=1)
is_correct = [a == b for a,b in zip(correct_output, correct_labels)]
accuracy = sum(is_correct) * 1. / labels.shape[0]
return accuracy
def one_hot_labels(labels):
one_hot_labels = np.zeros((labels.size, 10))
one_hot_labels[np.arange(labels.size),labels.astype(int)] = 1
return one_hot_labels
def read_data(images_file, labels_file):
x = np.loadtxt(images_file, delimiter=',')
y = np.loadtxt(labels_file, delimiter=',')
x = np.reshape(x, (x.shape[0], 1, 28, 28))
return x, y
def run_train(all_data, all_labels, backward_prop_func):
params, cost_dev, accuracy_dev = nn_train(
all_data['train'], all_labels['train'],
all_data['dev'], all_labels['dev'],
get_initial_params, forward_prop, backward_prop_func,
learning_rate=1e-2, batch_size=16, num_batches=401
)
t = np.arange(400 // 100 + 1)
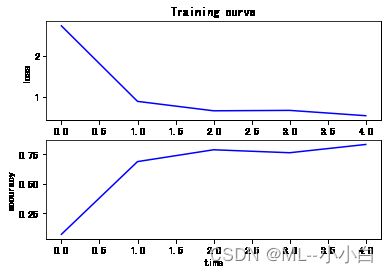
fig, (ax1, ax2) = plt.subplots(2, 1)
ax1.plot(t, cost_dev, 'b')
ax1.set_xlabel('time')
ax1.set_ylabel('loss')
ax1.set_title('Training curve')
ax2.plot(t, accuracy_dev, 'b')
ax2.set_xlabel('time')
ax2.set_ylabel('accuracy')
fig.savefig('output/train.png')
def main():
np.random.seed(100)
train_data, train_labels = read_data('./data/images_train.csv', './data/labels_train.csv')
train_labels = one_hot_labels(train_labels)
p = np.random.permutation(60000)
train_data = train_data[p,:]
train_labels = train_labels[p,:]
dev_data = train_data[0:400,:]
dev_labels = train_labels[0:400,:]
train_data = train_data[400:,:]
train_labels = train_labels[400:,:]
mean = np.mean(train_data)
std = np.std(train_data)
train_data = (train_data - mean) / std
dev_data = (dev_data - mean) / std
all_data = {
'train': train_data,
'dev': dev_data,
}
all_labels = {
'train': train_labels,
'dev': dev_labels,
}
run_train(all_data, all_labels, backward_prop)
main()
Currently processing 0 / 401
Cost and accuracy 2.721417647426753 0.0725
Currently processing 1 / 401
Currently processing 2 / 401
Currently processing 3 / 401
Currently processing 4 / 401
Currently processing 5 / 401
Currently processing 6 / 401
Currently processing 7 / 401
Currently processing 8 / 401
Currently processing 9 / 401
Currently processing 10 / 401
Currently processing 11 / 401
Currently processing 12 / 401
Currently processing 13 / 401
Currently processing 14 / 401
Currently processing 15 / 401
Currently processing 16 / 401
Currently processing 17 / 401
Currently processing 18 / 401
Currently processing 19 / 401
Currently processing 20 / 401
Currently processing 21 / 401
Currently processing 22 / 401
Currently processing 23 / 401
Currently processing 24 / 401
Currently processing 25 / 401
Currently processing 26 / 401
Currently processing 27 / 401
Currently processing 28 / 401
Currently processing 29 / 401
Currently processing 30 / 401
Currently processing 31 / 401
Currently processing 32 / 401
Currently processing 33 / 401
Currently processing 34 / 401
Currently processing 35 / 401
Currently processing 36 / 401
Currently processing 37 / 401
Currently processing 38 / 401
Currently processing 39 / 401
Currently processing 40 / 401
Currently processing 41 / 401
Currently processing 42 / 401
Currently processing 43 / 401
Currently processing 44 / 401
Currently processing 45 / 401
Currently processing 46 / 401
Currently processing 47 / 401
Currently processing 48 / 401
Currently processing 49 / 401
Currently processing 50 / 401
Currently processing 51 / 401
Currently processing 52 / 401
Currently processing 53 / 401
Currently processing 54 / 401
Currently processing 55 / 401
Currently processing 56 / 401
Currently processing 57 / 401
Currently processing 58 / 401
Currently processing 59 / 401
Currently processing 60 / 401
Currently processing 61 / 401
Currently processing 62 / 401
Currently processing 63 / 401
Currently processing 64 / 401
Currently processing 65 / 401
Currently processing 66 / 401
Currently processing 67 / 401
Currently processing 68 / 401
Currently processing 69 / 401
Currently processing 70 / 401
Currently processing 71 / 401
Currently processing 72 / 401
Currently processing 73 / 401
Currently processing 74 / 401
Currently processing 75 / 401
Currently processing 76 / 401
Currently processing 77 / 401
Currently processing 78 / 401
Currently processing 79 / 401
Currently processing 80 / 401
Currently processing 81 / 401
Currently processing 82 / 401
Currently processing 83 / 401
Currently processing 84 / 401
Currently processing 85 / 401
Currently processing 86 / 401
Currently processing 87 / 401
Currently processing 88 / 401
Currently processing 89 / 401
Currently processing 90 / 401
Currently processing 91 / 401
Currently processing 92 / 401
Currently processing 93 / 401
Currently processing 94 / 401
Currently processing 95 / 401
Currently processing 96 / 401
Currently processing 97 / 401
Currently processing 98 / 401
Currently processing 99 / 401
Currently processing 100 / 401
Cost and accuracy 0.8929015433158354 0.6875
Currently processing 101 / 401
Currently processing 102 / 401
Currently processing 103 / 401
Currently processing 104 / 401
Currently processing 105 / 401
Currently processing 106 / 401
Currently processing 107 / 401
Currently processing 108 / 401
Currently processing 109 / 401
Currently processing 110 / 401
Currently processing 111 / 401
Currently processing 112 / 401
Currently processing 113 / 401
Currently processing 114 / 401
Currently processing 115 / 401
Currently processing 116 / 401
Currently processing 117 / 401
Currently processing 118 / 401
Currently processing 119 / 401
Currently processing 120 / 401
Currently processing 121 / 401
Currently processing 122 / 401
Currently processing 123 / 401
Currently processing 124 / 401
Currently processing 125 / 401
Currently processing 126 / 401
Currently processing 127 / 401
Currently processing 128 / 401
Currently processing 129 / 401
Currently processing 130 / 401
Currently processing 131 / 401
Currently processing 132 / 401
Currently processing 133 / 401
Currently processing 134 / 401
Currently processing 135 / 401
Currently processing 136 / 401
Currently processing 137 / 401
Currently processing 138 / 401
Currently processing 139 / 401
Currently processing 140 / 401
Currently processing 141 / 401
Currently processing 142 / 401
Currently processing 143 / 401
Currently processing 144 / 401
Currently processing 145 / 401
Currently processing 146 / 401
Currently processing 147 / 401
Currently processing 148 / 401
Currently processing 149 / 401
Currently processing 150 / 401
Currently processing 151 / 401
Currently processing 152 / 401
Currently processing 153 / 401
Currently processing 154 / 401
Currently processing 155 / 401
Currently processing 156 / 401
Currently processing 157 / 401
Currently processing 158 / 401
Currently processing 159 / 401
Currently processing 160 / 401
Currently processing 161 / 401
Currently processing 162 / 401
Currently processing 163 / 401
Currently processing 164 / 401
Currently processing 165 / 401
Currently processing 166 / 401
Currently processing 167 / 401
Currently processing 168 / 401
Currently processing 169 / 401
Currently processing 170 / 401
Currently processing 171 / 401
Currently processing 172 / 401
Currently processing 173 / 401
Currently processing 174 / 401
Currently processing 175 / 401
Currently processing 176 / 401
Currently processing 177 / 401
Currently processing 178 / 401
Currently processing 179 / 401
Currently processing 180 / 401
Currently processing 181 / 401
Currently processing 182 / 401
Currently processing 183 / 401
Currently processing 184 / 401
Currently processing 185 / 401
Currently processing 186 / 401
Currently processing 187 / 401
Currently processing 188 / 401
Currently processing 189 / 401
Currently processing 190 / 401
Currently processing 191 / 401
Currently processing 192 / 401
Currently processing 193 / 401
Currently processing 194 / 401
Currently processing 195 / 401
Currently processing 196 / 401
Currently processing 197 / 401
Currently processing 198 / 401
Currently processing 199 / 401
Currently processing 200 / 401
Cost and accuracy 0.6646883271931007 0.7875
Currently processing 201 / 401
Currently processing 202 / 401
Currently processing 203 / 401
Currently processing 204 / 401
Currently processing 205 / 401
Currently processing 206 / 401
Currently processing 207 / 401
Currently processing 208 / 401
Currently processing 209 / 401
Currently processing 210 / 401
Currently processing 211 / 401
Currently processing 212 / 401
Currently processing 213 / 401
Currently processing 214 / 401
Currently processing 215 / 401
Currently processing 216 / 401
Currently processing 217 / 401
Currently processing 218 / 401
Currently processing 219 / 401
Currently processing 220 / 401
Currently processing 221 / 401
Currently processing 222 / 401
Currently processing 223 / 401
Currently processing 224 / 401
Currently processing 225 / 401
Currently processing 226 / 401
Currently processing 227 / 401
Currently processing 228 / 401
Currently processing 229 / 401
Currently processing 230 / 401
Currently processing 231 / 401
Currently processing 232 / 401
Currently processing 233 / 401
Currently processing 234 / 401
Currently processing 235 / 401
Currently processing 236 / 401
Currently processing 237 / 401
Currently processing 238 / 401
Currently processing 239 / 401
Currently processing 240 / 401
Currently processing 241 / 401
Currently processing 242 / 401
Currently processing 243 / 401
Currently processing 244 / 401
Currently processing 245 / 401
Currently processing 246 / 401
Currently processing 247 / 401
Currently processing 248 / 401
Currently processing 249 / 401
Currently processing 250 / 401
Currently processing 251 / 401
Currently processing 252 / 401
Currently processing 253 / 401
Currently processing 254 / 401
Currently processing 255 / 401
Currently processing 256 / 401
Currently processing 257 / 401
Currently processing 258 / 401
Currently processing 259 / 401
Currently processing 260 / 401
Currently processing 261 / 401
Currently processing 262 / 401
Currently processing 263 / 401
Currently processing 264 / 401
Currently processing 265 / 401
Currently processing 266 / 401
Currently processing 267 / 401
Currently processing 268 / 401
Currently processing 269 / 401
Currently processing 270 / 401
Currently processing 271 / 401
Currently processing 272 / 401
Currently processing 273 / 401
Currently processing 274 / 401
Currently processing 275 / 401
Currently processing 276 / 401
Currently processing 277 / 401
Currently processing 278 / 401
Currently processing 279 / 401
Currently processing 280 / 401
Currently processing 281 / 401
Currently processing 282 / 401
Currently processing 283 / 401
Currently processing 284 / 401
Currently processing 285 / 401
Currently processing 286 / 401
Currently processing 287 / 401
Currently processing 288 / 401
Currently processing 289 / 401
Currently processing 290 / 401
Currently processing 291 / 401
Currently processing 292 / 401
Currently processing 293 / 401
Currently processing 294 / 401
Currently processing 295 / 401
Currently processing 296 / 401
Currently processing 297 / 401
Currently processing 298 / 401
Currently processing 299 / 401
Currently processing 300 / 401
Cost and accuracy 0.6747279327634921 0.7625
Currently processing 301 / 401
Currently processing 302 / 401
Currently processing 303 / 401
Currently processing 304 / 401
Currently processing 305 / 401
Currently processing 306 / 401
Currently processing 307 / 401
Currently processing 308 / 401
Currently processing 309 / 401
Currently processing 310 / 401
Currently processing 311 / 401
Currently processing 312 / 401
Currently processing 313 / 401
Currently processing 314 / 401
Currently processing 315 / 401
Currently processing 316 / 401
Currently processing 317 / 401
Currently processing 318 / 401
Currently processing 319 / 401
Currently processing 320 / 401
Currently processing 321 / 401
Currently processing 322 / 401
Currently processing 323 / 401
Currently processing 324 / 401
Currently processing 325 / 401
Currently processing 326 / 401
Currently processing 327 / 401
Currently processing 328 / 401
Currently processing 329 / 401
Currently processing 330 / 401
Currently processing 331 / 401
Currently processing 332 / 401
Currently processing 333 / 401
Currently processing 334 / 401
Currently processing 335 / 401
Currently processing 336 / 401
Currently processing 337 / 401
Currently processing 338 / 401
Currently processing 339 / 401
Currently processing 340 / 401
Currently processing 341 / 401
Currently processing 342 / 401
Currently processing 343 / 401
Currently processing 344 / 401
Currently processing 345 / 401
Currently processing 346 / 401
Currently processing 347 / 401
Currently processing 348 / 401
Currently processing 349 / 401
Currently processing 350 / 401
Currently processing 351 / 401
Currently processing 352 / 401
Currently processing 353 / 401
Currently processing 354 / 401
Currently processing 355 / 401
Currently processing 356 / 401
Currently processing 357 / 401
Currently processing 358 / 401
Currently processing 359 / 401
Currently processing 360 / 401
Currently processing 361 / 401
Currently processing 362 / 401
Currently processing 363 / 401
Currently processing 364 / 401
Currently processing 365 / 401
Currently processing 366 / 401
Currently processing 367 / 401
Currently processing 368 / 401
Currently processing 369 / 401
Currently processing 370 / 401
Currently processing 371 / 401
Currently processing 372 / 401
Currently processing 373 / 401
Currently processing 374 / 401
Currently processing 375 / 401
Currently processing 376 / 401
Currently processing 377 / 401
Currently processing 378 / 401
Currently processing 379 / 401
Currently processing 380 / 401
Currently processing 381 / 401
Currently processing 382 / 401
Currently processing 383 / 401
Currently processing 384 / 401
Currently processing 385 / 401
Currently processing 386 / 401
Currently processing 387 / 401
Currently processing 388 / 401
Currently processing 389 / 401
Currently processing 390 / 401
Currently processing 391 / 401
Currently processing 392 / 401
Currently processing 393 / 401
Currently processing 394 / 401
Currently processing 395 / 401
Currently processing 396 / 401
Currently processing 397 / 401
Currently processing 398 / 401
Currently processing 399 / 401
Currently processing 400 / 401
Cost and accuracy 0.5459182551869477 0.8325