【机器学习算法】决策树-6 PRISM
目录
PRISM决策规则算法
如何使用分类树来进行分类预测:
分类树与分类规则间的关系
PRISM决策规则的产生方式
我的主页:晴天qt01的博客_CSDN博客-数据分析师领域博主
目前进度:第四部分【机器学习算法】
PRISM决策规则算法
如何使用分类树来进行分类预测:
如果我们建立好决策树,那我们要怎么进行分类规则的预测呢。一般有两种方法。
第一章直接法:
测试字段的值,未知的样本数据
根节点要进行字段验证,根节点一直跑到叶节点。到叶节点就会有它的标签。得到结果。
在树上找到一条路径。
第二种,间接法。把分类树转化为分类规则。就去分类规则中去找到可以预测的字段。
案例:
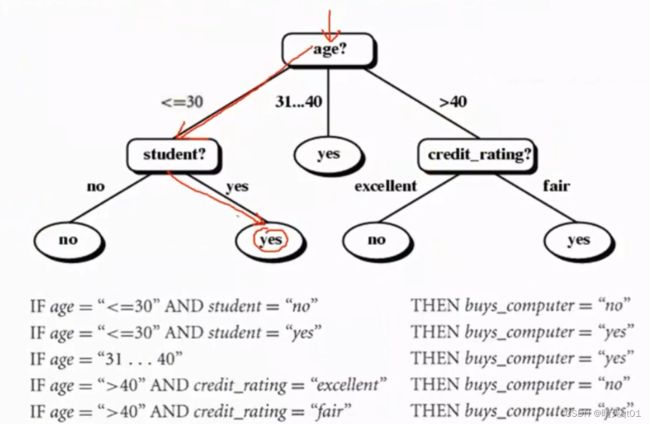
第一种就是按树去逐一运行。
第二种就是有5个叶子,就产生5个条件,满足那条规则,就用那条规则预测。
分类树与分类规则间的关系
你可能会纳闷分类树和分类规则不是同一个东西吗。
其实两种方法有蛮大的差异的。树的限制是比较多。规则是比较自由的,一会我们细说。
另一个案例:
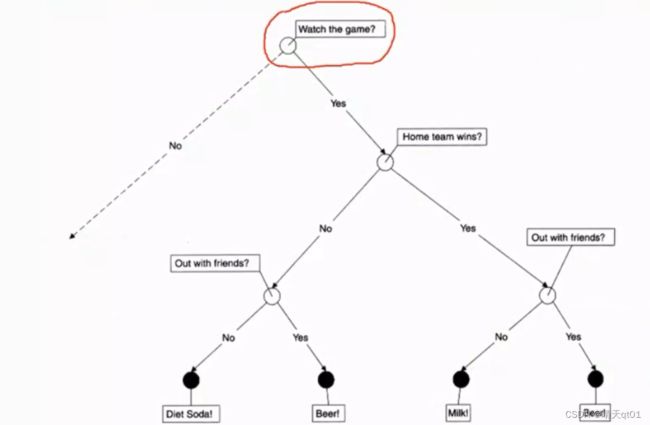
这是一个是否喝饮料的决策树,第一个字段是是否看比赛,第二个字段是主场是否胜利,第三个字段是有没有和朋友出门。有就啤酒,
然后我们就可以产生分类树:

我们发现第一和第三种规则都是喝啤酒。这个时候我们就去观察,字段是哪里有不一致,肯定有不一致,如果一致的话,就是一个规则了。
我们发现主场比赛是否胜利。只要看比赛和朋友出去都会喝啤酒,所以这个条件是假条件。
分类树产生的分类规则是有假的。所以我们要把假条件拿掉。这个对我们判断喝不喝啤酒问题不大,如果是在医疗,凭空给他多一个治疗条件,那就问题大了
所以我们要进行规则合并成一条更精准的规则,变成真正的分类规则。

你可能会纳闷,为什么分类树会产生这种假条件的规则。你会发现如果去掉这个规则。后面的另外两个规则就不能产生。所以分类规则是比较自由的。分类树是很受限制的。
有些人就考虑,能不能直接产生分类规则,而不是先产生分类树再产生分类规则。不用有noise在里面。
虽然它没有收到很大的重视,但是其实很重要的。
PRISM决策规则的产生方式。
PRISM就是一个很出名的直接建立分类规则的方法。会先建立短的分类规则,再建立长的分类规则。它其实是一个简单的覆盖方法。把训练数据覆盖为分类规则的方法
案例:

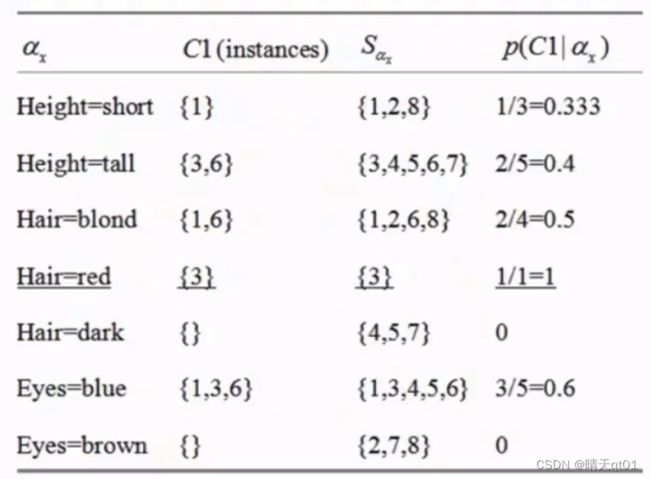
就现针对C1进行寻找,有哪些字段是属于C1的,第一个字段,身高是短的记录(128)就是只有一个记录1是属于C1
所以它就认为当身高是短的时候,它只有1/3的可能性属于C1
身高是tall,有百分之40的概率属于C1
到目前为止有点像bayes分类法。不过后面就不一样了。
其中有一个当发色是red的时候,C1的概率是百分之百,那么我就放入我的第一个规则,只要头发颜色是red那么就会分入C1
概率的计算方式:比如眼睛颜色是blue的时候,那么它出现C1的次数除以它自身出现的总次数,就是概率。
其实这个就是覆盖全部训练数据的方法,就比如我们red覆盖了第3行记录1,那么这行记录就没了,我们就开始考虑剩下的记录的规则是什么。
直到全部记录都被覆盖,那么就结束。

接下来我们要找其他规则。 把三去掉,和之前一样。我们在求条件下的C1概率
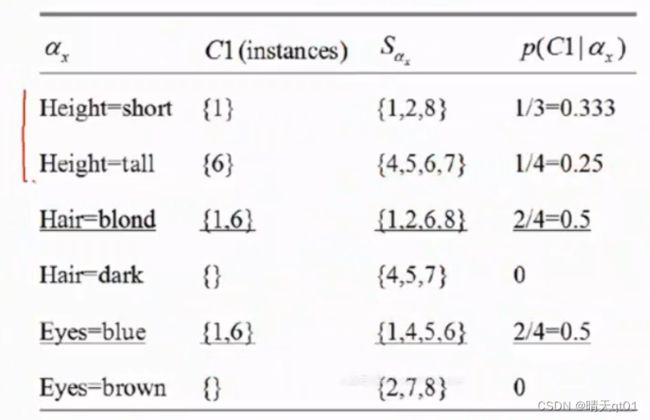
然后我们寻找,预测C1里面概率最大的是,Hair=Blond。再继续往下建立一个新的数据集,也就是左上角的数据集。

里面我们再去统计字段和C1的关系。我们发现当hair=blond的情况下eyes=blue(比height案例多,有2个)得到{1,6}
得到第2个规则,hair=Blond eyes=blue,则归类到C1
然后我们在把1,6排除掉。再去寻找C2
最后PRISM会得到4个规则

如果我们用ID3来进行分类树,我们会发现第3个规则是假规则。
所以PRISM就不需要多产生条件。可以产生比较少的条件,比较简化的规则。
分类树容易产生不相关的假条件,这里我们是针对算法的可解读性,不是准确率这些的问题来说明PRISM的优点,因为很多时候得到的条件很难解读的话,企业不能使用,而PRISM就可以吧假条件去除。容易找到业务关系。

如果你产生了一个比较好的分类规则,那你就规避掉了解读的问题。避免了很多假条件。
决策树到目前为止,我们就全部讲完了。
下面就到神经网络与深度学习的内容。