zookeeper深入浅出
zookeeper深入浅出
- 一,zookeeper深入浅出
-
- 1,zookeeper的基本信息
-
- 1.1,文件系统数据结构
- 1.2,zk一种cs结构
- 1.3,事件的监听机制
- 2,zookeeper经典的应用场景
- 3,下载安装
- 4,创建节点
- 5, zookeeper的ACL权限控制
-
- 5.1,权限信息
- 5.2,命令
- 6,ZooKeeper 内存数据和持久化
- 7,zookeeper代码实现
-
- 7.1,需要的依赖
- 7.2,创建zookeeper客户端
- 8,Curator实战
-
- 8.1,需要的依赖
- 8.2,创建Curator实体
- 8.3,递归创建子结点
- 8.4,删除结点
- 8.5,通过线程池去实现这个异步的创建结点的方式
一,zookeeper深入浅出
1,zookeeper的基本信息
zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同 步服务、集群管理、分布式应用配置项的管理等。
它是一个基于观察者模式的分布式服务管理框架,主要负责存储和管理大家关心的数据,然后接受观察者的注册,一旦数据的状态发生变化,zookeeper会将负责通知在zookeeper上注册的那些观察者做出相应的反应。主要有两个核心:文件系统数据结构+监听通知机制
1.1,文件系统数据结构
Zookeeper维护一个类似文件系统的数据结构,每个子目录项都被称为znode,和文件系统类似,我们可以自由的增加,删除znode。主要有下面几个节点:
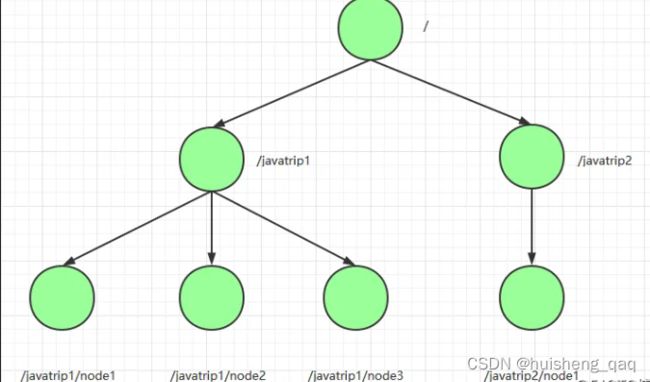
PERSISTENT持久化目录节点:客户端与zookeeper断开连接后,该节点依旧存在,只要不手动删除该节点,他将永远存在
PERSISTENT_SEQUENTIAL持久化顺序编号目录节点:客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号,长度10位。
EPHEMERAL临时目录节点:客户端与zookeeper断开连接后,该节点被删除,主要是和这个sessionId的过期时间进行绑定
EPHEMERAL_SEQUENTIAL临时顺序编号目录节点:客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
Container 节点:如果Container节点下面没有子节点,则Container节点在未来会被Zookeeper自动清除,定时任务默认60s 检查一次,就是说一个容器节点如果加了子节点,后面子节点被删除了,也会把这个容器节点删除。
TTL 节点:默认禁用,只能通过系统配置 zookeeper.extendedTypesEnabled=true 开启,不稳定。不需要自己去维护这个过期时间的问题,可以自定义维护这个存活时间。
1.2,zk一种cs结构
即一种客户端和服务端结构。首先会有一次tcp的三次握手建立连接,然后连接建立成功之后会生成一个sessionId,会携带一个sessionId来控制这个连接的过期时间。临时节点主要是通过这个过期时间来设置
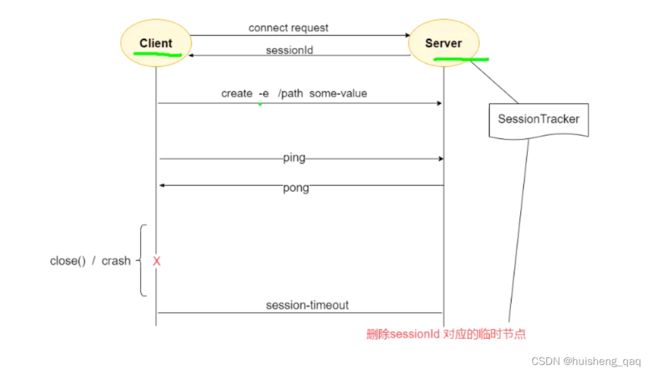
长连接和短连接并没有本质的区别,主要是根据业务来区分,如果要及时关掉就是一个短连接。
短连接是指通讯双方有数据交互时,就建立一个连接,数据发送完成后,则断开此连接,即每次连接只完成一项业务的发送。
长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况。每个TCP连接都需要三步握手,这需要时间,如果每个操作都是短连接,再操作的话那么处理速度会降低很多,所以每个操作完后都不断开,下次处理时直接发送数据包就OK了,不用建立TCP连接。 例如数据库连接,就是使用的就是长连接。
1.3,事件的监听机制
就是说可以对任意一个结点进行监听,即客户端注册监听它关心的任意节点,或者目录节点及递归子目录节点。
1,如果监听的是某个结点,节点被删除或者修改时,对应的客户端将被通知
2,如果是对某目录进行监听,则这个目录的子节点被创建或者删除时,对应的客户端将被通知
3,如果是对目录的递归子节点进行监听,则目录下面的任意子节点有变化,对应的客户端将被通知
通知都是一次性的,无论是对对应的结点还是目录进行监听,一旦触发,对应的监听即将被移除。
2,zookeeper经典的应用场景
1,分布式配置中心
2,分布式注册中心
3,分布式锁
4,分布式队列
5,集群选举
6,分布式屏障
7,发布/订阅
3,下载安装
下载地址:https://zookeeper.apache.org/releases.html
下载之后再解压:
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz
复制一份zoo_sample.cfg配置文件,并重新命名
cp zoo_sample.cfg zoo.cfg
启动命令,通过bin目录下的zkServer.sh进行启动
# 可以通过 bin/zkServer.sh 来查看都支持哪些参数
bin/zkServer.sh start conf/zoo.cfg

在安装目录下面创建data文件夹,然后在zoo.conf配置文件中设置这个dataDir路径为刚刚创建的data路径
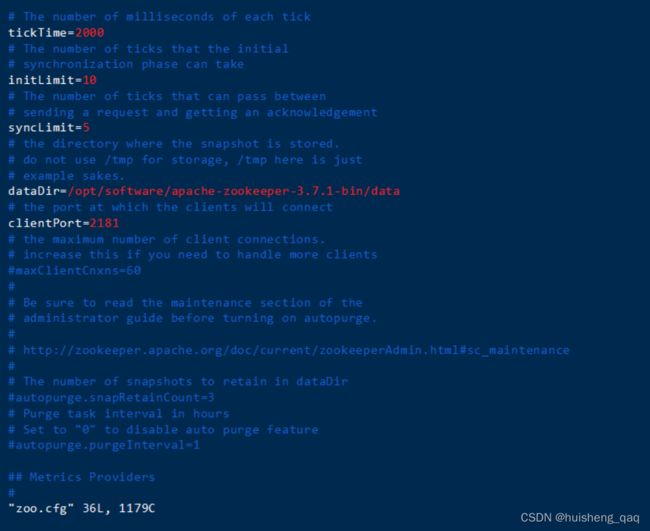
接下来就可以启动服务了

切换到这个bin目录下面,连接这个zookeeper
#连接本机
./zkCli.sh
#连接远程
./zkCli.sh -server ip:2181
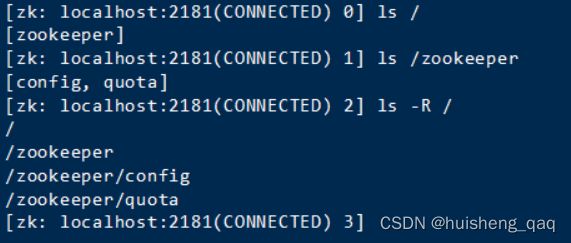
查看里面的全部信息。
ls / #查看当前目录下的节点
ls -R / #递归查看所有的子节点,可以发现呈树形形状
4,创建节点
1,创建结点的命令如下
create [-s] [-e] [-c] [-t ttl] path [data] [acl]
# -s: 顺序节点
# -e: 临时节点
# -c: 容器节点
# -t: 可以给节点添加过期时间,默认禁用,需要通过系统参数启用
2,创建持久化结点,每个创建的命令都要以**/**开头
create /test
create /test2 zhenghuisheng #设置key/value
get /test2 #获取这个value
set /test #修改
create /test2/sub0 # 创建子结点
3,创建顺序的持久化结点,主要添加这个 -s 命令
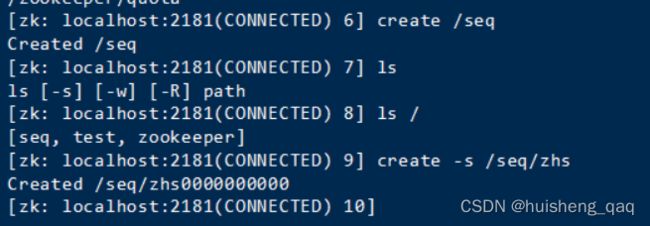
create /seq #创建一个父目录
create -s /seq/zhs #会生成一个10位的序列号,如下图,因此方便可以实现一个分布式锁
4,创建临时结点
create -e /temp #创建临时结点
create -e /temp qaq
get -s /temp

每个节点都有一个附属信息。
cZxid = 0x6 #事务id,创建,删除,修改都属于事务请求。通过这个事务id来保证这个顺序
ctime = Tue Jul 12 22:34:10 CST 2022 #创建这个事务的时间
mZxid = 0x6 #修改这个事务的事务id
mtime = Tue Jul 12 22:34:10 CST 2022 #修改时间
pZxid = 0x6 #子结点的事务被修改
cversion = 0 #子结点的版本id
dataVersion = 0 #乐观锁
aclVersion = 0 #权限控制
ephemeralOwner = 0x1028ab84f120000 #临时结点的过期时间
dataLength = 0 #数据长度
numChildren = 0 #子结点个数
临时结点和持久化结点的区别就是里面的这个ephemeralOwner不一样。临时结点在时间过期之后,会被服务器给清除掉。临时结点后面不能有子结点。 临时顺序结点和持久化顺序结点一样,并且也是一旦超时,就被被服务器给清楚掉。一旦这个sessionId超时,就不能被救活。
5,容器节点,-c开头,
create -c /container qqq #创建一个父节点
get -s /conteiner
create -c /container/sub0 #创建一个子结点
create -c /container/sub1
create -c /container/sub2
delete /container/sub0 #删除这个容器中的子结点
delete /container/sub0
delete /container/sub0
deleteall #删除全部节点
容器中的节点被删除之后,这个容器默认会存活60s时间,60s之后,就会删除这些结点。
6,ttl节点
需要启动一个系统参数,在这个bin目录下面,修改这个zkServer.sh,在这个ZOOMAIN后面直接添加
-Dzookeeper.extendedTypesEnabled=true
7,监听节点 -w,可以对结点进行通知,也可以对目录进行通知。结点的监听都是一次性的。get增对事件,ls针对目录。
#在获取这个数据时进行监听,一旦数据修改,立马会收到。
get -w /test01
ls -R -w /test #递归监听下面的全部结点
removewatches /test01 #删除监听
5, zookeeper的ACL权限控制
主要由三部分组成,有权限模式,授权对象,权限信息。
5.1,权限信息
创建结点权限:授权对象可以在数据结点下面创建子结点
更新结点权限:授权对象可以在数据结点下面更新子结点
读取结点权限:授权对象可以读取该节点的内容以及子结点的列表信息
删除结点权限:删除数据结点的子结点
管理者权限:授权对象可以对该数据结点进行ACL权限设置
5.2,命令
getAcl:获取某个节点的acl权限信息
setAcl:设置某个节点的acl权限信息
addauth: 输入认证授权信息,相当于注册用户信息
加密如下:
#通过‐sha1的方法进行加密,base64的方法进行编码
echo ‐n user1:pass1 | openssl dgst ‐binary ‐sha1 | openssl base64
创建节点并进行加密
create / zk‐node datatest digest:gj:X/NSthOB0fD/OT6iilJ55WJVado=:cdrwa
或者直接使用setAcl
setAcl / zk‐node digest:gj:X/NSthOB0fD/OT6iilJ55WJVado=:cdrwa
因此访问前需要进行授权
addauth digest zhs:test
get /zk‐node #获取
也可以使用明文的方式进行授权
#首先需要先登录
addauth digest u100:p100
#直接通过明文的方式创建节点
create /node‐1 node1data auth:u100:p100:cdwra
这是u100用户授权信息会被zk保存,可以认为当前的授权用户为u100
get /node‐1
也可以通过这个ip地址进行授权,也是需要登录才能访问结点
setAcl /node‐ip ip:192.168.109.128:cdwra
create /node‐ip data ip:192.168.109.128:cdwra
#登录
addauth digest u100:p100
6,ZooKeeper 内存数据和持久化
Zookeeper数据的组织形式为一个类似文件系统的数据结构,而这些数据都是存储在内存中的,所以我们可以认为,Zookeeper是一个基于内存的小型数据库。由ConcurrentHashMap存储数据。每一个操作都会存为一个事务日志,每一个操作都会持久化。
持久化数据方式主要有日志和快照。快照内存相对较小,日志的话会提前申请一个默认大小的空间,因此每个日志文件的大小都一样。
7,zookeeper代码实现
7.1,需要的依赖
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.7.1</version>
</dependency>
7.2,创建zookeeper客户端
//创建zookeeper客户端
zooKeeper=new ZooKeeper(CONNECT_STR, SESSION_TIMEOUT, new Watcher() {
@Override
public void process(WatchedEvent event) {
if (event.getType()== Event.EventType.None
&& event.getState() == Event.KeeperState.SyncConnected){
log.info("连接已建立");
countDownLatch.countDown();
}
}
});
zookeeper启动主要是通过线程的方式启动,里面主要包括两个线程,一个用来发送数据,一个来接受数据,并进行事件的监听。
this.cnxn.start();
public void start() {
//客户端往服务端发送数据
this.sendThread.start();
//接收客户端响应的线程,同时还有事件线程
this.eventThread.start();
}
进入源码可以发现,这两个线程其实就是一个守护线程
//业务现场在运行的时候,守护线程会自动退出
this.setDaemon(true);
创建持久化结点
/**
*/myconfig:结点名称
*ZooDefs.Ids.OPEN_ACL_UNSAFE:用于全部权限
*/
zooKeeper.create("/myconfig", bytes, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
基于乐观锁实现这个修改数据。通过dataVersion实现
@Test
public void testSetData() throws KeeperException, InterruptedException {
ZooKeeper zooKeeper = getZooKeeper();
Stat stat = new Stat();
//false:不监听
byte[] data = zooKeeper.getData(first_node, false, stat);
// int version = stat.getVersion();
zooKeeper.setData(first_node, "third".getBytes(), 0);
}
创建结点可以通过同步的方式实现,也可以同步异步的方式实现
//通过同步的方式实现,如果消息没有收到,就会阻塞
byte[] data = getZooKeeper().getData(first_node, watcher, null);
//也可以通过异步的方式实现,即通过一个异步的方式进行回调
getZooKeeper().getData("/test", false, (rc, path, ctx, data, stat) -> {
Thread thread = Thread.currentThread();
},"test");
8,Curator实战
这个是用Java 语言编程的 ZooKeeper 客户端框架,Curator项目是现在ZooKeeper 客户端中使用最多,对ZooKeeper 版本支持最好的第三方客户端,并推荐使用,Curator 把我们平时常用的很多 ZooKeeper 服务开发功能做了封装,例如 Leader 选举、分布式计数器、分布式锁等
8.1,需要的依赖
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>5.0.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-x-discovery</artifactId>
<version>5.0.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
8.2,创建Curator实体
curatorFramework = CuratorFrameworkFactory.builder().connectString(getConnectStr())
.retryPolicy(retryPolicy)
.sessionTimeoutMs(sessionTimeoutMs)
.connectionTimeoutMs(connectionTimeoutMs)
.canBeReadOnly(true)
.build();
//对连接进行一个监听
curatorFramework.getConnectionStateListenable().addListener((client, newState) -> {
if (newState == ConnectionState.CONNECTED) {
log.info("连接成功!");
}
});
8.3,递归创建子结点
// 递归创建子节点,即子结点和子子结点都会被创建
@Test
public void testCreateWithParent() throws Exception {
//获取这个Curator连接
CuratorFramework cf = getCuratorFramework();
String pathWithParent = "/node-parent/sub-node-1";
String path = cf.create().creatingParentsIfNeeded().forPath(pathWithParent);
log.info("curator create node :{} successfully.", path);
}
CuratorFramework curatorFramework = getCuratorFramework();
String forPath = curatorFramework
.create()
.withProtection() //起一个保护机制
.withMode(CreateMode.EPHEMERAL_SEQUENTIAL).
forPath("/curator-node", "some-data".getBytes());
log.info("curator create node :{} successfully.", forPath);
如客户端发送请求成功,但是服务端在响应的时候出现异常,那么这个客户端会进行这个重试的机制。在创建结点的时候会设置这个唯一id,如果创建成功,则不会重复创建。同时如果session过期的话,这个客户端也会将这个结点给删除。
8.4,删除结点
@Test
public void testDelete() throws Exception {
CuratorFramework cf = getCuratorFramework();
String pathWithParent = "/node-parent";
//删除当前结点
cf.delete().guaranteed().deletingChildrenIfNeeded().forPath(pathWithParent);
}
8.5,通过线程池去实现这个异步的创建结点的方式
@Test
public void testThreadPool() throws Exception {
CuratorFramework curatorFramework = getCuratorFramework();
ExecutorService executorService = Executors.newSingleThreadExecutor();
String ZK_NODE="/zk-node";
curatorFramework.getData().inBackground((client, event) -> {
log.info(" background: {}", event);
},executorService).forPath(ZK_NODE);
}