C++ 继承详解
C++ 继承
- 继承语法
- 继承方式
- 改变访问权限
- 名字遮蔽
- 继承时的对象模型
-
- 无变量遮蔽
- 有变量遮蔽
继承语法
继承的一般语法为:
class 派生类名:[继承方式] 基类名{
派生类新增加的成员
};
继承方式
继承方式包括 public(公有的)、private(私有的)和 protected(受保护的),此项是可选的,如果不写,那么默认为 private。不同的继承方式会影响基类成员在派生类中的访问权限。
(1)public继承方式
- 基类中所有 public 成员在派生类中为 public 属性;
- 基类中所有 protected 成员在派生类中为 protected 属性;
- 基类中所有 private 成员在派生类中不能使用。
(2)protected继承方式
- 基类中的所有 public 成员在派生类中为 protected 属性;
- 基类中的所有 protected 成员在派生类中为 protected 属性;
- 基类中的所有 private 成员在派生类中不能使用。
(3)private继承方式
- 基类中的所有 public 成员在派生类中均为 private 属性;
- 基类中的所有 protected 成员在派生类中均为 private 属性;
- 基类中的所有 private 成员在派生类中不能使用。
通过上面的分析可以发现:
- 基类成员在派生类中的访问权限不得高于继承方式中指定的权限。例如,当继承方式为 protected 时,那么基类成员在派生类中的访问权限最高也为 protected,高于 protected 的会降级为 protected,但低于 protected 不会升级。再如,当继承方式为 public 时,那么基类成员在派生类中的访问权限将保持不变。也就是说,继承方式中的 public、protected、private 是用来指明基类成员在派生类中的最高访问权限的。
- 不管继承方式如何,基类中的 private 成员在派生类中始终不能使用(不能在派生类的成员函数中访问或调用)。
- 如果希望基类的成员能够被派生类继承并且毫无障碍地使用,那么这些成员只能声明为 public 或 protected;只有那些不希望在派生类中使用的成员才声明为 private。
- 如果希望基类的成员既不向外暴露(不能通过对象访问),还能在派生类中使用,那么只能声明为 protected。
注意,我们这里说的是基类的 private 成员不能在派生类中使用,并没有说基类的 private 成员不能被继承。实际上,基类的 private 成员是能够被继承的,并且(成员变量)会占用派生类对象的内存,它只是在派生类中不可见,导致无法使用罢了。private 成员的这种特性,能够很好的对派生类隐藏基类的实现,以体现面向对象的封装性。
改变访问权限
使用 using 关键字可以改变基类成员在派生类中的访问权限,例如将 public 改为 private、将 protected 改为 public。
注意:using 只能改变基类中 public 和 protected 成员的访问权限,不能改变 private 成员的访问权限,因为基类中 private 成员在派生类中是不可见的,根本不能使用,所以基类中的 private 成员在派生类中无论如何都不能访问。
using 关键字使用示例:
#include代码中首先定义了基类 People,它包含两个 protected 属性的成员变量和一个 public 属性的成员函数。定义 Student 类时采用 public 继承方式,People 类中的成员在 Student 类中的访问权限默认是不变的。
不过,我们使用 using 改变了它们的默认访问权限,如代码第 21~25 行所示,将 show() 函数修改为 private 属性的,是降低访问权限,将 name、age 变量修改为 public 属性的,是提高访问权限。
名字遮蔽
如果派生类中的成员(包括成员变量和成员函数)和基类中的成员重名,那么就会遮蔽从基类继承过来的成员。所谓遮蔽,就是在派生类中使用该成员(包括在定义派生类时使用,也包括通过派生类对象访问该成员)时,实际上使用的是派生类新增的成员,而不是从基类继承来的。
下面是一个成员函数的名字遮蔽的例子:
#include运行结果:
小明的年龄是16,成绩是90.5
嗨,大家好,我叫小明,今年16岁
本例中,基类 People 和派生类 Student 都定义了成员函数 show(),它们的名字一样,会造成遮蔽。第 37 行代码中,stu 是 Student 类的对象,默认使用 Student 类的 show() 函数。
但是,基类 People 中的 show() 函数仍然可以访问,不过要加上类名和域解析符,如第 39 行代码所示。
基类成员函数和派生类成员函数不构成重载。基类成员和派生类成员的名字一样时会造成遮蔽,这句话对于成员变量很好理解,对于成员函数要引起注意,不管函数的参数如何,只要名字一样就会造成遮蔽。换句话说,基类成员函数和派生类成员函数不会构成重载,如果派生类有同名函数,那么就会遮蔽基类中的所有同名函数,不管它们的参数是否一样。
下面的例子很好的说明了这一点:
#include本例中,Base 类的func()、func(int)和 Derived 类的func(char *)、func(bool)四个成员函数的名字相同,参数列表不同,它们看似构成了重载,能够通过对象 d 访问所有的函数,实则不然,Derive 类的 func 遮蔽了 Base 类的 func,导致第 26、27 行代码没有匹配的函数,所以调用失败。
如果说有重载关系,那么也是 Base 类的两个 func 构成重载,而 Derive 类的两个 func 构成另外的重载。
继承时的对象模型
无变量遮蔽
有继承关系时,派生类的内存模型可以看成是基类成员变量和新增成员变量的总和,所有成员函数仍在另外一个区域——代码区,由所有对象共享。请看下面的代码:
#include obj_a 是基类对象,obj_b 是派生类对象。假设obj_a 的起始地址为 0X1000,那么它的内存分布如下图所示:
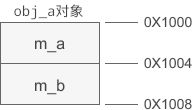
虽然变量 a 仅占用一个字节的内存,但由于内存对齐的需要,编译器会添加 3 个无用的字节(图中灰色部分),保证地址是 4 的倍数。后面的讲解中将忽略内存对齐,假设 a 的长度为4个字节。
假设 obj_b 的起始地址为 0X1100,那么它的内存分布如下图所示:
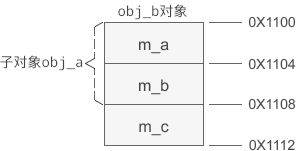
可以发现,基类的成员变量排在前面,派生类的排在后面。
下面再由 B 类派生出一个 C 类:
class C: public B{
private:
int d;
public:
C(char a, int b, int c, int d): B(a,b,c), d(d){ }
};
C obj_c('@', 45, 1009, 39);
假设 obj_c 的起始地址为 0X1200,那么它的内存分布如下图所示:
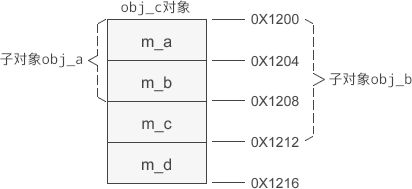
成员变量按照派生的层级依次排列,新增成员变量始终在最后。
有变量遮蔽
更改上面的C类:
class C: public B{
private:
int b; //遮蔽A类的变量
int c; //遮蔽B类的变量
int d; //新增变量
public:
C(char a, int b, int c, int d): B(a,b,c), b(b), c(c), d(d){ }
void display(){
printf("A::a=%c, A::b=%d, B::c=%d\n", a, A::b, B::c);
printf("C::b=%d, C::c=%d, C::d=%d\n", b, c, d);
}
};
C obj_c('@', 23, 95, 2000);
假设 obj_c 的起始地址为 0X1300,那么它的内存分布如下图所示:
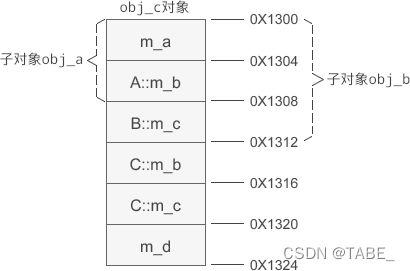
当基类A、B的成员变量被遮蔽,仍然会留在派生类对象 obj_c 的内存中,C 类新增的成员变量始终排在基类A、B的后面。
总结:派生类的对象模型中,会包含所有基类的成员变量。这种设计方案的优点是访问效率高,能够在派生类对象中直接访问基类变量,无需经过好几层间接计算。