后端500题ing
1-10题
1、任何物理设计(Physical Design)工具所需的输入以及从中生成的输出是什么
物理设计工具需要的Input data
- Technology file
- Physical Libraries
- Timing,Logical and Power Libraries
- TDF file
- Constraints
- Physical Design Exchange Format -PDEF(optional)
- Design Exchange Format -DEF (optional)
物理设计工具需要的Output data
- Standard delay format (.sdf)
- Parasitic format (.spef,.dspf)
- Post routed Netlist (.v)
- Physical Layout (.gds)
- Design Exchange format (. def)
物理设计工具需要的Input data
1、Technology file
(synopsys家格式:.tf cadence 家格式: .techlef ) :
描述了制造过程中的单元,绘图图案,层设计规则,通孔以及寄生电阻和电容。
2、Physical Libraries
总体而言,GDS 文件的 Lef 文件用于所有设计元素,如宏、std 单元、I0 PAD等,以及上面的 synopsys 格式 .CEL,.FRAM 视图 :
包含完整的布局信息和抽象模型,用于放置和布线,如引脚可访问性,阻塞(blockages)等。
3. Timing,Logical and Power Libraries
(.lib or LM view -. db for all design elements) :
包含时序和电源信息
4. TDF file (.tdf or .io) :
包含pad或引脚排列,如相同的顺序和位置。对于全芯片,实例化的VDD和VSS PAD 给Cut diode等供电。(Verilog 网表中没有)
5. Constraints (.sdc) :
包含所有与设计相关的约束,如面积、功率、时序。
6. Physical Design Exchange Format -PDEF(optional) :
包含行(row)、单元放置位置等
7. Design Exchange Format -DEF (optional) :
包含行(row)、单元放置位置等
物理设计工具需要的Output data
- Standard delay format (.sdf) : 时序细节 (除了负载信息)
- Parasitic format (.spef,.dspf) : cells或者nets的电阻和电容信息
- Post routed Netlist (.v)可以是扁平的或分层的:包含所有cell的连接信息。
- Physical Layout (.gds) : 物理布局信息
- Design Exchange format (. def) : 包含 row ,cell,net placement locations 等
2、 什么是 sanity checks(健全性检查)
健全性检查(Sanity Checks)主要在时序方面检查网表的质量,它还包括检查与库文件,时序约束,IO和优化指令相关的问题
一些网表健全性检查:
- Floating Pins(浮动引脚)
- Unconstrained Pins(无约束引脚)
- Un-driven i/p Ports(非驱动 i/p 端口)
Unloaded o/p Ports(空载的 o/p 端口)
- 引脚方向不匹配
- 多驱动等
其他可能的问题
- 未连接/错误连接的 Tie-high/Tie-low 引脚
- 电源引脚(因为 Tie-up 或 Tie-down 连接总是通过 Tie-Cells)
3、开始 Floor plan需要做什么?
(1)首先做数据输入:输入.v, .lib,.lef,.SDC等数据。【这是完成floor plan的第一个重要步骤。】
(2)定义芯片/块的大小,分配电源布线资源,放置hard macros,并为标准单元预留空间。【floor plan决定了芯片质量】
4、PD(physical design)的实现方式 ?
Flat
- 中小型专用集成电路
- 由于每个子设计周围没有备用空间用于电源/接地,因此具有更好的区域使用率
Hierarchical
- 用于超大型设计
- 当子系统单独设计时
- 仅当存在设计层次结构时才可能
5、放置宏(macros)的准则是什么?
在芯片外围放置宏
如果您没有合理的理由将宏放置在核心区域内,则将宏放置在芯片外围周围。
由于detour routing(绕很多线)的情况很多,在routing过程中,在核心内部放置宏可能会导致严重的后果,因为宏等于routing的一个大障碍。
将hard macros放置在核心外围的另一个优点是,更容易为它们供电,并减少了消耗大量功率的宏的IR drop问题。
放置宏时,请考虑与固定单元的连接:
在确定宏位置时,必须注意与固定元素(如 I/0 和预置宏)的连接。将宏放在其关联的固定元素附近。【通过在 GUI 中显示飞线(flight lines )来检查连接】
定向宏,使引脚之间的距离最小化
在确定宏的方向时,还必须考虑引脚位置及其连接。
在宏周围预留足够的空间
保留足够的布线空间
对于常规的网络布线和电源网络,您必须在宏周围保留足够的布线空间。在这种情况下,精确估计布线资源非常重要。使用试用 Route 中的congestion map来识别宏之间的congestion的热点,并根据需要调整其位置。
尽可能减少open fields:
除保留的布线资源外,请删除死区以增加随机逻辑的面积。选择不同的宽高比(如果该选项可用)可以消除open fields。
为电源网络预留空间:
所需的电源布线数量可以根据一个功耗而变化。您必须估计功耗并为电网预留足够的空间。如果低估了电源布线所需的空间,则可能会遇到布线问题。
6. 如果引脚分配给左侧和右侧,会发生什么情况。(如果你的顶部和底部有I0引脚)?
实际上顶层芯片会分成几个块,I0引脚会根据周围的块之间的通信来放置。
如果我们将引脚分配给左侧和右侧,而不是顶部和底部,我们将在以后的阶段面临布线问题。
7、在两个宏之间分配间距?
channel spacing= no of pins*pitch/ (total number of metal layers/2)
8、 如果我们对齐宏,会发生什么?
有两种情况
- 如果两个宏仅相互通信,可以对齐宏。
- 如果宏与其他单元(std cell和IO端口)通信,那么必须在宏之间提供适当的通道间距,否则,会有布线问题。
9.我们可以放置宏 90 和 270° 方向吗?
这取决于您正在研究哪种技术。
45nm及以下 foundry有朝向要求。Poly 方向应在整个芯片中相同。因此,宏的 poly 方向应与标准单元的poly方向匹配。
10、 在电源规划中,ring和stripe使用哪些金属层,为什么?
对于 rings 和 stripes,我们使用顶部金属层,因为顶部金属层有低电阻率。
- ✡ 高层更适合global routing。低层使用率比较高,用来做power的话会占用一些有用的资源,比如std cell 通常是m1 Pin 。
- ✡ EM能力不一样,一般顶层是低层的2~3倍。更适合电源布线。顶层金属通常比较厚,可以通过较大的电流
- ✡ 一般ip占用的层次都靠近下几层,如果上层没有被禁止routing的话,top layer 可以穿越,低层是不可能的,并且高层对下层的noise影响也小很多。
11-20题
11、我们可以在IO和core边界之间的空间放置单元吗?
不,我们不能在IO和core边界的空间之间放置cells,因为在IO和核心边界之间将放置电源环,否则会有布线问题。
12、您在placement后见过哪种类型的congestion?
- 由于placement blockage不足,Macro角落附近拥堵。
- 在狭窄通道中放置标准单元会导致拥塞。
- 同一模块的Macros如果相距较远,可能会导致时序违规。
- Macros的放置或Macros的通道不合适。
- 未给出placement blockage。
- 没有给出宏到宏通道空间。
- 高单元密度。
- 本地利用率高。
- 大量的复杂的cell(如具有很多的pin的AOI / OAI cell),被放置在一起。
- 将std cells放置在macros附近。
- 逻辑优化未正确完成。
- 引脚密度更多位于块的边缘。
- 优化时Buffer添加太多。
- IO 端口纵横交错;它需要按顺序正确对齐。
13、物理单元(physical cells)有哪些
End Cap cells:
- 这些cells可防止制造过程中的cell损坏。
- 用于row连接,并且指定row结束。
- 避免漏源短路。
- 这些用于解决 DRC 清理的边界 N-Well 问题。
Well Tap cells:
- 这些用于将 VDD 和 GND 分别连接到衬底和 N-Well,因为它会产生较小的漂移以防止闩锁。
- 如果使well tap之间保持指定距离,N-Well电位会产生正常的电气功能。
- 限制电源和地连接到衬底阱之间的电阻。
De- cap Cells:
- 它们是临时电容器,添加在在设计中电源和地的rail之间,以应对由于动态 IR 压降引起的功能故障。
- 避免远离电源的触发器进入亚稳态。
Filler Cells:
填充空的区域并提供 N 阱和注入层( implant layers)的连通性。
14、Non Default Rules(NDR)相关内容有什么?
Double width and double space.(双倍宽度和双倍间距。)
在 PNR 阶段之后,如果您会遇到在 ECO 阶段难以修复的时序/串扰/噪声违例,我们可以在route阶段尝试此 NDR 选项。
NDR 的用法和示例
当我们为诸如时钟之类的特殊网络布线时,我们希望为它们提供更大的宽度和更大的间距。 代替技术文件中默认的1个单位间距和1个单位宽度;
但是 NDR 具有双倍间距和双倍宽度。 时钟网络使用NDR布线时,信号完整性更好,串扰更小,噪声更小,但我们不能增加间距和宽度,因为它会影响芯片的面积。
Double spacing:用于避免串扰。
Double width: 用于避免EM。
15、What is setup and hold?
SETUP:时钟沿之前数据稳定所需的最短时间。
HOLD: 时钟沿后数据稳定所需的最短时间。
16. 在placement阶段可以进行setup check吗?
是的,我们将在placement阶段检查setup,而我们不会担心hold,因为时钟在placement阶段是idea的。
17、 修setup和hold violation的方法有哪些
A. Setup:
- Upsizing the cells(放大cell)
- Replace buffer with two inverters(用2 inverters换1 buffer)
- HVT to LVT(高电压阈值cell换成低电压阈值cell)
- If the net delay is more than break the net and insert the buffer
- Pin swapping(引脚交换)
- Pulling the launch and pushing the capture(延长发射,减小捕获)
- Cloning
B. Hold:
- Inserting the buffers(插入buffer)
- Downsizing the cells(缩小cell)
- LVT to HVT(低电压阈值cell换成高电压阈值cell)
- Pushing the launch and pulling the capture
18、怎么知道自己有 max cap violation?
report_timing - all violators19、在设计中怎么使用High Vt 和 Low Vt来降低功耗( Power Dissipation) ?
- 对有+ve slacks 的时序路径使用HVT 单元。
- 对有-ve slacks 的时序路径使用LVT 单元。
- HVT 单元延迟较大,但漏电较少。 设计中,+ve slack是没有用的,因为只有一些路径工作得更快,并不会帮助整体设计。如果 slack 为 0,我们很好。在这种情况下,通过使用 HVT 单元放弃 slack,但会增加功耗。
- LVT 单元速度非常快,但漏电大。 将 LVT 单元的使用限制在那些难以关闭时间的路径上。
20、什么是电迁移(Electromigration EM)以及如何解决它?
解释1:
电迁移(EM)是指由于从导电电子到金属原子的动量转移,金属原子运动的现象。 由于 EM 效应,金属路径中一段时间内的电流传导会导致开路或短路。电磁效应是无法避免的。
为了尽量减少电迁移(EM)的影响,我们使用更宽的导线,这样即使有 EM 效应,导线也能保持足够宽,以便在 IC 的整个生命周期内导电。
解释2:
由于金属中的金属原子中的高电流可以从其原始位置移位。 当它大量发生时,金属会打开或金属层会发生膨胀。这种效应称为电迁移。
影响:信号线或电源线短路或开路。
21-30题
21、为什么IR drop分析很重要?
IR drop 决定了标准单元引脚上的电压电平。 可接受的 IR 降值将在项目开始时确定,它是用于确定降额值的因素之一。如果 IR drop 的值大于可接受的值,它要求更改降额值。如果没有这种变化,时序计算就会变得乐观。例如,工具计算的 setup slack 小于实际值。
22、如果你同时遇到IR drop和congestion问题,你会怎么修啊?
- 把Marcos分散开
- 把标准单元分散开
- 增加strap的宽度
- 增加strap的数量
- 合理使用blockage
23、在 Reg 到 Reg 路径中,如果您有setup问题,您将在哪里插入buffer——接近启动触发器或捕获触发器? 为什么?
- 插入buffer是为了修复fanout violations,因此它们会减少setup违规;否则我们会尝试通过单元的大小来修复setup违规;现在假设您必须插入buffer!)
- 靠近捕捉路径。
- 因为可能有其他路径通过或源自更接近启动触发器的触发器。 因此插入buffer也可能影响其他路径。它可能会改善所有这些路径或降级。 如果所有这些路径都违反了,那么您可以在更靠近启动触发器的位置插入buffer,前提是它可以改善 slack。
24、Clock Tree中为什么要用Buffers ?
为了平衡skew (例如flop to flop delay)
25. 什么是串扰( Cross Talk)?
由于交叉耦合电容(cross coupling capacitance),在一个网络中切换信号会干扰相邻网络。 这种影响称为串扰。 串扰可能导致setup 或 hold violation.
26. 怎么样避免 Cross Talk?
- 双倍间距→ 更宽的间距→ 更小的电容 → 更小的crosstalk影响
- 多孔(via) → 更小的电阻 - 更小的 RC delay
- 屏蔽(Shielding) →恒定交叉耦合电容值 → crosstalk值已知
- 插入Buffer → 增强 victim 驱动力
27. Shielding是怎么避免 Crosstalk 问题? 这具体发生什么?
- 因为屏蔽层(shielded layers)连接到 VDD 或 VSS。,高频噪声noise( 或毛刺 glitch)耦合到 VSS (或VDD)
- 耦合电容与 VDD 或 VSS 保持恒定。
28、间距(Spacing)是怎样帮助减小 Crosstalk Noise?
width 越大→ 两个导体之间的间距(spacing)越大 → 交叉耦合电容越小→ cross talk越小
29、Buffer是怎么 用在 Victim 中来避免 Crosstalk?
Buffer 增加 victims 信号驱动强度;
buffers 打断 net 长度 →victims更能容忍来自aggressor的耦合信号。
30、为什么 Setup 在 max corner下检查, Hold 在 min corner下检查?
对于 setup ,
required time应该大于arrival time。当arrival time大时,有setup violates .
因此, 当 arrival time大或者当launch clock比capture clock 到达晚了,setup check更悲观。
这意味着 delay 更大。因此,setup 将在 max delays下检查。
对于 hold,
arrival time 应该大于 required time。当required time大时,有 hold violates.
因此,当required time大或者当launch clock比capture clock 到达早了,hold check更悲观。
这意味着 data arrival time 更少 。因此, hold将在 min delays下检查。
31-40题
31、为什么在CTS之前不检查hold?
CTS之前, clock 是 ideal的。这意味着不存在准确的skew.。所有clocks 在同一时间到达 flops。因此,我们没有 clock path的skew和 transition 数值, 但是这个信息已经足够去执行 setup analysis,因为 setup violations取决于 data path delay.
只有在CTS之后,时钟被传递( propagated)(实际的 clock tree 已经建立, clock buffers 被添加进时钟树 ,并且已经有了clock tree hierarchy,clock skew ,insertion delay)。
这就是为什么hold violations在CTS之后fix。
32.、 Setup 和 Hold violations可以同时出现在相同的 start points和end points吗?
是的 , 如果它们有不同的组合逻辑路径。
33、可以使用的降额值(derate value)是多少?
-
对于setup check,将数据路径降低 8% 到 15%,时钟路径中没有降额(derate)。
-
对于hold check,时钟路径降低 8% 到 15%,数据路径中没有降额(derate)。
34、为timing sign-off 检查的corners是什么 ?每个corner的derate value是否有任何变化吗?
- Corners: Worst,Best ,Typical.
- 对于best和worst corner, derating value 是一样的,没有变化;对于typical corner,值可能会变小 。
35.、在哪里得到 WLM? 你创建 WLMs吗?怎么样指定WLM?
- 线负载模型(Wire Load Models(WLM) ) 可从库供应商(library vendors)处获得。
- 我们不创建 WLM.
- 可以根据area指定 WLM。
36、在哪里得到 derating value? 决定 derating factor的因素是什么?
- 根据库供应商(library vendors)的指导方针和建议以及以前的设计经验,确定降额值(derating value)。
- PVT变化是决定降额系数(derating factor)的因素。
37、怎样在placement期间修 Setup ?怎样在CTS期间修 Setup 和 hold?
修setup Violation的方法
Placement 阶段:
- Timing path groups:
在 placement阶段,我们可以用group path 这个选项去解决 Setup timing。
对一组paths 或endpoints 进行分组以进行延时成本函数计算。延迟成本函数是所有组的总和(权重weight * violation), 其中violation是组内所有路径违反setup的数量。 如果一个group内没有 violation , 它的延时成本是0 .
group使您能够指定一组路径加以优化,即使另一个group中可能存在更大的violations。
当指定 endpoints时, 通向这些endpoints的 所有paths被分组 。
ICC 语法:
group_path [-weight weight_value] [-critical_range range_value] -name group_name
[-from from_list] [-through through_list] [-to to_list]举例:
group_path -name "groupl" -weight 2.0 -to {CLK1A CLK1B}- Create Bounds(创建边界):
我们可以通过使用固定坐标(fixed coordinates)定义移动边界(move bounds)来约束相关放置单元(relative placement cells,)的放置。
相关放置单元支持soft bounds和 hard bounds,同时支持矩形边界和直线边界(rectangular bounds 和 rectilinear bounds)。
通过使用move bounds来约束relative placement ,使用命令
ICC 命令:
create_bounds -coordinate {100 100 200 200} "U1 U2 U3 U4"-name boundl- place_opt
如果设计有 timing violation,可以重新run 带有 -timing 和-effort high 选项的place_opt 命令。
ICC 命令:
place_opt -mtiing-driven -effort highTiming driven placement尽力将cells沿着时序关键路径放置在一起,以减少net RCs并满足setup timing。
- Change the Floorplan(改变布局)
为了更好的满足时序,改变 Floorplan (macros 放置,macros 间距 和 pin脚方向 )
CTS 阶段
- 增加data-path logic gates的 驱动强度(drive strength):
有更好驱动强度的 cell 可以给负载电容快速充电 ,这意味着更小的传播延时( propagation delay)。
而且, output transition应该改善,在程序阶段会有更好的 delay。
一个有好驱动强度的gate会有较小的电阻 ,能够有效降低 RC时间常量; 因此,可以提供更少的 delay. 这在下面的图中进行了说明。
如果一个‘X’驱动强度的 AND gate,有一个值为‘R’的下拉电阻(pull down resistance),另一个AND gate有‘2X’驱动强度 ,电阻值为 R/2。那么,a bigger 有更好的驱动强度的较大的AND gate有更小的delay。

- 使用具有较低阈值电压的 data-path cells :
替换HVT 。 意味着将 HVT 单元更改为 SVT/RVT 或 LVT。 低 Vt 减少了转换时间,因此传播延迟减少。 因此,将 HVT 替换为 RVT 或 LVT 会加快时序。
- Buffer insertion
如果net 长度很长,那么我们插入 Buffer 。 它减少了转换时间(transition time),从而减少了线延迟(wire delay)。 如果由于转换时间的减少 > 缓冲区的单元延迟,而导致线延迟量减少,则整体延迟减少。
- 减少path中buffer的数量
这将减少cell delay,但会增加wire delay。
因此,如果我们可以减少比wire delay更多的cell delay,则有效级延迟会增加。
- 使用较高的金属层对net进行布线
- 用2inverters替换1 buffers:
添加inverter 比现有的buffer gate减少了2倍的转换时间(transition time)。因此,导线的 RC 延迟减小。
Cell delay :1buffer gate = 2 inverter gate
- 利用 clock skew(useful skew):
Positive skew 帮助改善setup slack.。
因此, 为了修 setup violation,我们可以选择增加 捕获触发器的clock latency , 或者减小发射触发器的 clock latency。
但是,这样做,我们需要小心考虑其他从/到这些触发器形成的时序路径的 setup 和 hold slack 。
这叫做 Useful Skew. 因此,通常来说,Useful skew是故意在时钟路径增加 delay intentionally in 来满足更好的 timing。
修 Hold Violation的方法
Hold violation 是 setup violation的对立面。
当数据与时钟速度相比太快时,就会发生Hold violation。
要修 hold violation, 应该增加data path里的delay 。
- 增加data path 逻辑门的drive strength
- 使用具有高阈值电压的data-path cells
- 插入/移除Buffer
- 使用较高层金属层对net布线
- 增加发射触发器时钟端口到数据输出端(clk ->q) 的delay
38、为什么不将时钟路径降额 -10% 以进行worst corner analysis?
可以做。但它可能不准确,因为数据路径会降额。
39、MMMC 文件在 VLSI 物理设计中的重要性和需求是什么?
- 物理设计期间的多模式多角 (Multi-Mode Multi corner (MMC)) 文件对不同modes & corners的设计进行了分析。
- VLSI 设计可以在功能或测试模式等模式下建模,每种模式都位于不同的process corners。
- 我们需要确保设计在所有corners都是稳定的,具体来说就是技术术语 PVT Corners(Process ,Voltage & Temperature 工艺、电压和温度)。
- 在物理设计的流程中,(规定的 Tool-Cadence,synopsys 等)MMMC 文件获取所有相关细节以获得所需的设计。
40、什么是 Timing DRV/’s, 解释产生的原因和怎么修?
Timing Drvs :
- Max Tran
- Max Cap
- Max Fanout
Causes:
- HVT cells有较慢的转换( transition)
与LVTs和 RVTs相比,HVT cells有较大的阈值电压。因此,这需要更多的时间导通cell,这导致了更大的 transition time。
- 弱驱动(Weak Driver)
driver 不能驱动 load ,这会导致被驱动的cell(driven cell)有差的 transition 。因此会增加 delay。
- 负载很多
驱动单元(driving cell )不能驱动超过其特征的负载。 这是设置在 . lib 使用最大上限值。 如果一个单元的负载增加到超过其最大电容值,那么它会导致不良转换,从而增加延迟。
- net长度很长
net越大,电阻越大,transition越差。 因此导致trans violation。 长net 的 RC 值也会增加单元的负载,从而导致max cap violations。
- Fanout太大:
如果 fanout数增加到超过驱动单元的特征限制,则会导致 max fanout violations. 增加的负载导致 max cap violation ,这也间接导致 max tran violation 。
Fixes:
Max Tran:
- 使用LVT cells替代 HVT cells
- 增大driver大小
- 通过增加buffer,减少net长度。 net越大,电阻越大。在一根长net中间放一个buffer,把电阻分成一两半。
- 通过减少fanout和driven cell的尺寸来减少负载。
Max Cap:
- 增大driver大小
- 通过增加buffer,减少net长度。
- 过减少fanout (通过负载拆分)或缩小驱动单元的尺寸来减少负载。
Max Fanout :
- 通过插入buffer或复制(cloning),将负载拆分来减少fanout 。
41-50题
41、为什么我们在CTS前强调setup violation ,在CTS后强调hold violation?
有效时序路径的Setup time取决于: 最大数据网络计算时间与时钟沿到达接收器(sink)的时间。
在 POST CTS 阶段之前,我们假设所有时钟都是理想的网络,并且它可以在 0 时间内到达芯片的每个可能的时钟接收器(clock sink)!
我们需要关注的是以这种方式实现数据路径,即从起点到终点至少不应该占用超过一个时钟周期。(假设一个完整的周期有效时序路径)。
在setup timing检查的两个组成部分中,一个始终是常数(时钟的周期),另一个变量是数据路径延迟,在 CTS 阶段完成之前,我们可以使用这个变量所有选项。
如果我们不能在 CTS之前实现这一延伸目标(stretch goal),那么以后将很难收敛时序。
因此,直到 CTS 阶段,我们专注于单独获得数据路径综合或数据网络物理实现。
我希望清楚为什么我们专注于 CTS 阶段之前的setup timing。
让我们从另一个角度来看,我们为什么不只关注hold time呢?
路径的Hold time取决于:最小数据路径延迟与时钟边沿时间。
由于时钟在 0 时间内到达芯片的每个接收器, 并且至少,data path delay将始终大于触发器/时序路径端点的保持请求(hold req)。
就是这样,除非时钟路径网络延迟发生变化,否则没有必要分析有效路径的保持时序。(但至少,可以查看总保持时序路径,看看它是否是 FP/MCP。)
42、在placement之后,这里有setup violation,我们应该怎么做?即使我们已经完成了优化。
placement之后的Setup violation是不值得担心的。好吧,除非它来自于模块放置不当。查看宏布局和模块布局,看看是否有问题。
例如,如果有取指令模块(module for instruction fetch)并且它被拆分并放置在两个或三个不同的集群中,那么我们可能想用模块放置指南或边界来约束它。
在放置阶段让tool 有正确的约束,并且把timing effort flag 标记为high,再进行一轮。
进行多轮次的 CTS 和routing阶段的优化。这些中的每一个都将尝试重新审视这个问题,并将做出一些改进。
我见过一些糟糕的slacks,比如 -500 ps 和 30000 plus 路径失败,但这些都由 STA 的时序团队积极处理。(利用诸如upsize,修max cap,max fanout和max transition,放入lvt单元之类的东西)
**Additional note :
在 place 阶段使用的routing engine和timing engine不是signoff 的质量,并且与 tempus 或 primetime 等工具可以评估的东西相差甚远。
43、 超大规模集成电路物理设计(VLSI physical design)中的插入延迟(insertion delay)是什么意思?
- insertion delay 概念来自 时钟树综合( clock tree synthesis)。
- 当建立 clock tree时,cts 开始构建从时钟源到接收器的时钟。
- 一旦构建了时钟,现在时钟信号必须从源(source )传输到接收器(sinks)。 时钟信号从源传输到接收器所花费的时间称为插入延迟(insertion delay)。
例子:
时钟源在A 点,,因此时钟从 A 点开始构建,它必须到达点 B、C、D接收器(触发器)。
所以从 A 点到 点 B 、C 、D ,时钟信号必须传播。 但是在这之间它会建立一些逻辑来平衡所有三个接收器,因为信号必须一次到达 3 个接收器 B C D ,这被称为倾斜平衡(Skew Balance)(CTS 的主要目标)。
时钟信号从 A 点到 B C D 所花费的时间称为插入延迟。您可以参考 LATENCY 概念以获取更深入的信息。
44、在VLSI Physical Design中,我们为什么不在CTS之前布线?
- 一旦您的设计处于所有数据和时钟逻辑网络都已正确平衡和综合的阶段,就应该进行布线。 铺设实际的金属线需要将所有设计对象(单元)放置在合法位置。 placement后阶段是我们达到这一点的时候。 但这并不意味着您的设计已准备好进行布线,您应该在placement后考虑其他high fanout nets和时钟网络信号。 在此阶段之前,时钟是理想的网络(假设可以驱动任意数量的负载而无需任何buffer)。
- 在逻辑综合期间,我们不会平衡 HFN 和时钟网络,因此单个时钟端口可能会驱动数千个触发器(即使在placement之后也有虚拟布线)。 CTS 是将这种加载合成为平衡树的阶段,以对所有接收器(触发器)具有最小偏差和延迟。
- 在您完成时钟的逻辑综合之前,您不得布线任何东西。完成 CTS 后,您就可以开始先布线设计时钟,然后再布线数据信号。 让我知道是否需要任何声明(clarifications)。
45、在VLSI里什么是 path group ,为什么要用它?
顾名思义,它是一组路径。
路径分组的原因是为了指导synthesis engine的工作。
例如 让我们假设您从单个路径组中的所有路径开始。
在这种情况下,synthesis engine将花费大部分时间优化最坏情况violators的逻辑。 一旦满足时间要求,就会转移到下一个最坏情况的violators,依此类推。
现在查看您可能已经确定的初始timing report。
一些需要架构更改的路径(例如,级联的加法器/乘法器将被流水线逻辑替换),因此您不希望synthesis engine花费太多时间来优化此逻辑。 使其成为具有较低优先级的单独路径组。
因为所有努力都花在了高violation Paths上,没有优化低violation Paths。 制作这两组的单独路径组。
46、在 VLSI 中为 I/O 逻辑路径设置单独的路径组有什么好处?
- 路径组在进行综合和 PnR 的工具中形成了优化功能的基础。现在,更多实际的路径组(realistic path groups)使工具更容易在所有方面进行优化。
- 现在大多数时候我们的 I/O 约束是budgeted ,不可能是实际的。 此外,从时钟域的角度来看,它们可能并不干净。 因此,如果它们与内部路径保持在同一组中,它们可能会影响 qor。 此外,该工具在最关键的路径上工作,并尝试优化到低于称为关键范围的特定范围。 如果 I0 路径是最关键的路径,那么工具可能无法在内部路径上工作,因此是次优设计。
47、在修timing时,我怎样在VLSI design中找到 false path ?
false path是 STA 中非常常用的术语。 是指在芯片正常工作的情况下激发时,在有限的时间内永远不需要被捕获,因此不需要对时序进行优化的时序路径。 在正常情况下,从触发器发出的信号必须在一个时钟周期内被另一个触发器捕获。
但是,在某些情况下,来自发送触发器的信号何时到达接收触发器并不重要。 导致这种情况的时序路径被标记为false path,并且优化工具未针对时序进行优化。
48、时钟门控路径上,是什么让满足时序非常具有挑战性?是什么使它比常规的setup/hold flop to flop时序路径更重要?
- 在构建时钟树时,我们尝试平衡所有的触发器。 这使得时钟门 (clock gate, CG) 在早期时钟树中,通过它本身的延迟 , 驱动一堆触发器。 这使得对于时钟门控锁存时钟周期减去延迟,得到满足setup的可用时间,从而使其更紧密地满足。
- 现在如果时钟门的fanout超过它的驱动能力,就会出现一个更大的小树(或者可能是2 个并行buffers),使得Clock 更早到达时钟门,从而使满足setup更加困难。
49、静态 IR drop和动态 IR drop分析有什么区别?
静态 IR 压降是电压降,当恒定电流通过具有不同电阻的电力网络时。当电路处于稳定状态时,会发生这种 IR 压降。
动态 IR 压降是由于cell data的高切换导致高电流消耗电力网络时的压降。 由于减少了静电,你应该增加电网的宽度,或者必须设计一个稳健的电网,以减少动态 IR 压降,降低触发率或将去电容单元放置在高开关单元附近。
50、静态IR drop分析需要什么?
IR drop 是来自电网的金属线在到达standard cells的 VDD 引脚之前的电压降。 由于 IR 压降,可能会因 VDD 值的变化而出现时序问题。
51-60题
51、 什么是 GDSII file?
GDS(Graphic Data Stream)是calma公司在1971年和GDS II在1978年开发的文件。
它是一种二进制文件格式,以分层格式(hierarchical format)表示layout data。
有labels、shapes、图层信息等2D和3D布局几何数据等数据。
然后将该文件提供给使用该文件根据文件中提供的参数蚀刻芯片的制造厂。
52、什么是与 VLSI 物理设计相关的 SDF 文件?
SDF 代表标准延迟格式(Standard delay format)。它提供了后端 VLSI 设计流程中广泛使用的时序数据的信息。
SDF 提供有关信息:
- 路径延迟
- 互连延迟(Interconnect delays)
- 时序约束
- 影响延迟的技术参数
- Cell delays
SDF 文件还用于门级仿真中延迟的反向注释(back annotation),以模拟精确的 Si 行为。
53、在VLSI中,什么是DEF文件?
设计交换文件(Design Exchange File)是一个行业标准文件,用于以 ASCII 格式表示 IC 的逻辑和连接性。
它通常定义芯片尺寸(die size)、连接性(connectivity)、引脚布局(pin placement )和电源域(power domain)信息。
54、解释金属可编程ECO 单元的类型 ( metal programmable ECO cells)?
可编程 ECO (programmable ECO cells)单元有 2 种类型:
- ECO 填充单元(ECO filler)
- 功能性 ECO 单元(functional ECO cells)
ECO 填充单元:基于称为 Front-end-of-line (FOBL) 的基础层构建的,FEOL 是注入层、扩散层和多晶硅层(implant, diffusion, and poly layers)。 这允许使用后端层(back-end-of-line layers)执行任何functional ECO。
功能可编程 ECO 单元:包括各种组合和时序单元,通过使用filler cells的宽度倍数实现多种驱动强度。 他们的单元具有与 ECO 填充单元相同的 FEOL 结构(same FEOL footprint)。
唯一的区别:功能性 ECO 将使用ECO filler FEOL layout ,并具有与多晶硅层(poly-layers)和扩散层以及内部连接的金属层的接触连接,以构建功能性栅极。
55、什么是 +ve unateness, -ve unateness & non-unate?
+ve unateness:如果输出信号方向与输入信号方向相同或输出信号不变,则用+ve unate表示一个时序弧(timing arc)【示例 - AND,OR】
-ve Unateness:如果输出信号方向与输入信号方向相反或输出信号不变,则称一个时序弧为-ve unate【例子:NOR,NAND, Inverter】
Non-Unate:在none unate时序弧中,输出转换不能仅根据输入的变化方向来确定,还取决于其他输入的状态。【示例:异或XOR】
56、我们能得到0 skew有什么问题吗?
如果skew是 0,那么所有的 flops将会在同一时间触发。所以功耗会更多的。
57、如果在capture clock pin上插入inverter,对时序有什么影响?
插入 inverter之前,这里有完整的时钟周期可用于Setup。
插入 inverter之后,对于setup的时序计算变成了半周期路径。
并且因此 setup timing 将会非常关键(critical)。但是我们没有看到任何hold timing问题,因为capture clock 早到了半个周期(例如,在-ve边沿),而且launch clock在capture clock之后到达(例如在+ve 边沿)。Hold path将额外增加半个周期,因此变得不那么重要。
如果一个电路设计中同时存在正时钟沿触发和负时钟沿触发的触发器,那么在这种电路中需要进行半周期的检查。
例子: 在launch clock pin上插入inverter
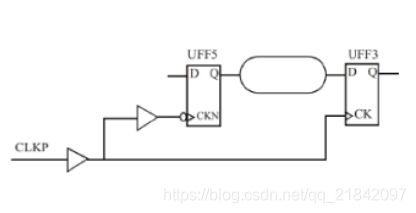
对其进行建立时间检查,那么其检查的时钟沿如下图:

58、 clock skew 和 clock latency之间的区别?
Clock skew :是时钟在不同的时间到达时钟元素(clocked elements例如触发器)。
clock latency:是到达时钟输入引脚的时钟,它是从那里生成的。 从该引脚仅将时钟提供给不同的触发器。
59、什么是 Pad limited design 和 core limited design?处理这两个的方法有什么不同吗?
- Pad limited design:
pad 面积限制了die的大小。IO pads的数量可能更大。 如果die area是一个约束,我们可以选择交错的IO Pads(staggered IO Pads)。
- Core limited design:
core面积限制了die的大小。IO pads的数量可能会更少。 在这些设计中,可以使用在线 IO(in line IOs)
60、我们怎么样决定 chip core area?

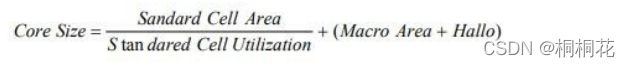
Die Size = Core Size + IO to Core Clearance + Area of Pad (Including IO Pitch Area) + Area of Bond longest Pad
芯片尺寸 = 内核尺寸 + IO 到 Core间隙 + Pad面积(包括 IO 间距面积)+Pad最长焊盘面积
IO 到 Core间隙(IO to Core Clearance):
是从 Core边界到 I/O Pad内侧的空间(设计边界)61-70题
61、 初始floorplan时如何得出利用率(utilization factor)和纵横比(aspect ratio)的值?
**利用率(Utilization Percentages)**
假设标准单元占据 70% 的基础层(Base Layers ),剩余的 30% 用于布线。 如果宏的面积大于利用率,可以相应增加利用率。

Blockages,macros,和 pads 组合在有效利用率(effective Utilization)的分母中。
有效利用定义(effective utilization):
是所有标准单元都放置在blockage区域之外。 这包括buffers,这些buffers(出于计算利用率的目的)被假定放置在non-buffer blockage区域之外。
最佳纵横比(Best Aspect Ratio):
- 考虑一个五层设计,其中第 1、3、5 层是水平的,第 2 和 4 层是垂直的。 通常,第 1 层被标准单元几何结构占据,无法用于布线。通常,Metal layer 2通过vias连接到metal layer 1 引脚。 这些vias往往会阻碍metal layer 2 上约 20% 的潜在垂直布线。如果所有层上的布线间距相同,则水平层和垂直层之间的比率约为 2:1.8。 这意味着可用的垂直布线资源少于水平布线资源,这决定了芯片纵横比 宽大于高。
- 使用横向与纵向布线源的比例,最佳纵横比为1.11; 因此,芯片长宽比是矩形而不是正方形,并且宽比高:

- 接下来,考虑一个四层设计。 metal layer 1 不可用于布线,metal layer 2 被连接layer 1和layer 2 的vias阻挡 20%。Layer 3水平且完全可用,layer 4 垂直且完全可用。 对于这种情况,垂直布线资源比水平资源多 80%。 因此,水平与垂直布线资源的比例为0.56,该芯片的垂直尺寸大于其水平尺寸。 纵横比 = W/H = 1/1.8 = 0.56
62、什么是 HALO? 和 blockage有什么区别?
可以为hard macros, black boxes, 或 committed partitions指定Block halos 。
当你向 block添加一个halo 时, 它会成为 blocks 属性的一部分。如果你移动 block, halo也会随之移动。可以为设计的任何部分指定blockages 。 如果我们移动一个 block, blockage 就不会。
63、在设计中使用的利用率是多少?
没有硬性规定,即使保持以下值,也可以在没有太多congestion的情况下收敛设计。
- Floor Plan - 70 %
- Placement - 75 %
- CTS - 80 %
- CTS - 85 %
- 在 GDSII 生成期间 - 100 %
64、 standard cells 和IO cells之间的区别是什么?IR工作电压有什么不同吗? 如果是这样,为什么?
- 标准单元(Std Cells)是逻辑单元。 但是 IO 单元在核心和外部世界之间相互作用。IO 单元包含一些保护电路,如短路、过压。
- Core工作电压和 IO 工作电压之间会有差异。 这取决于使用的技术库。 对于 130 nm 通用库,Core电压为 1.2B,IO 电压为 2.5/3.3V。
65、同时切换输出文件( simultaneous switching output (SSO) file)的重要性是什么?
- SSO:
“Simultaneously Switching Outputs”的缩写,表示一定数量的 I/O buffers 同时以相同的方向切换(H !L,HZ !L 或 L !H,LZ !H)。
由于较大的 di/dt 值和power/ground cells上的键合线(bonding wire)的寄生电感,这种同时切换会在power/ground线上产生噪声(noise )。
- SSN:
同时切换output buffers产生的噪声。“Simultaneously Switching noise”
它将改变power/ground节点的电压电平,即所谓的“接地反弹效应(Ground Bounce Effect)”。
通过将一个稳定的输出保持在低“0”或高“1”,同时设备的所有其他输出同时切换,在设备output上测试这种效果。发生在稳定输出节点的噪声称为“静态输出切换(Quiet Output Switching (QOS)“。如果将输入低电压定义为 Vil,则“Vil”的 QOS 被认为是系统可以承受的最大噪声。
- DI:
应用单个ground cell 时,指定 I/O 单元的例化(copies)同时从高电平切换到低电平,而不会使静态输出“0”上的电压高于“Vil”。 我们以“Vil”的QOS作为定义DI的标准,因为“1”比“0”具有更大的噪声容限。
例如,在LVTTL specification中,“Vih”(2.0V) 到 VD33(3.3V) 的margin在typical corner处为 1.3V,高于“Vil”(0.8V) 到ground (0V)的margin。
DF:“Drive Factor(驱动因子)”。是指定output buffer对power/ground rail上 SSN 的贡献量。
output buffer的 DF 值与 dI/dt 成正比,dI/dt 是output buffer上电流的导数。
我们可以得到 DF 为: DF = 1 /DI
66、是否有从前端收到任何checklist,而且这个checklist与在floor plan阶段需要处理任何nets的切换活动(switching activity )相关?
是的。macro的切换活动(Switching activities )将在checklist中提供;它包含每个macro可用的在不同频率下的功耗
67、什么是 power trunk?
电源主干(Power trunk)是连接 IO pad 和 Core ring 的金属片。
68、 怎样处理chip中的 热点(hot spot)?
增加 power straps的数量或增加 power strap的width ,会帮助减小因为电压降导致的热点(hot spot),并将电压降保持在 10% 以下。
69、什么是 功率门控(power gating)?
功率门控(Power gating)是一种功率降低技术。这有助于关闭芯片的特定区域以防止使用电源。
70、 宏电源环( macro power ring)是必要的还是可选的?
对于 hierarchical设计,宏电源环是必要的。 对于 flat设计,宏电源环是可选的。
71-80题
71、如果你同时有 IR drop和 congestion问题,怎么去修?
- 把 macros分散开
- 把 standard cells分散开
- 增加 strap 宽度
- 增加 straps数量
- 合理使用blockage
72、增加 power line width和提供更多的 straps 是唯一解决IR drop的方法吗?
- 把 macros分散开
- 把standard cells分散开
- 使用适当的 blockage
73、什么是 tie-high cells和 tie-low cells,在哪里使用它们?
tie cell:电压钳位单元
tie cell作用:
1、保护cell免受 ESD 影响。单元输入引脚将连接到 TIEH/TIEL,而不是连接到 PG。 如果它们直接连接到 PG,如果有电源波动,cell就会损坏。
2、某些信号端口,固定的逻辑电平上。
数字电路中某些信号端口,或闲置信号端口需要钳位在固定的逻辑电平上,电压钳位单元按逻辑功能要求把这些钳位信号通过tie high与VDD相连,通过tie low与VSS相连,使其维持在固定的电位上。
3、隔离普通信号
tie cell还起到隔离普通信号的的作用(VDD,VSS),在做LVS分析或者形式验证时不致引起逻辑混乱。
tie cell结构:
M1连接至高电位,栅极和源极连接在一起,mos管工作在饱和区。起到有源电阻的作用,使A点的电位为高电平。M2工作在线性区。
M1和M2共同组成Tie-Low 。M3和M4共同组成 Tie-high 。
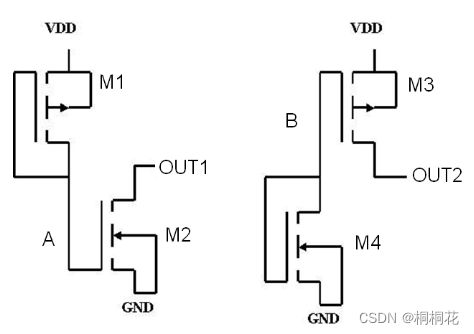
Tie-high cells、 Tie-Low cells 将晶体管的栅极连接到电源或接地。
如果栅极连接到电源/接地,则晶体管可能会由于电源或接地而开启/关闭。
foundry 厂的建议是为了达到这个目的,使用 tie cells。 这些cells是 standard-cell library的一部分。 需要Vdd的cell,来连接到Tie high(所以tie high是一个供电单元(power supply cell))。 而想要 Vss 的cell将自身连接到 Tie-low。
74、SOCE和Astro Tool Design中使用了哪些 placement 优化方法?
- PreplaceOpt
- Inplace Opt
- Post Place opt.
- Incremental Opt
- Timing Driven
- Congestion Driven
75、什么是 扫描链重排(Scan chain reordering)?它怎么样影响 物理设计(Physical Design)?
将属于芯片同一区域的cells 组合在一起,以允许仅在同一区域的cells 之间进行扫描连接( scan connections)称为扫描聚类(scan Clustering)。聚类(Clustering )还允许消除congestion程度和timing violations。
scan cell ordering的类型
- Cluster based scan cell order(基于簇的扫描单元顺序)
- power - driven scan cell order(功率驱动扫描单元顺序)
- Power optimized routing constrained scan cell order( 功率优化布线约束扫描单元顺序 )
Power driven scan cell order(功率驱动扫描单元顺序)
- 确定扫描单元的链接,,以便在移位操作(shifting operations)期间最小化扫描链中的切换率(toggling rate )。
- 识别扫描链的扫描单元的输入和输出,来限制扫描操作期间转换的传播。
- 如果扫描链长度减小了,这会增加走线能力( wire ability)或减小 芯片裸片面积 ,同时,通过减小和寄存器引脚共用扫描链的电容负载效应,提高信号速度。
- 扫描合成后,将所有扫描单元连接在一起可能会导致 PAR 期间的 routing congestion 。这会导致面积开销(area overhead )和时序收敛问题。
- 扫描链优化 - 寻找连接扫描元件的新顺序(order)的任务,以使扫描链的线长最小化 。
76、 scan chains中,如果一些flip flops是 +ve 边沿触发的,而其余的flip flops 是 -ve 边沿触发的,它的行为如何?
- 对于同时具有正负时钟触发器的设计, 扫描插入工具(scan insertion tool) 将始终对扫描链进行布线,以使负时钟触发器位于扫描链中的正边沿触发器之前。 这避免了锁定闩锁(lockup latch)的需要。
- 对于相同的时钟域,negedge flop 将始终将刚刚捕获的数据捕获到时钟 posedge 的 posedge flop 中。
- 对于多个时钟域,这完全取决于时钟树的平衡方式。 如果时钟域完全异步,ATPG 必须屏蔽接收触发器。
77、扫描链重新排序(scan chain reordering)是什么意思?
答案1:
基于时序和congestion,该工具以最佳方式放置标准单元。 在这样做的同时,如果扫描链被分离,它可以打破链排序(这是由像 Synopsys 的 DFT 编译器这样的扫描插入工具完成的)并且可以重新排序以优化它.. .. 它保持链中的触发器数量 。
答案2:
在布局过程中,优化可能会使扫描链因congestion而难以布线。 因此,该工具将重新排序链以减少congestion。 这有时会增加链中的hold time问题。 为了克服这些buffers,可能必须将其插入扫描路径。 它可能无法准确地保持扫描链长度。 它不能交换来自不同时钟域的单元。
78、什么是JTAG?
答案1:
JTAG 是“Joint Test Action Group”的首字母缩写词。这也称为标准测试访问端口和边界扫描架构的 IEEE 1149.1 标准。这被用作 DFT 技术之一。
答案2:
JTAG(Joint Test Action Group)边界扫描是一种测试IC及其互连的方法。这使用了内置在芯片中的移位寄存器,因此可以将输入移入并移出结果输出。 JTAG 需要四个 I/O 引脚,称为时钟、输入数据、输出数据和状态机模式控制。
JTAG 的用途扩展到嵌入式微控制器的调试软件。这消除了对成本更高的在线仿真器的需求。 JTAG 还用于将配置比特流下载到 FPGA。
JTAG 单元也称为边界扫描单元,是放置在 I/O单元内部的小电路。目的是通过边界扫描链使数据能够传入/传出 I/O。这些扫描链的接口称为 TAP(Test Access Port测试访问端口),扫描链和 TAP 的操作由实现 JTAG 的芯片内部的 JTAG 控制器控制。
79、什么是 CTS?
时钟树合成(Clock tree synthesis)是一个平衡时钟偏差(clock skew)和最小化插入延迟以满足时序、功率要求和其他约束的过程。
时钟树综合提供以下特性来实现时序收敛(timing closure):
- Global skew clock tree synthesis(全局偏斜时钟树综合)
- Local skew clock tree synthesis( 局部偏斜时钟树综合)
- Real clock useful skew clock tree synthesis(真实时钟的有用的偏斜时钟树综合)
- Ideal clock useful skew clock tree synthesis(理想时钟有用的偏斜时钟树综合)
- Interlock delay balance(联锁延迟平衡)
- Splitting a clock net to replicate the clock gating cells(拆分时钟网络以复制时钟门控单元)
- Clock tree optimization(时钟树优化)
- High-fanout net synthesis(高扇出网络合成)
- Concurrent multiple corners (worst-case and best-case) clock tree synthesis(并发多角(最坏情况和最好情况)时钟树合成)
- Concurrent multiple clocks with domain overlap clock tree synthesis(并发多时钟与域重叠时钟树合成)

80、 与时钟树相关的 SDC 约束是什么?
如果加载的SDC 文件中没有create_clock 语句,CTS 将不会运行。 确保您的 SDC 文件中至少有一个 create_clock。
如果您在物理上不存在且仅存在于分层网表中的管脚上定义 create_clock,则 CTS 将无法运行。
最好同时定义set_clock_transition、set_clock_latency 和set_clock_uncertainty
时钟树综合有以下时钟树约束:
- Maximum transition delay
- Maximum load capacitance
- Maximum fanout
- Maximum buffer level
81-90题
81、在CTS期间,Buffer(逻辑)层数是如何确定的?
- 把 macros分散开
- 把 standard cells分散开
- 增加 strap 宽度
- 增加 straps数量
- 合理使用blockage
82、buffer和inverter哪个好? 如果是这样,为什么?
- Inverters,由于 Inverters的转换时间更短。它减少了 VDD 和 VSS rail 之间的电流,从而降低了功耗。 最好将两者与所有驱动强度一起使用以获得良好的skew和insertion delay。
- 在时钟树中使用inverters的另一个好处是可以减少占空比失真。 单元库的延迟模型(delay models)通常以三种不同的操作条件或corners为特征:worst, typical, 和 best。 但是,还有一些其他效果没有在这些corners建模。 您可能会遇到由 PLL 引入的时钟抖动(clock jitter )、PFET 或 NFET 掺杂的差异以及制造过程的其他已知物理效应。
83、在做CTS时,设计中使用了哪些 buffer 和 inverters ?
时钟树合成(Clock tree synthesis )在时钟树构造中使用buffers 或inverters。 如果在准备的库(library preparation)中定义了布尔函数,则该工具会识别buffers 和 inverters。
默认情况下,Clock tree synthesis将clock trees 与库中可用的所有buffers和 inverters合成。 没有必要在Buffers/Inverters中明确指定所有这些。
84、你将如何为门控时钟( Gated Clocks)构建时钟树?
从历史上看,为任何驱动时钟门控元件(drives clock gating elements)和时钟叶(clock leaves)的网络(net)构建了单独的树。 两棵树在net根处分叉。 这通常会导致过多的插入延迟,并使时钟树更容易因片上变化 (on-chip variation(OCV)) 而出现故障。
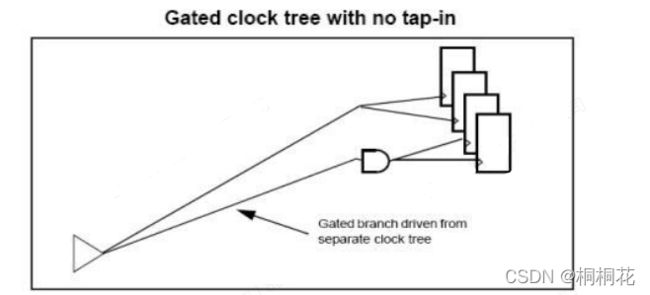
默认情况下,时钟树合成器尝试将门控分支(gated branches)接入时钟树的较低点,与非门控分支(non-gated branches)共享更多时钟树拓扑(clock tree topology)。 它尝试在主树中较早地插入负偏移分支点(negative offset branch points )。
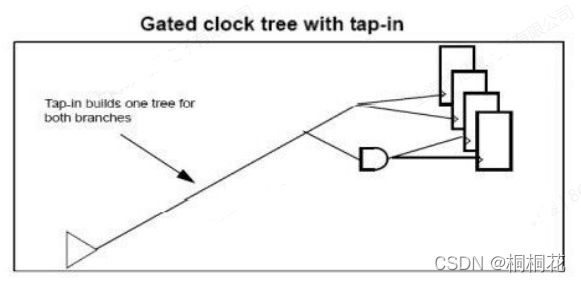
在许多情况下,这会导致插入更少的buffers以及更低的时钟插入延迟(clock insertion delays)。 在门控和非门控分支之间共享时钟树拓扑通常还可以减少local OCV对时序的影响。 如果插入的buffers过多或时钟树插入延迟过大,则应禁用时钟分接功能(clock tap-in feature)。
85、解释时钟树选项(Clock Tree Options)以构建更好的时钟树?
有五种特殊的clock options可用于解决这种情况。它们极大地扩展了您控制时钟构建的能力。
Clock phase(时钟相位):
1. clock phase是与源时钟(source clock)特定边沿相关的 timer event。
2.每个时钟域由两个时钟相位创建:
- The rising edge 上升沿
- The falling edge 下降沿
- 时钟相位以timing clock命名,R 或F 表示时钟的上升或下降相位。
- 这些相位通过电路传播到endpoints,因此时钟引脚上的事件可以追溯到定义的时钟驱动的事件。
- 由于工具能够通过电路传播多个时钟,因此任何时钟引脚都可以有两个或多个时钟相位与之关联。
- 例如,如果 CLKA 和 CLKB 连接到 2:1 MUK 的 i0 和 il 输入,则该 MUX 扇出中的所有时钟引脚都有四个与之关联的时钟相位 - CLKA:R, CLKA:F,CLKB :R 和 CLKB:F。(这假设您允许传播多个时钟相位)。
skew phase(偏移相位):
- skew phase是 clock phases的集合。
- 每个 clock phase都放在同名的 skew phase中。
- . 定义时钟时,也会自动创建skew phases。它们的创建名称与创建的clock phases相同。
Skew group(偏移组)
- Clock tree skew balancing是在每个skew group 的基础上完成的。
- skew group是 clock phase的细分。
- 正常情况下,一个clock phase的所有管脚都在group 0,作为一个group平衡。.
- 如果您创建了一组标记为group 1 的引脚,例如 :
- 然后包含这些管脚的skew phase将被分成两个skew groups:一组包含用户指定的组,另一组包含“正常(normal)”clock pins。
- 如果我们想隔离某些clock pins 组而不用default group平衡它们,此功能很有用。我们现在可以定义多组引脚,并且独立地平衡它们 。
Skew anchor or Sink Point
- skew anchor 是控制下游时钟树的 clock endpoint 。
- 例如,一个作为 2 分频时钟发生器的寄存器有一个clock input pin,它是一个 skew anchor,因为时钟到达该时钟引脚的时间会影响生成域(generated domain )中从寄存器 Q 引脚开始的所有时钟的到达时间。
Skew offset
- skew 偏移(offset) 一个浮点数,用来描述当将多个不同周期的时钟或同一时钟不同相位的不同边沿放入同一个偏斜相位时,存在一定的相位关系。
- 当您想与同一组中的另一个clock phase进行比较时,可以使用skew offset 来调整特定clock phase的到达时间。
86、skew group 与 clock phase 和 skew phase有什么关系?
A skew group 是一组被声明为一个group的clock pins 。默认情况下,所有时钟引脚都放置在group 0中。因此每个skew phase包含一个group。
例如,如果用户创建了一组标有数字 1的管脚,那么包含这些管脚的skew phase将分为两个skew groups:
- The “normal” clock pins
- The user-specified group.
这对于隔离具有特殊情况,并且您不希望与default group平衡的时钟管脚组很有用。
Skew optimization是在插入basic clock后发生的skew-group基础上执行的
87、为什么要减小 Clock Skew?
- 减少 clock skew不仅是性能问题,也是制造问题。
- 基于扫描的测试是目前最流行的在结构上测试芯片制造缺陷的方法,它需要最小skew以允许扫描矢量的无错误移动以检测电路中的卡住和延迟故障。
- best-case PVT Corner的Hold failures在这些电路中很常见,因为在一个触发器的输出和扫描链上下一个触发器的扫描输入之间通常没有逻辑门(logic gates)。
- 在这种情况下管理和减少clock skew差通常可以解决这些hold failures。
88、 做 CTS 前要做哪些检查?
- 分层管脚(Hierarchical pins)不应定义为时钟源( clock source)。
- 生成时钟应有有效的主时钟源,生成时钟在以下情况下没有有效的主时钟源:
create_generated_clock 中指定的主时钟( master clock)不存在。
create_generated_clock 中指定的主时钟不驱动生成时钟的源引脚。
生成时钟的源管脚由多个时钟驱动,有些主时钟没有用create_generated_clock 指定。- 无接收器(sinks)的时钟(主时钟或生成时钟)
- 循环时钟(Looping clock)
- 级联时钟(Cascaded clock),在其扇出中具有未合成的时钟树
- Multiple-clocks-per-register propagation 未使能,但设计包含重叠时钟 时钟树异常不应被忽略。
- output pin上定义的 Stop pin或float pin是一个问题。
89、你将如何合成clock tree?
- 单时钟(Single clock)- 正常综合与优化Single clock-normal synthesis and optimization
- 多时钟(Multiple Clocks)-分别合成每个时钟
- 多时钟域交叉合成(Multiple clocks with domain Crossing)- 每个时钟独立,平衡skew。
90、这个项目有多少个时钟?
- 由你的项目决定
- 更多时钟更具挑战性!
91-100题
91、你是如何处理所有这些 clocks?
Multiple clocks(多个时钟) →分别单独合成 →平衡 skew→ 优化 the clock tree
时钟是来自单独的外部资源还是 PLL?
- 如果它来自不同的时钟源(clock sources) (即异步( Asynchronous) 来自不同的 pads 或pins) 那么平衡这些时钟源之间的 skew 就变得具有挑战性。
- 如果是来自 PLL(即同步 Synchronous),那么 skew 平衡比较容易。
92、为什么要在时钟树中使用buffer?
为了平衡 skew (例如, flop 到 flop delay)
93、当你有48 MHz 和500 MHz 的clock design,哪个更复杂?
500 MHz;它比 48 MHz 设计更受限制(即更小的时钟周期)。
94、什么是拥塞(congestion)?
如果可用于布线的布线轨道(routing tracks)少于所需的轨道数,这叫做congestion。
95、在典型的时序分析报告中,timing violations有什么种类?
- Setup time violations - Hold time violations
- Minimum delay - Maximum delay
- Slack - External delay(外部延迟)
96、 可以使用 STA 分析基于锁存器的设计吗( latch)?
锁存器的Setup和 Hold检查 基于锁存器的设计通常使用两相非重叠时钟来控制数据路径中的连续寄存器。
在这些情况下,Timing Engine 可以使用时间借用(time borrowing)来减少对连续路径(successive paths.)的约束。
例如,考虑图 1 所示的两相基于锁存器的路径,所有三个锁存器都是电平敏感的,当 G 输入为高电平时,栅极有效(active)。 L1和L3由PH1控制,L2由PH2控制。 上升沿从锁存器输出发射数据,下降沿在锁存器输入处捕获数据。
对于此示例,请考虑setup time和 delay time为零。

图 2 显示了 Timing Engine 如何在这些锁存器之间执行setup checks。 对于从 L1 到 L2 的路径,PH1 的上升沿发射数据。 数据必须在 time=20的 PH2 关闭沿之前到达 L2。 此时序要求标记为 Setup 1。根据 L1 和 L2 之间的延迟量,数据可能在 PH2 的opening edge之前或之后到达( time=10),如时序图中的虚线箭头所示。 在 time=20 之后到达将是 timing violation。

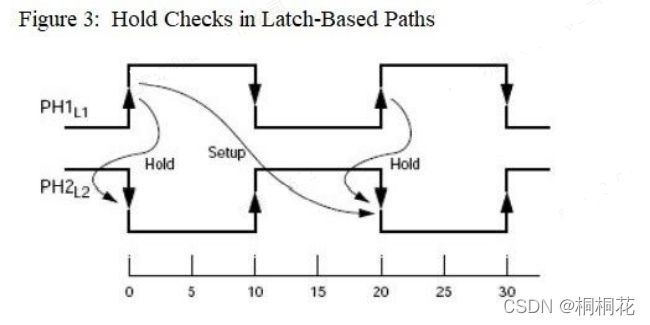
如果数据在time=10 时PH2 的开启沿之前到达L2,则从L2 到L3 的下一条路径的数据在time=10 时由PH2 的opening edge启动,就像同步触发器一样。此时序要求标记为Setup 2a。如果数据在 PH2 的打开边缘之后到达,则第一条路径(从 L1 到 L2)从第二条路径(从 L2 到 L3)借用时间。在这种情况下,第二条路径的数据发射不是发生在开始边缘,而是发生在数据到达 L2 的时间,在 PH2 的打开和关闭边缘之间的某个时间。此时序要求标记为Setup 2b。借位发生时,路径起源于 D 引脚而不是 L2 的 G 引脚。对于第一条路径(从 L1 到 L2),如果发生借位,Timing Engine 会将 setup slack 报告为零。如果数据在时间=10 的开始沿之前到达,则slack为正,如果数据在time=20 的结束沿之后到达,则slack为负(违规)。执行保持检查,Timing Engine 认为启动和捕获边缘相对于setup检查。它验证在起点发射的数据不会太快到达终点,从而确保上一个周期发射的数据被锁存而不被新数据覆盖。这在图 3 中进行了描述。
97、在不同的PVT条件下,delay是怎么变化的?
- P增加 ->delay 增加
- P减小-> 减小
- V 增加 -> delay减小
- V减小 ->delay增加
- T 增加 ->delay增加
- T 减小 ->delay 减小
98、cell delay和 net delay是什么?
Gate delay
- Gate delay = (i/p transition time,Cnet+Cpin)的函数。
- Cell delay与 Gate delay相同。
cell delay
对于任何 gate,它是在input transition的 50% 到相应的output transition的 50% 之间测量的。
Intrinsic delay(内在延迟):
Intrinsic delay是gate的内部延迟。单元的输入引脚到单元的输出引脚。
当一个接近零的转换(slew)施加到输入引脚并且输出没有看到任何负载条件时,它被定义为一个单元的输入和输出对之间的延迟。它主要是由与其晶体管相关的内部电容引起的。
这种延迟很大程度上与形成栅极gate的晶体管的尺寸有关,因为晶体管尺寸的增加会增加内部电容器。
Net Delay (或 wire delay)(线延迟)
信号首次施加到net的时间与它到达连接到该net的其他设备的时间之间的差异。
这是由于net的有限电阻和电容。 它也被称为线延迟(wire delay)。
Wire delay =fn(Rnet , Cnet+Cpin)
99、什么是 delay models,它们之间的差别是什么 ?
- Linear Delay Model (LDM)(线性延迟模型)
- Non Linear Delay Model (NLDM)(非线性延迟模型)
- Composite current source modeling (CCS)(互补电流源模型)
100、什么是 wire load mode?
Wire load model 是NLDM,用来估计net的R和C的值 。
101-110题
-
101、写出 Setup和 Hold 等式?
-

//Setup equation:
Tlaunch + Tclk-q_max + Tcombo_max 〈= Tcapute + Tclk - Tsetup
//Hold equation:
Tlaunch + Tclk-q_min + Tcombo_min >= Tcapture + Thold
102、决定触发器setup time的factors是什么?
- D- pin transition (D端口引脚的转换时间)
- clock transition(时钟转换时间)
103、 什么是 latency? 有哪些类型?
Source Latency(源延迟)
- 源延迟 在设计中定义为“时钟原点(clock origin point)到时钟定义点(clock definition point)的延迟”。
- 从时钟源(clock source)到时钟树开始的延迟(即时钟定义点)。
- 时钟信号从其理想波形原点传播到设计中的时钟定义点所花费的时间。
Network latency(网络延迟)
- 它也称为插入延迟(Insertion delay)或网络延迟(Network latency)。 它被定义为“从时钟定义点到寄存器时钟引脚的延迟”。
- 时钟信号(上升或下降)需要从时钟定义点传播到寄存器时钟引脚。
104、在 DRC 中解决了哪些违规问题?
包括以下 65 和 90nm 设计规则:
- Fat metal width spacing rule
- Fat metal extension spacing rule
- Maximum number minimum edge rule
- Metal density rule (requires a Hercules license)
- via density rule (requires a Hercules license)
- Fat metal cornect rule
- via corner spacing rule
- Minimum length rule
- via farm rule
- Enclosed via spacing rule
- Minimum enclosed spacing rule
- Fat poly contact rule
- externdMacroP inToBlockage (new parameter)
- Special end-of-line spacing rule
- Special notch rule
- U-shaped metal spacing rule
- Maximum stack level for via (for array)
- stud spacing
- Multiple fat spacing
- Enclosure
105、解决 DRC LVS 问题的 Magma 和 Calibre 有什么区别?
Magma 是一个实现工具,这个只做metal level DRC,但是 Caliber 是一个sign off工具,它在 POLY 和 Diffusion level做 DRC。
106、在LVS中解决的 violations是什么?
- Open Error
- short Error
- Device Mismatch
- Port Mismatch
- Instance Mismatch
- Net Mismatch
- Floating Nets
107、在 power analysis期间 ,如果你面临 IR drop 问题, 你怎样做去避免?
- 增加power metal layer宽度
- 选择更高的金属层。
- 把marcos或standard cells分散开
- 提供更多的straps。
108、为什么要使用与时钟相关的double spacing和multiple vias?
为什么是时钟? -- 因为与任何其他信号相比,它是一个有规律地改变其状态的信号。
如果任何其他信号快速切换,那么我们也可以使用双倍空间。
双倍间距(Double spacing) -> 宽度更大 -> 电容更小 -> 串扰更少
多个通孔(Multiple vias ) -> 电阻并联 -> 电阻较小 -> RC 延迟较小
109、 与 ASIC 后端相关的天线规则(antenna rules )意味着什么? 这些违规行为如何处理?
一般来说,修复天线(antenna )问题是相当昂贵的。 因此,在修复天线违规(antenna violations)之前,应该在很少或 0 个 DRC 违规的情况下完成布线。
天线修复可以在“Optimize Routing”之前或之后进行。
在天线修复后,运行“Optimize Routing”会第一次生成良好的布局layout。
但是,在大多数情况下,如果两个步骤都需要,首先运行“Optimize Routing”可以缩短整体周转时间。
110、什么是天线效应( Antenna effect )和天线比( antenna ratio)? 如何消除这种情况?为什么它只出现在深亚微米技术中(Deep sub-micron technology)?
天线效应(Antenna effect):
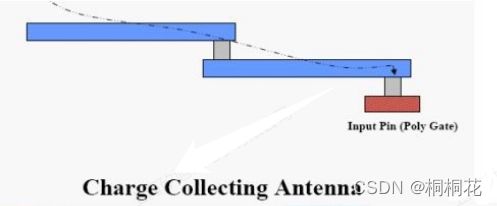
芯片制造过程中会出现天线效应(antenna effect ),导致芯片失效。在金属化过程中(当金属线跨器件铺设时),一些连接到晶体管多晶硅栅极的线可能会悬空(未连接),直到上层金属层沉积。长的悬空线互连可以充当临时电容器,在制造步骤(例如等离子蚀刻)期间收集电荷。如果悬空节点上积聚的能量突然释放,逻辑门可能会因晶体管栅极氧化层击穿而遭受永久性损坏。这被称为天线效应(Antenna Effect)。
因为在纳米技术中,晶体管栅极下方的氧化物厚度非常薄。 这个问题在 0.35u 技术中不存在。 即使这种电荷没有释放到身体。 它作为热载体留在氧化物中。那里通过改变阈值,也是一个大问题
天线消除及其效果:


天线比(Antenna Ratio):
天线比定义为导体的物理面积与天线电连接到的总栅极氧化物面积之间的比率。
较高的比率意味着对天线效应的失败倾向更大。
金属天线比 = 500
金属天线比 = 1100
为什么要铺线(Why Wire Spreading)?
制造过程中的随机颗粒缺陷可能会导致线路短路/开路,从而导致产量损失
修剪到短路/开路的此类区域称为“critical area(关键区域)”

- 提高针对随机粒子缺陷的产量
- 线展开(wire spreading)导致更均匀分布的线
-各种缺陷大小的概率分布以计算临界区域
- 分布函数因不同的制造工艺而异
-将路线(route)推离轨道(track) 1 /2间距(pitch)
- 即使减少“short”的critical area,也可能导致“open”的critical area增加
- 可以选择加宽wires,因此不会增加“open”的critical area -不会推动frozen nets

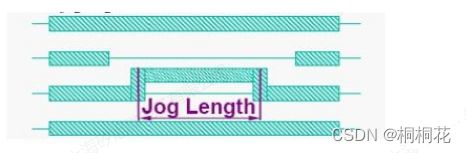
按pitch将路线(route)推离轨道(track),由此产生的微动金属( jog metal)长度可能超过最小微动长度。
111-120题
111、在修理Antenna之前,为什么不运行 wire spreading ?
- 不推荐,天线优先级排在DRC之后
- Wire spreading 【通过偏离轨道( pushing off-track)】可能不会留下足够的资源来修复 antenna
112、 wire spreading会跳层( switch layers)吗?
如果空间允许,将线推离轨道,不切跳层以允许把线推开pushing(spreading展开)
然而,在 wire spreading之后, Search & Repair 可能会导致解决DRC的最小变化
113、 wire spreading 会导致Antenna violations吗?
取决于天线长度的Antenna ratio 可能随着 wire spreading略有变化。
在大多数情况下不应引入新的Antenna violations
114、为什么要插入 填充单元(Filler Cell)?
为了更好的产率,芯片的密度需要均匀。
一些 placement sites在一些row上保持空的状态 :
- 接受两个填充单元lists :带/不带金属(with/without metal)
- 插入无金属单元 时不检查drc。您需要提供无金属单元(without metal)
- 只有在没有违反DRC的情况下才插入有金属的单元(Cells with metal)
Filler cell Insertion
- 建议按照指定的顺序(由大到小)插入单元
- 默认情况下,尊重 hard/soft placement blockages
115、为什么要插入金属填充物(Metal Fill Insertion)?
金属密度不均匀在制造过程中会导致问题。尤其是化学机械抛光 (Chemical mechanical polishing)
考虑金属填充环境的提取:
- 提取FILL view中不考虑金属填充
- 提取CELL view中未正确考虑填充
- 时序分析不考虑填充
116、你知道输入向量(input vector)控制的减少泄漏的方法吗?
栅极的漏电流也取决于其输入。 因此,找到泄漏最少的输入集(set of inputs)。 通过将此最小泄漏矢量应用于电路,可以减少电路处于待机模式(standby mode)时的泄漏电流。 这种方法被称为输入矢量控制的泄漏减少方法。
117、怎么减小动态功耗(dynamic power)?
- 通过设计良好的 RTL 来减少开关活动
- 时钟门控(Clock gating)
- 架构改进(Architectural improvements)
- 降低电源电压( supply voltage)
- 使用多个电压域-Multi vdd
118、动态功率的向量是什么?
电压和电流
119、什么是分区(Partitioning)?
分区( Partitioning )是将设计拆分为可管理部分的过程。分区的目的是将复杂的设计组件划分为可管理的部分,以便于实现。在此步骤中,定义了时序和物理实现的模型。在原型(prototyping)设计期间定义的平面布置图(floorplan)被下推到较低级别的块中,从而保留了布局(placement)、电源布线(power routing)以及与布局和布线相关的障碍。通过插入打孔缓冲器(hole-punch buffers)或修改块网表(block netlist ),也可以为在块上布线和缓冲的网络分配馈通(Feed-through)。平面物理实现不需要逻辑分区。分区拆分设计用于逻辑和物理实现。 对于分层物理实现,逻辑分区直接影响物理实现阶段。
分区是一种从逻辑设计角度管理功能复杂性的方法。
分区允许多个设计团队并行进行。
平面和分层物理实现(flat and hierarchical physical implementations )之间的桥梁是:
- Creation of timing budgets(创建时间预算 引)
- Pin optimization( 引脚优化)
- Feed-through or hole-punch buffer assignment( 馈通或打孔缓冲区分配)
- Floorplan push-down (Obstructions,Power routes)平面图下推(障碍物,电电源布线)
- 高级网表优化:时序、时钟、电源和信号完整性
120、比较与ASIC设计相关的分层和扁平化(hierarchical and flattened )设计方法?
Flat Design Advantages(扁平化设计优势)
- 扁平化设计方法确保不同层次结构之间的边界约束没有问题。
- 具备分析I/O和hard macro 到block 的paths的能力。 你有更准确的时序分析,因为不需要块建模
Disadvantages:
- 数据量大
- 运行时间长
Hierarchical Design Advantages(分层设计优势):
- 可以通过在顶层和块级并行关闭时序来节省时间
- 生成早期顶层时序分析
- 数据集更小,运行时间更快
- 块实现后可以复用。
- 如果设计使用IP block,将其插入分层模块化设计比尝试将其安装到flat design中更容易。
Disadvantages:
- 初步块表征不准确, 并且可以产生错误的顶层和块级时序违规,以及屏蔽时序违规似乎使得满足时序。
- 当模块发生变化时,需要经常更新模块时序模型。
- 由于边界建模,细节被隐藏或丢失。
121-130题
121、 哪些参数(或方面)可以区分芯片设计( Chip Design)和块级设计(Block level design)?
- 芯片设计有I/O pad; 块设计有引脚 pin。
- 芯片设计使用所有可用的金属层; 块设计可能不会使用所有金属层。
- 芯片一般呈矩形; 块可以是矩形的,直线的。
- 芯片设计需要多次封装; 块设计以宏( macro)结束。
122、StarRC需要哪些输入?
- Milkyway 或GDSII 或LEF/DEF database
- layer mapping file(图层映射文件)
- nxtgrd 文件 (包含 RC 互连信息)
- StarRC 命令文件
- StarXtract
包含的 GDSII 层必须等同于使用 GDS_LAYER_MAP_FILE 命令的 LEF 数据库层。
如果图层映射文件中未指定任何 GDSIl 图层,则不会对其进行翻译以进行提取,并且不会产生寄生参数。
123、在用于电源门控/电源开关(power gating/power switches)的 PMOS 和 NMOS 中,您更喜欢用哪一种?
Header (PMOS):
- 更高的电阻(由于更低的迁移率 mobility),因此转换速率/转换(slew rate/transition)将更大,即开关活动更慢
- 由于更高的转换率(transition rate.),短路功率更大。
- 更高的电阻,漏电会更小 - 优点
- Switch ON & Switch OFF 时间更长,因为转换率更高
Footer (NMOS):
- 由于更高的移动性和驱动强度,电阻会更低,转换率(slew rate)会更少
- 由于转换率较低,短路功率较小
- 由于电阻较低,泄漏功率会更大
- 对于相同的电流量,底部栅极(Footer gates)更小(NMOS 的迁移率是 PMOS 的两倍)
- Switch ON & Switch 0FF 需要更少的时间,因为转换率较低
- 我们更喜欢 PMOS header,因为它具有更少的泄漏(由于更高的电阻)和更慢的开关速率。 如果开关速度较快,它会尝试同时吸收巨大的冲击电流来接通模块,这将导致电源完整性问题。
- 因此,电源门控设备(Power gating devices)应该是高 VT 单元(High VT cells f),以实现较慢的开关。
- NMOS 比 PMOS 更漏电,设计对通过footer 开关耦合的虚拟接地 (VIRTUAL_vss) 上的接地噪声更敏感
- footer & header 的选择取决于开关效率、面积效率和体偏置等 3 个参数(switching efficiency, area efficiency & body bias)
- Switch Efficiency:ON和OFF状态下漏极电流的比值(Ion/Ioff)。电源开关的总漏电流主要由开关效率决定。
- 面积效率(Area efficiency):取决于产品长*宽(L*W)。 PMOS晶体管中的开关效率随着W的增加而降低,因此优选较小的W。
- 体偏置(Body Bias):在休眠晶体管(sleep transistor )上施加反向体偏置(reverse body bias )可以增加开关量效率(体偏置增加 Vt,因此漏电流 Ioff 将降低)并显着减少泄漏。 header 开关中反向体偏置的成本明显低于footer 开关。 这是因为 PMOS 的 NWELL 很容易用于标准 CMOS 工艺中的偏置连接。 而NMOS晶体管在标准CMOS工艺中没有WELL,需要更高的芯片制造成本和设计复杂度
- 结论:PMOS header在反向体偏置应用中更可取。
124、什么是电源门控( power gating),它的完整性问题(integrity issues )以及 coarse grain power gating 和 fine grain power gating之间的比较?
电源门控Power Gating
有效减少待机或睡眠模式下的泄漏功率
电源门控开销(Power Gating Overheads):
- 睡眠晶体管占用的硅面积。
- 永久和虚拟电源网络(power networks)的布线资源。
- 复杂的电源门控设计和实现过程。
电源完整性问题(Power integrity issues)
- 睡眠晶体管上的 IR drop
- 浪涌唤醒电流引起的接地反弹(Ground bounce caused by inrush wake up current)
- 唤醒延迟(Wakeup latency)
与fine grain相比,coarse grain power gating具有
- 对 PVT 变化不敏感
- 引入更少的 IR-drop 变化。
- 施加更小的面积开销
125、在时钟树综合 (CTS) 之后,会出现许多以clock gate/ICG enable pins结束的时序路径。为什么这些路径没有固定在位置上,我该如何处理它们?
在时钟树综合之后,clock gates变得至关重要,因为默认情况下,它们的时钟引脚到达时间与寄存器时钟引脚具有相同的延迟。一旦构建了时钟树,时钟门将位于时钟树的中间部分,而不是叶子leaf端。因此,时钟到达时间比时钟叶leaf引脚处的时间早,并且时序受到影响。
下面显示了一个简单的示例:
Pre-CTS,clock gates的 register pin和时钟管脚是0 ns的时钟延迟,这模拟了两者的相同到达时间。
Post-CTS,clock gates现在在树的中间,看到800ps的延迟。但是,所有寄存器都看到其时钟引脚的 1.5ns 到达时间,因为它们处于树的叶级。
从寄存器到时钟门的任何路径现在都可以看到时钟到达时间的差异,并且 pre-CTS slack 降低了 700ps (1.5ns - 800ps)。由于时钟门应该位于中间点以允许时钟树的关闭部分,因此假设时钟门的时钟引脚应该与寄存器平衡是不正确的。
这些路径可以通过以下方式解决:
首先,检查这些 ICG 在 CTS 后时钟树中的位置。它们是否靠近时钟树的根或触发器的时钟引脚会影响您处理它们的方式。
如果时钟门大约在时钟树的中间,你可以通过拆分(复制)时钟门来获得好处。拆分时钟门会创建原始驱动器的并行副本,从而产生更多时钟门驱动器,每个驱动器的负载更少。如果为 pre-CTS 完成拆分,那么我们有效地将时钟门推到时钟树的下方,增加了功率但改善了使能时序。请参阅 split_clock_net 命令。
如果时钟门位于树的开头或接近树的底部,拆分时钟门不太可能带来任何改进。在这种情况下,您应该将 pre-CTs 时钟延迟值添加到 ICG 时钟引脚,以便正确模拟 pre-CTS 延迟。使用上面的示例,您将在 place_opt 期间但在时钟树合成之前对时钟门的时钟引脚应用 -700ps 延迟。应用延迟允许您在知道实际时钟门时钟到达时间之前正确地对松弛进行建模。
如果 ICG 是单个“顶级时钟门”,由相对较小的逻辑锥馈电,您可以对馈送使能信号逻辑的触发器应用浮动引脚约束,以更早地获取它们的时钟(有用歪斜)。有时这种技术是顶级时钟门的最佳解决方案,因为它不会影响功率;拆分顶层时钟门可能会产生非常大的功率影响。
126、在 SI 分析中应该如何处理 CRPR? 即,在使用 SI analysis或crosstalk analysis进行setup分析期间,怎样把受到 crosstalk影响的cell的悲观性去除?为什么?
CRPR and Crosstalk Analysis(CRPR和串扰分析)
(1)当您使用 Prime Time SI 执行crosstalk analysis时, 由于时钟路径公共段的crosstalk引起的延迟变化可能是悲观的,但仅适用于零周期检查(zero-cycle check)。 当相同的时钟沿同时触发path的 launch和capture事件时,会发生零周期检查。 对于其他类型的path, crosstalk引起的延迟变化并不悲观。 因为 ,对于launch和capture 时钟沿,不能假设变化是相同的
(2)因此,仅当检查是零周期检查时, CRPR 算法消除了 在 launch和capture时钟路径的公共部分的 串扰引起的延迟 。 在零周期检查中,攻击者(aggressor)的开关换向同时以相同的方式影响 launch和capture信号。
(3)以下是 CRPR 可能适用于串扰引起的延迟的一些情况:
- 标准hold check
- 对一个register进行 hold check,该register是一个 Q-bar 输出连接到 D 输入的寄存器,如在 2 分频时钟电路中。
- 由于寄存器的 Q-bar 输出和 D 输入之间的寄生电容,使用串扰反馈(crosstalk feedback)进行hold check
- 在设置为零的多周期路径上进行hold check,例如,使用单个时钟边沿进行启动和捕获的电路,设计启动和捕获之间具有skew。
- 某些setup check涉及透明锁存器
(4)与时钟路径公共部分的串扰相关的hold analysis和setup analysis之间存在一个重要区别。
对于hold analysis,
launch& capture时钟边沿通常是相同的边沿。 通过公共时钟部分的时钟边沿不能对启动时钟路径和捕获时钟路径产生不同的串扰贡献。因此,worst-case hold analysis消除了公共时钟路径的串扰贡献。
对于setup analysis,
它将在不同的时钟边沿上完成,时钟边沿将在一个时钟周期之后出现。 所以在公共时钟路径上,来自 launch& capture paths的串扰贡献是不同的。 所以我们不应该从公共时钟路径中消除串扰贡献。
127、什么是不确定性(Uncertainty)?为什么我们在 cts 前和 cts 后对setup和hold有不同的uncertainty?
Uncertainty:
指定了一个时钟沿可以出现的窗口。
在物理设计中,不确定性将用于对几个因素进行建模:
- 抖动 jitter (时钟沿与其理想位置的偏差)
- 额外的余量 Extra margins
- 偏斜skew(在 pre-cts)
对于setup 和 hold指定不同的uncertainty。
由于保持检查是针对同一时钟沿执行的,时钟沿的任何偏差(抖动)都会以相同的方式影响launch flop和 capture flop。
所以对于hold uncertainty来说,不需要对 jitter 建模,这就是为什么我们总是看到hold uncertainty的值低于setup uncertainty的值的原因。
在 CTS 之前,uncertainty也会对实现时钟树(后 CTS)后的预期偏差skew进行建模。因此,在 CTS 后阶段,我们将减少uncertainty值,因为有了实际的skew值。
setup Uncertainty:
Pre-CtS = Jitter + Skew + Extra setup margin
Cts = Jitter + Extra setup marginHold Uncertainty:
Pre-CtS = Skew + Extra hold margin
cts = Extra hold margin128 、为什么我们对clock cells和data cells有不同的降额系数(de-rating factors)? 这是什么原因?
(1)时钟单元(clock cells)的开关活动远远超过数据单元(data cells),因此它会导致更多的 PVT 变化。 因此,由于OCV引起的clock cells延迟变化可能会导致比data path更多的violations。 这就是为什么clock cells比data cells降额更多。
(2)OCV 影响通常在时钟路径上更明显,因为在芯片中,时钟路径更长,
(3)时钟单元具有二阶效应,因此降额更多。 数据单元具有一阶效应,因此降额较少。
129、在CTS中使用的buffers和Inverters,有什么优缺点?建立 时钟树时,更喜欢使用哪一个?
Inverter:更小的面积和可以驱动更远的距离。 但开关更多。 适合脉冲宽度和脉冲周期维护。
换句话说:当您比较相同的驱动强度单元时,Inverter的当前驱动能力大于buffer,即Inverter比buffer快。
因此在相同的净长度下,它需要的Inverter数量少于buffer数量。
因此,使用Inverter插入延迟(Insertion Delay)会更好。 即间接降低OCV(OCV与插入延迟成比例)对时序的影响。
由于基于inverter的 CTS开关较多,可能会增加 OCV? (有人说)。保持 50% 的占空比和inverter具有再生特性(regenerative property)
inverter比buffer有更好的降噪效果 。
130、TIE cells的用途是什么?TIE 的内部结构是什么?
tie cell:电压钳位单元。进行esd保护
(1)在较低的技术节点,晶体管栅氧化层很薄,对电源电压波动很敏感。 如果晶体管栅极直接连接到 PG 网络,晶体管栅极氧化物可能会因电源电压波动而损坏。 为了克服这个问题,TIE cell被引入了 b/w PG 和transistor gates。
(2)因此,引入TIE cell 是为了防止 ESD 问题。
(3)只需更换一层metal layer,即可轻松将这些 TIE cells从 0 转换为 1,反之亦然。
(4)假设您只需要使用一个金属掩模(metal mask )进行 ECO,以便将其中一个组合逻辑门的输入上的 0 更改为 1,但您只有一个可用的tie down cell。 如果这种tie down cell 的设计使得您可以通过仅使用一个金属层轻松地将其功能从 0 更改为 1,那么对于局部 ECO 来说,这将是一个具有成本效益的更改。

131-140题
131、如果我们使用ocv derating factors,为什么我们在 post-cts 阶段之后,使用clock uncertainties(setup uncertainty和hold uncertainty)?
(1)Jitter 不是 OCV 的一部分,这个 Jitter 问题是由于 PLL 噪声造成的。所以我们应该将不确定性(uncertainties )和降额因子(ocv derating factors)做当分开的。
(2)OCV derating是基于路径的余量(margin)。它将仅考虑 PVT 变化 OCV → 工艺变化,
即由于掩模变化、CMP 变化和蚀刻引起的晶体管沟道长度变化/栅极氧化物厚度变化。
即如果两个具有相同驱动强度library cell的instance,位于layout中不同位置,那么由于这些变化,单元延迟(cell delay)可能会有所不同(由于工艺变化导致的单元延迟变化)
(3) 温度变化:结温(junction temperature)和时钟单元(clock cells)开关活动和高密度区域可能会产生更高的温度。所以单元延迟会有所不同
(4)电压变化:对于某些cell,电压会因 IR drop 问题而降低。这可能是因为这些region密度更高。 IR drop margin 取决于您计划在您的设计中实现的IR drop。如果您满足 3% 的 IR drop,那么您可以灵活地降低OCV derating的flat margin。
(5)如果您在设计中没有使用 ENDCAP 单元,那么您需要在derating factors中填充/添加更多的margin。 因为每个标准库单元(standard library cell )的特征都假设,它位于芯片的中间(如果一个cell位于中间,则该cell上的stress会更小,因此它可以正常运行。 如果它位于最后,则stress会更大,因此cell可能无法按预期运行)。 像这样有很多因素。 代工厂(foundry)和公司决定减少或增加持flat margin。[这里stress我认为是电压应力]
132、如果base gets frozen,你如何解决setup timing violation?
- 看看那条path的nets有没有绕路(detours)。 然后删除net,重新route。
- 在更高metal layer 上的布线,或layer提升
- 修复data path串扰(crosstalk )问题
- 修复clock path串扰(crosstalk )问题
- 使用buffer代替fortune /spare cells
- 逻辑重构(Logic restructuring)。例如, 重新安排AND gate的时序关键网络(timing critical nets)远离其ground 和OR gate的时序关键网络,远离其power。 因此,非时序关键网络首先出现,并且不充当时序关键网络的负载。 最终延迟会减少 。
133、antenna violations的修复方法有哪些?
- 在gate附近增加antenna diodes
- 跳到到靠近栅极的更高金属层
- 如果该路径不是时序关键,则在输入gate附近插入buffer
- 将antenna violation的net 连接到buffer 的输入引脚,输出引脚float或接dummy load
134、如果通过添加buffer来拆分net,net delay会减少吗?
假设net为L个单位长度或截面,用distributed RC model表示每个net section
假设单位长度的电阻为 Rp,单位长度的电容为 Cp
Net Total resistance Rt = L*Rp
Total Capacitance = L* Cp
Total net delay Dt = Rt * Ct = (L^2) * Rp *Cp如果插入buffer,
net length=L/2 ,net delay = (L^2) * Rp *Cp/4net delay的推导方式为:
R 与(L/A= L/Wt)成正比,
C 与(A/D= tL/S)成正比;
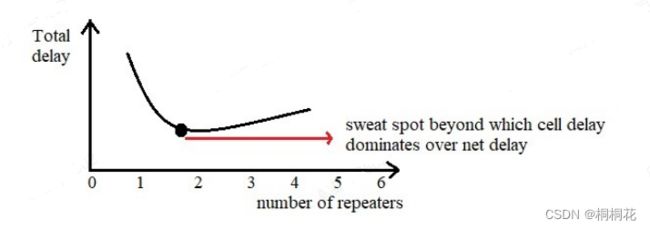
RC 与(L ^2)成正比中继器(Repeaters)的概念和我在“插Inserting the Buffer”(上点)中讨论的一样。只是我试图以不同的方式解释这一点,但总体概念是相同的。
长距离routing 意味着,由于一系列RC延迟导致的巨大RC负载,如图所示。
一个不错的选择是使用中继器,将线路分成几段。为什么这个解决方案在延迟方面可以更好?因为与 RC 延迟相比,门延迟非常小。
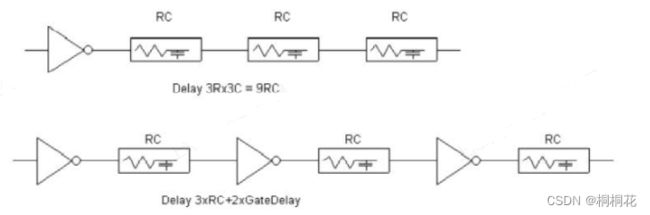
在单逆变器驱动的互连情况下,传播延迟变为
Tdelay= tgate+nR.nC= tgate + (n^2)RC= tgate + 9RC如果插入两个中继器,传播延迟变为:
Tdelay=tgate(逆变器延迟)+ 2tgate(中继器延迟)+3RC = 3tgate + 3RC这样你就可以看到在电路中没有中继器的情况下,RC 延迟是怎样的。
因此,如果gate delay远小于RC delay,中继器可以提高开关速度性能,但代价是功耗更高。 随着您不断添加repeaters以改善长度为 L 的固定net上的transition,那么总延迟将随着网络中添加中继器的增加而减少。
在某一时刻,gate delay大于 RC delay,即门延迟优于网络延迟。 如果您在该point之外添加repeaters,则总体total delay开始增加。 所以你不应该在那个sweat spot之外添加buffers。 这就是我们计算特定buffers可以驱动多少net 长度的方法。
135、为什么我们不能使用 PMOS 作为footer和 NMOS 作为header?
如果我们使用 NMOS 作为header(Drain D 连接到 VDD,Source S 连接到负载 CL &.SHUTDOWN 块),那么 NMOS 将产生 VDD-VT 的输出值。
这意味着我们降低了连接到 NMOS 源极的“shut down” 模块的电源电压。 这种电压降低会影响shut down block中cells的性能 。
如果我们使用 PMO 作为footer(Source S 连接到 SHUTDOWN 块,Drain D 连接到地),那么 PMOS 将在source产生 VT 的输出值。 这意味着shut down block不是纯粹连接到地面。
这种安排使输出电压衰减。
136、 NLDM vs CCS?
CCS timing model:
(1)RC-009 warning信息描述的问题的解决方案。
当驱动器模型的驱动电阻(drive resistance)远小于网络对地阻抗(network impedance to ground)时,会出现此warning。
(2)更好的处理Miller Effect,动态IR drop,多电压分析。
(3)随着更小纳米技术的出现, 已经开发了对 cell 行为建模的 CCS 时序方法,来解决深亚微米过程的影响。
(4)驱动模型(driver model)采用时变电流源(time-varying current source)。
这种驱动模型的优点是 ,它能够准确处理高阻抗网络和其他非线性行为。
(5)CCS timing receiver model使用两个不同的电容值而不是单个集总电容。
第一个电容用作输入延迟阈值之前的负载。 当输入波形达到这个阈值时,负载被动态调整到第二个电容值。
该模型在存在米勒效应(Miller Effect)的情况下提供了更好的loading effects近似值
(6)CCS 时序模型通过使用时变(time-varying)和电压相关的电流源为cell输出drivers建模提供了额外的精度。
通过指定不同场景下receiver引脚电容和output charging currents的详细模型来提供时序信息
(7)CCS模型 没有long tail effect。
NLDM:
(1)NLDM driver model使用与resistor((戴维宁模型))串联的linear voltage ramp。
resistor有助于使voltage ramp平滑,使生成的驱动器波形类似于驱动 RC 网络的实际驱动器的曲率。
(2) 当驱动电阻远小于网络对地阻抗时,平滑效果会降低,可能会降低 RC 延迟计算的精度。
发生这种情况时,Prime Time 会调整驱动器电阻以提高准确性并发出 RC-009 警告。
(3)NLDM receiver model是一个电容,代表receiver输入的负载电容。
不同的电容值可以应用于不同的条件,例如上升和下降转换或最小和最大时序分析。
然而,单个电容值适用于给定的时序检查,它不支持米勒效应的精确建模。
(4)NLDM timing models表示通过基于输出负载电容和输入转换时间的时序弧的延迟。
实际上,cell output看到的负载由电容和互连电阻组成。
互连电阻成为问题 ,因为 NLDM 方法假设输出负载是纯电容性的
(5) NLDM有 long tail effect
(6)带有NDLM库的常规STA不能考虑米勒效应和long tail effect。
(7) 时序分析结果可以比Spice结果更乐观。
137、如何修复route之后的database(即将流片)上特定区域的 DRC? 考虑两种情况,例如,该区域的cell Density较高的情况和该区域的cell Density较低的情况。
Cell Density 比较高:
1、收集该区域的所有网络,找出+ve slack margin超过150ps的非关键时序网络(non-critical timing nets)。
然后 ,通过关闭 SI driven和timing driven选项(删除这些nets &删除 global route &使用 route eco 命令 route_zrt_eco 重新对这些路径重新布线。) ,对那些非关键网络递增地re-route。(eco route)
因此,该工具会将那些非关键网络从该区域引开。
2、从该区域的非关键时序路径中收集所有buffers/inverters,并缩小它们的尺寸。 这样在该区域获得一些routing tracks 或space,
收集该区域中的所有vias,并将所有multi-cut vias转换为single cut vias。
3、基于 DRC cleaning,对area处理
4、从关键时序路径(critical timing paths)中收集所有nets ,并且在block中使用的最高metal layer上方的metal layer上,递增re-route。
5、我们可以盲目的应用cell padding或者module padding。 但它可能会影响时序,因为它会扰乱所有cells ,包括critical cells。
6、最后,在不影响该区域foundry给出的IR drop限制的情况下,尝试通过移除一些vias来修整PG straps。但这不太可取,因为该区域的单元密度非常高。
7、在属于非关键时序路径地跨越drc area 的nets上添加guide buffers,并将这些guided buffers放置到远离 drc 区域。
Cell Density比较低:
(假设因为某些feed through或从上到下交叉的nets, DRC 较高。反之亦然)*
我们不能在这里应用所有上述技术,因为cell density非常小。
我们在这里唯一能做的就是修整PG。 即使修整PG,也不会因为 cell 数量较少而影响 IR drop limit。
138、在pre-cts阶段,如何解决特定区域(核心区域)的congestion问题?
- 更改max density 值 & 重新运行placement 步骤,查看congestion是否得到控制
- 如果density(cell density和pin density)更大,则对那些cell 应用cell padding 或module padding 或partial density 。
- 查看是否有floor plan 问题,导致module分开
- 由于某些floor plan问题,检查该区域是否有buffer/inverter chain进入
139、有 10 个macros,它们应该放在 5x2(10 个macros应该放在 2 列中)数组中。
您将留下多少垂直通道(vertical channel)用于对所有macro pins布线?
假设每个macro的 10 个metal layer设计有 200 个pins,并且macro被阻塞到metal 4 (block level 使用的最大层为 M8)
macro pins总数为
10x200=2000可用的vertical metal layers为
M3、M5 和 M7。在 28nm 技术节点,
M1-M6 的track间距为 0.05um,
M7-M8 的track间距为 0.1um(2x),
M9-M10的track间距为 0.8um(8x) 假设需要的最小space是H,那么需要的总space是
H/0.05 + H/0.05 + H/0.1 = 2000 (for M3,M5,M7)
H = 2000/50 = 40um这意味着我们必须从底部到顶部为这些macros 留出 40um的空间。
如果你喜欢的话,底部会浪费很多 routing tracks,因为底部的2个宏只有400个IO pins。
因此,如果您想有效地利用该空间,请不要在底侧保留 40um,仅保持与 VDD-VSS 间距相等的距离。
IO pins会随着你往top side 增加,你需要在top side 40um 空间,(在顶部Routing track 需要2000 IO pins )。
这意味着,宏应该以V-SHAPE方式放置,以有效利用区域和routing track。
140、在存在串扰的情况下,您会移除 setup半周期时序路径 & hold半周期时序路径上的 CRPR 吗?(即当您在capture clock pin上插入inverter时)?
否。
在capture clock path & launch clock path计算期间,来自公共时钟路径的Crosstalk 贡献不同。
因为launch flops& capture flops的时钟沿不同。 即launch edge & capture edges由半个周期分开,用于setup & hold计算。 所以我们不应该从setup & hold的时序分析中删除这些串扰值
141-150题
141、如何改善 insertion delay?
(1)通过使用适当的时钟驱动强度单元(clock drive strength cells)。
即不是低驱动强度单元(low drive strength cell),倾向使用clock inverter,而不是clock buffers。
(2)对时钟网络(clock nets)使用双倍宽度(double width)
因为它将电阻降低一半(R'=R/2),并且接地电容略有增加。
因此,总体而言,由于电阻的主要影响,插入延迟(insertion delay)将得到改善
(3)将clock port 放置在任何core边缘。
这样,这应该与所有corner或多或少等距。
(4)将第一级时钟门控元件放置在设计的中心,并从那里构建时钟树。
(5)稍微放宽max transition限制和skew限制以获得insertion delay。
(6)multi-point CTS。
即将整个设计区域分成 4 个相等的部分,然后构建。
从主时钟端口到这 4 个点的 Hclock 树,然后在每个区域添加 1 个大clock buffer。
- 从主时钟端口断开所有 CP pins
- 收集每个区域的所有register的CP pins,
- 将CP pins连接回位于该区域的大clock buffer的输出
- 然后从那个大clock buffer的输出引脚构建regular clock tree。
(7)时钟网格(clock mesh)
但布线资源和功耗会更多。
(8)在进入 CTS 步骤之前,congestion应该是最小的。
否则congestion可能会clock nets 绕路,因此可能需要大量cells来修复 DRV。
所以它会降低插入延迟。
(9)floor plan问题,例如某些macro channels中缺少密度。
由于某些registers可能放置在这些区域中。
因此,CTS engine将尝试通过添加大量clock cells来平衡该寄存器与所有其他leaf pins
(10)fish-bone CTS
(11)仅对 CTS 使用具有适当驱动强度的单个buffer/inverter。
这样在 MCM 设计中会很好,因为不同corners的 OCV 效应将被最小化。
这种技术不会改善插入延迟。 但由于 OCV 影响较小,间接有助于减少violations次数。
(只使用一个buffer/inverter过于乐观。
CTS 必须在 spine n 根部驱动不同量的负载。 必须使用大量cell 来处理。 否则,如果使用low drive,即使不需要,它也会在某些地方添加high drive cell 。 将添加太多cells。)
142、如何解决天线违规问题(Antenna violations)? 解决这些问题的可能方法是什么 ?
Antenna Ratio = 连接到栅极的金属面积 /栅极面积。
如果antenna ratio率超过每个金属层上指定的值,则会发生Antenna violation。
解决方法:
(1)层跳到更高的金属层(金属面积会减少)
(2)在栅极附近增加天线二极管(栅极面积会增加)
天线效应的影响
当与晶体管栅极接触的金属线被等离子蚀刻时,它可以充电到足以消除薄栅极氧化物的电压。 这被称为等离子体引起的栅极氧化损伤,或简称为天线效应。
它会增加栅极泄漏,改变阈值电压,并降低晶体管的预期寿命。 更长的电线会积聚更多的电荷,更有可能损坏栅极。
在高温等离子蚀刻过程中,源漏扩散形成的二极管可以传导大量电流。 这些二极管会在栅极氧化层损坏之前从导线中释放电荷。
143、你能用buffer修复antenna violation吗?
是的,可以用buffer修复,
即用buffer替换antenna diode(output float和连接到栅极的input pin)。
这将增加gate 面积。 这样antenna violation就会下降
144、分别有 3 个具有不同电压域的模块(假设 V1、v2、V3)。
V1 是“always on”, V2是“ON/OFF(ONO Block)”,V3是“shut down”
V1放在顶部,V2放在中间 , V3 在底部。
如果信号从 V3 通过 V2到 V1 ,需要多少个隔离单元? 反之亦然。
来自 V1-V3 的Signal :
当信号从V1传输到 v2 时,不需要隔离单元,
因为 V1 始终处于开启状态。
当 V2 关闭且 V3 开启时:V2 和 V3之间,需要 1 个隔离单元
当 V2 开启且 v3 开启时:V2 和 V3之间,无隔离单元
来自 V3 -V1 的Signal:
当信号从 V3 传递到 V1 时,需要 2 个隔离单元。
一个 V1和V2之间
一个在 V2 和 V3 之间。
为了更好地理解:下图描述了 AON 和 ON0 的电源域交叉场景

电源域交叉场景。
图的案例是:
1. AON驱动ONO(无需隔离)
2.ONO驱动ONO(无需隔离)
3. ONO驱动AON(需要隔离)
4.ON0块ONO馈通
5. ONO 块中的 AON 馈通
145、是如何使用conformal LEC 生成functional ECO 的?
通过比较functional eco实现的synthesized netlist与具有conformal的routed netlist,生成functional EC0 patch。
146、如果我在 pre-cts 阶段增加clock slew/transition会发生什么?
(1)clock slew/transition用于在 pre-cts 阶段,预先对触发器的ck到 q 的延迟和library setup check建模,而不是等到 CTS 步骤。
(2) pre-cts 阶段,对clock pins的 clock transition constraint 无非是对library setup margin建模,这在 cts 之后可以看到。
(3)触发器上的Library setup check将增加(Library setup check将根据clock pin 上的slew 和data pin上的 slew而变化),因此,数据路径的time period较少,工具会更加努力地修复timing violations。
147、如果您有多个时钟通过 MUX,会发生什么? 你如何建立时钟树?
- 为,通过 MUX 的D0 pin从其functional clock port 到所有register pins的functional clock ,建立"clock tree"。
- 在 MUX/Z 管脚上设置set_dont_touch_network,然后为 test_clock 构建 CTS。
- 然后,在Test clock上修复"DRC only" clock tree,Test clock 连接到 MUX 的 D1 引脚,即仅连接到 D1 引脚。
148、为什么在clock tree阶段关注clock skew而不是时序收敛?
即,如果在 CTS 期间满足timing要求,为什么需要注意skew ?
为什么不能专注于timing而不是在 CTS 阶段满足skew。
减少clock skew不仅是性能问题,也是制造问题。
基于扫描的测试需要最小的skew,以允许scan vectors 的无差错移动,以检测电路中的stuck-at faults和delay faults。(基于扫描的测试,这是目前最流行的结构测试芯片制造缺陷的方法,)
在这些电路中,best-case PVT Corner下的Hold failures很常见。 因为在一个触发器的输出和scan chain下一个触发器的scan input之间通常没有逻辑门。
在这种情况下, 处理和减少clock skew通常可以解决这些hold failures
149、有 3 个flops。
在 pre-cts 阶段,从 A 到 B 的setup time为 +200ps,B 到 C 为 -50ps,
在CTS阶段,给出的skew constraints 为 50ps。
(即 A 到 B 是 50ps skew,B 到 C 是 +50ps skew)
您将如何解决它?
将在任一侧borrow timing ,即将 B flop的时钟引脚提前 50ps
150、post route阶段,如果我不得不稍微过度约束设计,你更喜欢调整clock frequency 还是更喜欢调整clock uncertainty?
调整clock frequency总是更好。 因为它改变/影响crosstalk arrival windows的计算。
这样 EDA 工具就可以看到这些crosstalks 并适当地修复它,而不会过度修复设计和,而且硅片上的成功率总是更高。
而如果你改变uncertainty,它不会影响crosstalk arrival windows的计算。
即,您没有看到由于crosstalk windows而导致timing path violations的增加。 但是您确实会看到由于uncertainty增加而导致的大量timing path violations,您需要盲目地修复它们 ,而且这就像过度修复设计。 硅片上的设计有可能会失败 ,并且 可能无法达到目标性能。
因为当我们尝试以targeted/changed frequency运行设计时,我们可能会看到由于crosstalk导致的cell delay changes/noise bumps
151-160题
151、如果调整clock uncertainty,是否会影响 SI?
不。 clock uncertainty设置不影响 crosstalk arrival windows的计算。
152、如果调整clock frequency(时钟周期更小),是否影响SI?
是的。
clock frequency的变化会影响串扰到达窗口的计算 。 如果稳定信号在时钟边缘附近通过,则crosstalk noise会增加。
结果,交叉影响cells 的延迟将改变,并出现更多的 setup/hold violations。
如果在route 阶段有机会进行优化,工具将努力修复这些timing violations。
153、EDA 中最常用的顶级命令是什么?
placeOpt
clockOpt
routeOpt
ecoRoute
ecoPlace
. . .154、如何获取EDA中的选项/默认设置?
get*Mode,
//其中*表示 ECO,trailRoute,detailRoute155、如何获得macro的 11x & ury
set llx [lindex [lindex [dbGet [dbGet -p top.instance.name $macro].box] 0] 0]
set lly [lindex [lindex [dbGet [dbGet -p top.instance.name $macro].box] 0] 1]156、b/w regular OCV 和 AOCV 有什么区别? 您认为常规 OCV derating factors 是否比 AOCV 更悲观?
是的,当我们有较深的逻辑电平深度时(deep logic level depth),Regular OCV 更悲观。
在Regular OCV中,无论逻辑级别如何,都对所有单元应用flat derating,因此我们将看到大量的timing violations。
AOCV(advanced OCV):随着逻辑深度的增加,降额系数会降低,如cell 离分叉点的距离越远,降额系数就会增加。
具有更多gates的更长path,往往具有更少的总变化。 因为从门到门的random variations往往会相互抵消。 因此, AOCV 将较高的降额值应用于较短的时钟路径,而将较低的降额值应用于较长的时钟路径。
AOCV 根据路径逻辑深度的度量和特定路径经过的物理距离来确定降额系数。 具有更多门的较长路径往往具有较少的总变化,因为从门到门的随机变化往往会相互抵消。 跨越芯片的较大物理距离的路径往往具有较大的系统变化。 AOCV 没有传统的 OCV 分析那么悲观,传统的 OCV 分析依赖于不考虑路径特定指标的恒定降额因素。
157、AOCV 中的“基于位置的降额(location based Derating)”是什么意思? 您决定cell降额数量的参考是什么?
OCV 降额(OCV derating)将随着单元从时钟分叉点位置的增加而增加
158、为什么我们不能先对设计进行布线,然后再进行时钟树综合? 有什么理由吗?
一般走线是基于时序驱动的,只有在时钟建立后才有可能。
如果设计先布线,那么对于时钟树,您将无法获得适当的布线资源,因此时钟布线会绕道并会影响insertion delay& skew。
159、如果将 CMOS 反相器中的 PMOS 和 NMOS 互换会发生什么?
PMOS : ON ( v(gs)< -V(tp)) OFF ( V(gs) > -V(tp))
NMOS: ON ( v(gs) > v(tn)) OFF ( v(gs)< V(tp))
假设 V(tn)=V(tp)=V(t)
PMOS&NMOS交换位置后,连接如下:
NMOS:漏极 D 连接到 Vdd,源极S 连接到负载 CL
PMOS:漏极 D 连接到地, 源极 S 连接到负载 CL
- 输出电压将通过负载 CL(假设 CL 上的初始电压为 0v)
- Vin = Vdd:
- 对于 MMOS:
- V(gs) = Vdd - 0 = Vdd ,大于 V(t)。 因此 NMOS 开启。 [即 v(gs)> v(t) ]
- 它开始将负载电容器 CL 充电至 Vdd。
- 当 CL 两端的输出电压 V0 达到 Vdd - V(t) [即 VO = Vdd - V(t)] 时,
- 然后 NMOS 的栅极和源极电压差将下降到 V(t)[即 Vgs = Vg - Vs = Vdd -(Vdd-v(t)) = Vt) ]。
- 然后 MMOS 将关闭。
- 所以当 Vin = Vdd 时, 输出VO=Vdd-V(t)。 输出随 V(t) 衰减。
- 对于 PMOS:
- V(gs)= Vg - Vs = Vdd - 0 = Vdd ,大于 -V(t) ,因此 PMOS 关闭。
- Vin = 0 :
- 对于 NMOS:
- v(gs)= Vg - Vs = 0 - ( Vdd - V(t)) = - (Vdd - v(t)) , 所以 NMOS 关闭
- 对于 PMOS:
- v(gs) = vg - Vs = 0 - ( Vdd - v(t)) = - (Vdd - V(t) ,小于 -V(t)即v(gs)< -V (t) 条件满足。 所以 PMO 已开启。
- 因此负载电容 CL 两端的电压将开始通过 PMOS 向 0v 放电,当负载 CL 两端的电压达到 V(t) 时它将停止放电。
- 所以此时 Vgs = Vg - Vs = 0 -v(t) = -Vt。 所以此时 PMOS 将关闭。
- 因此,当 Vin 为 0v 时,负载 CL 上的输出电压将为 v(t)。
- **总结:**
- 当 Vin = vdd VO = Vdd - V(t)
- 当 Vin = 0v VO = V(t)
- 当 Vin = vdd VO = Vdd - V(t)
- 所以这个电路不作为纯缓冲器,而是作为部分缓冲器。
- 160、如果hold的多周期(Multi cycle)值为2, 那么您在哪个edge验证/检查hold violation? 这个hold check 是否取决于频率?
-
默认情况下,将根据capture edge检查setup MCP(MCP多周期)
-
默认情况下,将根据launch edge 检查hold MCP。
-
对edges的时序检查将根据 MCP 定义中指定的 -start 或 -end 选项而改变。
-
create_clock -name CLKM -period 10 [get_ports CLKM] set_multicycle_path 3 -setup -from [get_pins UFFO/Q]-to [get_pins UFF1/D] //setup多周期约束指定 从 UFFO/CK 到 UFF1/D 的路径,最多可能需要三个时钟周期才能完成setup检查。 set_multicycle_path 2 -hold -from lget_pins UFFO/Q]-to lget_pins UFF1/D]指定hold multi cycle为2,以获得与单周期setup情况相同的hold check行为。
-
-
-
-
这是因为在没有这种hold multi cycle规范的情况下,default hold check是在setup capture edge之前的active edge上完成的,这不是我们想要的。
-
我们需要在默认hold check边沿之前移动hold 检查两个周期,因此指定了两个保持多周期 。
-
多周期保持上表示的周期数指定从其默认保持检查沿(这是设置捕获沿之前的一个有效沿)向后移动的时钟周期数。
-
由于该路径的设置多周期为 3,因此其默认保持检查位于捕获沿之前的活动沿。
-
-
-
在大多数设计中,如果最大路径(或设置)需要 N 个时钟周期,则实现最小路径约束大于(N-1)个时钟周期是不可行的。
-
通过指定两个周期的多周期保持,保持检查边沿移回启动边沿(在 0ns) 因此,在大多数设计中,指定为 N(周期)的多周期设置应伴随指定为 N-1(周期)的多周期保持约束。
-
当指定了 N 的多周期设置但缺少相应的 N-1 多周期保持时会发生什么?
-
在这种情况下,保持检查在设置捕获沿之前的一个周期执行。 对于保持检查,捕获边沿移回0ns,发射边沿也在0ns,那么保持根本不依赖于频率。
-
-
171-180题
-
171、什么是timing window并解释它?
-
STA 从aggressor nets的timing windows中获取此信息。
-
在时序分析过程中,获得了nets的最早和最晚切换时间。这些时间表示网络可以在一个时钟周期内切换的timing windows。 switching windows(上升和下降)提供了有关aggressor nets是否可以一起切换的必要信息。
-
Timing window: 特定网络的最新和最早到达时间差是该网络的时间窗口。
-
Timing window是一个window,在这个window内信号可以在时钟周期内的任何时间发生变化。
-
172、为什么不固定动态峰值功率,为什么只固定 RMS 功率?
-
-
-
-
RMS ( Root Mean Square)功率额定值:RMS 功率的含义定义为均方根,这是一种表示直流电压或交流电压的统计方式。它不使用峰值,而是使用平均值,因此您可以更好地了解其真实性能和功率处理能力。
-
在直流电路中
-
功率始终计算为产生与直流功率相同的加热效果的 RMS 功率
-
汲取的电流始终为 rms 电流 .... I=sqrt(Power/Resistance)
-
173、如何修复 LVS 中的text short ? 我们可以用text short 流片吗? 什么是text short ?
-
text short:具有两个不同标签(label)的相同net shape或pin shape或substrate layer。
-
(理想情况下没有风险,因为它只是技术上的label short )。
-
但我不会流片,它可以隐藏两个具有相同标签的不同nets,或者确实是一个open的情况。
-
174、什么是+ve unateness,-ve unateness & non-unate? 你在 library看到Unateness吗?我们在 DFF 中看到unateness吗? 你会在 DFF 中看到什么样的 Unateness?
-
+ve Unateness:
-
如果输出信号方向与输入信号方向相同或输出信号不变,则用 +ve unate 表示一个时序弧。
-
-
示例 :AND,OR
-
-ve Unateness:
-
如果输出信号方向与输入信号方向相反或输出信号不变,则称一个时序弧为-ve unate。
-
-
示例 :NOR,NAND,反相器
-
Non-Unate:
-
在 non-unate时序弧中,输出转换不能仅根据输入的变化方向来确定,还取决于其他输入的状态。
-
-
示例:XOR异或
-
因为 DFF 对时序弧 CP→Q 具有non-unateness ,因为它不仅取决于 CP 转换,还取决于 D Pin 上的转换。 见下面的例子:
-
- 所以此时 Vgs = Vg - Vs = 0 -v(t) = -Vt。 所以此时 PMOS 将关闭。
- 因此负载电容 CL 两端的电压将开始通过 PMOS 向 0v 放电,当负载 CL 两端的电压达到 V(t) 时它将停止放电。
- v(gs) = vg - Vs = 0 - ( Vdd - v(t)) = - (Vdd - V(t) ,小于 -V(t)即v(gs)< -V (t) 条件满足。 所以 PMO 已开启。
- 对于 PMOS:
- v(gs)= Vg - Vs = 0 - ( Vdd - V(t)) = - (Vdd - v(t)) , 所以 NMOS 关闭
- 然后 MMOS 将关闭。
- 然后 NMOS 的栅极和源极电压差将下降到 V(t)[即 Vgs = Vg - Vs = Vdd -(Vdd-v(t)) = Vt) ]。
- 当 CL 两端的输出电压 V0 达到 Vdd - V(t) [即 VO = Vdd - V(t)] 时,
-
pin(Q){ direction : output ; max_capacitance : 0.404; function : "IQ"; timing(){ related_pin : "CP"; timing_sense: non_unate; timing_type : rising_edge; } }175、library中的 -ve lib 值是什么?
-
library hold margin value可以是负数。
-
因此,negative hold check,意味着触发器的data pin可以在clock pin之前发生变化,并且仍然满足hold time check。
-
-
触发器的library setup margin value也可以是负数。
-
这意味着在触发器的引脚上,数据可以在clock pin之后发生变化,并且仍然满足setup time check。
-
-
setup 和 hold 都可以是负数吗?
-
不; 为了使setup check和 hold check保持一致,setup 和 hold值的总和应该是正的。
-
因此,如果setup (or hold) check 包含负值 - 相应的hold (or setup)应该足够正,以便setup加上hold 值是正数
-
对于触发器,在scan data input pins上有一个negative hold time是有帮助的。
-
这在clock skew 方面提供了灵活性,并且可以消除几乎所有buffer插入以修复scan mode中的hold violations的需要。
-
-
-
-
- 它开始将负载电容器 CL 充电至 Vdd。
- V(gs) = Vdd - 0 = Vdd ,大于 V(t)。 因此 NMOS 开启。 [即 v(gs)> v(t) ]
pin (D){
direction : input;timing ) {
related_pin : "CK";
timing_type : "hold_rising";
rise_constraint ("setuphold_template_3x3") {
index_1("0.4,0.57,0.84"); /* Data transition*/
index_2("0.4,0.57,0.84");/* Clock transition*/
values(/* 0.40.570.84*/\
/*0.4*/"-0.220,-0.339,-0.584",\
/*0.57*/"-0.247,-0.381,-0.729",\
/*0.84*/"-0.398,-0.516,-0.864");
}
}
176、什么是antenna violation 以及如何解决? 您在 28nm 技术节点看到什么样的antenna violation ? 每次掩模mask制造后,晶圆代工厂释放所有电荷时,为什么要修accumulation area/gate area?
在 28nm 技术节点有 2 种antenna violations:
(1)金属区/栅极区(metal area/gate area)
(2)累积金属面积/栅极面积(cumulative metal area/gate area)
因为蚀刻是一层又一层发生的,即使你在每个较低层之后都去除了电荷,仍然有可能小部分电荷残留或再次积累,当电荷积累在一起时会破坏栅极。因为在较低的技术节点上,栅极长度非常 最小,而且对轻微的电荷积累很敏感。
在累积面积模式下,工具考虑当前layer 上的金属段和所有下层layer 金属段。 在这种模式下,天线比计算为
天线比率 = 所有连接的金属面积 / 总栅极面积(antenna_ratio = all connected metal areas / total gate area)
177、nxtgrd 文件与 ICC TLUPlus 文件有何不同? 为什么我们不能在 ICC 中使用 nxtgrd 来匹配 RC 延迟?
nxtgrd 文件和 TLUPLus 文件都是使用 STARRC 中的 grdgenxo 实用程序从相同的 ITF 文件生成的(具有相同类型的版本)。
这两个文件都包含类似类型的 RC 互连相关信息和cap tables。但文件格式不同。
ICC extract engine (rc_extract) 可能不会采用 nxtgrd 文件中的格式
178、如果不涉及 vdd/freq,如何减少独立逆变器(standalone inverter)的短路电流?
如果输出负载电容较低且输入上升/下降时间较长,则短路电流较大。
为了减少短路功耗,输入/输出上升和下降时间应该是相同的数量级 t
PAvg(short-circuit) = 1/12[k t f (VDD- Vthn -|Vthp|)3]一般来说,短路电流与频率 f 和电压成正比。
(短路电流与频率成正比:
即短路电流通常在时钟从 0 变为 1 或 1 变为 0 时出现。
因此,如果时钟由于时钟频率而更多地切换,则短路电流将更多,反之亦然)
179、什么是die/scribe/sealer line/mask/die/corner cell?
特殊的corner cells,用于在shutdown block的corners周围,打开电源信号。
180、我们可以增加 GRC cell的大小吗?
ICC 中没有用户控制 GRC 的大小,它是由工具动态计算的,不是恒定的。
默认情况下,GRC 的宽度等于标准单元row 的高度。
181-190题
181、您采取了哪些措施来防止设计中的 Sl 问题?
Placement
- 减少设计中的congestion或做SI aware placement
- 避免出现cell 密度较高的区域
- 使用place_opt - congestion - area_recovery 命令
- 不要使用较低驱动强度的cells。它充当victim net。(受别人影响)
- 将高驱动强度cells保留在不使用列表中。 它将充当aggressor nets(影响别人)
- 通过控制设计中定义的maximum transition 约束来帮助防止串扰。 maximum transition 约束取决于技术和库。 您需要在较低的maximum transition 约束和拥塞之间找到最佳折衷。 在post route优化期间,可以放宽maximum transition约束。
- 使用 IC Compiler 工具中的maximum net length 约束,通过防止非常长的wires来最小化串扰效应。
CTS
- 为clock network应用 NDR 规则。 因此clock network对串扰效应不太敏感
- 从signal nets应用spacing b/w clock network
- 因为时钟网络通常是高频网络,所以它们通常是强攻击网络。 您可以通过用地线屏蔽时钟网络来防止串扰。
- 通过为这些gators添加一些padding,尽量避免将clock gators 放在非常近的位置。 因为,它们充当相邻signal nets的攻击者
Route
● 做 SI aware routing或crosstalk aware detail route
● Route 可以执行以下信号完整性任务
(1) 防止串扰(在global routing和track assignmen期间)
(2)在post route 优化期间修复crosstalk violations
● 轨道分配期间的串扰预防:
通过运行 set_si_options -route_xtalk_prevention true ,并在运行 route_opt 时使用 -xtalk_reduction 选项 , 启用串扰预防(Enable crosstalk prevention )。
182、您将如何确定static IR drop分析和dynamic IR drop分析的sign off要求是什么
它来自top level,通常基于soc的10-20%。
- Static IR Drop:(VDD + VSS) 的 2.5 至 3%
- Dynamic IR Drop:3 倍于static IR drop
183、我们必须在 IR drop target 中考虑timing margins 吗?
是的。 它考虑时序信息。
Redhawk 将timing window file作为输入以获得更好的结果。 您可以在 Redhawk 手册中获得更多信息。
【timing window file 包含每个引脚上的转换和负载信息】
184、什么是零位保留触发器(zero-bit retention flop)?
所有保留触发器(retention flops )都需要在其clock pin和reset pin上进行隔离。
这些隔离可以作为retention flop 的一部分来实现,也可以将一个单独的隔离单元(isolation cell)连接到CK/RST pin。
第一种实现的优点是它降低了复杂性。
第二种实现占用更少的面积,因为我们可以为多个retention flops使用一个公共isolation cell。 但它增加了实现的复杂性。
第二种方法称为零位保留触发器 (zero-bit retention flops)。
Retention cell: 保留单元,一种能够在电源关闭的情况下,能保持内部状态的特殊单元。
Retention cell是时序逻辑,有两种类型:
- retention flip-flop ;
- retention latch.
一个Retention cell是由一个普通的flip-flop(或者latch) 加上一个额外的save-latch组成。
save-latch可以在关电的时候保存状态,在重新上电的时候恢复普通flip-flop的状态。
Retention flip-flop
和普通的flip-flop的差别就是多了一个save-latch.
1. Save-latch一般是一个HVt cell, 以节省静态功耗;
2. Save-latch是由备用电源供电;
正常情况下,
Retention flip-flop和普通的flip-flop功能一样,但是会把输出锁存在Save-latch中
当电源关掉时,
由于Save-latch是由备用电源供电,Save-latch还是保持原有状态;
当RESTORE信号拉成1时,
Save-latch会把输出送给前面的flip-flop,就能立刻恢复下电时的状态了。
低功耗技术——低功耗中使用的特殊单元 - 知乎 (zhihu.com)
 Retention flip-flop
Retention flip-flop
184、一般来说,解释一下零位保持触发器(zero-bit retention flop)的实现方法?
首先,如果retention flop 的 CK/RST 引脚上有incoming Netlist 中的任何隔离单元,我们将它们移除。
在 HENS 之后,我们将最后一个buffer连接到retention flop的复位引脚,并将其转换为 iso high cell。 这将负责reset pin isolation。
在 CTS 阶段之前,我们得到所有retention flops的CK pins 的所有扇入(fan-in)。 这些将是 ICG outputs。 在这些outputs上,我们将插入一个隔离(iso low)单元。 我们在这些隔离单元的输出上添加一个 don't touch。现在我们让工具做 CTS。 在 CTS期间,该工具将根据需要克隆isolation cells。 这将负责clock isolation。
185、retention flop secondary pin 布线有哪些注意事项?
在整个设计中,在primary power stripes之间有一个secondary power stripe。
在placement期间,我们必须确保所有 RFF 都与secondary power stripes对齐。 这是为了降低RFF secondary power的电阻连接。
在 RFF 的secondary power pin上应用 route-as-signal 属性。
然后,在这些route在power nets上的信号应用 3x 宽度的 NDR 规则。这些信号将在时钟网络和信号网络之前布线。
186、destination isolation cell和source isolation cell有什么区别?
从可切换域(switchable domain)到 AON 域(AON domain)时需要隔离。
isolation cell可以放置在可切换域(源隔离source isolated)或 AON 域(目标隔离destination isolated)中。
如果它在可切换域可切换域(源隔离source isolated)中,则需要 AON 域的辅助电源。
187、 我们什么时候需要电平转换器(level shifters)?
当两个域(domains)之间存在显着(如果高于噪声容限)电压差时,需要使用电平转换器。
188、如果我们降低频率(增加时钟周期),对setup 和 hold有什么影响?
1. 它将改善全周期和半周期时序路径的setup timing。
2. 如果是全时钟周期路径(因为启动和捕获沿同时到来),它不会影响hold;但它改善了半周期路径的hold timing,因为捕获比启动时钟早半个周期。
189、hold取决于频率吗?
1. 对于全周期时序路径,hold不依赖于的频率
2. 但是hold取决于半周期时序路径的频率,因为启动和捕获边沿出现在不同的时间。
190、 您在职业生涯中解决了哪些类型的 EM violations?
1. 首先我会尝试增加金属的宽度 。 如果它很拥挤,那么我会去更高的层以获得更多的空间来增加金属的宽度。
2.如果violation出现在violation上,增加更多via。
191-200题
191、如果我在设计中随机选择一个单元,那么该单元在静态和无矢量 IR drop analysis中的功率是多少?
静态功率(Static power )适用于平均功率计算算法,并假设一切都在switching,因为功率均匀分布。
而矢量 IR 分析适用于假设切换率为 20%,那么特定单元将switch的概率也是 20%。
192、为什么 antenna violation发生在 signal net上,而不是 power net?
Power nets 没有连接到 gate。
193、您将如何修复半循环路径?
half cycle path的Hold修复轻松,Setup是半周期路径的关键。
194、 解决cross talk?的技术有哪些?
提高Layer,减少net长度,屏蔽,增强驱动,增加buffer。
195、 body biasing如何影响timing?
阈值电压 Vt 将随着体/衬底偏置电压的增加而降低。
因此,设备运行速度更快,时序得到改进,设setup timin收敛更容易。 更多的功耗。
196、在 post signoff DB(database) 上,如果我们增加频率,会发生什么?
如果我们增加频率,设计中每个时序弧的时序窗口都会改变。
结果,时序窗口的重叠可能会改变,因此可能会增加/减少设计中的串扰效应。
197、noise glitch是否总是影响的设备功能?
不,noise glitch并不总是影响功能,除非它被flop捕获。
如果时钟或触发器的set/reset pins上存在noise bump或glitch,那么它将影响设计的功能。
如果noise bump高度大于noise threshold & noise bump宽度大于fanout cells的延迟,则受害网络上的noise bump会传播到fanout cells的输出
只要这种noise bump不通过组合单元传播,就没有问题,也没有功能变化。
如果此noise bump传播,并最终到达触发器的 D 引脚,并被寄存器捕获,将改变功能。
198、timing window和设计频率之间的关系?
Timing window不过是任何timing arc上最大和最小到达时间之间的差异。
如果我们改变频率,Timing window的到达时间将会改变。
199、如果您想提高性能,您会在设计uncertainty 或 Frequency中更改哪一项?
频率Frequency。
如果你增加uncertainty, uncertainty的close timing不能保证所需的性能,因为它不会解决与noise相关的问题。
但是改变频率会改变crosstalk的arrival windows并影响时序。 因此,如果我们可以用它来close timing,我们就可以保证所需的频率。
200、您如何在不考虑架构更改的情况下提高设计中的动态功耗?
- 多位Multibit
- 时钟门控clock gating
- xor 非门控寄存器上的自门控xor self-gating on ungated registers
- 使用 SAIF 进行功率感知放置power aware placement using SAIF
- 减少插入延迟reduce insertion delay
- 不要使用巨大的不必要地不确定性值don’t use huge uncertainty values unnecessarily
- 等等
201-210题
201、什么是阈值电压? 它如何影响cell传播延迟?
阈值电压是在 CMOS 中在源极和漏极之间建立通道所需的最小电压。
单元的延迟与阈值电压成反比。
202、什么是Power aware placement?
Low-power placement试图根据可用的开关活动,缩短高活动net的长度。
Low-power placement不会进行任何优化,包括调整drivers的大小。 但是,它与调整单元大小的时序、功率、DRC 和congestion优化同时进行。
203、HVT 与 ULVT在corners下 scaling,如果路径的setup也很关键,您更愿选择哪个去修复hold?
由于驱动电压 (Vgs-Vt )的巨大变化,与 ULVT 单元相比,HVT 单元的单元延迟变化在不同PVT corner处更高。 所以我为此目的使用 ULVT。
PVT corners (针对不同的工作电压和因逆温而产生的不同温度)
204、如何修复动态电压降(Dynamic voltage drop)?
(1)添加额外的power/ground straps
通过添加额外的power/ground straps来提高电流传导性,使power grid更加密集。
(2) Cell padding:
为同时切换的cell添加cell padding,以减少power grid的峰值电流需求。
(3)缩小cell:
降低非关键时序路径中单元的驱动强度,以降低局部热点的瞬时电流需求或作为预防措施。
您可以使用 set_clock_cell_spacing 命令来扩展clock cells(与data path cells相比,clock cells具有更多的开关活动)。
这只不过是改变了非关键时序路径单元的时序窗口
(4)插入decap cells:
Decap 充当充电储备,当热点区域中同时切换电池时,可为标准单元提供电流。
然而,decaps 是泄漏的,它会增加设计中的泄漏功率。
(5)分开输出电容(Splitting output capacitance):
从power grid汲取的电流量与被驱动的输出电容成正比。
负载分流可以降低power grid的峰值电流需求。因此将解决动态 IR 压降问题。
(6)使用 MIM (Metal -Insulator - Metal) 稳定电源
205、影响Vt的因素有哪些?
(1)VDD(VDS)
随着VDS 的增加,漏极周围的耗尽区将增加。 因此沟道长度会减小。 所以阈值电压会改变或下降。
(2)衬底体电压(Substrate body voltage):
随着衬底体电压从0V开始升高,阈值会降低。
Vt = Vt(sb=0) - K [ Sqrt (Phy + Vt(sb) - sqrt(phy)].
通道长度:阈值电压变化与通道长度成正比
(3)栅氧化层厚度:
随着栅氧化层厚度的减小,阈值电压会降低。 对于较小的 Vgs 电压,如果厚度较小,将形成通道。
(4)温度:
随着温度的升高,阈值电压会降低。
Vt(T)=Vt(Tr)-K(T-Tr); Tr => 室温,其中 K 是一个因数
(5)沟道掺杂浓度:
阈值电压随着沟道掺杂的增加而降低
(6)衬底掺杂会增加VT
(假设NMOS的P型衬底掺杂会增加VT)
206、当 温度升高时 Vt 会发生什么变化? 为什么?
VT 随着温度的升高而降低。
Vt(T) = Vt(Tr) - K(T-Tr);( Tr => 室温,其中 K 是一个因子 )
207、当温度增加时,迁移率会发生什么? 为什么?
随着温度的升高,迁移率会降低,因为升高的温度会诱导更多的电荷载体,这些电荷载体会与其他电荷载体发生碰撞。 这将降低载流子的迁移率。
208、迁移率是否随着温度的升高而不断降低?
是的
209、 PMOS (holes) vs NMOs (electron)mobility?
电子迁移率总是高于空穴迁移率。 电子迁移率的速度比空穴高了 2 到 2.5 倍 。
210、cell delay取决于什么?
- Input slew,
- output load,
- input signal vector sequence,输入信号向量序列
- Multiple input switching (MIS),多输入开关
- VT,
- Mobility,
- temperature,
- channel-length,
- VDD gate oxide thickness,
211-220题
211、当 clk transition不好时,power 和 timing会发生什么?
- 动态功耗(短路功耗会增加),
- 增加时钟单元延迟。增加时钟单元延迟。会影响时序 时序取决于该单元在时钟网络中的位置)
- 影响设计性能(工作频率会下降)
- 如果capture register的 CK 引脚上的clock transition不良,则library setup & hold time会增加。 这将使setup & hold timing修复变得复杂。
212、当clk transition不好时setup 和 hold会发生什么?
我们需要在这里考虑不同的点。
Case 1
如果launch clock pin上的clock transition不良而capture register clk 上的时钟转换良好,则launch register的 clk 到 q 延迟将增加。 所以,它会减少setup window。
所以,在这种情况下,setup 会变得更糟,hold 会更好。
Case 2
如果capture clk 上的clock transition不良,而launch clock pin上的clock transition良好,那么这将增加捕capture path 延迟并恶化setup library margin。
然后,您必须根据library setup margin加上由于不良的 clock transition导致的capture path delay增加的综合效果,来判断setup 的好坏。
Case 3
如果在 clk 反相器(除了启动和捕获寄存器的 ck 引脚)上存在时钟转换,那么这里会出现不同的情况。
A
如果公共时钟路径上出现不良的clock transition,那么它会以同样的方式影响两个launch &capture paths 。 因此,它不会影响setup or hold violation。
B
如果launch clock path出现不良的clock transition,则launch path会延迟。 setup变得更糟糕了,对于hold violation更好。
C
如果在capture clock path上出现不良transition,则capture clock会延迟。 这对setup有利,对hold timing不利。
213、 为什么要在常规 CTS 上进行网格mesh划分?
更好的偏移(skew),更低的延迟,有助于实现更高的性能或频率,更好的时序收敛
214、 你会把你的clock gates放在sink或 root附近吗?
时序方面,
ICG 靠近 sinks 可以更好的解决 ICG 的使能时序问题,但是这样会导致功耗不好。
对于power效率,
将 ICG 放置在root附近可以更好地降低功耗但是在 Enable 引脚上的时序会很差 。
215、什么是电源门控(power gating)?
电源门控是一种在不执行任何操作时关闭模块的技术。 这样就可以省很多电了。
有两种类型的电源门控技术可用;
(1) header,用PMOS实现将用于断开VDD与block的连接。
(2) footer,用 NMOS 实现将用于断开 VSS 与block的连接.
216、什么是isolation cell? 您如何决定使用与门或或门来实现isolation cell?
(1)isolation cell放置在信号从可切换电源域(switchable power domain)到 AON 电源域(AON power domain)的接口处,并且两者都在相同的电压下工作。
(2)放置isolation cell的主要目的是,防止在可切换电源域关闭时,未知逻辑信号从可切换电源域传播到 AON 域。
(3)另一个原因是,如果不插入isolation cell,未知逻辑会到达 AON 域,导致亚稳态问题(逻辑电平在 0 和 1 之间),从而消耗短路功率。
(4)具有隔离控制信号(为0)的与门来自电源管理模块,用于阻止未知信号进入AON域。
(5)具有隔离控制信号(为1)的或门来自电源管理模块,用于阻止未知信号进入AON域。.
217.pre-CTS ,Clock Skew 的来源?
芯片内工艺,电压,温度 (PVT) 变化
- 具有不同通道长度的不同clock buffers
- 局部电压下降导致buffer delay增加
- 热点导致栅极和线延迟增加
- 跨芯片时钟抖动的器件失配
218、什么是抖动(Jitter )及其来源?
时钟抖动(Clock jitter )是时钟信号生成电路与理想时钟相关的时钟边沿不准确性。
时钟抖动可以看作是时钟周期或占空比的统计变化。
时钟抖动的来源:
暂时的电源变化
- 变化的活动可以在影响全局或局部clock buffers的不同周期中改变电源电压。 、
锁相环抖动
- PLL 的电源变化会影响振荡器频率
- PLL元件没有零响应时间
- PLL 倍增的参考时钟抖动
- 由于电源噪声导致反馈时钟信号出现抖动,全局时钟分布可能会增加 PLL 的抖动。
线耦合
- 改变数据可以改变不同周期的耦合
动态偏移电路
219、Clock buffer 和常规buffer之间的区别?
Clock buffers
优点:
- 由于 PMOS 和 NMO 晶体管的导通电阻相等,上升和下降转换时间相等。 (这可以通过将 PMOS 的宽度增加 2.5 倍 NMOS 的宽度来实现。)
- Clock buffer保持脉冲宽度
- Clock buffer delay 将小于常规buffer,因为常规buffer的电阻是 NMOS 电阻的 2.5 倍。 因此,常规buffer的上升时间会更长——这不是真的(请参阅下面的电子表格) clock buffer 实际上比常规buffer有更多的延迟。

缺点:
- 由于 PMOS 宽度增加,clock buffer 的面积高于常规buffer,即面积损失更大
- 由于 PMOS 的 导通电阻较低,泄漏电流更多。 因此,clock buffer的泄漏功率会更大。
220、什么是米勒效应 ( Miller Effect)?
米勒定理(Miller effect)
在 微电子学 中,反相放大电路中,
输入与输出之间的分布电容或寄生电容由于 放大器 的放大作用,其等效到输入端的 电容值 会扩大1+K倍,其中K是该级放大电路电压放大倍数。
虽然一般密勒效应指的是 电容 的放大,但是任何输入与其它高放大节之间的阻抗也能够通过密勒效应改变 放大器 的输入阻抗。
浅谈MOSFET中的米勒效应 - 知乎 (zhihu.com)

CMOS 反相器的内部物理结构 在输出漏极和输入栅极之间会有一个内部反馈电容,称为 Cgd。
根据米勒定理,Cgd 出现在输入端,乘以放大器增益 A+1(即 Cgd(A+1))。
与没有 Cgd 相比,这会降低放大器的最大工作频率。
然后如前所述,Cgd 可以极大地限制放大器的带宽。
如果将 CMOS 反相器用作逻辑门,则晶体管充当开关。
在开和关状态下,它们处于准静态状态,Cgd 的影响可以忽略不计。电容。 结果是减慢了反相器的转换速度,并且传播延迟时间增加了。
总之,Cgd的MILER效应降低了CMOS反相器的最高工作频率。
我们可以使用级联连接(公共源与公共门串联)来减少米勒效应。 级联共栅提高了输入-输出隔离(或反向传输),因为输出与输入之间没有直接耦合。 这消除了米勒效应,因此有助于提高带宽。
器件工程师可以通过减小栅极和漏极之间的重叠区域来减小该电容。 那就是在技术上最小化 Cgd。
load cell/receiver 是high drive strength cell (单级cell,例如逆变器),输出负载较轻(short net),因此输出上的快速转换,通过米勒电容强烈耦合回输入互连( 类似于串扰)并在输入信号处引起大量失真,例如延迟信号转换。
因此,即使没有外部串扰,这里的 Receiver 也充当了aggressor driver。 因此,它会影响cells的工作频率。
221-230题
221、 Pre & post-route correlation
(1)在预布线阶段(pre-route stage),默认情况下(在ICC compiler器中)使用elmore delay engin计算互连 RC 延迟,并且在布线后阶段(post-route stage),使用 Arnoldi delay engine计算互连 RC 延迟。
所以我们应该检查我们在pre-route stage使用的delay engines的类型。
为了更好地与post-route correlation,我们必须在pre-route阶段使用AWE(Asymptotic Waveform Evaluation)delay engine。
(2)在预布线阶段(pre-route stage),没有考虑耦合电容,因此在预布线阶段不存在串扰效应。 而在布线后阶段,串扰影响就出现了。 所以会有timing correlation问题。
从route stage & post-cts 优化阶段,报告同一路径的时序,并看到串扰是导致不良correlation的主要原因。
如果是这样,那么尝试减少设计的拥塞,你会看到改进的timing correlation。
(3)在 post-cts stage增加不确定性值,并进行post-cts 优化可能会提高相关性。
但这种方法也会过度优化非关键时序路径。 这就像通过优化非关键时序路径不必要地增加了面积开销
在此之前,如果您看到大量针对 post cts DB 的时序违规,在route阶段找出时序违规路径并增加不确定性值。
如果违规路径的数量很少,请查看违规原因。 使用 NDR 对所有那些时序关键网络布线,或使用更高金属层布线,可能会帮助您解决这些违规问题。
222、 Post-route & Signoff timing correlation
(1). Prime-time总是使用Arnoldi delay engine来计算互连 RC 延迟。 所以对于post-route设计,总是打开Arnoldi delay engine以获得更好的时序相关性(timing correlation)(ICC)
(2)有时在实现工具中使用的降额(derate)与signoff PT 不一致。 使用降额从 PT 和实施工具报告相同路径的时序,然后检查两个工具之间的降额一致性。 如果它们不匹配,则在实现工具中使用适当的降额来进行timing correlation。
(3)如果您通过直接比较 ICC Compiler 的时序路径与 PrimeTime 的时序路径发现不相关,请尝试通过在 ICC Compiler 中读取相同的寄生文件(parasitics file)来缩小问题范围,然后找出RC scaling factors。 使用这些新的 RC scaling factors可能会改善时序相关性。
ICC Compiler执行命令:
extract_rc
report_timingPrimeTime 执行命令:
read_parasitics
report_timing(4)报告 Signoff PT 中的所有时序变量,并将它们与实施工具中的变量进行比较。 尝试在实现工具中修改这些变量以获得更好的时序相关性。
您将在 ICC 和 PT-SI 中看到相同的变量,但我们可能在其他实现工具中看不到类似的变量,但我们可能会找到提供与 PT 中类似的功能的变量。
(5)实现工具默认使用 GBA。 这是比较悲观的做法。 而 PT 在 GBA 和 PBA 上运行。 因此,如果 PT 使用 PBA,则将其更改为 GBA。 这样你会看到更好的时序相关性。
GBA(Graph Based Analysis)(基于图形的分析 ):
单元延迟将根据通过其input pins之一的最差转换传播( slew propagation)来计算。
PBA(Path Base Analysis)(路径基础分析):
单元延迟将根据通过输入引脚的实际传播来计算
(6)
※在 ICC 中检查 IC Compiler 和 PrimeTime 工具之间的相关性,以及 ICC Compiler 和 StarRC 工具之间的相关性,包括 IC Compiler和PrimeTime工具中的时序和信号完整性相关变量、命令和SDC设置。
运行 命令:
check_signoff_correlation※ 要仅检查 IC Compiler 和 Prime Time 设置之间的相关性,请使用 命令
check_primetime_icc_consistency_settings而不是 命令
check_signoff_correlation(7)使用相同的输入数据 b/w ICC & PT,如网表,SDC,参考库,操作条件
223、 ICC Vs Extraction Correlation
(1)确保使用相同的 ITF 文件生成 TLUPlus 和 nxtgrd 文件
(TLUPlus 文件将用于ICC 和StarRC 中的 nxtgrd 文件)
(2)确保 nxtgrd 和 TLUPlus 文件都使用相同的 grdgenxo 版本生成
(3)使用 OPERATING_TEMPERATURE 将工作温度信息传递给 StarRC。
ICC Compiler 会自动从操作条件中获取此信息。
(4)确保向 StarRC 提供管脚电容信息。
IC Compiler 从 . db 文件获得管脚电容信息
StarRC 从 LM view中存在的 db 文件获得管脚电容信息。
如果 LM views 不存在,则通过 StarRC 中的 SKIP_CELL_PORT_PROP_FILE 指定引脚电容信息。
(5)关闭 vIRtual shield extraction
set_extraction_options -vIRtual_shield_extraction false(6)确保 IC Compiler 和 StarRC 之间的金属填充设置一致。
建议在 ICC 和 StarRC 中执行不使用金属填充的 correlation。
224、使用CMOS画 NAND/ NOR gate
与非门NAND:


或非门NOR


225、为什么传输门(Transmission gate )中的 PMOS 和 NMOS 总是相同的面积?
CMOS传输门:
(1)CMOS 传输门可以通过 NMO 和 PMOS 晶体管的并联组合构成,具有互补的门信号。
(2)与 NMOS 传输门相比,CMOS 传输门的主要优点是允许输入信号在没有阈值电压衰减的情况下传输到输出。
使用互补对,而不是单个NMOS或PMOS器件来实现传输门的优点是门延迟时间几乎与CMOS传输门的输入变量的电压电平无关。
(3)在某些情况下,您会发现 beta 比率等于 1 的原因是,当传输门打开时,PMO 和 NMOS 都打开并并联。
尽管只有 PMO 擅长通过 'l' 而 NMOS 擅长通过 '0' ,但它们确实通过相反的逻辑电平较弱。
所以,加起来平均阻力比只有一个Moson。 因此,您并不需要像 CMO 逆变器那样的 beta=2,但像 1.5 或 1 这样的值就足够了。
使用晶体管作为驱动电路和负载电路之间的开关被称为传输门,因为开关可以将信息从一个电路传输到另一个电路。
施加到晶体管的偏压决定了哪个端子充当漏极,哪个端子充当源极。
**NMOS传输门:**
- NMOS 栅极连接到可变 Vg
- 一个端子连接到负载 CL
- 一个端子将连接到输入电压 Vin。
- 输出将通过负载 CL 获取。
当 Vin = Vdd
(1)Vg= 0
Vin=Vdd 的端子将作为漏极,另一个负载CL 的端子作为源极。
所以 Vgs = 0 - 0 = 0。 NMOS 关闭并且 Vo = 0
(2) Vs = Vdd - 0 = Vdd,
所以NMOS导通(即Vgs> Vt)并开始向Vdd充电负载CL。
一旦输出达到Vdd - Vt,充电将停止,因为此时电压Vgs将变为Vt。
所以对于 Vin = Vdd,Vo= Vdd - Vt,它被 Vt 衰减。
这是Vin=Vdd时MMOS传输门的缺点之一。
当 Vin = 0 时:
(1) Vin=0 的一端作为源极 ,另一个负载 CL 的一端作为漏极 D。
(2)如果 Vg = Vdd,
则 Vgs = Vdd - 0 = Vdd,所以 NMOS 开启(因为 Vgs> Vt ),
因此负载 CL 两端的电压将开始通过 NMOS & source 放电
所以当 Vin = 0 时输出 Vo = 0。
这意味着当 Vin = 0 时 NMO 晶体管提供“良好”逻辑 0
这就是为什么我们不会使用 NMOS 作为传输门,因为它正在产生输出值 当 Vin= Vdd 时的 vdd-Vt
CMOS传输门:
CMOS传输门由一个PMOS和一个NMOS管并联构成,其具有很低的导通电阻(几百欧)和很高的截止电阻(大于10^9欧)。
T1是N沟道增强型MOS管,T2是P沟道增强型MOS管。
T1和T2的源极和漏极分别相连作为传输门的输入端和输出端。(TP和TN是结构对称的器件,它们的漏极和源极是可互换的。)
C和C’是互补的控制信号。
由于CMOS传输门的结构是对称的,所以,输出端和输入端可以互换,是一个双向器件。
数字电路基础知识——CMOS门电路 (与非门、或非、非门、OD门、传输门、三态门)_摆渡沧桑的博客-CSDN博客_cmos门电路
设TP和TN的开启电压|VT|=2V,输入模拟信号的变化范围为-5V到+5V。防止电流从漏极直接流入衬底,使衬底与漏源极之间形成PN结反向偏置:
- TP的衬底接+5V电压,
- TN的衬底接-5V电压。
两管的栅极由互补的信号电压(+5V和-5V)来控制,分别用C和!C表示。
传输门的工作情况如下:
当C端接低电压时,开关是断开的。
当C端接低电压-5V时TN的栅压即为-5V,
Vi取-5V到+5V范围内的任意值时,TN不导通。同时,TP的栅压为+5V,TP亦不导通。
为使开关接通,可将C端接高电压+5V。
此时TN的栅压为+5V,Vi在-5V到+3V的范围内,TN导通。
同时TP的栅压为-5V,Vi在-3V到+5V的范围内TP将导通。
由上分析可知,
- 当Vi≤-3V时,仅有TN导通,
- 当Vi≥+3V时,仅有TP导通
- 当Vi在-3V到+3V的范围内,TN和TP两管均导通。

226、解释 CEL 和 FRAM view ?
CEL 是包含所有层的设计的完整视图(如 GDS),FRAM 只是设计的原理视图(如 lef)
CEL 视图
物理结构的完整布局视图,例如通孔、标准单元、宏或整个芯片;包含单元的布局、布线、引脚和网表信息。
- 布局、布线和掩模生成所需的所有单元信息。
- 放置信息,例如tracks、site rows和placement blockages;
- routing information,例如网表、引脚、route guide南和互连建模信息,以及用于最终掩膜生成的所有掩膜层几何形状。
FRAM 视图:
FRAM 视图是单元的抽象,仅包含布局和布线所需的信息:不允许布线的metal blockages区域、允许的过孔区域和引脚位置。
从 CEL 视图创建 FRAM 视图的过程通常称为blockage,pin, 和 via (BPV) 提取。
FRAM 视图用于布局和布线,而 CEL 视图仅用于生成芯片制造的最终掩模数据流。
227、将 n-well 连接到 VDD 并将 p-substrate 连接到 VSS 的原因是什么?
防止正向偏置漏极到 n 阱结和源极到 p 衬底结。
228、Well Edge Proximity (WEP)effect(边缘邻近效应)
因为离子从光刻胶掩模散射到井的边缘, 靠近retrograde well的晶体管(例如,在大约 1 nm 内)可能具有与远离边缘的晶体管不同的阈值电压, 这称为边缘邻近效应。
229、为什么需要金属密度规则 (Metal Density Rule )?
我们必须在指定区域内保持特定层的最小和最大密度。蚀刻速率对必须去除的材料量有一定的敏感性。
例如,如果多晶硅密度太高或太低,晶体管栅极可能最终会过度蚀刻或蚀刻不足,从而导致沟道长度变化。 类似地,CMP工艺在密度不均匀时可能会导致铜的凹陷(过度去除)。
为了防止这些问题,在 100m X100m的区域内,金属层可能需要具有 30% 的最小密度和 70% 的最大密度。扩散多晶硅和金属层可能必须手动添加或在设计完成后通过填充程序添加。
填充物可以接地或悬空:
- 浮动填充(Floating fill):有助于降低总电容,但对附近导线的耦合电容更大。
- 接地填充( Grounded fill ):需要将接地网布线到填充结构。
金属填充物可以以各种形状和大小存在。
通常,设计中有两种类型的金属填充结构:
- 接地金属填充(grounded metal fill):通过过孔连接到电源或接地
- 浮动金属填充( floating metal fill):与信号、电源或接地网络没有连接
这两种类型可能存在于同一布局中。
运行 StarRc 提取时,您可以指定要仿真或真实的金属填充。
这两种方法根据精度要求产生不同的结果。
仿真填充仅在布局布线流程的早期阶段使用,不应用于与布局布线流程相关联。
LEF/DEF 有两种不同形式的用于指定金属填充的语法。
浮动金属填充多边形在 DEF 文件的“FILLS”部分中指定。
如果填充多边形连接到电源和接地网络,它们在电源和接地网络的 SPECIALNETS 部分(特殊 WIRing 的一部分,形状定义为 FILLWIRE)中指定。
金属填充可以通过两种方式处理:
- 作为接地金属填充
- 浮动金属填充
接地金属填充物
在信号网络提取过程中,填充多边形被视为属于电源和接地网络的多边形。
在提取离子期间没有对这些多边形进行特殊处理。
浮动金属填充
在这种模式下,计算信号和填充多边形之间以及不同填充多边形之间的电容。
填充节点会在运行中减少,并计算信号网络之间的等效电容和信号网络的接地电容。
如果金属填充没有连接到网表中的任何电路元件,则称它是浮动的。
通过将填充网上的电荷设置为零来有效地确定填充网上的电势。
即使填充网络没有电连接,它们也会在其他网络之间引入电容耦合效应
**栅极和扩散电容:**
扩散电容取决于源/漏区的大小。更宽的晶体管具有成比例地更大的扩散电容。 增加沟道长度会成比例地增加栅极电容,但不会影响扩散电容。
230、解释ECO Extraction
ECO extraction是仅对与参考设计(reference design)不同的设计部分执行提取的技术
StarRC ECO 提取流程仅在因 ECO 修复而更改的网络上执行提取,从而大大减少了总运行时间。在此流程中,StarRC 工具维护两个寄生网表:
- 一种用于全芯片提取
- 一种用于受 ECO 影响的网络
ECO extraction通过智能选择网络进行re-extraction,达到与全芯片提取相同的提取精度。除了由 ECO 直接更改的网络之外,该工具还根据它们与 ECO 网络的耦合电容来选择相邻网络。
COUPLE_ TO_ GROUND 命令应在 ECO 流程中设置为 NO。
Net E,ECO net,是一个作为时序违规修复的一部分进行修改的网络。
Net A 耦合到Net E; 这种类型的net是直接受 ECO 影响的net( ECO-affected net)。
Net N 不直接耦合到Net E,而是耦合到Net A。这种类型的net是间接受 ECO影响的net。
StarRC 工具在 ECO 网表(NETLIST_ECO_FILE 命令指定的文件)中包括 net E 和 net A,但不包括 net N。net A 和 net N 之间的耦合电容在 ECO netlist中 net A 下显示为悬空电容。
PrimeTime 工具可以读取 ECO netlist并相应地调整网络 N 的耦合和总电容。

如果你在一个单元上进行LVT交换,那么StarRC工具不会重新提取连接的线或在网表中替换它们。
来自全芯片提取的网表被写入由NETLIST_FILE 命令指定的文件。来自 ECO 提取的网表被写入 NETLIST_ECO_FILE 命令指定的文件。
ECO_MODE 命令控制ECO 提取。选项有 YES、RESET 和 NO(默认)。
第一次 StarRC 运行始终是全芯片提取,因为 ECO 提取必须存在参考运行。随后的 StarRC 运行可以是全芯片或 ECO 提取,具体取决于与设计大小相比受 ECO 影响的网络的数量。
StarRC 工具维护完整的网表和 ECO 网表; PrimeTime 工具可以读取这两个网表并适当地使用它们。 .
来自全芯片提取的网表被写入由NETLIST_FILE 命令指定的文件。来自 ECO 提取的网表被写入 NETLIST_ECO_FILE 命令指定的文件。
除非以下条件之一适用,否则将执行 ECO 提取:StarRC 工具不执行任何提取,也不更新网表,如果设计数据库自上次提取后没有任何逻辑或物理变化。
如果StarRC目录缺失,由于没有参考运行,工具会进行全芯片提取。