- 用Python实现读取统计单词个数
程序媛了了
python游戏java
完整实例代码:fromcollectionsimportCounterdefpythonit():danci={}withopen("pythonit.txt","r",encoding="utf-8")asf:foriinf:words=i.strip().split()forwordinwords:ifwordnotindanci:danci[word]=1else:danci[word]+=
- Android应用性能优化
轻口味
Android
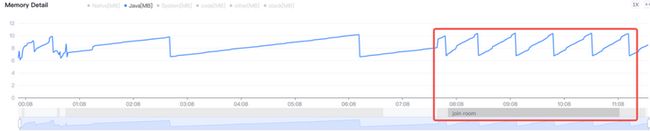
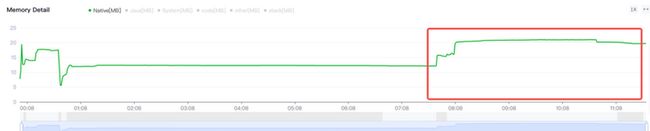
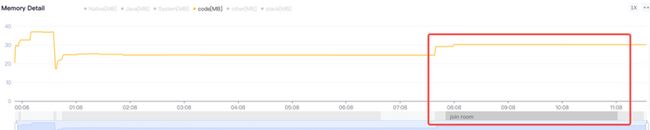
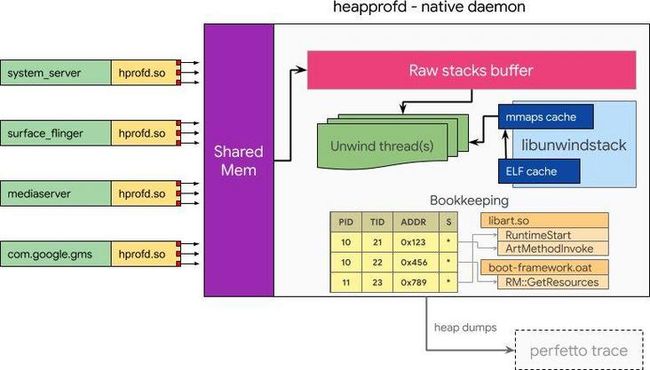
Android手机由于其本身的后台机制和硬件特点,性能上一直被诟病,所以软件开发者对软件本身的性能优化就显得尤为重要;本文将对Android开发过程中性能优化的各个方面做一个回顾与总结。Cache优化ListView缓存:ListView中有一个回收器,Item滑出界面的时候View会回收到这里,需要显示新的Item的时候,就尽量重用回收器里面的View;每次在getView函数中inflate新
- tiff批量转png
诺有缸的高飞鸟
opencv图像处理pythonopencv图像处理
目录写在前面代码完写在前面1、本文内容tiff批量转png2、平台/环境opencv,python3、转载请注明出处:https://blog.csdn.net/qq_41102371/article/details/132975023代码importnumpyasnpimportcv2importosdeffindAllFile(base):file_list=[]forroot,ds,fsin
- 深入浅出 -- 系统架构之负载均衡Nginx的性能优化
xiaoli8748_软件开发
系统架构系统架构负载均衡nginx
一、Nginx性能优化到这里文章的篇幅较长了,最后再来聊一下关于Nginx的性能优化,主要就简单说说收益最高的几个优化项,在这块就不再展开叙述了,毕竟影响性能都有多方面原因导致的,比如网络、服务器硬件、操作系统、后端服务、程序自身、数据库服务等,对于性能调优比较感兴趣的可以参考之前《JVM性能调优》中的调优思想。优化一:打开长连接配置通常Nginx作为代理服务,负责分发客户端的请求,那么建议开启H
- 补充元象二面
Redstone Monstrosity
前端面试
1.请尽可能详细地说明,防抖和节流的区别,应用场景?你的回答中不要写出示例代码。防抖(Debounce)和节流(Throttle)是两种常用的前端性能优化技术,它们的主要区别在于如何处理高频事件的触发。以下是防抖和节流的区别和应用场景的详细说明:防抖和节流的定义防抖:在一段时间内,多次执行变为只执行最后一次。防抖的原理是,当事件被触发后,设置一个延迟定时器。如果在这个延迟时间内事件再次被触发,则重
- MyBatis 详解
阿贾克斯的黎明
javamybatis
目录目录一、MyBatis是什么二、为什么使用MyBatis(一)灵活性高(二)性能优化(三)易于维护三、怎么用MyBatis(一)添加依赖(二)配置MyBatis(三)创建实体类和接口(四)使用MyBatis一、MyBatis是什么MyBatis是一个优秀的持久层框架,它支持自定义SQL、存储过程以及高级映射。MyBatis免除了几乎所有的JDBC代码以及设置参数和获取结果集的工作。它可以通过简
- metaRTC8.0,一个全新架构的webRTC SDK库
metaRTC
webrtc音视频
概述metaRTC8.0是metaRTC开源以来架构变化最大的一个版本,是metaIPC3.0等高性能的基础。metaRTC8.0是一个全新架构版本,并非在metaRTC7.0版本上简单升级,在QOS/语音对讲/内存占用/视频文件录制读取等方面新增多个模块,在弱网对抗/语音对讲/内存优化等效果上有显著提升。metaRTC8.0在一年多的开发中进行了近200次迭代,metaRTC8.0社区版计划在2
- metaRTC/webRTC QOS 方案与实践
metaRTC
metaRTC解决方案webrtcqos
概述质量服务(QOS/QualityofService)是指利用各种技术方案提高网络通信质量的技术,网络通信质量需要解决下面两个问题:网络问题:UDP/不稳定网络/弱网下的丢包/延时/乱序/抖动数据量问题:发送数据量超带宽负载和平滑发送拥塞控制是各种技术方案的数据基础,丢包恢复解决丢包问题,抗乱序抖动解决网络乱序抖动问题,流量控制解决平滑发送数据/数据超带宽负载/延时问题。拥塞控制(Congest
- metaRTC5.0 API编程指南(一)
metaRTC
metaRTCc++c语言webrtc
概述metaRTC5.0版本API进行了重构,本篇文章将介绍webrtc传输调用流程和例子。metaRTC5.0版本提供了C++和纯C两种接口。纯C接口YangPeerConnection头文件:include/yangrtc/YangPeerConnection.htypedefstruct{void*conn;YangAVInfo*avinfo;YangStreamConfigstreamco
- Rust是否会取代C/C++?Rust与C/C++的较量
AI与编程之窗
源码编译与开发rustc语言c++内存安全并发编程代码安全性能优化
目录引言第一部分:Rust语言的优势内存安全性并发性性能社区和生态系统的成长第二部分:C/C++语言的优势和地位历史积淀和成熟度广泛的库和工具支持性能优化和硬件控制丰富的行业应用社区和行业支持第三部分:挑战和阻碍学习曲线现有代码库的迁移成本生态系统和工具链的完善度社区和人才培养行业应用和推广法规和标准化第四部分:未来趋势和可能性行业趋势教育和人才培养兼容和共存行业标准化企业支持和应用开源社区和生态
- 连接池的性能如何优化?
蜡笔小新星
MySQL经验分享学习pythonmysql数据库
连接池的性能优化是提高数据库访问效率和应用程序响应速度的关键。以下是一些优化连接池性能的策略:1.选择合适的连接池大小连接池的大小应根据应用程序的并发需求和数据库服务器的处理能力来确定。如果连接池太小,可能会导致线程等待连接;如果连接池太大,可能会消耗过多的系统资源。通常,连接池的大小应该设置为应用程序的并发用户数加上一些额外的连接以处理突发请求。2.设置合理的最小和最大连接数最小连接数(mins
- 系列3:【深入】qiankun动态与按需加载子应用—像电影一样控制出现时机
rabbit_it
qiankun学习前端框架前端阿里云
一、引言:为何需要动态加载在现代前端开发中,性能优化始终是一个关键问题。对于微前端架构而言,管理多个子应用带来了前所未有的灵活性,但也对资源的加载和使用效率提出了更高要求。假设你的微前端项目就像一场电影,而子应用是场景或演员。在不同的情节中,我们只需要特定的场景和演员出现,而不需要所有场景和演员一开始就站在舞台上等待。这时,动态加载和按需加载就成为了关键工具——让需要的内容在正确的时机上场,节省性
- STM32 的 RTC(实时时钟)详解
千千道
STM32stm32物联网单片机
目录一、引言二、RTC概述三、RTC的工作原理1.时钟源2.计数器3.闹钟功能4.备份寄存器四、RTC寄存器1.RTC_TR(TimeRegister,时间寄存器)2.RTC_DR(DateRegister,日期寄存器)3.RTC_SSR(SubsecondRegister,亚秒寄存器)4.RTC_PRER(PrescalerRegister,预分频器寄存器)5.RTC_CR(ControlReg
- 9.15初识指针
西科Monesy
c语言开发语言
初识指针什么是指针?指针是一种数据类型,它存储了变量的内存地址。通过指针,程序可以直接访问和操作内存中的数据,而不是通过变量的名称。这使得C语言在内存管理和性能优化方面具有很大的灵活性。内存是什么?内存是电脑上的存储器,计算机中程序的运行都是在内存中进行的。程序中如果有数据需要存储也会申请内存空间。为了有效的使用内存,就把内存划分成一个小小的内存单元,每个内存单元的大小是一个字节。为了能够有效的访
- 解决BERT模型bert-base-chinese报错(无法自动联网下载)
搬砖修狗
bert人工智能深度学习python
一、下载问题hugging-face是访问BERT模型的最初网站,但是目前hugging-face在中国多地不可达,在代码中涉及到该网站的模型都会报错,本文我们就以bert-base-chinese报错为例,提供一个下载到本地的方法来解决问题。二、网站google-bert(BERTcommunity)Thisorganizationismaintainedbythetransformerstea
- opencv 学习 1
木木ainiks
opencv计算机视觉python
opencv学习的第一天#coding:utf-8importcv2ascv#首先读图片src=cv.imread(“img/1.jpg”)#设置图片的名字cv.namedWindow(“1”,cv.WINDOW_AUTOSIZE)#显示图片第一个参数设置图片名,第二个参数图片的地址cv.imshow(“1”,src)cv.waitKey(0)#将图片写入固定位置cv.imwrite(“img/2
- Java中的服务端点响应缓存:Spring Cache抽象
微赚淘客机器人开发者联盟@聚娃科技
java缓存spring
Java中的服务端点响应缓存:SpringCache抽象大家好,我是微赚淘客返利系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿!在Java后端服务开发中,缓存是一个重要的性能优化手段。Spring框架提供了一个强大的缓存抽象,允许开发者以统一的方式使用不同的缓存技术。本文将介绍如何在Java应用中使用SpringCache抽象来实现服务端点的响应缓存。响应缓存的重要性响应缓存在服务端点中
- JavaScript 基础 - 第15天
+码农快讯+
JavaScript学习笔记javascript前端开发语言
文章目录JavaScript基础-第15天深浅拷贝浅拷贝深拷贝通过JSON序列化实现js库lodash实现深拷贝通过递归实现深拷贝异常处理throwtry...catchdebugger处理this改变thiscallapplybindthis指向性能优化防抖(debounce)手写防抖函数节流(throttle)手写节流函数JavaScript基础-第15天深浅拷贝浅拷贝浅拷贝:把对象拷贝给一个
- 【QT教程】QT6硬件图形界面编程 QT硬件编程
QT性能优化QT原理源码QT界面美化
qtqt6.3qt5c++QT教程
QT6硬件图形界面编程使用AI技术辅助生成QT界面美化视频课程QT性能优化视频课程QT原理与源码分析视频课程QTQMLC++扩展开发视频课程免费QT视频课程您可以看免费1000+个QT技术视频免费QT视频课程QT统计图和QT数据可视化视频免费看免费QT视频课程QT性能优化视频免费看免费QT视频课程QT界面美化视频免费看1QT6硬件图形界面编程概述1.1QT6硬件图形界面编程简介1.1.1QT6硬件
- 前端性能优化
EdmundChen
要做性能优化,首先我们得知道用户从开始访问站点到看结果的这一段时间到底后花在了哪些地方。这就设计到一个经典问题。在游览器输入地址按下回车键之后到用户看到结果经历了哪些过程,这里简单说一下大的几个过程。(假设是输入的一个域名而非IP)1.通过DNS解析获得网址的对应IP地址2.浏览器拿到IP地址与远程web服务器通过TCP三次握手协商来建立一个TCP/IP连接3.浏览器通过HTTP接发送请求4.服务
- 面试总结1
Xl_Lee
性能优化1.造成tableView卡顿的原因有哪些?1.最常用的就是cell的重用,注册重用标识符如果不重用cell时,每当一个cell显示到屏幕上时,就会重新创建一个新的cell如果有很多数据的时候,就会堆积很多cell。如果重用cell,为cell创建一个ID,每当需要显示cell的时候,都会先去缓冲池中寻找可循环利用的cell,如果没有再重新创建cell2.避免cell的重新布局cell的布
- React项目的开发前准备 以及 JSX 的基本使用
渡鸦七
Reactreact.js前端前端框架
React项目的开发前准备以及JSX的基本使用React项目创建create-react-appnpxcreate-react-appmy-appcdmy-appnpmstartyarncreatereact-appyarncreatereact-appmy-appcdmy-appyarnstartcreate-react-app和yarncreatereact-app都可以快速创建一个React
- SpringBoot3与SpringBoot2的区别
bjzhang75
springboot
文章目录1、JDK环境2、SpringFramework版本3、主要变化和新特性3.1配置变化3.2GraalVM3.3安全性改进3.4性能优化3.4.1启动时间3.4.2内存使用3.5改进的依赖管理3.6全新启动器3.7Kotlin支持SpringBoot3与SpringBoot2的区别1、JDK环境SpringBoot3最低要求JDK17SpringBoot2最低要求JDK82、SpringF
- Python 将parquet文件转换为csv文件
一个小坑货
#python常用功能方法python开发语言
Python将parquet文件转换为csv文件使用pyarrow插件将parquet文件转换为csv使用pyarrow插件将parquet文件转换为csv```pythonimportosimportpyarrow.parquetaspqfromconcurrent.futuresimportThreadPoolExecutorimportcsvimporttime#定义一个函数来处理单个Par
- Java-后端程序员个人知识总结
金肴羽
java开发语言
文章目录概要1.编程语言2.数据结构与算法3.数据库知识4.框架和库5.服务器管理6.网络知识7.版本控制8.测试9.安全知识10.系统设计11.编码规范与最佳实践12.持续学习和适应能力概要后端程序员,主要负责应用程序的逻辑、数据库交互、服务器配置以及应用的性能优化等。成为一名优秀的后台程序员,需要掌握以下技能:1.编程语言掌握至少一种后台编程语言JavaPythonHtmlJavaScript
- WebRTC之LiveKit的基础入门使用(入门必看)
tabzzz
前端webrtcweb3typescript
LiveKit本文主要是讲解在Next13+中如何使用LiveKit来实现简单的音视频通话,想了解更多的还是要去官方文档去掌握更复杂、高级的使用方法。什么是LiveKitLiveKit是一个开源的实时通信平台,基于WebRTC,主要用于构建高质量的音视频通话、实时数据传输和互动应用。LiveKit除了方便以外的大优势就是它提供了丰富的API和SDK,支持多种平台,包括Web、iOS、Android
- 案例分析:如何用设计模式优化性能7
是小旭啊
fastapi
设计模式就是对常用开发技巧进行的总结,它使得程序员之间交流问题,有了更专业、便捷的方式。比如,我们在《02|理论分析:性能优化有章可循,谈谈常用的切入点》中提到,I/O模块使用的是装饰器模式,你就能很容易想到I/O模块的代码组织方式。事实上,大多数设计模式并不能增加程序的性能,它只是代码的一种组织方式。本课时,我们将一一举例讲解和性能相关的几个设计模式,包括代理模式、单例模式、享元模式、原型模式等
- ELK 架构中 ES 性能优化
xianjie0318
elk架构elasticsearch
1.背景由于目前日志采集流程中,经常遇到用户磁盘IO占用超过90%以上的场景,但是观察其日志量大约在2k~5k之间,整体数据量不大,所以针对该问题进行了一系列的压测和实验验证,最后得出这篇优化建议文档2.压测前期准备2.1制造大量日志该阶段为数据源输入阶段,为了避免瓶颈在数据制造侧,所以需要保证filebeat具有足够的日志制造能力最后效果,filebeat可以达到70kQPS的数据发往logst
- mybatis支持json,Spring boot配置
Knight_9
mysql5.7版本以后支持原生json格式,基于Springboot进行配置说明。mybatis支持mysql的json格式mysql-connector,mysql的驱动版本要大于等于5.1.40,否则json字段查询会发生乱码。继承BaseTypeHandler自定义一个json类型处理器,放到一个handler包下,例:packagecom.c.config.handler;importc
- 微信小程序中的实时通讯:TCP/UDP 协议实现详解
人工智能的苟富贵
前端小程序微信小程序tcp/ipudp
文章目录前言一、实时通讯的基础知识二、微信小程序中TCP/UDP的支持2.1TCP实现2.2UDP实现三、实现即时通讯的基本架构四、实际开发中的注意事项4.1网络环境问题4.2数据格式与协议设计4.3消息重发机制五、实时通讯中的性能优化5.1减少不必要的通信5.2数据压缩5.3异步通信与心跳机制六、使用场景七、总结前言在现代应用程序中,实时通讯已成为用户体验的关键组成部分。无论是在线聊天、游戏、还
- jQuery 键盘事件keydown ,keypress ,keyup介绍
107x
jsjquerykeydownkeypresskeyup
本文章总结了下些关于jQuery 键盘事件keydown ,keypress ,keyup介绍,有需要了解的朋友可参考。
一、首先需要知道的是: 1、keydown() keydown事件会在键盘按下时触发. 2、keyup() 代码如下 复制代码
$('input').keyup(funciton(){
- AngularJS中的Promise
bijian1013
JavaScriptAngularJSPromise
一.Promise
Promise是一个接口,它用来处理的对象具有这样的特点:在未来某一时刻(主要是异步调用)会从服务端返回或者被填充属性。其核心是,promise是一个带有then()函数的对象。
为了展示它的优点,下面来看一个例子,其中需要获取用户当前的配置文件:
var cu
- c++ 用数组实现栈类
CrazyMizzz
数据结构C++
#include<iostream>
#include<cassert>
using namespace std;
template<class T, int SIZE = 50>
class Stack{
private:
T list[SIZE];//数组存放栈的元素
int top;//栈顶位置
public:
Stack(
- java和c语言的雷同
麦田的设计者
java递归scaner
软件启动时的初始化代码,加载用户信息2015年5月27号
从头学java二
1、语言的三种基本结构:顺序、选择、循环。废话不多说,需要指出一下几点:
a、return语句的功能除了作为函数返回值以外,还起到结束本函数的功能,return后的语句
不会再继续执行。
b、for循环相比于whi
- LINUX环境并发服务器的三种实现模型
被触发
linux
服务器设计技术有很多,按使用的协议来分有TCP服务器和UDP服务器。按处理方式来分有循环服务器和并发服务器。
1 循环服务器与并发服务器模型
在网络程序里面,一般来说都是许多客户对应一个服务器,为了处理客户的请求,对服务端的程序就提出了特殊的要求。
目前最常用的服务器模型有:
·循环服务器:服务器在同一时刻只能响应一个客户端的请求
·并发服务器:服
- Oracle数据库查询指令
肆无忌惮_
oracle数据库
20140920
单表查询
-- 查询************************************************************************************************************
-- 使用scott用户登录
-- 查看emp表
desc emp
- ext右下角浮动窗口
知了ing
JavaScriptext
第一种
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/
- 浅谈REDIS数据库的键值设计
矮蛋蛋
redis
http://www.cnblogs.com/aidandan/
原文地址:http://www.hoterran.info/redis_kv_design
丰富的数据结构使得redis的设计非常的有趣。不像关系型数据库那样,DEV和DBA需要深度沟通,review每行sql语句,也不像memcached那样,不需要DBA的参与。redis的DBA需要熟悉数据结构,并能了解使用场景。
- maven编译可执行jar包
alleni123
maven
http://stackoverflow.com/questions/574594/how-can-i-create-an-executable-jar-with-dependencies-using-maven
<build>
<plugins>
<plugin>
<artifactId>maven-asse
- 人力资源在现代企业中的作用
百合不是茶
HR 企业管理
//人力资源在在企业中的作用人力资源为什么会存在,人力资源究竟是干什么的 人力资源管理是对管理模式一次大的创新,人力资源兴起的原因有以下点: 工业时代的国际化竞争,现代市场的风险管控等等。所以人力资源 在现代经济竞争中的优势明显的存在,人力资源在集团类公司中存在着 明显的优势(鸿海集团),有一次笔者亲自去体验过红海集团的招聘,只 知道人力资源是管理企业招聘的 当时我被招聘上了,当时给我们培训 的人
- Linux自启动设置详解
bijian1013
linux
linux有自己一套完整的启动体系,抓住了linux启动的脉络,linux的启动过程将不再神秘。
阅读之前建议先看一下附图。
本文中假设inittab中设置的init tree为:
/etc/rc.d/rc0.d
/etc/rc.d/rc1.d
/etc/rc.d/rc2.d
/etc/rc.d/rc3.d
/etc/rc.d/rc4.d
/etc/rc.d/rc5.d
/etc
- Spring Aop Schema实现
bijian1013
javaspringAOP
本例使用的是Spring2.5
1.Aop配置文件spring-aop.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans
xmlns="http://www.springframework.org/schema/beans"
xmln
- 【Gson七】Gson预定义类型适配器
bit1129
gson
Gson提供了丰富的预定义类型适配器,在对象和JSON串之间进行序列化和反序列化时,指定对象和字符串之间的转换方式,
DateTypeAdapter
public final class DateTypeAdapter extends TypeAdapter<Date> {
public static final TypeAdapterFacto
- 【Spark八十八】Spark Streaming累加器操作(updateStateByKey)
bit1129
update
在实时计算的实际应用中,有时除了需要关心一个时间间隔内的数据,有时还可能会对整个实时计算的所有时间间隔内产生的相关数据进行统计。
比如: 对Nginx的access.log实时监控请求404时,有时除了需要统计某个时间间隔内出现的次数,有时还需要统计一整天出现了多少次404,也就是说404监控横跨多个时间间隔。
Spark Streaming的解决方案是累加器,工作原理是,定义
- linux系统下通过shell脚本快速找到哪个进程在写文件
ronin47
一个文件正在被进程写 我想查看这个进程 文件一直在增大 找不到谁在写 使用lsof也没找到
这个问题挺有普遍性的,解决方法应该很多,这里我给大家提个比较直观的方法。
linux下每个文件都会在某个块设备上存放,当然也都有相应的inode, 那么透过vfs.write我们就可以知道谁在不停的写入特定的设备上的inode。
幸运的是systemtap的安装包里带了inodewatch.stp,位
- java-两种方法求第一个最长的可重复子串
bylijinnan
java算法
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
public class MaxPrefix {
public static void main(String[] args) {
String str="abbdabcdabcx";
- Netty源码学习-ServerBootstrap启动及事件处理过程
bylijinnan
javanetty
Netty是采用了Reactor模式的多线程版本,建议先看下面这篇文章了解一下Reactor模式:
http://bylijinnan.iteye.com/blog/1992325
Netty的启动及事件处理的流程,基本上是按照上面这篇文章来走的
文章里面提到的操作,每一步都能在Netty里面找到对应的代码
其中Reactor里面的Acceptor就对应Netty的ServerBo
- servelt filter listener 的生命周期
cngolon
filterlistenerservelt生命周期
1. servlet 当第一次请求一个servlet资源时,servlet容器创建这个servlet实例,并调用他的 init(ServletConfig config)做一些初始化的工作,然后调用它的service方法处理请求。当第二次请求这个servlet资源时,servlet容器就不在创建实例,而是直接调用它的service方法处理请求,也就是说
- jmpopups获取input元素值
ctrain
JavaScript
jmpopups 获取弹出层form表单
首先,我有一个div,里面包含了一个表单,默认是隐藏的,使用jmpopups时,会弹出这个隐藏的div,其实jmpopups是将我们的代码生成一份拷贝。
当我直接获取这个form表单中的文本框时,使用方法:$('#form input[name=test1]').val();这样是获取不到的。
我们必须到jmpopups生成的代码中去查找这个值,$(
- vi查找替换命令详解
daizj
linux正则表达式替换查找vim
一、查找
查找命令
/pattern<Enter> :向下查找pattern匹配字符串
?pattern<Enter>:向上查找pattern匹配字符串
使用了查找命令之后,使用如下两个键快速查找:
n:按照同一方向继续查找
N:按照反方向查找
字符串匹配
pattern是需要匹配的字符串,例如:
1: /abc<En
- 对网站中的js,css文件进行打包
dcj3sjt126com
PHP打包
一,为什么要用smarty进行打包
apache中也有给js,css这样的静态文件进行打包压缩的模块,但是本文所说的不是以这种方式进行的打包,而是和smarty结合的方式来把网站中的js,css文件进行打包。
为什么要进行打包呢,主要目的是为了合理的管理自己的代码 。现在有好多网站,你查看一下网站的源码的话,你会发现网站的头部有大量的JS文件和CSS文件,网站的尾部也有可能有大量的J
- php Yii: 出现undefined offset 或者 undefined index解决方案
dcj3sjt126com
undefined
在开发Yii 时,在程序中定义了如下方式:
if($this->menuoption[2] === 'test'),那么在运行程序时会报:undefined offset:2,这样的错误主要是由于php.ini 里的错误等级太高了,在windows下错误等级
- linux 文件格式(1) sed工具
eksliang
linuxlinux sed工具sed工具linux sed详解
转载请出自出处:
http://eksliang.iteye.com/blog/2106082
简介
sed 是一种在线编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾
- Android应用程序获取系统权限
gqdy365
android
引用
如何使Android应用程序获取系统权限
第一个方法简单点,不过需要在Android系统源码的环境下用make来编译:
1. 在应用程序的AndroidManifest.xml中的manifest节点
- HoverTree开发日志之验证码
hvt
.netC#asp.nethovertreewebform
HoverTree是一个ASP.NET的开源CMS,目前包含文章系统,图库和留言板功能。代码完全开放,文章内容页生成了静态的HTM页面,留言板提供留言审核功能,文章可以发布HTML源代码,图片上传同时生成高品质缩略图。推出之后得到许多网友的支持,再此表示感谢!留言板不断收到许多有益留言,但同时也有不少广告,因此决定在提交留言页面增加验证码功能。ASP.NET验证码在网上找,如果不是很多,就是特别多
- JSON API:用 JSON 构建 API 的标准指南中文版
justjavac
json
译文地址:https://github.com/justjavac/json-api-zh_CN
如果你和你的团队曾经争论过使用什么方式构建合理 JSON 响应格式, 那么 JSON API 就是你的 anti-bikeshedding 武器。
通过遵循共同的约定,可以提高开发效率,利用更普遍的工具,可以是你更加专注于开发重点:你的程序。
基于 JSON API 的客户端还能够充分利用缓存,
- 数据结构随记_2
lx.asymmetric
数据结构笔记
第三章 栈与队列
一.简答题
1. 在一个循环队列中,队首指针指向队首元素的 前一个 位置。
2.在具有n个单元的循环队列中,队满时共有 n-1 个元素。
3. 向栈中压入元素的操作是先 移动栈顶指针&n
- Linux下的监控工具dstat
网络接口
linux
1) 工具说明dstat是一个用来替换 vmstat,iostat netstat,nfsstat和ifstat这些命令的工具, 是一个全能系统信息统计工具. 与sysstat相比, dstat拥有一个彩色的界面, 在手动观察性能状况时, 数据比较显眼容易观察; 而且dstat支持即时刷新, 譬如输入dstat 3, 即每三秒收集一次, 但最新的数据都会每秒刷新显示. 和sysstat相同的是,
- C 语言初级入门--二维数组和指针
1140566087
二维数组c/c++指针
/*
二维数组的定义和二维数组元素的引用
二维数组的定义:
当数组中的每个元素带有两个下标时,称这样的数组为二维数组;
(逻辑上把数组看成一个具有行和列的表格或一个矩阵);
语法:
类型名 数组名[常量表达式1][常量表达式2]
二维数组的引用:
引用二维数组元素时必须带有两个下标,引用形式如下:
例如:
int a[3][4]; 引用:
- 10点睛Spring4.1-Application Event
wiselyman
application
10.1 Application Event
Spring使用Application Event给bean之间的消息通讯提供了手段
应按照如下部分实现bean之间的消息通讯
继承ApplicationEvent类实现自己的事件
实现继承ApplicationListener接口实现监听事件
使用ApplicationContext发布消息