分布式系统架构演进
文章目录
-
-
-
- 服务奔溃的本质
- 分布式架构的演进
- 高可用服务优化思路
- 总结
-
-
高并发下服务为什么会崩溃,本质是什么? 应对高并发的分布式架构又是如何不断演进优化?
服务奔溃的本质
崩溃是通俗的说法,就是服务不正常了。但是这个不正常是有语境的,比如我们淘宝买东西,应该几秒钟就提示购买成功,但是如果界面一直转圈,10秒后才出来,这个就叫负载大,卡了。如果这个时间继续增大到30秒或者1分钟,浏览器就认为超时了,直接显示打不开,那么对外就是宣称服务崩溃了。比如双十一某宝一些页面一直打不开。但是实际上服务器上程序并没有退出,只是处理不过来了。
崩溃的原因是:服务器对于请求都是排队的,负载不大的时候感觉不到,因为都是1秒内处理了。当请求数量上去后,就开始有感觉了。但是继续增大的话,队列也满了,服务器开始丢弃部分请求,给你一个友好的提示。
如果继续增大网络请求,当网络变得拥堵,而屏幕前的你更是着急的不停的按F5, 那TCP 数据包将反复进行重传,操作系统的TCP协议栈也开始丢弃请求,对外表现为服务器网络也连不上了。
继续增大的话,网卡硬件部分开始满速运行,这时候,CPU、磁盘都可能已经满负荷运载,这时候就只能祈祷服务器的硬件质量非常可靠。如何实现一个高并发系统,早已不是什么新话题,分布式架构也是在类似这样的场景下诞生并不断发展演化。
分布式架构的演进
要了解什么是分布式,得先从它面临的问题开始谈起。在互联网发展的早年,上网还是件新鲜事,所以互联网用户自然也不多。一个网站只需要简单的部署在一台机器上,就完全够用了,所以也就没有分布式的概念。
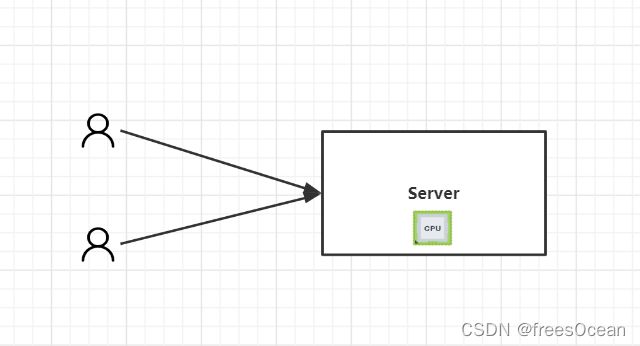
但是,随着互联网迅速发展,用户开始增加,单机的性能开始出现瓶颈。不过好在摩尔定律还能应付用户的增长,所以你只需要提高单机的配置依然可以高枕无忧。但是随着互联网的飞速发展,原本只有几个玩家的互联网市场,开始百花齐放,与此同时摩尔定律也遭遇物理的天花板,单机性能的提升不但缓慢,而且价格高昂。
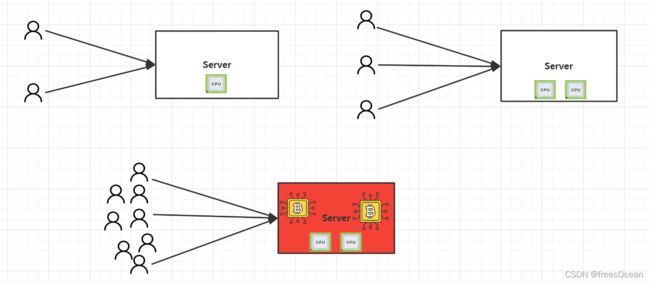
就拿最重要的数据库系统来说,很多大企业比如银行要花数千万的经费来购买Oracle 或IBM的服务以及配套的小型机。而一些小企业玩家,能不能挣到几千万还是未知数。所以,找到新的软件运行方式成为必然。
单机到分布式的演变
既然一个机器不够,那就用多台机器,每个机器上都运行一个相同的应用,组成一个整体对外服务。由多台机器构成的整体就是集群,集就是多的意思,群就是表示一个整体。对用户来讲,只有一个网站,是以一个整体对外服务,至于你后台有多少台机器,用户不知道也不需要知道。
而一个相同的应用,运行在多个不同的机器上,这个应用就是分布式应用。
所以分布式的核心思想就是分治思想,一个人干不了,不是找一个更强的人干,而是找很多普通人一块干。显然后者更加容易实现。
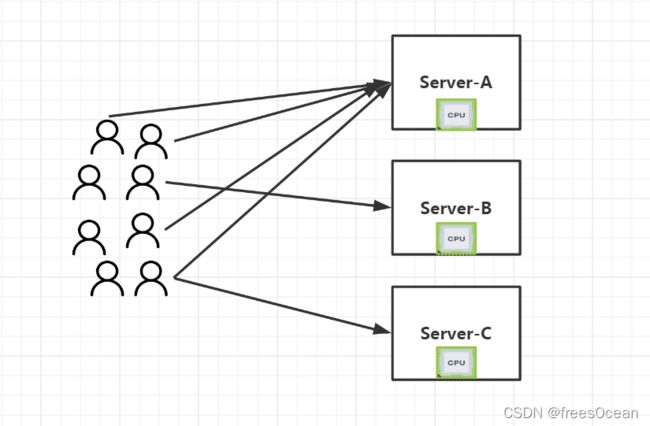
那么问题来了,当用户访问网站,具体要用哪个机器上的服务来响应用户,该由谁来决定?如果全都访问A,那就出现了数据倾斜,A忙的要死,而其他服务器却无事可做。理想的状态是能够比较均匀的分配请求到不同的服务器上,即需要负载均衡(Load Balance)。
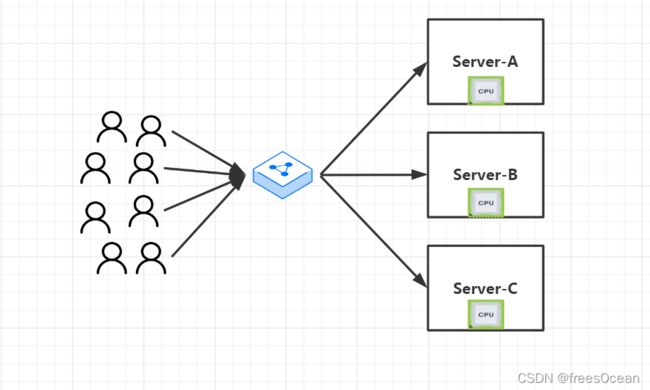
用户的请求全部交给负载均衡设备,负载均衡设备根据策略来平衡分配请求到后端的服务器。这里的负载均衡器,有通过硬件实现的四层负载设备F5, 或者7层负载设备Nignx。其最终目的都是接管所有客户端的请求,然后根据某种策略(比如DNS轮训,URL轮询等)进行分配,让资源合理利用。(这里的四层或七层,指的是负载均衡的实现时位于OSI参考模型的哪一层)
我们知道HashMap时的底层是数组+链表,哈希函数的作用也是类似,就是把数据平均散列到底层的数组中,让数据均匀,所以哈希函数也叫散列函数,可以看作是一种微观的负载均衡。
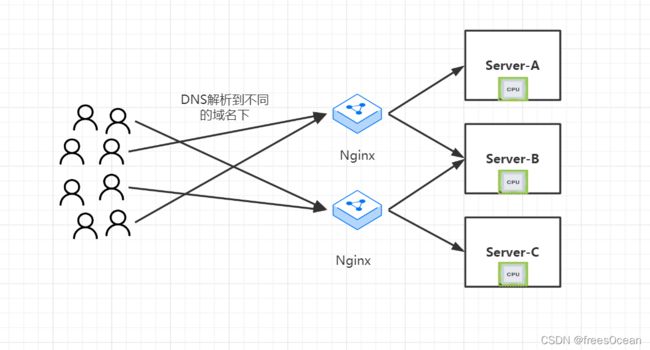
从上图也可以看到此时的负载均衡设备成了整个流量的关卡,所以它的稳定性至关重要,所以nginx也应该部署为集群,以提高它的容错性。所以在此演化为下面这种模式
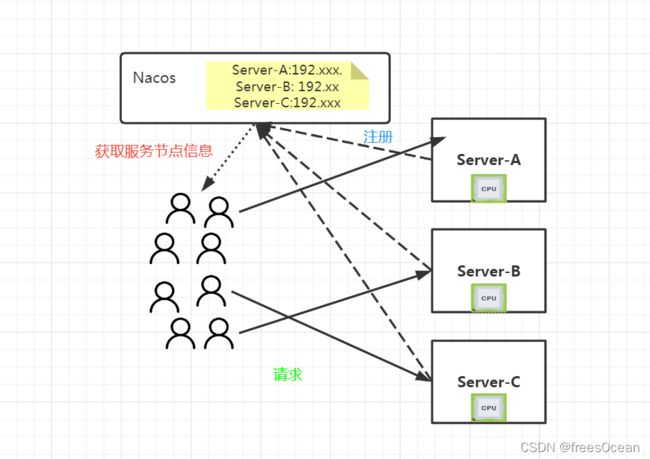
刚才我们谈到的负载均衡策略,都是在服务端实现,而随着微服务架构的普及,现在出现了另一种负载均衡方式:客户端负载均衡。 客户端负载均衡指的是,要访问哪个节点的服务,客户端自己决定,但是客户端如何知道有哪些节点可以访问?这里就涉及到服务注册和发现。后端的所有可用服务注册到服务注册和发现中心(比如nacos、zookeeper、consule、eureka、etcd…)
这时客户端只要连接注册中心,就能拿到这张访问名单,然后自己决定该访问哪个节点。
分布式的核心是分治思想,但是实现分布式系统不是增加几台机器那么简单,集群间的通信,网络,数据一致性等等一系列问题有非常深的技术壁垒。而这种复杂性,也带来了很多问题。这也进一步要求我们的服务架构要配套升级,才能应对分布式应用带来的复杂性。
服务架构升级
随着从单机到分布式的演化,我们的服务架构也在演化,从单体架构,SOA架构、到微服务架构,在到目前经常被提到的无服务架构(serverless)。单机和分布式式关注的应用的部署环境,即单机部署还是集群部署。而服务架构关注的是业务逻辑层面,单体架构将所有业务逻辑放在同一套代码中,SOA和微服务,则根据业务将模块拆分,分别开发和部署,SOA和微服务概念的界限很模糊,唯一区别就是拆分的粒度不同。而具体到每一个服务本身,它可以单机部署或分布式部署。而无服务,目标则是屏蔽底层服务的复杂性,让用户只关心业务逻辑,至于什么分布式,高可用,全交给云厂商,而底层其实还是微服务那一套。
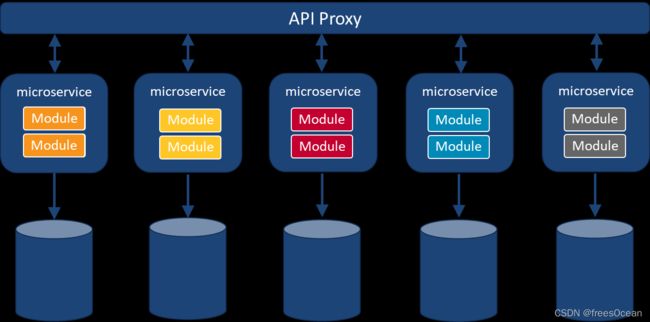
随着底层细节的屏蔽,我们说的单机部署和集群部署其实还不太准确,因为在云计算时代,我们压根就不需要知道具体有几台物理机器,我只需要描述需要的计算资源即可,所以用单实例部署和多实例部署 会更加准确,因为一台机器也可能虚拟化成多台机器,而随着容器化部署等技术,机器与机器的边界似乎已经被打破,这一点如果你部署过k8s应用,体会会更加深刻。
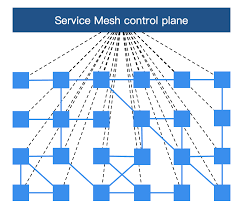
随着云原生的发展,容器化部署成为主流。目前基于k8s的ServiceMesh被称为第二代微服务架构,而k8s本身对Pod的调度又可以进行多实例和负载均衡处理,所以又多了一种玩法。并且ServiceMesh把微服务中网关的部分功能,比如流量控制下沉到了基础设施层,而且像灰度发布蓝绿发布等高级玩法,在ServiceMesh中则支持的非常好。k8s的发展势头不可阻挡,因为背后有google、Redhat等巨头站台,而ServiceMesh又紧密结合k8s, 所以受到google等巨头的大力推崇,所以
技术演进这条路将一直持续下去,正如《人月神话》中所说的那样,软件开发没有银弹。
高可用服务优化思路
看到这里,我们会想,如果把目前最牛逼的架构都用上,再购买足够多的服务那高并发的问题不就解决了。当然如果不考虑成本,的确如此。但是软件开发考虑的因素太多了,成本,需求等等,最终的方案就是在这些限制下做出一个权衡。
具体到每一个软件开发过程,可能情况有所不同。但是我们依然可以提供一些思路如何去优化一个系统。
全局性优化策略:
- 基于安全和隐私,应该搭建私有云,非必要不使用公有云
- 某些流量洪峰期间,停止界面非核心服务,比如双十一,物流,评论等功能可能会进行屏蔽,将资源让出。
后端服务优化:
-
微服务改造,充分利用云原生的弹性伸缩性
-
数据库读写分离
并且数据库可以采用查询分析能力更强的数据库,比如ClickHouse。另外做好缓存策略。
-
CDN缓存,一方面加快用户访问速度,另一方面减少后端服务器负载压力
-
服务和数据冗余
-
热数据缓存
-
降级限流:这是一种弃车保帅的策略,非常重要。
前端页面优化:
- 非必要,不使用图片
- 非核心数据,在客户端计算,减轻服务端计算压力
- 启用http1.1头部压缩,减轻带宽压力
- 界面提示友好,不要提示崩溃等字样,制造焦虑
测试优化:
- 添加高性能自动化测试,压力测试
- 服务演练,做好短期故障的前后端演练工作,提高问题处理效率,服务崩溃不可怕,只要能快速修复,其实影响不大
总结
本文我们聊到分布式应用的诞生和演进,以及服务架构的演化升级,也给出了一些高可用服务优化的思路。没有更好的方案,所有的方案都是在当时的场景,资源,人力等情况下形成的最好的方案。技术演进会一直向前,没有终局!