时序数据库
时序数据库
万物互联时代,工业物联网产生的数据量比传统的信息化要多数千倍甚至数万倍,并且是实时采集、高频度、高密度,动态数据模型随时可变。传统数据库在对这些数据进行存储、查询、分析等处理操作时捉襟见肘,迫切需要一种专门针对时序数据来做优化的数据库系统,即时间序列数据库。

什么是时序数据
从定义上来将,时间序列数据Time Series Data (TSD),就是一串按时间维度索引的数据。用描述性的语言来解释什么是时序数据,简单的说,就是这类数据描述了某个被测量的主体在一个时间范围内的每个时间点上的测量值。它普遍存在于IT基础设施、运维监控系统和物联网中。
简单的说,就是这类数据描述了某个被测量的主体在一个时间范围内的每个时间点上的测量值。它普遍存在于IT基础设施、运维监控系统和物联网中。
例如:对某个服务器的性能采集数据,某个时间点收集服务器的cpu、内存、io等,就是一系列时序数据
对时序数据进行建模的话,会包含三个重要部分,分别是:主体,时间点和测量值。套用这套模型,你会发现你在日常工作生活中,无时无刻不在接触着这类数据。
-
如果你是一名司机,汽车的位置数据是随着时间变化不断在变化的,那么根据时间确定的位置值及其他属性所组成的一系列数据就是一组时序数据,当我们驾驶汽车开启导航时,就需要根据这一组时序数据判断接下来到达目的地的路线以及存储驾驶记录。
-
如果你是一个运维人员,监控数据是一类时序数据,例如对于机器的CPU的监控数据,就是记录着每个时间点机器上CPU的实际消耗值。
-
如果你是一个股民,某只股票的股价就是一类时序数据,其记录着每个时间点该股票的股价。
-
在互联网中,时序数据更是无处不在,比如,用户访问网站的记录、应用系统的系统日志数据等等。
时序数据是基于时间的一系列的数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。
什么是时序数据库
基于快速增长的时序数据应用需求以及区别于传统关系型数据的特征,时序数据库应运而生。
时序数据库全称为时间序列数据库 Time Series Database (TSDB),用于存储和管理时间序列数据的专业化数据库,是优化用于摄取、处理和存储时间戳数据的数据库。其跟常规的关系数据库SQL相比,最大的区别在于:时序数据库是以时间为索引的规律性时间间隔记录的数据库。
时序数据库特点
时序数据库一般具有以下特点:
高吞吐量写入能力
这是针对时序业务持续产生海量数据这么一个特点量身定做的,当前要实现系统高吞吐量写入,必须要满足两个基本技术点要求:系统具有水平扩展性和单机LSM体系结构。系统具有水平扩展性很容易理解,单机肯定是扛不住的,系统必须是集群式的,而且要容易加节点扩展,说到底,就是扩容的时候对业务无感知,目前Hadoop生态系统基本上都可以做到这一点;而LSM体系结构是用来保证单台机器的高吞吐量写入,LSM结构下数据写入只需要写入内存以及追加写入日志,这样就不再需要随机将数据写入磁盘,HBase、Kudu以及Druid等对写入性能有要求的系统目前都采用的这种结构。
数据分级存储/TTL
这是针对时序数据冷热性质定制的技术特性。数据分级存储要求能够将最近小时级别的数据放到内存中,将最近天级别的数据放到SSD,更久远的数据放到更加廉价的HDD或者直接使用TTL过期淘汰掉。
高压缩率
提供高压缩率有两个方面的考虑,一方面是节省成本,这很容易理解,将1T数据压缩到100G就可以减少900G的硬盘开销,这对业务来说是有很大的诱惑的。另一个方面是压缩后的数据可以更容易保证存储到内存中,比如最近3小时的数据是1T,我现在只有100G的内存,如果不压缩,就会有900G的数据被迫放到硬盘上,这样的话查询开销会非常之大,而使用压缩会将这1T数据都放入内存,查询性能会非常之好。
高效时间窗口查询能力。
时序业务的查询需求分为两类,一是实时数据查询,反映当前监控对象的状态;二是主要是查询某个时间段的历史数据,历史数据的数据量非常大,这时候需要针对时间窗口大量数据查询进行优化。
多维度查询能力
时序数据通常会有多个维度的标签来刻画一条数据,就是上文中提到的维度列。如何根据随机几个维度进行高效查询就是必须要解决的一个问题,这个问题通常需要考虑位图索引或者倒排索引技术。
高效聚合能力
时序业务一个通用的需求是聚合统计报表查询,比如哨兵系统中需要查看最近一天某个接口出现异常的总次数,或者某个接口执行的最大耗时时间。这样的聚合实际上就是简单的count以及max,问题是如何能高效的在那么大的数据量的基础上将满足条件的原始数据查询出来并聚合,要知道统计的原始值可能因为时间比较久远而不在内存中哈,因此这可能是一个非常耗时的操作。目前业界比较成熟的方案是使用预聚合,就是在数据写进来的时候就完成基本的聚合操作。
批量删除能力
时序业务对于过期的数据需要进行批量删除操作。
通常不需要具备事务的能力
时序数据库与传统关系型数据库不同,传统关系型数据库注重增删改查和事务功能,而时序数据库针对海量数据写入,其读取查询多是一段时间段内的数据。
时序数据库发展历史

从时间轴中可以看到,虽然时序数据库近几年才进入大众视野,但其发展可以追溯到 20 世纪 90 年代,在监控领域产生了时序数据存储的需求,由此出现的第一代时序数据库,以RRDtool和 Whisper 为代表,使用固定大小的数据库,可以随时间变化快速存储数值型数据,但是其读性能还是比较弱,缺乏针对时间的特殊优化,并且处理的数据模型单一,通常是内嵌在监控系统中。
随着大数据的发展,时序数据爆发式增长,不只是监控系统,其他系统也有更多处理时序数据的需求,在2011 年开始出现了以 OpenTSDB、KairosDB 为代表的基于分布式存储的时序数据库,这类时序数据库在继承通用存储优势的基础上,针对时间进行优化。比如OpenTSDB 底层依赖于 HBase 集群存储,根据时序的特征对数据进行压缩,节省存储空间;用 TSD进行读写,对时序数据的常用查询进行封装,提供数据聚合、过滤等操作。但是这类数据库也有许多不足,比如低效的全局 UID 机制,依赖 Hadoop 和 HBase 环境,部署及维护成本高。
随着微服务的发展,时序数据库在高速发展,OpenTSDB 存在的不足和部署复杂性促进了低成本的垂直型时序数据库的诞生。以 IfluxDB 为代表的垂直型时序数据库成为时序数据库市场的主流,针对时序数据具备更高效的存储读取等数据处理能力和高效的压缩算法。InfluxDB 的单机版本采用类似 LSM Tree 的 TSM Tree存储结构,引入了 series-key 的概念,根据时间特征对数据实现了很好的分类,减少冗余存储,提高数据压缩率。相对于 OpenTSDB 需要配置 Java 环境和 HBase 环境,InfluxDB 基于 Goland,无依赖,部署简单,并且使用类 SQL 语言的 InfluxQL,易于开发。
时序数据库的发展现状
近几年,时序数据库(time-series database)一直是数据库的热点。在DB-Engines最近24个月的流行度报告中,时序数据库力压其他类别的数据库,是增长趋势最快的数据库类别。

DB-Engines把时间序列数据库作为独立的目录来分类统计,下图是2022年时序数据库前10名榜单

常见的时序数据库
-
RRDTool 是最早的时间序列数据库,它自带画图功能,现在大部分时间序列数据库都使用 Grafana 来画图。
-
Graphite 是用 Python 写的 RRD 数据库,它的存储引擎 Whisper 也是 Python 写的, 它画图和聚合能力都强了很多,但是很难水平扩展。
-
OpenTSDB 使用 HBase 解决了水平扩展的问题。
-
KairosDB 最初是基于 OpenTSDB 修改的,但是作者认为兼容 HBase 导致他们不能使用很多 Cassandra 独有的特性, 于是就抛弃了 HBase 仅支持 Cassandra。
-
InfluxDB 早期是完全开源的,后来为了维持公司运营,闭源了集群版本。增加专门的时间序列数据库单元。
-
**Prometheus **开源的服务监控系统和时序列数据库。
-
TimescaleDB 唯一支持完整SQL的开放源代码时间序列数据库,已针对支持全面SQL的快速提取和复杂查询进行了优化。

开源时序数据库对比
| 时序数据库 | 优点 | 缺点 |
|---|---|---|
| OpenTSDB | - Metric+Tags -集群方案成熟(HBase) - 写高效(LSM-Tress) | - 查询函数有限 - 依赖HBase - 运维复杂 - 聚合分析能力较弱 |
| Graphite | - 提供丰富的函数支持 - 支持自动Downsample - 对Grafana的支持最好 - 维护简单 | - Whisper存储 引擎IOPS高 - Carbon组件CPU使用率高 - 聚合分析能力较弱 |
| InfluxDB | - Metrics+Tags - 部署简单、无依赖 - 实时数据Downsample - 高效存储 | - 开源版本没有集群功能 - 存在前后版本兼容问题 - 存储引擎在变化 |
| Prometheus | - Metric + Tags - 适用于容器监控 - 具有丰富的查询语言 - 维护简单 - 集成监控和报警功能 | - 没有集群解决方案 - 聚合分析能力较弱 |
| Druid | - 支持嵌套数据的列式存储 - 具有强大的多维聚合分析能力 - 实时高性能数据摄取 - 具有分布式容错框架 - 支持类SQL查询 | - 一般不能查询原始数据 - 不适合维度基数特别高的场景 - 时间窗口限制了数据完整性 - 运维较复杂 |
| ElasticSearch | - 支持嵌套数据的列式存储 - 支持全文检索 - 支持查询原始数据 - 灵活性高 - 社区活跃 - 扩展丰富 | - 不支持分析字段的列式存储 - 对硬件资源要求高 - 集群维护较复杂 |
| ClickHouse | - 具有强大的多维聚合分析能力 - 实时高性能数据读写 - 支持类SQL查询 - 提供丰富的函数支持 - 具有分布式容错框架 - 支持原始数据查询 - 适用于基数大的维度存储分析 | - 比较年轻,扩张不够丰富,社区还不够活跃 - 不支持数据更新和删除 - 集群功能较弱 |
时序数据库基本概念

度量(metric)
监测数据的指标,例如风力和温度。相当于关系型数据库中的table。
标签(tag)
指标项监测针对的具体对象,属于指定度量下的数据子类别。一个标签(Tag)由一个标签键(TagKey)和一个对应的标签值(TagValue)组成。
例如在监测数据的时候,指定度量(Metric)是“气温”,“城市(TagKey)= 杭州(TagValue)”就是一个标签(Tag),则监测的就是杭州市的气温。更多标签示例:机房 = A 、IP = 172.220.110.1。
域(field)
单域
对温度的时间序列监测值。
温度(temperature)作为一个度量(metric),共4个数据点,每个数据点由如下组成:
-
timestamp:时间戳
-
三个tag:每个tag都是一个key-value对,tag的key分别是deivceID、floor、room。
-
一个field:温度值
其中4个数据点使用的metric、tag是相同的,所以是同一个时间序列。如图所示:

多域,单一数据源采集
记录一段时间内的某个集群里各机器上各端口的出入流量,每半小时记录一个观测值。
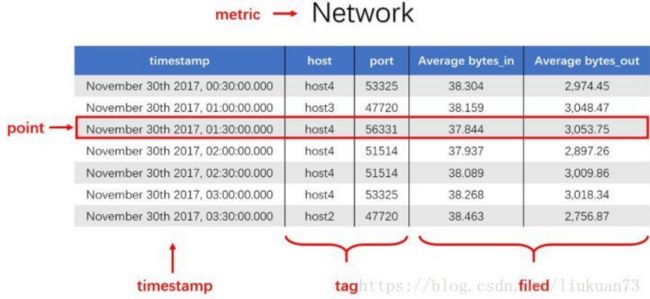
网络(Network)作为一个度量(metric),总共7个数据点。每个数据点由以下部分组成:
- timestamp:时间戳
- 两个tag:host、port,代表每个point归属于哪台机器的哪个端口
- 两个field:bytes_in、bytes_out,代表piont的测量值,半小时内出入流量的平均值
- 同一个host、同一个port,每半小时产生一个point,随着时间的增长,field(bytes_in、bytes_out)不断变化。
如host:host4,port:51514,timestamp从02:00 到02:30的时间段内,bytes_in 从 37.937上涨到38.089,bytes_out从2897.26上涨到3009.86,说明这一段时间内该端口服务压力升高。
多域,多个数据源采集
监测风力的两个域(speed和direction)的监测数据,监测数据来自不同的传感器。
风力(wind)作为一个度量(metric),总共2个时间序列,8个数据点。每个数据点由以下部分组成:
-
3个tag:key分别是sensor、city、province。
为了表示在广东省深圳市传感器编号95D8-7913上传风向(direction)数据,可以将这个数据点的tag为标记为sensor=95D8-7913、city=深圳、province=广东。
-
两个域:风向(direction)和速度(speed),分别来自不同的传感器。
如图,当使用的是metric、field和tag是相同的时,是同一个时间序列。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iuFEM2ux-1649905463201)(https://gitee.com/AuroraLeVi/markdown/raw/master/img/%E7%9B%91%E6%B5%8B%E9%A3%8E%E5%8A%9B%E7%9A%84%E4%B8%A4%E4%B8%AA%E5%9F%9F(speed%E5%92%8Cdirection)]%E7%9A%84%E7%9B%91%E6%B5%8B%E6%95%B0%E6%8D%AE%EF%BC%8C%E7%9B%91%E6%B5%8B%E6%95%B0%E6%8D%AE%E6%9D%A5%E8%87%AA%E4%B8%8D%E5%90%8C%E7%9A%84%E4%BC%A0%E6%84%9F%E5%99%A8.png)
将数据采用metric+field的方式存储的优势在于,可以在同一个时间序列下联合查询。以上图为例,要查询1467627246000-1467627249000时间内风力(wind)的情况,可以联合查询多个field的值,得到下图的数据。

度量值(value)
度量对应的数值,如56°C、1000r/s等(实际中不带单位)。如果有多个field,每个field都有相应的value。不同的field支持不同的数据类型写入。对于同一个field,如果写入了某个数据类型的value之后,相同的field不允许写入其他数据类型。
时间戳(Timestamp)
数据(度量值)产生的时间点。
数据点 (Data Point)
针对监测对象的某项指标(由度量和标签定义)按特定时间间隔(连续的时间戳)采集的每个度量值就是一个数据点。1个metric+1个field(可选)+1个timestamp+1个value + n个tag(n>=1)”唯一定义了一个数据点。相当于关系型数据库中的row。
时间序列(Time Series)
1个metric+1个field(可选) +n个tag(n>=1)”定义了一个时间序列。主要是针对某个监测对象的某项指标(由度量和标签定义)的描述。某个时间序列上产生的数据值的增加,不会导致时间序列的增加。
时间精度
时间线数据的写入时间精度——毫秒、秒、分钟、小时或者其他稳定时间频度。例如,每秒一个温度数据的采集频度,每 5 分钟一个负载数据的采集频度。
数据组(Data Group)
可以按标签这些数据分成不同的数据组。用来对比不同监测对象(由标签定义)的同一指标(由度量定义)的数据。
例如,将温度指标数据按照不同城市进行分组查询,操作类似于该 SQL 语句:select temperature from xxx group by city where city in (shanghai, hangzhou)。
聚合( Aggregation)
可以对一段时间的数据点做聚合,如每10分钟的和值、平均值、最大值、最小值等。
例如,当选定了某个城市某个城区的污染指数时,通常将各个环境监测点的指标数据平均值作为最终区域的指标数据,这个计算过程就是空间聚合。
时序数据库应用场景
时序数据库特别适用于物联网设备监控和互联网业务监控场景。
近年来,时序数据的应用更为广泛,包括物联网(如汽车定位)、经济金融领域、环境监控领域、医学领域、工业制造领域、农业生产领域、硬件和软件系统监控等各方面,都在大量使用时序数据,揭示研究对象的趋势性、规律性、异常性。
系统运维和业务实时监控
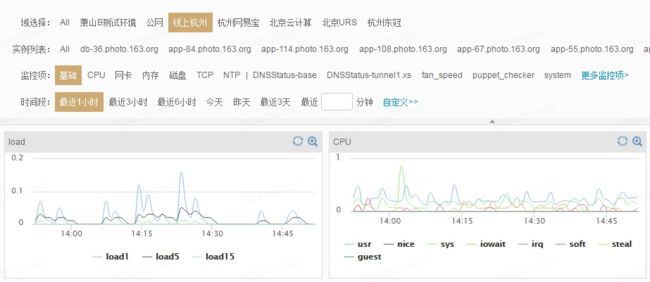
在业务服务器上部署各种脚本客户端,实时采集服务器指标数据(IO指标、CPU指标、带宽内存指标等等),业务相关数据(方法调用异常次数、响应延迟、JVM GC相关数据等等)、数据库相关数据(读取延迟、写入延迟等等),很显然,这些数据都是时间序列相关的。客户端采集和实时计算之后会发送给哨兵服务器,哨兵服务器会将这些数据进行存储,并实现实现监控和分析的展现,供用户查询。
如下图所示,用户可以登录哨兵系统查看某台服务器的负载,负载曲线就是按照时间进行绘制的,带有明显的时序特征:
物联网设备状态监控存储分析
在可预知的未来3~5年,随着物联网以及工业4.0的到来,所有设备都会携带传感器并联网,传感器收集的时序数据将严重依赖TSDB的实时分析能力、存储能力以及查询统计能力。

上图是一个智慧工厂示意图,工厂中所有设备都会携带传感设备,这些传感设备会实时采集设备温度、压力等基本信息,并发送给服务器端进行实时分析、存储以及后期的查询统计。除此之外,比如现在比较流行的各种穿戴设备,以后都可以联网,穿戴设备上采集的心跳信息、血流信息、体感信息等等也都会实时传输给服务器进行实时分析、存储以及查询统计。
阿里云拥有自主研发的时序数据库产品 TSDB ,此产品在阿里内部磨练多年, 历经多次双十一高严苛场景的功能和性能验证, 在应用监控,服务器资源监控,数据库监控, 智慧园区设备监控,以及盒马新零售边缘设备监控都有丰富的落地使用场景 ,覆盖了阿里集团80%以上的时序监控业务。
存储以及后期的查询统计。除此之外,比如现在比较流行的各种穿戴设备,以后都可以联网,穿戴设备上采集的心跳信息、血流信息、体感信息等等也都会实时传输给服务器进行实时分析、存储以及查询统计。
阿里云拥有自主研发的时序数据库产品 TSDB ,此产品在阿里内部磨练多年, 历经多次双十一高严苛场景的功能和性能验证, 在应用监控,服务器资源监控,数据库监控, 智慧园区设备监控,以及盒马新零售边缘设备监控都有丰富的落地使用场景 ,覆盖了阿里集团80%以上的时序监控业务。