JAVAEE----多线程2
线程的状态
我们之前说 进程有就绪状态和阻塞状态,这么说其实是针对一个进程只有一个线程的情况
但其实更常见的情况是----> 一个进程中包含多个线程,而所谓的状态,其实也是绑定在线程上的
我们之前说的就绪状态,阻塞状态都是针对系统层面上的线程的状态(PCB)
而在j ava的Thread类中,对于线程的状态又进一步的细化了
那我们下面就来看看线程状态细化后都分为哪些吧~

3.
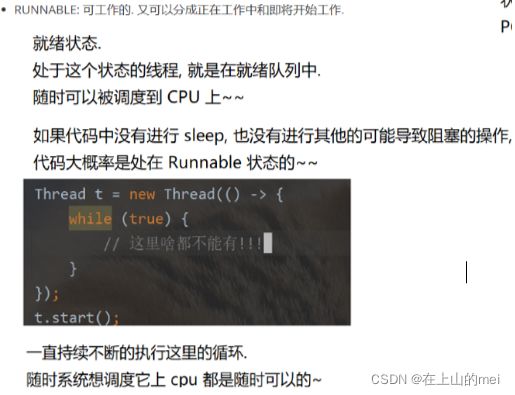
4.

完整的代码:
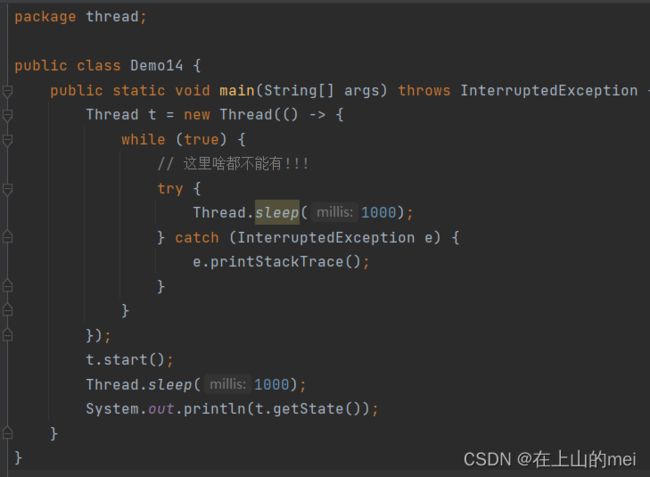
5.

6.

我们小小的整理一下这六种状态之间的关系~

多线程安全(重点)
操作系统调度线程的时候是随机的(抢占式执行)
正因为这样的随机性,就可能导致程序的执行出现一些bug----> 线程不安全
没有出现bug---->线程安全
我们来举一个线程不安全的例子:
使用两个线程,对同一个整型变量进行自增操作,每个线程自增5w
package thread;
class Counter {
// 这个 变量 就是两个线程要去自增的变量
public int count;
public void increase() {
count++;
}
}
public class Demo15 {
private static Counter counter = new Counter();
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
// 必须要在 t1 和 t2 都执行完了之后, 在打印 count 的结果.
// 否则, main 和 t1 t2 之间都是并发的关系~~, 导致 t1 和 t2 还没执行完, 就先执行了下面的 打印 操作
t1.join();
t2.join();
// 在 main 中打印一下两个线程自增完成之后, 得到的 count 结果~~
System.out.println(counter.count);
}
}
这个例子中的代码要知道的是: 
然后下面我们看一下执行结果:发现---->本该是10w结果出来的是77130,那说明这个线程是不安全的!!

那我们就来看看出什么问题了?
这里面count本应该t1的count加完是5w,t2的count加完是5w,最后合起来是10w吗
那问题就出现在count++上了
那我们来分析一下count++
 ------->
-------> 
那下面我们简单画几个根据这个例子可能出现的顺序
1.
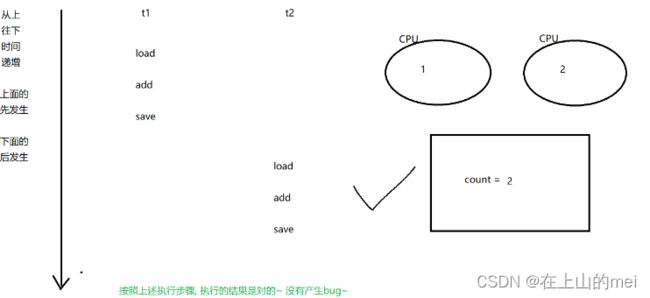
2.

3.

4.

.....还有很多种情况就不写了
怎么解决线程不安全的问题?
答案是----> 加锁!!!--->在自增之前先加锁lock,自增之后再解锁unlock
就像下面这个图片里这样
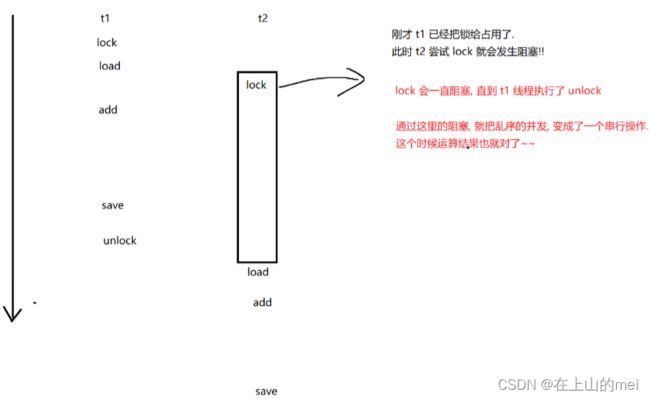
加锁之后的代码:
package thread;
class Counter {
// 这个 变量 就是两个线程要去自增的变量
public int count;
public void increase() {
synchronized (this) {
count++;
}
}
}
public class Demo15 {
private static Counter counter = new Counter();
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
// 必须要在 t1 和 t2 都执行完了之后, 在打印 count 的结果.
// 否则, main 和 t1 t2 之间都是并发的关系~~, 导致 t1 和 t2 还没执行完, 就先执行了下面的 打印 操作
t1.join();
t2.join();
// 在 main 中打印一下两个线程自增完成之后, 得到的 count 结果~~
System.out.println(counter.count);
}
}
那看了上面的例子,我们可能会有一个问题----> 这样加锁之后不就和单线程没区别了吗,成为串行了
确实是这样,加锁之后,并发程度就降低了,此时数据更靠谱了,但相应的速度也慢了
但其实实际开发中,一个线程要做的任务很多,可能一个线程要执行多个步骤,其中可能只有一个步骤涉及到线程安全问题,只针对这一个步骤加锁即可,其他的步骤还是并发执行的
解决完这个小疑问之后,我们来看下 加锁的方法
最常用的方法--->给方法直接加上synchronized关键字--->
此时进入方法,就会自动加锁;离开方法,就会自动解锁
当一个线程加锁成功的时候,其他线程尝试加锁,就会触发阻塞等待
阻塞会一直持续到占用锁的线程把锁释放为止
产生线程不安全的原因(5个原因)
1.线程是抢占式执行2.多个线程对同一个变量进行修改操作3.针对变量的操作不是原子的4.内存可见性问题5.指令重新排序
1.线程是抢占式执行,线程间的调度充满随机性(这是线程不安全的根本原因,但我们没有办法,这个解决不了)
第1个解决不了,我们接着看其他原因~
2.多个线程对同一个变量进行修改操作(就像上面count++的例子)
第二个原因我们有 解决办法---->可以通过调整代码结构,使不同线程操作不同变量
3.针对变量的操作不是原子的
一条 java 语句不一定是原子的,也不一定只是一条指令,比如像上面的count++的例子,其实是由三步操作组成的
什么是原子性?
我们把一段代码想象成一个房间,每个线程就是要进入这个房间的人。如果没有任何机制保证,那么当A进入房间之后,这时B 也进入了房间,就会打断 A 在房间里的隐私。这个就是不具备原子性的。而给这个房间加一把锁,A 进去就把门锁上,其他人就进不来了。这样就保证了这段代码的原子性了。
不保证原子性会给多线程带来什么问题?
如果一个线程正在对一个变量操作,中途其他线程插入进来了,如果这个操作被打断了,结果就可能是错误的。
对于针对变量的操作不是原子的的情况的解决办法--->加锁操作,把这里的多个操作打包成一个原子的操作
4.内存可见性问题(编译器优化的一个典型案例)
什么是内存可见性?
可见性指, 一个线程对共享变量值的修改,能够及时地被其他线程看到.

5.指令重新排序(编译器优化的一个操作)
举一个例子:

编译器会智能调整我们写的代码的前后顺序,从而提高程序的效率
但因为是多线程代码,编译器可能会产生误判,因此
解决方法 ----->synchronized
好的,写到这里我们会发现上面5个产生线程不安全的原因,解决办法里多次出现了synchronized,
因此我们小总结下:synchronized--->
内存可见性面试题
可以从硬件角度(CPU,内存)回答;也可从JMM角度(主内存,工作内存)回答
从硬件角度回答:

从JMM角度回答:


硬件角度和JMM角度,两个角度一起看一下他们的对应关系:
JMM角度的 "主内存" 对应的是硬件角度的 "内存"
"工作内存"对应的是CPU 的寄存器和高速缓存
有一个问题:为什么我们要把变量总是拷来拷去呢?
因为 CPU 访问自身寄存器的速度以及高速缓存的速度, 远远超过访问内存的速度(快了 3 - 4 个数量级, 也就是几千倍, 上万倍).
比如某个代码中要连续 10 次读取某个变量的值, 如果 10 次都从内存读, 速度是很慢的. 但是如果
只是第一次从内存读, 读到的结果缓存到 CPU 的某个寄存器中, 那么后 9 次读数据就不必直接访问
内存了. 效率就大大提高了.
由于CPU从内存存取数据取的太慢,我们就想,可以把这样的数据直接放到寄存器里,后面直接从寄存器中读取,但是这样寄存器空间就太紧张了,于是CPU又另外创建了一个存储空间,这个空间比寄存器大,比内存小,我们叫他缓存(cache),缓存级别分为L1,L2和L3

