实现方法
latent space representation similarity

古老方法
Visual-semantic embedding(nips’13)
idea
模型十分原始,还没有用“cross modal”这种标签,目的是为了学到好的image和text融合的embedding。
图中label其实是image description(text),给image加了个transformation,希望image的space能够transform到与text相同的空间中去。
loss
其loss是拉进相同对,拉远不同对的hinge rank loss:
v()是image的latent space,Mv()就到了与text相同的space了,然后dot得到分数。
小结
后续的其实都可以说是这个模型泛化的。
Image Encoders
UNITER(eccv'20)
出自微软dynamic 365
image端Faster RCNN,nlp端bert。
训练loss除了text bert的MLM,img端也用类似的掩码后重建,外加image-text matching的loss
loss
txt的MLM是bert的老loss,不谈了。
第二部分是图片重建loss。
对图片的重建文章给了三种,因为图片的重建是一个二维张量,所以可以:
- feature regression,在给定其他img region的条件下,恢复出被mask掉的region。回归用的是mse:

- 由于图片是FasterRCNN输出是bounding box和这个box的cls类别,还可以用cls类别做loss:

- 除了mse,还可以用KL拉进输出的ditribution:

第三部分是 txt和img的matching (ITM) loss,采用了二分类loss,预测两个是否是pair:
至此pretrain的Loss就结束了。
其他信息
为了用作不同下游任务,文章还给出了什么下游任务用什么loss组合:
ViT(Vision Transformer ICLR'21)
transformer在cv的转化版。尽管在这篇工作之前也有很多类似的工作,但是这个工作还原度最高、效果最好、训练资源最大。

与原版Transformer稍微有一点区别:
- img patch要先经过线性层做latent space转换
- Transformer block的layer norm的顺序有变化
- positional embedding图像是2D的,txt是1D的,文章尝试了各种2D方式,都差不多。
训练方式和Transformer高度还原,添加1个CLS的token,去做图片分类,文章也尝试了用pooling等cv常用操作,效果差不读。

loss
用CLS预测图片的分类
CLIP
训练
实验

img-text retrieval
JEMA(cikm'21)
来自DeepAI
方法
食物与食谱多模对齐,文章偏应用。
结构特别复杂,image两段feature extraction,text也两段,后各自融合,各自由两两个小loss引导,再两模态融合又有大loss引导,融合后,再加一个小loss引导,共4段loss。
loss
- $DHTL_{sm}$,Soft-margin based Batch Hard Triplet Loss,就是triplet loss,soft margin又hard的triplet loss,这是主loss:

平常的triplet loss是$L=max(d(a,b)-d(a,c)+margin,0)$,原先的$margin+*$,被approximate成了$ln(1-ln(\gamma(*+margin)))$。loss是双边的取样了两次,一次的recipe(text)$\rightarrow$food(image),一次反过来。 - 两个多分类loss,分别是image与image label和text与text高频term的两个多分类任务的loss。


- 一个discriminator loss,专门判别embedding是否是text emb还是img emb:

$F_D$是判别器,判别此emb是否是visual image,还另外给text那部分加了一个让他embs尽可能变得像visual emb的loss $L_{DA}$。
文章的理由是,既然我判别器是判别emb是否是visual,那对text来说我就要尽可能接近v的emb才能让这个GAN work啊。(我估计是模型不加$L_{DA}$收敛不了,个人看过的GAN里加这个的不多。。)
效果
仍然是retrieval实验,用text embs去找 img embs,或者相反方向。
JEMA模型的不同在于recipe关键词的排序不同,img都是ResNet系列做encoder。
最后还是TFIDF的效果最好(老的东西不一定效果不好~)
消融
既然加了这么多loss,到底有没有效果?
-b意思是使用普通triplet loss,作为基线模型;MA_v、MA_r是分支的多分类loss;CA和DA表示 embs判别那个loss是用判别方式还是用分类方式;已经大loss $DHTL_{sm}$。
消融实验结果看起来非常舒服的,并且使用了和eval相同的分数MedR、R@1等。
case study
以text$\rightarrow$img为例,因为输入要有2段:instruction和ingredient,retrieve出来food imgs。
小结

- 这是有监督的,2个模态监督信息 img的分类+text的高频term。
- 结构复杂,组件多。
效果好,各组件消融实验清楚。
EOMA ICMR ’22
文章提出event概念,曰 在一段时间内先做什么后座什么的这些事情,叫做event。而我们food recipe是event dense的,所以要强调event在feature extraction阶段的作用。
话虽然这么说,但是其实forward流程完全一样,只是换个说法讲故事而已。
模型

与原工作的不同点:
- text端:title也用作text data,encoder换为transformer系列
- img端:encoder换为CNN(其实是ResNetXt101,与上个工作一样)+ViT
- event embs:
loss:内部align外加两项

eval
效果只能说炸裂,换了encoder之后直接升天。

既然loss和forward流程并无改变,其实此还是该归功于encoder的选择,Transformer系列、ViT和Transformer确实太好用了。
消融实验的数据也是非常好看(会不会有猫腻……
小结
- 更换encoder,注意event后,效果炸裂,直接提点10%以上;
- 其他和上篇工作一样,可以理解为更换了encoder后的上篇工作;
- 由于效果炸裂,成为会议的best paper candidate。
Graph based Text-Img:GSMN(cvpr'20)
方法

首先分两段输入,text和img。两端分开来说。
text: 用NLP的依存分析解析出来各个word的关系并依据这些关系建图。word embedding用Bi-GRU第i层的avg的hidden state,可能是依存关系的工具给的。
img:用Faster RCNN得到的各个object框,然后用ResNet取feature作为initial representation,用极坐标定点各个object的位置,并以此建图。
以上两步就得到了visual graph和textual graph,接下来进行两次尺度上的matching。
node level matching
(文章说是matching,倒不如说是representation的预处理……)
这里是对不经过图卷积的node表示直接进行matching。$U_{\alpha}$做text node表示矩阵,$V_{\beta}$做visual node 表示矩阵,matching过程如下:
两两计算$v$和$u$的相似度得到相似度矩阵,后在img维度上softmax得到text$\rightarrow$img的权重,并与V相乘,得到了获得text信息的img表示$C_{t->i}$。

img$\rightarrow$text方向上也是这么做,得到$C_{i->t}$。至此,visual node的embedding和graph,以及textual node embedding和graph都准备好了。
structural level matching
这一步倒相对简单了,直接把两个graph送入图卷积神经网络GCN后得到两组feature,然后平均了两两组合输入再过linear得到这个pair的match程度。经过message passing,
先经过图卷积,
在经过两层linear,得到用mlp推断的similarity。
(他这里并没有用$X$表征一幅图,而是用$x$,一般来说$x$表示图中一个节点。原因应该是这里一幅图+图caption就要建两个图,整个数据集有很多个图,他把图看成了“基本单位”。
有了两个方向的匹配度,平均一下就是undirectional真的similarity了。
(有一点奇怪,structural level matching的sim并没有visual node和 textual node的交互……只有node level matching的时候进行了交互融入进去了一点两模态的交互。
文章对此有如下解释:
revise
text GRU,img Faster RCNN+ResNet,node matching获得初始表示,经过图卷积后计算sim,然后进行triplet loss。
loss
也是经典的triplet loss,拉进match pair的距离,拉远不match的,同时也可见整个模型是有监督的
效果
文章方法GSMN。
- 数据集:Flickr30K and MSCOCO,img+caption
- 任务:retrieval
- 测试指标:

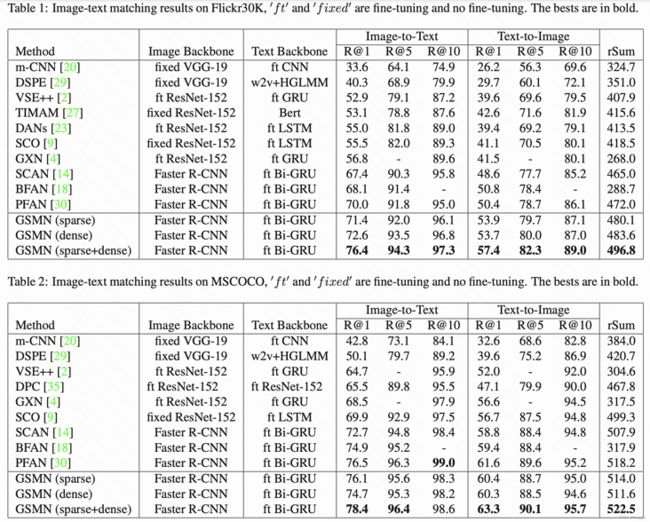
提升很大3%左右。
sparse意思是我用NLP依存关系对textual graph建边;dense指我直接fully connect,不用依存关系了。sparse+dense文章没清楚,可能是有些图sparse有些图dense?
文章只给出了retrieval的结果,没有给更细粒度的semantic segment的效果,只给了他的case study:
由于用的Faster RCNN,还是只能画框来表征object,这种semantic segment是图中textual node与visual node的dot sim得到的。
小结
- 方法有点怪的,除了loss是“比较通用”,node matching其实是对初始表示做个加权,structure matching是自己这一路用mlp做个预测值,只有node matching能勉强说是两模态有信息交流……
- 能实现的仍然是 短语级别 - 图片级别的retrieval,而不是图片obj和word级别的对齐,
- 在retrieval上,与sota相比提升很大
ALBEF nips'21
流程

3个encoder,除了img和text还有multimodal encoder。img encoder是ViT(终于有用ViT的了),text encoder和multimodal encoder都是是bert。
txt和img端得到feature后,再输入multimodal的encoder,然后以输出做loss。
这还没完,这是一个base model,还有一个momentum model(图右侧),momentum model的encoder参数按照running average方法更新,除了base model的3个loss,还有base model和momentum model的loss。
loss
loss有三块,bert的MLM,text-img matching和NCE。MLM还是完形填空,略过。
带监督的nce
带监督的NCE loss的时机在multimodal encoder之前,这也是文章标题说的:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation,他要在fuse之前做align。(但是也没说这样子的好处)
文章直接用img和txt的个encoder的[CLS] token做整个img和txt的表征,进行infoNCE,两个方向上:
再加入监督信息:
matching loss
matching loss是multimodal encoder过后,会输出这一组txt和img是否是一组,这个loss是有监督的
最终的loss就是三部分加起来
与momentum modal的loss
回顾带监督的nce有两个estimation distribution $p_{m}^{i2t}$和$p_{m}^{t2i}$。我base modal有这俩,momentum model也有。文章最小化这两者的KL散度。![]()
为什么要外加个momentum model?
文章给出的理由是:数据大部分是爬虫爬来的,即便是有标签的pair,也只是“weakly correlated”,是有很多噪声,那那些text和img更相关的可能埋没在neg pair里面了。而原本的NCE只认给定的txt和img,但是如果我有个momentum modal,他的参数更新是相对旧的,我就能找到不是标定的txt-img但是“更可能”是有关系的pair了。The image-text pairs used for pre-training are mostly collected from the web and they tend to be noisy. Positive pairs are usually weakly-correlated: the text may contain words that are unrelated to the image, or the image may contain entities that are not described in the text. For ITC learning, negative texts for an image may also match the image’s content. For MLM, there may exist other words different from the annotation that describes the image equally well (or better). However, the one-hot labels for ITC and MLM penalize all negative predictions regardless of their correctness.
To address this, we propose to learn from pseudo-targets generated by the momentum model.个人理解:牵强!可能就是硬为了用上momentum 机制,蹭MoCo的热度……
到此Loss部分结束,简单说是base model的3部分,外加base-momentum的1部分,都是带有监督信息的。
消融实验
TR text retrieval;IR image retrieval。
第1、2行可以看到ITC(image-text constrastive loss)那部分对retrieval影响大~3个点。
选取hard negative pair也能提点1%。
倒数2、3、4行,momentum model和base model机制只提了0.x%。
与baseline的实验
retrieval做法:
During inference, we first compute the feature similarity score sit $c$ for all image-text pairs. Then we take the top-k candidates and calculate their ITM score sit $m$ for ranking

提了很多,但是差距不是很大。分数都非常高95%以上了都。
小结
- 模型是有监督的。
- 使用了ViT,最新的视觉领域的encoder了,数据集也极大,retrieval的结果都达到95%以上了。
- momentum model机制大可不必,参数量直接翻了一倍结果也提升不大
- txt的bert和img的ViT,估计整个模型会很大。
能加强Semantic Align的正则项 ACL'21
论文提出了一个“距离”IAIS,并且提供了最小化此距离的对应loss
距离的提出
文章的输入,是把各个模态的序列合并了起来:$$X=X_V||X_L$$L表示linguistic,V表示visual。并起来以后,再做和transformer self-att一样的操作。但是由于并不是一个模态的了,文章把详细拆成了四个部分:
$S_{LL}$$S_{VV}$是“模态内att;”$S_{LV}$$S_{VL}$是“模态间att”。
接下来,由于假设L和V是对齐的,所以也希望$S_{LL}$$S_{VV}$距离也能够相近:
文章定义了m-KL是双向的KL,从$S_{LL}$到$S_{VV}$一个KL,还有反向一个。并且把这个距离叫做Intra Modal Self-att Distance with annotation (ISDa)。
那这个距离有用没用?
UNITER在训练过程中,随着Recall的增大,ISDa在减小,并且二者皮尔森系数是-0.6,说明是有关联的。
提出的新附加loss
通过用$S_{VL}$和$S_{LV}$“重建”$S_{VV}$和$S_{LL}$,并且与用$S_{VV}$和$S_{LL}$的m-KL来算loss。
重建方法一:
其实就是找att最大的然后记录、转换。
转换过后,新出来的$S_{LL}^s$跟$S_{VV}^s$就和原SLL SVV做m-KL。
重建方法二:
$$S_{VV}^d=\sigma (S_{VL})\sigma (S_{LV})$$
然后还是m-KL拉进$S_{VV}^d$和$S_{LL}^d$和原$S_{VV}$和$S_{LL}$
retrieval实验
刚刚介绍的副loss只用在了fine tune阶段,而且设置了阈值只在符合条件的pair才给计算。(这种计算量巨大)

不过这对比不使用,是有效果的。
sigular指两个for的重建$S_{LL}$,distributed指$S_{VV}^d=\sigma (S_{VL})\sigma (S_{LV})$重建。
小结
- 提出了一个距离以及配套的loss,能够仅在fine tune阶段就提升retrieve的效果
- encoder 是 FasterRCNN,相对老旧,在使用IDSa的时候不方便
- 把$X_V$$X_L$并到一起了做输入了,实际使用会方便吗?
- 由于文章计算资源不够,实验有限。
CAMP(iccv'19)
直来直去的feature fusion。
$V$是FasterRCNN取出来的;$T$是bi-directional GRU取出来的。数据集Flickr30K和COCO。

forward
$T$是text feature、$V$是visual feature。
第一步
进行类似transformer K Q V attention的操作(cross modal message aggregation),只不过这次是$T$和$V$矩阵。$$A=softmax(\frac{(W_vV)^T(W_TT)}{\sqrt d})$$,$$\hat T=AT$$这个操作是对$T$的,对$V$也有相同操作。
对应图上红色。
第二步
再来一次Gated fusion+residual(图中对应绿色)。gate(单个向量)操作:
对于$V$,整体来看是1 $V$和$T$进入gate算门是否被激活 2 与门$G$再做运算做fusion:
⊕ is the fusing operation (elementwise sum)。
这一步文章还单独画了一个图:第三步
再来一次和第一步相同的操作
第四步loss
有了$v*$和$t*$相加后过mlp和sigmoid作为两者是否是pair的预测, 。
。
不过他是以最难二分类loss,就是从所有的vt pair中,只取最接近真pair的那组做0:
消融实验

base model:没有任何cross model的操作,直接用encoder取到的feature做cos retrieve。可以看到也不差。
影响比较大的组件:cross att(红色 11)、fusion residual(绿色的残差链接 12)、mlp预测与ranking loss而不是用cos(蓝色 7)。

消融的结果可以看到:
- 两次两个模态的交互起到了至关重要的角色。
- 就即便是base model的feature直接cos检索,效果也不差,仅差了5个点
小结
总结
- 全部是有监督模型
- 尽管case study上,能够实现sentence word $\leftrightarrow$ img obj级别的align,但是并没有一个model是以此为目的,且给出衡量指标的模型,全部的模型都是检索任务。不过retrieval的提升可以理解为query中的obj与samples的obj对得更齐了使得整体的结果上升了。
- txt端的encoder大部分都是bert,img这边有Faster RCNN和ViT,这些模型retrieval结果的提高,很大程度上是encoder升级换代。
- 没有模型是只用一个Loss就解决掉align问题的,全部都是多角度、多方位的几个loss叠加训练。
- 训练Loss 主要都是triplet loss+其他需求loss构成。