Oceanbase – 千亿级海量数据库
from: http://www.nosqlnotes.net/archives/170
我在数据库大会有一个报告:<<Oceanbase – 千亿级海量数据库>>,ppt已上传到Slideshare上。有一些同学问我,Oceanbase的创新点在哪里?
从大学的数据结构课程可以知道,数据量比较大时,有两种数据结构很常用:哈希表和B+树,分布式系统也是类似的。如下图:
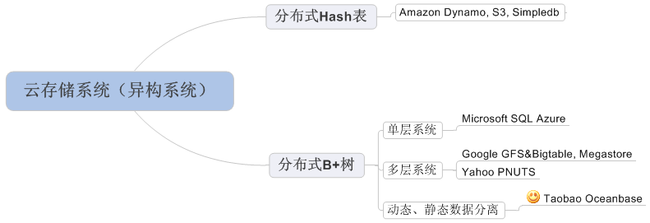
Amazon的系统实现了一个分布式哈希表,而Google Bigtable, Yahoo PNUTS,Microsoft SQL Azure实现了一颗分布式B+树。分布式哈希表实现相对简单,但只支持随机读取;而分布式B+树支持范围查询,但实现比较复杂,主要有两个难点:
1, 状态数据的持久化和迁移。更新操作改变系统的状态,数据库系统中更新操作首先以事务提交日志(MySQL称为binlog, NOSQL称为commit log)写入到磁盘,为了保证可靠性,commit log需要复制多份并保证它们之间的一致性。另外,机器宕机时需要通过commit log记录的状态修改信息将服务迁移到集群中的其它节点。
2, 子表的分裂和合并。B+树实现的难点在于树节点的分裂与合并,在分布式系统中,数据被顺序划分为大小在几十到几百MB大小的数据范围,一般称为子表,相当于B+树结构中的叶子节点。由于每个子表在系统中存储多份,需要保证多个副本之间的分裂点是一致的。由于子表在分裂的同时也有更新操作,保证多个副本之间一致是比较困难的。
对于这两个问题,不同的系统有不同的解决方法:
1, 状态维持。Google Bigtable将状态数据写入到GFS中,由GFS提供可靠性保证,但GFS本身是一个巨大的工程;Yahoo PNUTS将状态数据写入到分布式消息中间件,Yahoo内部称为Yahoo Message Broker;Microsoft SQL Azure直接通过网络将数据复制到多机,由于一台机器服务多个子表,这些子表的副本可能分布在整个集群中,因此,任何两台机器都可能建立数据复制的网络通道,需要处理与这些通道有关的异常情况。
2, 子表分裂。由于底层有GFS保证可靠性,Google Bigtable设计时保证每一个子表同时只被一台机器(Tablet Server)服务;Yahoo PNUTS通过引入复杂的两节点提交(Two-phase commit)协议协调多个副本之间的一致性,使得他们的分裂点相同;Microsoft SQL Azure干脆不支持子表分裂,牺牲一部分扩展性从而简化系统设计。
淘宝Oceanbase设计之初对淘宝的在线存储需求进行分析发现:淘宝的数据总量比较大,未来一段时间,比如五年之内的数据规模为百TB级别,千亿条记录,另外,数据膨胀很快,传统的分库分表对业务造成很大的压力,必须设计自动化的分布式系统;然而,在线存储每天的修改量很小,大多数情况下单机的内存就能存放下。因此,我们采用将动态数据和静态数据分离的办法。动态数据的数据量小,采用集中式的方法解决,这样,状态数据维持从一个分布式的问题转化为单机的问题;静态数据的数据量大,采用分布式的方法解决,因为静态数据基本不变,实现时不需要复杂的线程同步机制,另外,保证静态数据的多个副本之间一致性是比较容易的,简化了子表的分裂和合并操作。通过这样的权衡,淘宝Oceanbase以一种很简单的方式满足了未来一段时间的在线存储需求,并且还获得了一些其它特性,如高效支持跨行跨表事务,这对于淘宝的业务是非常重要的。另外,我们之所以敢于做这样的权衡,还有一个重要的原因:我们内部已经思考了很多关于动态数据由集中式变为分布式的方案,即使我们对需求估计有些偏差,也可以很快修改原有系统进一步提高可扩展性。