Flink Postgres CDC


大数据技术AI
Flink/Spark/Hadoop/数仓,数据分析、面试,源码解读等干货学习资料
128篇原创内容
公众号
1、Flink JDBC 写 Postgres
添加依赖
org.apache.flink
flink-connector-jdbc_2.11
${flink.version}
代码
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class Flink_JDBC_PG {
public static void main(String[] args) {
Configuration conf = new Configuration();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.build();
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(env, settings);
String source = "CREATE TABLE student (\n" +
" id INT,\n" +
" age INT,\n" +
" name STRING,\n" +
" create_time TIMESTAMP(3),\n" +
" WATERMARK FOR create_time AS create_time\n" +
") WITH (\n" +
" 'connector' = 'datagen',\n" +
" 'rows-per-second'='20',\n" +
" 'fields.id.kind'='random' ,\n" +
" 'fields.id.min'='1',\n" +
" 'fields.id.max'='100',\n" +
" 'fields.age.kind'='random',\n" +
" 'fields.age.min'='1',\n" +
" 'fields.age.max'='100',\n" +
" 'fields.name.kind'='random',\n" +
" 'fields.name.length'='3'\n" +
")";
tableEnvironment.executeSql(source);
String sink_sql = "CREATE TABLE sink_student (\n" +
" id INT,\n" +
" age INT,\n" +
" name STRING,\n" +
" PRIMARY KEY (id) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:postgresql://bigdata:5432/postgres',\n" +
" 'table-name' = 'student',\n" +
" 'username'='postgres',\n" +
" 'password'='123456'\n" +
")";
tableEnvironment.executeSql(sink_sql);
String result = "insert into sink_student select id,age,name from student";
tableEnvironment.executeSql(result);
tableEnvironment.executeSql("select * from student").print();
}
}
pg表要提前创建好,要有主键
2、Postgres 配置binlog
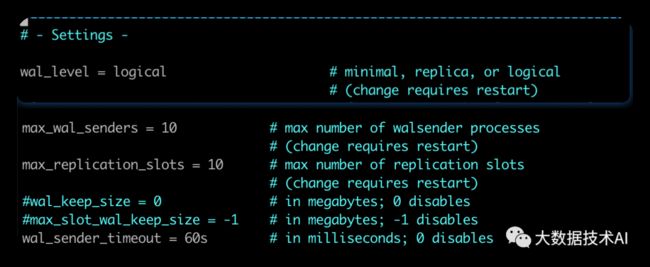
2.1 更改配置文件postgresql.conf
# 更改wal日志方式为logical
wal_level = logical # minimal, replica, or logical
# 更改solts最大数量(默认值为10),flink-cdc默认一张表占用一个slots
max_replication_slots = 20 # max number of replication slots
# 更改wal发送最大进程数(默认值为10),这个值和上面的solts设置一样
max_wal_senders = 20 # max number of walsender processes
# 中断那些停止活动超过指定毫秒数的复制连接,可以适当设置大一点(默认60s)
wal_sender_timeout = 180s # in milliseconds; 0 disable
重新加载配置或重启postgres
[root@bigdata ~]# docker exec -it 7b2d8a96ef4c /bin/bash
root@7b2d8a96ef4c:/# su postgres
postgres@7b2d8a96ef4c:/$ pg_ctl reload
server signaled
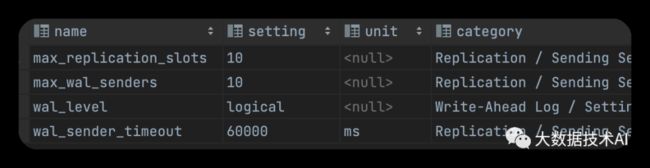
查看参数
select *
from pg_settings
where name in ('wal_level',
'max_replication_slots',
'max_wal_senders',
'wal_sender_timeout');
2.2 给用户复制流权限
-- 给用户复制流权限
ALTER ROLE postgres REPLICATION;
-- 给用户登录数据库权限
GRANT CONNECT ON DATABASE postgres TO postgres;
-- 把当前库public下所有表查询权限赋给用户
GRANT SELECT ON ALL TABLES IN SCHEMA public TO postgres;
2.3 发布表
-- 更新发布所有表标识(可选)
UPDATE pg_publication SET puballtables= false WHERE pubname IS NOT NULL;
-- 查看发布设置
SELECT * FROM pg_publication;
-- 查看那些表发布
SELECT * FROM pg_publication_tables;
-- 创建发布所有表
CREATE PUBLICATION dbz_publication FOR ALL TABLES;
-- 为发布添加一个表
ALTER PUBLICATION dbz_publication ADD TABLE student;
2.4 更改表的复制标识包含更新和删除的值
-- 更改复制标识包含更新和删除之前值
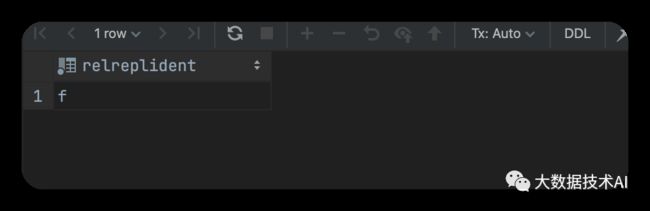
ALTER TABLE student REPLICA IDENTITY FULL;
-- 查看复制标识(为f标识说明设置成功)
SELECT relreplident FROM pg_class WHERE relname = 'student';
2.5 常用pg命令
-- 可以不用重启postgres cluster 就可以生效配置
pg_ctl reload
-- 创建用户
CREATE USER root WITH PASSWORD '123456';
-- 给用户增删改查权限
GRANT INSERT, UPDATE, SELECT, DELETE ON ALL TABLES IN SCHEMA public TO postgres;
-- 给用户复制流权限
ALTER ROLE postgres REPLICATION;
-- 给用户登录数据库权限
GRANT CONNECT ON DATABASE postgres TO postgres;
-- 把当前库public下所有表查询权限赋给用户
GRANT SELECT ON ALL TABLES IN SCHEMA public TO postgres;
UPDATE pg_publication SET puballtables= false WHERE pubname IS NOT NULL;
-- 查看发布设置
SELECT * FROM pg_publication;
-- 查看那些表发布
SELECT * FROM pg_publication_tables;
-- 创建发布所有表
CREATE PUBLICATION dbz_publication FOR ALL TABLES;
-- 为发布添加一个表
ALTER PUBLICATION dbz_publication ADD TABLE student;
-- 更改复制标识包含更新和删除之前值
ALTER TABLE student REPLICA IDENTITY FULL;
-- 查看复制标识(为f标识说明设置成功)
SELECT relreplident FROM pg_class WHERE relname = 'student';
-- 删除slot
SELECT PG_DROP_REPLICATION_SLOT('my_slot');
-- 查询用户连接数
SELECT usename, COUNT(*) FROM pg_stat_activity GROUP BY usename ORDER BY COUNT(*) DESC;
-- 设置用户最大连接数
ALTER ROLE postgres CONNECTION LIMIT 200;
3、Flink Streaming Postgres CDC
3.1 引入依赖
com.ververica
flink-sql-connector-postgres-cdc
2.1.0
3.2 代码
import com.ververica.cdc.connectors.postgres.PostgreSQLSource;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
public class FlinkStream_CDC_PG {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
SourceFunction sourceFunction = PostgreSQLSource.builder()
.hostname("bigdata")
.port(5432)
.database("postgres")
.schemaList("public")
.tableList("public.student")
.username("postgres")
.password("123456")
.slotName("sink_student_cdc1")
.decodingPluginName("pgoutput")
.deserializer(new JsonDebeziumDeserializationSchema())
.build();
DataStreamSource streamSource = env.addSource(sourceFunction);
streamSource.print();
env.execute();
}
}
4、Flink SQL Postgres CDC
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
public class FlinkSql_CDC_PG {
public static void main(String[] args) {
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.useBlinkPlanner()
.build();
TableEnvironment tableEnvironment = TableEnvironment.create(settings);
tableEnvironment.getConfig().getConfiguration().setString("execution.checkpointing.interval", "3s");
String pg_sql = "CREATE TABLE sink_student_cdc1 (\n" +
" id INT,\n" +
" age INT,\n" +
" name STRING\n" +
") WITH (\n" +
" 'connector' = 'postgres-cdc',\n" +
" 'hostname' = '106.52.242.238',\n" +
" 'port' = '5432',\n" +
" 'username' = 'postgres',\n" +
" 'password' = '123456',\n" +
" 'database-name' = 'postgres',\n" +
" 'schema-name' = 'public',\n" +
" 'table-name' = 'student',\n" +
" 'decoding.plugin.name' = 'pgoutput',\n" +
" 'slot.name'='sink_student_cdc1',\n" +
" 'debezium.snapshot.mode' = 'exported'\n" +
")";
tableEnvironment.executeSql(pg_sql);
tableEnvironment.executeSql("select * from sink_student_cdc1").print();
}
}
5、问题汇总
Q1:PSQLException: ERROR: replication slot “flink” is active for PID 974 error
slot.name 要唯一,一张表一个
Q2:使用CDC 2.x版本,只能读取全量数据,无法读取增量(binlog) 数据
CDC 2.0 支持了无锁算法,支持并发读取,为了保证全量数据 + 增量数据的顺序性,依赖Flink 的 checkpoint机制,所以作业需要配置 checkpoint。SQL 作业中配置方式:
Flink SQL> SET 'execution.checkpointing.interval' = '3s';
DataStream 作业配置方式:
env.enableCheckpointing(3000);
PGCDC:更改表的复制标识包含更新和删除
Q3:作业报错 Replication slot “xxxx” is active
- 前往 Postgres 中手动执行以下命令
select pg_drop_replication_slot('rep_slot');
- pg source with 参数中添加
'debezium.slot.drop.on.stop' = 'true',在作业停止后自动清理 slot
Q4:什么时候使用 flink-sql-connector-xxx.jar,什么时候使用 flink-connector-xxx.jar,两者有啥区别?
Flink CDC 项目中各个connector的依赖管理和Flink 项目中 connector 保持一致。
flink-sql-connector-xx 是胖包,除了connector的代码外,还把 connector 依赖的所有三方包 shade 后打入,提供给 SQL 作业使用,用户只需要在 lib目录下添加该胖包即可。
flink-connector-xx 只有该 connector 的代码,不包含其所需的依赖,提供 datastream 作业使用,用户需要自己管理所需的三方包依赖,有冲突的依赖需要自己做 exclude, shade 处理。
Q5:decoding.plugin.name 无法访问文件 “decoderbufs”: 没有那个文件或目录
根据Postgres服务上安装的插件确定。支持的插件列表如下:
-
decoderbufs(默认值)
-
wal2json
-
wal2json_rds
-
wal2json_streaming
-
wal2json_rds_streaming
-
pgoutput
Q6:SlotName
Slot names must conform to PostgreSQL replication slot naming rules, which state: “Each replication slot has a name, which can contain lower-case letters, numbers, and the underscore character.”
Q7:snapshot.mode
initial- 只有当逻辑服务器名称没有记录偏移量时,连接器才会执行快照。
always- 每次启动连接器时,连接器都会执行快照。
never- 连接器从不执行快照。当连接器以这种方式配置时,其启动时的行为如下。如果卡夫卡偏移量主题中之前存储的LSN,连接器将继续从该位置流式传输更改。如果没有存储LSN,连接器将从服务器上创建PostgreSQL逻辑复制插槽的时间点开始流式传输更改。只有当您知道所有感兴趣的数据仍然反映在WAL中时,never快照模式才有用。
initial_only-连接器执行初始快照,然后停止,而不处理任何后续更改。
exported- 连接器根据创建复制插槽的时间点执行快照。这是以无锁方式执行快照的绝佳方式。
