FlinkCDC+Hudi+Hive大数据实时入湖基础实战
目录
前言:新架构与湖仓一体
一、版本说明
二、编译打包hudi 0.10.0版本
1.使用git克隆github上最新的master
2.编译打包
三、创建flink工程
1.pom文件主要内容
2.checkpoint
3.flinkcdc代码
4.hudi代码(具体参数可参考官网)
5.捕获mysql变更并写入到hudi
6.执行语句
四、查看hudi文件目录
1.mysql未插入数据
2.插入数据后查看hdfs分区内容
五、hive查询hudi数据
1.hive准备工作
2.登录hive客户端连接工具
3.select * 查询
4.select count(*) 查询
前言:新架构与湖仓一体
通过湖仓一体、流批一体,准实时场景下做到了:数据同源、同计算引擎、同存储、同计算口径。数据的时效性可以到分钟级,能很好的满足业务准实时数仓的需求。下面是架构图:

MySQL 数据通过 Flink CDC 进入到 Kafka。之所以数据先入 Kafka 而不是直接入 Hudi,是为了实现多个实时任务复用 MySQL 过来的数据,避免多个任务通过 Flink CDC 接 MySQL 表以及 Binlog,对 MySQL 库的性能造成影响。
通过 CDC 进入到 Kafka 的数据除了落一份到离线数据仓库的 ODS 层之外,会同时按照实时数据仓库的链路,从 ODS->DWD->DWS->OLAP数据库,最后供报表等数据服务使用。实时数仓的每一层结果数据会准实时的落一份到离线数仓,通过这种方式做到程序一次开发、指标口径统一,数据统一。
从架构图上,可以看到有一步数据修正 (重跑历史数据) 的动作,之所以有这一步是考虑到:有可能存在由于口径调整或者前一天的实时任务计算结果错误,导致重跑历史数据的情况。
而存储在 Kafka 的数据有失效时间,不会存太久的历史数据,重跑很久的历史数据无法从 Kafka 中获取历史源数据。再者,如果把大量的历史数据再一次推到 Kafka,走实时计算的链路来修正历史数据,可能会影响当天的实时作业。所以针对重跑历史数据,会通过数据修正这一步来处理。
总体上说,这个架构属于 Lambda 和 Kappa 混搭的架构。流批一体数据仓库的各个数据链路有数据质量校验的流程。第二天对前一天的数据进行对账,如果前一天实时计算的数据无异常,则不需要修正数据,Kappa 架构已经足够。
(本节内容,引用自:37 手游基于 Flink CDC + Hudi 湖仓一体方案实践)
一、版本说明
flink 1.13.1
flinkcdc 2.0.2
hudi 0.10.0
hive 3.1.2
mysql 5.7+
代码环境 idea
二、编译打包hudi 0.10.0版本
1.使用git克隆github上最新的master
进入文件夹,右键git bash here进入git命令行模式
克隆hudi源码 git clone https://github.com/apache/hudi.git
切换到0.10.0分支 git checkout release-0.10.0
2.编译打包
先在 $hudi_home 目录下执行命令 mvn clean install -DskipTests
然后进入 packaging/hudi-flink-bundle 目录,按照如下操作打 bundle jar
mvn install -DskipTests -Drat.skip=true -Pflink-bundle-shade-hive3
# 如果是 hive2 需要使用 profile -Pflink-bundle-shade-hive2
# 如果是 hive1 需要使用 profile -Pflink-bundle-shade-hive1
#注意1:hive1.x现在只能实现同步metadata到hive,而无法使用hive查询,如需查询可使用spark查询hive外表的方法查询。
#注意2: 使用-Pflink-bundle-shade-hive x,需要修改profile中hive的版本为集群对应版本(只需修改profile里的hive版本)。修改位置为packaging/hudi-flink-bundle/pom.xml最下面的对应profile段,找到后修改profile中的hive版本为对应版本即可。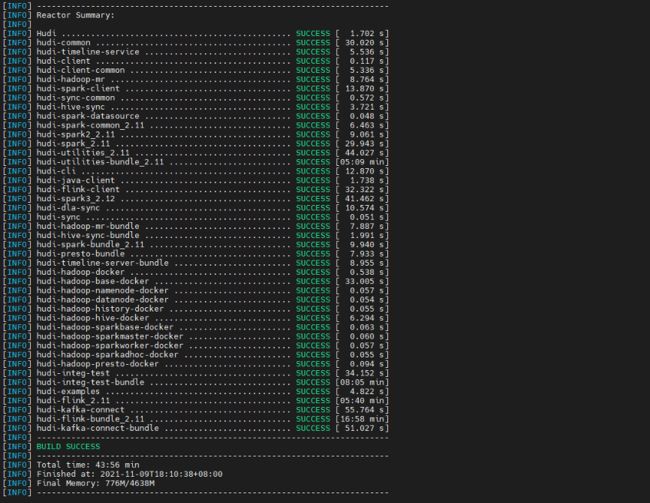
( 如果遇到hudi-integ-test或者hudi-integ-test-bundle编译失败,可进入根目录下pom文件中将这两个module注掉)
三、创建flink工程
1.pom文件主要内容
UTF-8
UTF-8
UTF-8
1.8
1.8
1.8
2.12
1.13.1
5.1.44
org.apache.hudi
hudi-flink-bundle_2.12
0.10.0-rc2
com.ververica
flink-connector-mysql-cdc
2.0.2
org.apache.flink
flink-clients_2.12
${flink.version}
org.apache.flink
flink-java
${flink.version}
org.apache.flink
flink-streaming-java_2.12
${flink.version}
org.apache.flink
flink-jdbc_2.12
1.10.3
org.apache.flink
flink-connector-jdbc_2.12
${flink.version}
org.apache.flink
flink-runtime-web_2.12
${flink.version}
org.apache.flink
flink-table-planner_2.12
${flink.version}
org.apache.flink
flink-table-common
${flink.version}
org.apache.flink
flink-table-api-java-bridge_2.12
${flink.version}
org.apache.flink
flink-table-api-java
${flink.version}
org.apache.flink
flink-table-planner-blink_2.12
${flink.version}
org.apache.hadoop
hadoop-hdfs
2.6.0
org.apache.hadoop
hadoop-client
2.6.0
org.apache.hadoop
hadoop-common
2.6.0
mysql
mysql-connector-java
${mysql-connector.version}
2.checkpoint
//1.1 开启CK并指定状态后端为FS
env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("hdfs://hadoop1:8020/flink/checkpoints/hudi-flink"));
env.enableCheckpointing(60000L); //头和头
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(30000L);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(30000L); //尾和头
3.flinkcdc代码
String source_table = "CREATE TABLE mysql_users (\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED ,\n" +
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3)\n" +
" ) WITH (\n" +
" 'connector'= 'mysql-cdc',\n" +
" 'hostname'= '*.*.*.*',\n" +
" 'port'= '3306',\n" +
" 'username'= 'root',\n" +
" 'password'='123456',\n" +
" 'server-time-zone'= 'Asia/Shanghai',\n" +
" 'debezium.snapshot.mode'='initial',\n" +
" 'database-name'= 'test',\n" +
" 'table-name'= 'users_cdc'\n" +
")";4.hudi代码(具体参数可参考官网)
String sink_table = "CREATE TABLE hudi_users (\n" +
" id BIGINT,\n" +
" name VARCHAR(20),\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3),\n" +
" `partition` VARCHAR(20),\n" +
" primary key(id) not enforced --必须指定uuid 主键 \n" +
")\n" +
"PARTITIONED BY (`partition`)\n" +
"with(\n" +
" 'connector'='hudi',\n" +
" 'path' = 'hdfs://hadoop1:8020/hudi/hudi_users',\n" +
" 'hoodie.datasource.write.recordkey.field'= 'id', -- 主键\n" +
" 'write.precombine.field'= 'ts', -- 自动precombine的字段\n" +
" 'write.tasks'= '1',\n" +
" 'compaction.tasks'= '1',\n" +
" 'write.rate.limit'= '2000', -- 限速\n" +
" 'table.type'= 'MERGE_ON_READ', -- 默认COPY_ON_WRITE,可选MERGE_ON_READ\n" +
" 'compaction.async.enabled'= 'true', -- 是否开启异步压缩\n" +
" 'compaction.trigger.strategy'= 'num_commits', -- 按次数压缩\n" +
" 'compaction.delta_commits'= '1', -- 默认为5\n" +
" 'changelog.enabled'= 'true', -- 开启changelog变更\n" +
" 'read.streaming.enabled'= 'true', -- 开启流读\n" +
" 'read.streaming.check-interval'= '3', -- 检查间隔,默认60s\n" +
" 'hive_sync.enable'='true', -- required,开启hive同步功能\n" +
" 'hive_sync.mode' = 'hms', -- required, 将hive sync mode设置为hms, 默认jdbc\n" +
" 'hive_sync.metastore.uris' = 'thrift://hadoop1:9083', -- metastore的端口\n" +
" 'hive_sync.table' = 'hudi_users', -- hive新建表名\n" +
" 'hive_sync.db' = 'hudi', -- hive新建数据库名\n" +
" 'hive_sync.support_timestamp' = 'true' -- 兼容hive timestamp类型\n" +
")";5.捕获mysql变更并写入到hudi
String transform_sql = "insert into hudi_users select *, DATE_FORMAT(birthday, 'yyyyMMdd') from mysql_users";6.执行语句
tableEnv.executeSql(source_table);
tableEnv.executeSql(sink_table);
tableEnv.executeSql(transform_sql);四、查看hudi文件目录
1.mysql未插入数据
任务启动,此时mysql中未插入数据,hdfs上自动创建目录/hudi/hudi_users/
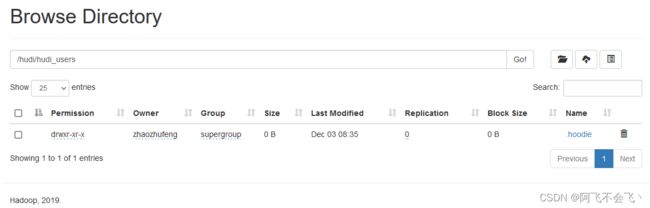
点击.hoodie
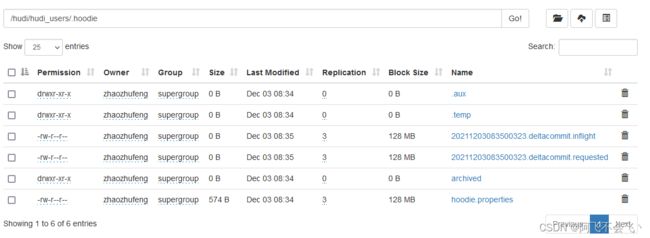
Hudi状态文件说明:
(1)requested:表示一个动作已被安排,但尚未启动
(2)inflight:表示当前正在执行操作
(3)completed:表示在时间线上完成了操作
2.插入数据后查看hdfs分区内容

观察hdfs变化,此时新增一个分区目录
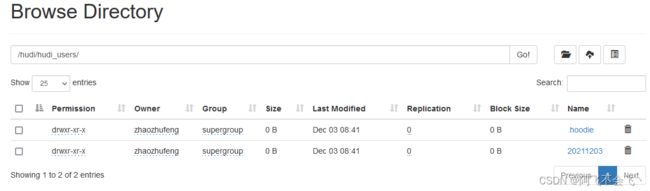
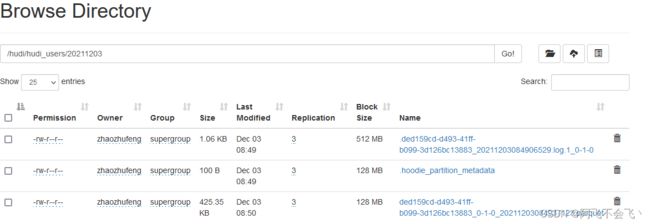
说明:hudi分区文件以及.log和.parquet文件都已生成
两种文件区别:Hudi会在DFS分布式文件系统上的basepath基本路径下组织成目录结构。每张对应的表都会成多个分区,这些分区是包含该分区的数据文件的文件夹,与hive的目录结构非常相似。在每个分区内,文件被组织成文件组,文件id为唯一标识。每个文件组包含多个切片,其中每个切片包含在某个提交/压缩即时时间生成的基本列文件(parquet文件),以及自生成基本文件以来对基本文件的插入/更新的一组日志文件(*.log)。Hudi采用MVCC设计,其中压缩操作会将日志和基本文件合并成新的文件片,清理操作会将未使用/较旧的文件片删除来回收DFS上的空间。
五、hive查询hudi数据
1.hive准备工作
1)在 Hive 服务器导入 Hudi 包
在 Hive 根目录下创建 auxlib/ 文件夹,并把hudi install后packaging/hudi-hadoop-mr-bundle/target目录下的hudi-hadoop-mr-bundle-0.10.0-SNAPSHOT.jar 放入其中,否则会报
FAILED: SemanticException Cannot find class 'org.apache.hudi.hadoop.HoodieParquetInputFormat'2)将 hudi-hadoop-mr-bundle-0.9.0xxx.jar , hudi-hive-sync-bundle-0.9.0xx.jar 放到 hiveserver 节点的lib目录下;
修改 hive-site.xml 找到 hive.default.aux.jars.path 以及 hive.aux.jars.path 这两个配置项,将第一步中的jar包全路径给配置上去;
hive.default.aux.jars.path
file:///opt/hive-3.1.2/lib/hudi-hadoop-mr-bundle-0.9.0xxx.jar,file:///opt/hive-3.1.2/lib/hudi-hive-sync-bundle-0.9.0xx.jar
hive.aux.jars.path
file:///opt/hive-3.1.2/lib/hudi-hadoop-mr-bundle-0.9.0xxx.jar,file:///opt/hive-3.1.2/lib/hudi-hive-sync-bundle-0.9.0xx.jar
3)重启hive metastore服务和hiveserver2服务;
4) 设置set hive.input.format= org.apache.hadoop.hive.ql.io.HiveInputFormat;
2.登录hive客户端连接工具
使用DBeaver工具连接hive客户端
发现自动新增了hudi库和hudi_user_ro、hudi_user_rt两张表
ro表和rt表区别:
ro 表全称 read oprimized table,对于 MOR 表同步的 xxx_ro 表,只暴露压缩后的 parquet。其查询方式和COW表类似。设置完 hiveInputFormat 之后 和普通的 Hive 表一样查询即可;
rt表示增量视图,主要针对增量查询的rt表;
ro表只能查parquet文件数据, rt表 parquet文件数据和log文件数据都可查;
3.select * 查询
查询hudi_user_ro表

查询hudi_user_rt表

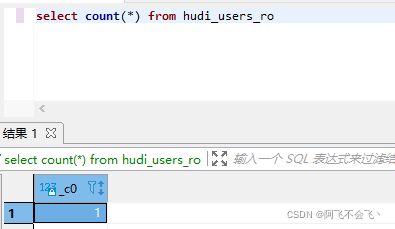
4.select count(*) 查询
查询hudi_user_ro表
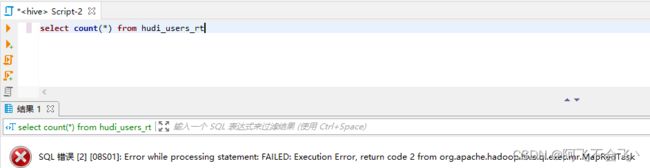
查询hudi_user_rt表,发现有异常出现,经过查阅资料,hudi社区会在以后的版本修复
参考资料
Flink CDC + Hudi + Hive + Presto构建实时数据湖最佳实践_Focus on Bigdata-CSDN博客
HUDI FLINK 答疑解惑 · 语雀
用Flink+hudi实现仓湖一体架构,是一种什么体验? - 知乎