【SQL】SQL的基础语法
想要成为一名数据研发工程师,SQL是必会的技能。数仓建模过程中用到Hive,其实也是通过写类SQL的语句,通过底层的引擎将其翻译成MapReduce程序,减少了程序员的开发量。除此之外,Spark、Flink等计算框架也支持使用SQL来实现查询。所以在面试的过程中,SQL是必须要考察的内容。今天先分享SQL的基础语法,而窗口函数是重中之重,后面单独写一篇进行讲解。
1.语法
SELECT 查询列表
FROM 表名或视图列表
WHERE 条件表达式
GROUP BY 字段名 HAVING 条件表达式
ORDER BY 字段 ASC|DESC
LIMIT m,n;
说明:
- 如果SELECT后面是 *,那么表示查询所有字段
- SELECT后面的查询列表,可以是表中的字段,常量值,表达式,函数
- 查询的结果是一个虚拟的表
- select语句,可以包含5种子句:依次是where、 group by、having、 order by、limit必须照这个顺序。
2.关联查询
作用:从2张或多张表中,取出有关联的数据。
关联查询一共有几种情况:
- 内连接:INNER JOIN 、CROSS JOIN
- 外连接:左外连接(LEFT OUTER JOIN)、右外连接(RIGHT OUTER JOIN)、全外连接(FULL OUTER JOIN)
- 自连接:当 table1 和 table2 本质上是同一张表,只是用取别名的方式虚拟成两张表以代表不同的意义
说明:
- 连接 n 个表,至少需要 n-1 个连接条件。 例如:连接三个表,至少需要两个连接条件。
- 当两个关联查询的表如果有字段名字相同,并且要查询中涉及该关联字段,那么需要使用表名前缀加以区分
- 当如果表名比较长时,可以给表取别名,简化 SQL 语句

select <select_list>
from tableA A
inner join tableB B
on A.key=B.key;

select <select_list>
from tableA A
left join tableB B
on A.key=B.key;
select <select_list>
from tableA A
right join tableB B
on A.key=B.key;
select <select_list>
from tableA A
left join tableB B
on A.key=B.key
where B.key is null;

select <select_list>
from tableA A
right join tableB B
on A.key=B.key
where A.key is null;

select <select_list>
from tableA A
left join tableB B
on A.key=B.key
union
select <select_list>
from tableA A
right join tableB B
on A.key=B.key;

select <select_list>
from tableA A
left join tableB B
on A.key=B.key
where B.key is null
union
select <select_list>
from tableA A
right join tableB B
on A.key=B.key
where A.key is null;
2.1 笛卡尔积
定义:将两(或多)个表的所有行进行组合,连接后的行数为两(或多)个表的乘积数。
在 MySQL 中,如果缺少关联条件或者关联条件不准确,则会出现笛卡尔积。
注:外连接必须写关联条件,否则报语法错误。
2.2 关联条件
表连接的约束条件可以有三种方式:WHERE, ON, USING
- WHERE:适用于所有关联查询。
- ON:只能和 JOIN 一起使用,只能写关联条件。虽然关联条件可以并到WHERE中和其他条件一起写,但分开写可读性更好。
- USING:只能和 JOIN 一起使用,而且要求两个关联字段在关联表中名称一致,而且只能表示关联字段值相等。
#关联条件
#把关联条件写在where后面
SELECT ename,dname FROM t_employee,t_department WHERE t_employee.dept_id=t_department.did;
#把关联条件写在on后面,只能和JOIN一起使用
SELECT ename,dname FROM t_employee JOIN t_department ON t_employee.dept_id=t_department.did;
#把关联字段写在using()中,只能和JOIN一起使用
SELECT ename,basic_salary FROM t_employee INNER JOIN t_salary USING(eid);
#n张表关联,需要n-1个关联条件
#查询员工姓名,基本工资,部门名称
SELECT ename,basic_salary,dname FROM t_employee,t_department,t_salary
WHERE t_employee.dept_id=t_department.did AND t_employee.eid=t_salary.eid;
SELECT ename,basic_salary,dname FROM t_employee JOIN t_department JOIN t_salary
ON t_employee.dept_id=t_department.did AND t_employee.eid=t_salary.eid;
2.3 内连接

有两种,显式的和隐式的,返回连接表中符合连接条件和查询条件的数据行
格式:
隐式:SELECT [cols_list] from 表1,表2 where [condition]
显式:SELECT [cols_list] from 表1 JOIN 表2 ON [关联条件] where [其他筛选条件]
SELECT dep.dept_id,dep.name,emp.id,emp.name
FROM t_employee emp JOIN t_department dep
ON emp.dept_id=dep.dept_id;

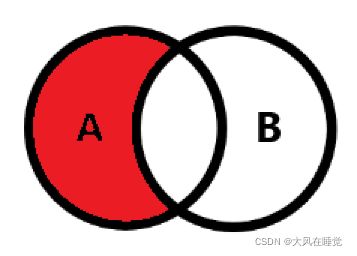
2.4 外连接
外连接分为左外连接,右外连接,
- 左外连接(LEFT OUTER JOIN),简称左连接(LEFT JOIN)
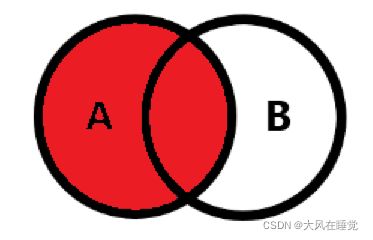
#查询所有部门信息以及该部门员工信息
SELECT did,dname,eid,ename
FROM t_department LEFT OUTER JOIN t_employee
ON t_department.did = t_employee.dept_id;

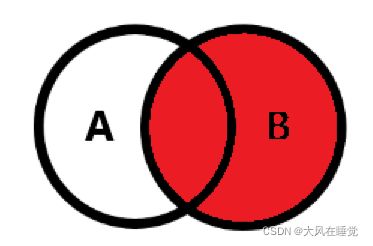
- 右外连接(RIGHT OUTER JOIN),简称右连接(RIGHT JOIN)

#查询所有员工信息,以及员工的部门信息
SELECT eid,ename,did,dname
FROM t_department RIGHT OUTER JOIN t_employee
ON t_employee.dept_id = t_department.did;

- 全外连接(FULL OUTER JOIN),简称全连接(FULL JOIN)。MySQL 不支持 FULL JOIN,但是可以用 left join union right join代替。

#查询所有部门信息和员工信息
SELECT did,dname,eid,ename
FROM t_department LEFT OUTER JOIN t_employee
ON t_department.did = t_employee.dept_id
UNION
SELECT did,dname,eid,ename
FROM t_department RIGHT OUTER JOIN t_employee
ON t_department.did = t_employee.dept_id;

2.5 自连接
当 table1 和 table2 本质上是同一张表,只是用取别名的方式虚拟成两张表以代表不同的意义。然后两个表再进行内连接,外连接等查询。
#自连接
#查询员工姓名以及领导姓名,仅显示有领导的员工
SELECT emp.ename,mgr.ename
FROM t_employee AS emp, t_employee AS mgr
WHERE emp.mid = mgr.eid;
#查询员工姓名以及领导姓名,仅显示有领导的员工
SELECT emp.ename,mgr.ename
FROM t_employee AS emp JOIN t_employee AS mgr
ON emp.mid = mgr.eid;
#查询所有员工姓名及其领导姓名
SELECT emp.ename,mgr.ename
FROM t_employee AS emp LEFT JOIN t_employee AS mgr
ON emp.mid = mgr.eid;
3.select 的五个子句
3.1 where 条件查询
设置条件,对记录进行筛选。例如查询id=1的学生信息:
select * from stu_tb where id=1;
3.2 group by 分组查询
很多情况下,用户都需要进行一些汇总操作,比如统计整个公司的人数或者统计每一个部门的人数等。在分组之后,由于一个分组有多行数据,所以必须要进行聚合才能得到1对1的答案进行输出。聚合函数有如下几种:
- AVG(【DISTINCT】 expr):返回 expr 的平均值
- COUNT(【DISTINCT】 expr):返回 expr 的非NULL值的数目
- MIN(【DISTINCT】 expr):返回 expr 的最小值
- MAX(【DISTINCT】 expr):返回 expr 的最大值
- SUM(【DISTINCT】 expr):返回 expr 的总和
#聚合函数
#AVG(【DISTINCT】 expr) 返回expr的平均值
SELECT AVG(basic_salary) FROM t_salary;
#COUNT(【DISTINCT】 expr)返回expr的非NULL值的数目
#统计员工总人数
SELECT COUNT(*) FROM t_employee;#count(*)统计的是记录数
#统计员工表的员工所在部门数
SELECT COUNT(dept_id) FROM t_employee;#统计的是非NULL值
SELECT COUNT(DISTINCT dept_id) FROM t_employee;#统计的是非NULL值,并且去重
#MIN(【DISTINCT】 expr)返回expr的最小值
#查询最低基本工资值
SELECT MIN(basic_salary) FROM t_salary;
#MAX(【DISTINCT】 expr)返回expr的最大值
#查询最高基本工资值
SELECT MAX(basic_salary) FROM t_salary;
#查询最高基本工资与最低基本工资的差值
SELECT MAX(basic_salary)-MIN(basic_salary) FROM t_salary;
#SUM(【DISTINCT】 expr)返回expr的总和
#查询基本工资总和
SELECT SUM(basic_salary) FROM t_salary;
上面的聚合函数是对整个表格使用的。如果加上 group by,可以实现按照部门统计等操作。
#group by + 聚合函数
#统计每个部门的人数
SELECT dept_id,COUNT(*) FROM t_employee
GROUP BY dept_id;
#统计每个部门的平均基本工资
SELECT emp.dept_id,AVG(s.basic_salary )
FROM t_employee AS emp,t_salary AS s
WHERE emp.eid = s.eid
GROUP BY emp.dept_id;
#统计每个部门的年龄最大者
SELECT dept_id,MAX(birthday) FROM t_employee GROUP BY dept_id;
#统计每个部门基本工资最高者
SELECT emp.dept_id,MAX(s.basic_salary )
FROM t_employee AS emp,t_salary AS s
WHERE emp.eid = s.eid
GROUP BY emp.dept_id;
#统计每个部门基本工资之和
SELECT emp.dept_id,SUM(s.basic_salary )
FROM t_employee AS emp,t_salary AS s
WHERE emp.eid = s.eid
GROUP BY emp.dept_id;
注意:
- 用 count(*),count(1) 谁好呢?其实,对于 MyISAM引擎的表,没有区别的。这种引擎内部有一计数器在维护着行数。对于 InnoDB 的表,用 count(*) 直接读行数,效率很低,因为 InnoDB 真的要去数一遍。
- 在SELECT 列表中所有未包含在组函数中的列都应该是包含在 GROUP BY 子句中的,换句话说,SELECT列表中最好不要出现GROUP BY子句中没有的列。
3.3 having 筛选
having与where类似,可筛选数据。但也有不同点,不同点如下:
- where 针对表中的列发挥作用,查询数据;having 针对查询结果中的列发挥作用,筛选数据
- where 后面不能写分组函数,而 having 后面可以使用分组函数
- having 只用于 group by 分组统计语句
#按照部门统计员工人数,仅显示部门人数少于3人的
SELECT dept_id,COUNT(*) AS c
FROM t_employee
WHERE dept_id IS NOT NULL
GROUP BY dept_id
HAVING c <3;
3.4 order by 排序
按一个或多个字段对查询结果进行排序。用法:order by col1,col2,col3…
- 先按col1排序如果col1相同就按照col2排序,依次类推。
- col1,col2,col3可以是select后面的字段也可以不是。
- 默认是升序,也可以在字段后面加asc显示说明是升序,desc为降序。
- order by 后面除了跟1个或多个字段,还可以写表达式,函数,别名等。
#统计每个部门的平均基本工资,并按照平均工资降序排列
SELECT emp.dept_id,AVG(s.basic_salary)
FROM t_employee AS emp,t_salary AS s
WHERE emp.eid = s.eid
GROUP BY emp.dept_id
ORDER BY AVG(s.basic_salary) DESC;
3.5 limit 分页
用法:limit m,n
- m 表示从下标为 m 的记录开始查询,第一条记录下标为 0
- n 表示取出 n 条出来,如果从 m 开始不够 n 条了,就有几条取几条。
- m=(page-1)*n,page 是页码,n 表示每页显示的条数。例如:第一页limit 0,n。第二页limit n,n。依次类推,得出公式limit (page-1)*n , n
#统计每个部门的平均基本工资,并显示前三名
SELECT emp.dept_id,AVG(s.basic_salary)
FROM t_employee AS emp,t_salary AS s
WHERE emp.eid = s.eid
GROUP BY emp.dept_id
ORDER BY AVG(s.basic_salary) DESC
LIMIT 0,3;
4.子查询
某些情况下,当进行一个查询时,需要的条件或数据要用另外一个 select 语句的结果,这个时候,就要用到子查询。例如求比张三工资高的员工。一般根据子查询的嵌入位置分为,where型子查询,from型子查询,exists型子查询。
4.1 where 型子查询
where 型子查询即把内层 sql 语句查询的结果作为外层 sql 查询的条件。
-
子查询要包含在括号内。
-
建议将子查询放在比较条件的右侧。
-
单行操作符对应单行子查询,多行操作符对应多行子查询。
-
对于单行操作符,右边子查询必须返回的是单个值,单行比较运算符(=,>,>=,<,<=,<>)
-
对于多行操作符,右边子查询可以返回多行,但必须是单列,ALL,ANY,IN 其中,ALL和ANY运算符必须与单行比较运算符(=,>,>=,<,<=,<>)结合使用。
-
IN:等于任何一个
-
ALL:和子查询返回的所有值比较。例如:sal>ALL(1,2,3) 等价于 sal>1 && sal>2 &&sal>3,即大于所有。
-
ANY:和子查询返回的任意一个值比较。例如:sal>ANY(1,2,3)等价于sal>1 or sal>2 or sal>3,即大于任意一个就可以。
-
EXISTS:判断子查询是否有返回结果(不关心具体行数和内容),如果返回则为TRUE,否则为FALSE。
-
-
#查询和张三,李四在同一个部门的员工
SELECT * FROM t_employee
WHERE dept_id IN(SELECT dept_id FROM t_employee WHERE ename='张三' OR ename = '李四');
#查询全公司工资最高的员工编号,基本工资
#方法一
SELECT eid,basic_salary FROM t_salary
WHERE basic_salary = (SELECT MAX(basic_salary) FROM t_salary);
#方法二
SELECT eid,basic_salary FROM t_salary
WHERE basic_salary >= ALL(SELECT basic_salary FROM t_salary);
4.2 from 型子查询
from 型子查询即把内层 sql 语句查询的结果作为临时表供外层 sql 语句再次查询。
#找出比部门平均工资高的员工编号,基本工资
SELECT t_employee.eid,basic_salary
FROM t_salary INNER JOIN t_employee INNER JOIN (
SELECT emp.dept_id AS did,AVG(s.basic_salary) AS avg_salary
FROM t_employee AS emp,t_salary AS s
WHERE emp.eid = s.eid
GROUP BY emp.dept_id) AS temp
ON t_salary.eid = t_employee.eid AND t_employee.dept_id = temp.did
WHERE t_salary.basic_salary > temp.avg_salary;
4.3 exists 型子查询
exists 型子查询把外层的查询结果拿到内层,看内层的查询是否成立。
#查询部门信息,该部门必须有员工
SELECT * FROM t_department
WHERE EXISTS (SELECT * FROM t_employee WHERE t_employee.dept_id = t_department.did);
欢迎关注公众号。
