【算法】并查集(Java)
今天学习一种新的数据结构并查集。“并”表示合并,“查”表示查找,“集”表示集合。其基本思想是用 father[i] 表示元素 i 的父节点。例如 father[1] = 2 表示元素 1 的父节点是 2。如果 father[i] = i,那么说明 i 是根节点,根节点作为一个集合的标识,如下图表示两个集合,它们的根节点分别是 1 和 5。当然,如果不使用数组来记录,而使用 map 来记录,那么可以使用 father.get(i) = null 来表示根节点。
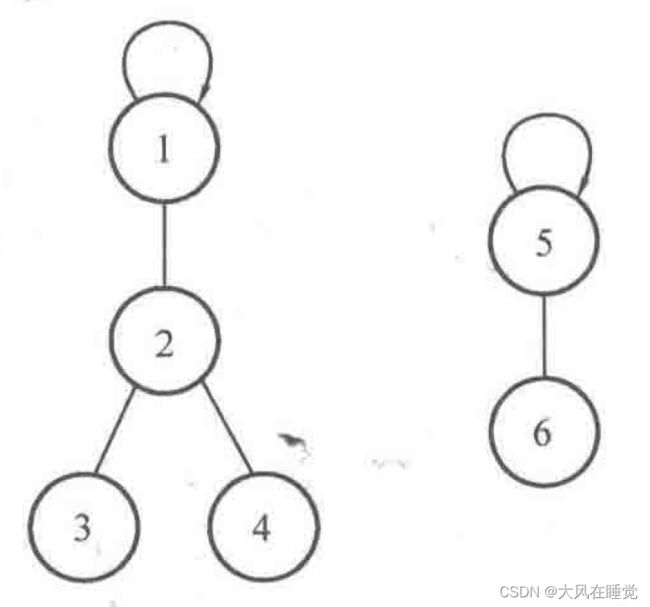
1.并查集的基本操作
下面定义了并查集的类,并实现了基本操作。
class UnionFind {
// 用 Map 在存储并查集,表达的含义是 key 的父节点是 value
private Map<Integer,Integer> father;
// 0.构造函数初始化
public UnionFind(int n) {
father = new HashMap<Integer,Integer>();
for (int i = 0; i < n; i++) {
father.put(i, null);
}
}
// 1.添加:初始加入时,每个元素都是一个独立的集合,因此
public void add(int x) { // 根节点的父节点为null
if (!father.containsKey(x)) {
father.put(x, null);
}
}
// 2.查找:反复查找父亲节点。
public int findFather(int x) {
int root = x; // 寻找x祖先节点保存到root中
while(father.get(root) != null){
root = father.get(root);
}
while(x != root){ // 路径压缩,把x到root上所有节点都挂到root下面
int original_father = father.get(x); // 保存原来的父节点
father.put(x,root); // 当前节点挂到根节点下面
x = original_father; // x赋值为原来的父节点继续执行刚刚的操作
}
return root;
}
// 3.合并:把两个集合合并为一个,只需要把其中一个集合的根节点挂到另一个集合的根节点下方
public void union(int x, int y) { // x的集合和y的集合合并
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY){ // 节点联通只需要一个共同祖先,无所谓谁是根节点
father.put(rootX,rootY);
}
}
// 4.判断:判断两个元素是否同属一个集合
public boolean isConnected(int x, int y) {
return find(x) == find(y);
}
}
2.练习:力扣721. 账户合并[1]
给定一个列表 accounts,每个元素 accounts[i] 是一个字符串列表,其中第一个元素 accounts[i][0] 是 名称 (name),其余元素是 emails 表示该账户的邮箱地址。
现在,我们想合并这些账户。如果两个账户都有一些共同的邮箱地址,则两个账户必定属于同一个人。请注意,即使两个账户具有相同的名称,它们也可能属于不同的人,因为人们可能具有相同的名称。一个人最初可以拥有任意数量的账户,但其所有账户都具有相同的名称。
合并账户后,按以下格式返回账户:每个账户的第一个元素是名称,其余元素是 按字符 ASCII 顺序排列 的邮箱地址。账户本身可以以 任意顺序 返回。
示例 1:
输入:accounts = [["John", "[email protected]", "[email protected]"], ["John", "[email protected]"], ["John", "[email protected]", "[email protected]"], ["Mary", "[email protected]"]]
输出:[["John", '[email protected]', '[email protected]', '[email protected]'], ["John", "[email protected]"], ["Mary", "[email protected]"]]
解释:
第一个和第三个 John 是同一个人,因为他们有共同的邮箱地址 "[email protected]"。
第二个 John 和 Mary 是不同的人,因为他们的邮箱地址没有被其他帐户使用。
可以以任何顺序返回这些列表,例如答案 [['Mary','[email protected]'],['John','[email protected]'],
['John','[email protected]','[email protected]','[email protected]']] 也是正确的。
示例 2:
输入:accounts = [["Gabe","[email protected]","[email protected]","[email protected]"],["Kevin","[email protected]","[email protected]","[email protected]"],["Ethan","[email protected]","[email protected]","[email protected]"],["Hanzo","[email protected]","[email protected]","[email protected]"],["Fern","[email protected]","[email protected]","[email protected]"]]
输出:[["Ethan","[email protected]","[email protected]","[email protected]"],["Gabe","[email protected]","[email protected]","[email protected]"],["Hanzo","[email protected]","[email protected]","[email protected]"],["Kevin","[email protected]","[email protected]","[email protected]"],["Fern","[email protected]","[email protected]","[email protected]"]]
解答如下:
class Solution {
public List<List<String>> accountsMerge(List<List<String>> accounts) {
Map<String, Integer> emailToId = new HashMap<>(); // 记录每个邮箱对应的id
int n = accounts.size();
UnionFind myUnion = new UnionFind(n); // 定义并查集,并查集记录的都是id,用id作为集合的标识而不是邮箱
// 1.遍历所有 email,同一个账户合并为同一个集合
for (int i = 0; i < n; i++) {
List<String> mails = accounts.get(i);
int nums = mails.size();
for (int j = 1; j < nums; j++) {
String curEmail = mails.get(j);
// 邮箱的去重体现在这里,没出现过才记录,出现过就不记录了,只合并集合
if (!emailToId.containsKey(curEmail)) { // 如果还没出现过该邮箱
emailToId.put(curEmail, i); // 就把该邮箱所属的id记录下来
} else { // 如果出现过该邮箱
myUnion.union(i, emailToId.get(curEmail)); // 那就合并这两个id所属的集合
}
}
}
// 2.记录每个id下面的邮箱。注意不能记录用户名下面的邮箱,因为可能有两个人重名
Map<Integer, List<String>> idToEmail = new HashMap<>(); // 记录每个id有哪些邮箱
for (Map.Entry<String, Integer> entry : emailToId.entrySet()) {
int id = myUnion.find(entry.getValue()); // 找到该邮箱的id
List<String> emails = idToEmail.getOrDefault(id, new ArrayList<>());
emails.add(entry.getKey());
idToEmail.put(id, emails); // 把该邮箱放入id下面的邮箱集合
}
// 3.id换成用户名,并排序
List<List<String>> result = new ArrayList<>();
for (Map.Entry<Integer, List<String>> entry : idToEmail.entrySet()) {
List<String> emails = entry.getValue();
Collections.sort(emails);
emails.add(0, accounts.get(entry.getKey()).get(0)); // 添加用户名
result.add(emails);
}
return result;
}
}
class UnionFind {
// 用 Map 在存储并查集,表达的含义是 key 的父节点是 value
private Map<Integer,Integer> father;
// 0.构造函数初始化
public UnionFind(int n) {
father = new HashMap<Integer,Integer>();
for (int i = 0; i < n; i++) {
father.put(i, null);
}
}
// 1.添加:初始加入时,每个元素都是一个独立的集合,因此
public void add(int x) { // 根节点的父节点为null
if (!father.containsKey(x)) {
father.put(x, null);
}
}
// 2.查找:反复查找父亲节点。
public int find(int x) {
int root = x; // 寻找x祖先节点保存到root中
while(father.get(root) != null){
root = father.get(root);
}
while(x != root){ // 路径压缩,把x到root上所有节点都挂到root下面
int original_father = father.get(x); // 保存原来的父节点
father.put(x,root); // 当前节点挂到根节点下面
x = original_father; // x赋值为原来的父节点继续执行刚刚的操作
}
return root;
}
// 3.合并:把两个集合合并为一个,只需要把其中一个集合的根节点挂到另一个集合的根节点下方
public void union(int x, int y) { // x的集合和y的集合合并
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY){ // 节点联通只需要一个共同祖先,无所谓谁是根节点
father.put(rootX,rootY);
}
}
// 4.判断:判断两个元素是否同属一个集合
public boolean isConnected(int x, int y) {
return find(x) == find(y);
}
}
Reference
[1]力扣721.账户合并:https://leetcode-cn.com/problems/accounts-merge/
欢迎关注公众号,回复801获取《算法笔记》pdf。每天分享大数据开发面经。
