BiSeNet v2
paper:BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation
v2中的Detail Path和Semantic Path分别对应v1中的Spatial Path和Context Path
和v1相比,主要有以下两点改进
- 移除了耗时的跨层连接,简化了模型结构。
- 重新设计了整体架构。具体包括(1)加深了Detail Path来编码更多的细节信息(2)对于Semantic Path,基于深度可分离卷积设计了轻量的components(3)提出了一个有效的aggregation layer来增强两条路径之间的联系
Bilateral Segmentation Network
整体结构如下图所示

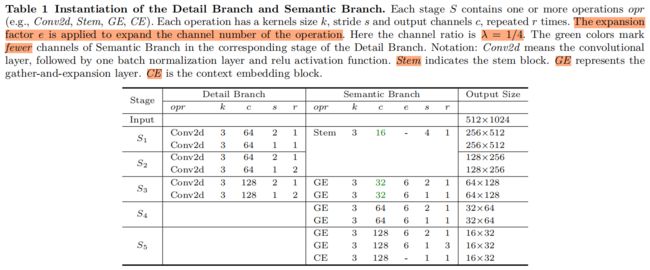
细节分支和语义分支的具体结构如下表所示
Detail Branch
细节分支负责提取空间细节信息,即low-level信息,因此该分支需要丰富的通道容量即通道数要大这样才能编码丰富的空间细节特征。同时因为该分支专注于low-level信息,因此需要是一个stride小的浅层结构。综合来看细节分支需要通道数大层数少。此外最好不要使用residual connection,额外增加内存访问成本降低了速度。
如表(1)所示,细节分支包含3个stage,每个stage包含2个卷积层,每个卷积层后都有一个BN和一个ReLU,每个stage的第一个卷积层stride=2,因此该分支的输出特征图大小是模型输入的1/8。
细节分支的具体结构如下
DetailBranch(
(detail_branch): ModuleList(
(0): Sequential(
(0): ConvModule(
(conv): Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(1): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(2): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(2): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(2): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
)Semantic Branch
同时考虑到大感受野和小计算量,作者借鉴了轻量型网络如Xception、MobileNet、ShuffleNet设计了语义分支的结构,与细节分支大通道数浅层的特点相反,语义分支需要小通道数深层的结构,具体如下
Stem Block
作者采用Stem Block作为语义分支的第一个stage,如下图(a)所示,它使用了两种不同的降采样方式来减小特征表示,然后将两个分支的输出进行concatenate,这个结构具有高效的计算成本和特征表达能力。

Stem Block的具体结构如下
(stage1): StemBlock(
(conv_first): ConvModule(
(conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(convs): Sequential(
(0): ConvModule(
(conv): Conv2d(16, 8, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(8, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(pool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(fuse_last): ConvModule(
(conv): Conv2d(32, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)Gather-and-Expansion Layer
除了第一个stem block和最后的context embedding block,语义分支的中间每个stage都是由GE layer组成的,如下图所示

GE层包括(1)一个3x3卷积用来有效地聚合特征响应并扩展到高维空间(2)一个在每个通道上单独提取特征的3x3深度卷积(3)一个1x1卷积将深度卷积的输出映射到一个低通道空间。
当stride=2时,另外采用2个3x3深度卷积进一步扩大感受野,并且采用深度可分离卷积作为shortcut。
语义分支的stage3的结构如下所示,具体包括2个GE layer,第一个GE层stride=2,第二个GE层stride=1
(stage2): Sequential(
(0): GELayer(
(conv1): ConvModule(
(conv): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(dwconv): Sequential(
(0): ConvModule(
(conv): Conv2d(16, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=16, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): ConvModule(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(shortcut): Sequential(
(0): DepthwiseSeparableConvModule(
(depthwise_conv): ConvModule(
(conv): Conv2d(16, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=16, bias=False)
(bn): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(pointwise_conv): ConvModule(
(conv): Conv2d(16, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(conv2): Sequential(
(0): ConvModule(
(conv): Conv2d(96, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(act): ReLU()
)
(1): GELayer(
(conv1): ConvModule(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(dwconv): Sequential(
(0): ConvModule(
(conv): Conv2d(32, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(conv2): Sequential(
(0): ConvModule(
(conv): Conv2d(192, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(act): ReLU()
)
)Context Embedding Block
作者将语义分支最后一个stage的最后一层由GE layer换成了CE layer,其结构如图(4)(b)所示,采用全局平均池化和残差连接来高效地编码全局上下文信息。
(stage4_CEBlock): CEBlock(
(gap): Sequential(
(0): AdaptiveAvgPool2d(output_size=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv_gap): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(conv_last): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)Bilateral Guided Aggregation
因为细节分支和语义分支关注的特征不同,细节分支提取的是low-level细节特征,而语义分支提取的是high-level语义特征,因此不能简单的通过summation或concatenation的方式融合两个分支提取的特征,作者提出了bilateral guided aggregation layer来融合来自两个分支的互补信息,利用语义分支的上下文信息来指导细节分支的特征响应,通过不同尺度下的引导,我们可以获得不同尺度的特征表示,有效地编码了多尺度信息。具体结构如下图所示

BGA代码
class BGALayer(BaseModule):
"""Bilateral Guided Aggregation Layer to fuse the complementary information
from both Detail Branch and Semantic Branch.
Args:
out_channels (int): Number of output channels.
Default: 128.
align_corners (bool): align_corners argument of F.interpolate.
Default: False.
conv_cfg (dict | None): Config of conv layers.
Default: None.
norm_cfg (dict | None): Config of norm layers.
Default: dict(type='BN').
act_cfg (dict): Config of activation layers.
Default: dict(type='ReLU').
init_cfg (dict or list[dict], optional): Initialization config dict.
Default: None.
Returns:
output (torch.Tensor): Output feature map for Segment heads.
"""
def __init__(self,
out_channels=128,
align_corners=False,
conv_cfg=None,
norm_cfg=dict(type='BN'),
act_cfg=dict(type='ReLU'),
init_cfg=None):
super(BGALayer, self).__init__(init_cfg=init_cfg)
self.out_channels = out_channels
self.align_corners = align_corners
self.detail_dwconv = nn.Sequential(
DepthwiseSeparableConvModule(
in_channels=self.out_channels,
out_channels=self.out_channels,
kernel_size=3,
stride=1,
padding=1,
dw_norm_cfg=norm_cfg,
dw_act_cfg=None,
pw_norm_cfg=None,
pw_act_cfg=None,
))
self.detail_down = nn.Sequential(
ConvModule(
in_channels=self.out_channels,
out_channels=self.out_channels,
kernel_size=3,
stride=2,
padding=1,
bias=False,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=None),
nn.AvgPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False))
self.semantic_conv = nn.Sequential(
ConvModule(
in_channels=self.out_channels,
out_channels=self.out_channels,
kernel_size=3,
stride=1,
padding=1,
bias=False,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=None))
self.semantic_dwconv = nn.Sequential(
DepthwiseSeparableConvModule(
in_channels=self.out_channels,
out_channels=self.out_channels,
kernel_size=3,
stride=1,
padding=1,
dw_norm_cfg=norm_cfg,
dw_act_cfg=None,
pw_norm_cfg=None,
pw_act_cfg=None,
))
self.conv = ConvModule(
in_channels=self.out_channels,
out_channels=self.out_channels,
kernel_size=3,
stride=1,
padding=1,
inplace=True,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg,
)
def forward(self, x_d, x_s): # (4,128,60,60),(4,128,15,15)
detail_dwconv = self.detail_dwconv(x_d) # (4,128,60,60)
detail_down = self.detail_down(x_d) # (4,128,15,15)
semantic_conv = self.semantic_conv(x_s) # (4,128,15,15)
semantic_dwconv = self.semantic_dwconv(x_s) # (4,128,15,15)
semantic_conv = resize(
input=semantic_conv,
size=detail_dwconv.shape[2:],
mode='bilinear',
align_corners=self.align_corners) # (4,128,60,60)
fuse_1 = detail_dwconv * torch.sigmoid(semantic_conv) # (4,128,60,60)
fuse_2 = detail_down * torch.sigmoid(semantic_dwconv) # (4,128,15,15)
fuse_2 = resize(
input=fuse_2,
size=fuse_1.shape[2:],
mode='bilinear',
align_corners=self.align_corners) # (4,128,60,60)
output = self.conv(fuse_1 + fuse_2) # (4,128,60,60)
return outputBooster Training Strategy
为了进一步提高分割精度,作者提出了一种强化训练策略,它在训练阶段可以增强特征表示,在推理阶段可以直接丢弃,因此不会增加模型的推理速度。如图(3)所示,通过将辅助分割head添加到语义分支的不同位置,对模型的中间输出进行额外的监督,可以提高模型的精度。
实现过程
下面以MMSegmentation中的bisenet v2实现为例,捋一下具体实现过程
假设batch_size=4,输入shape为(4, 3, 480, 480)。
- Detail Branch的输出为(4, 128, 60, 60)
- Semantic Branch如表(1)所示,Stem Block的输出为(4, 16, 120, 120),S3的输出为(4, 32, 60, 60),S4的输出为(4, 64, 30, 30),S5的输出包括第二个GE层的输出(4, 128, 15, 15)和最后一个CE层的输出(4, 128, 15, 15)。因此语义分支的输出是一个list,包含5个输出,最后CE的输出和细节分支的输出一起作为输入进入到BGA层,前4个输出在训练过程中,作为辅助分割head的输入。
- Bilateral Guided Aggregation的输出为(4, 128, 60, 60)
Experimental Results
Cityscapes
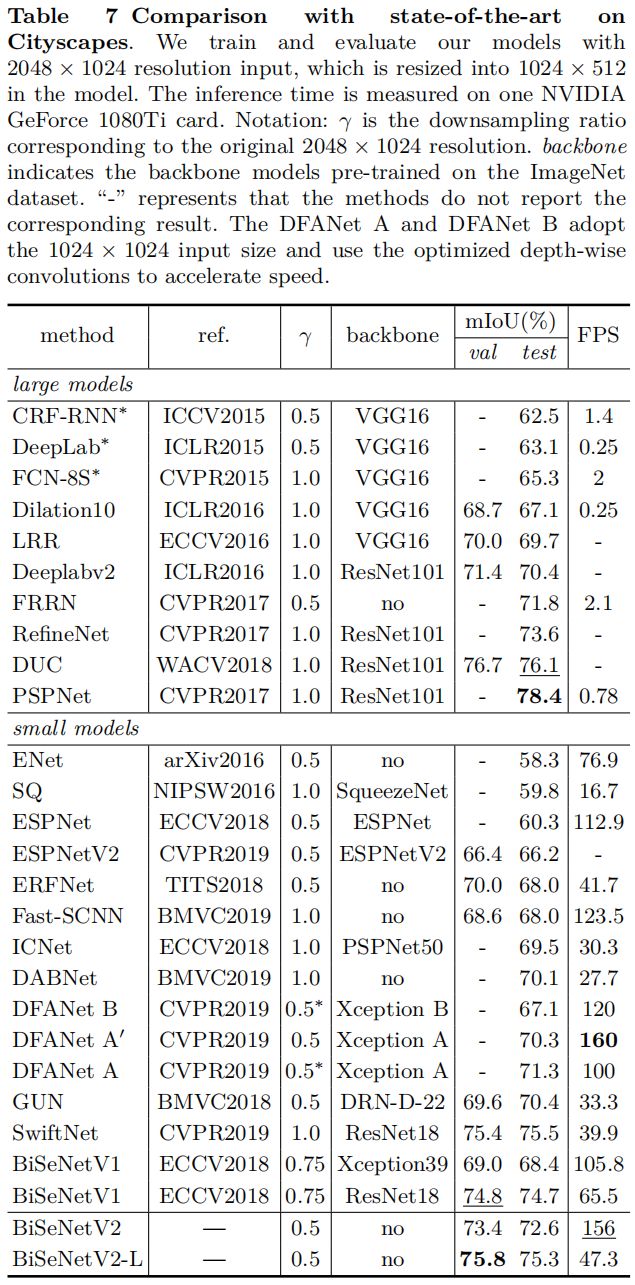
CamVid