Docker中的网络详解
本节主要是介绍Docker默认的网络行为,包含创建的默认网络类型以及如何创建用户自定义网络,也会介绍如何在单一主机或者跨主机集群上创建网络的资源需求。
1、默认网络
当你安装了docker,她自动创建了3个网络,可以使用docker network命令来查看

这三个网络被docker内建。当你运行一个容器的时候,可以使用--network参数来指定你的容器连接到哪一个网络。
1)bridge网络
默认连接到docker0这个网桥上。
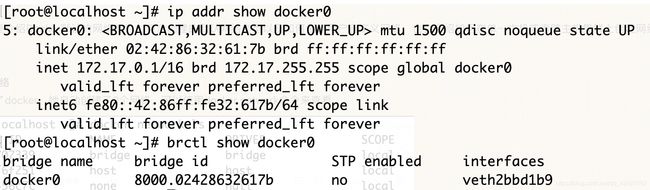
注:brctl命令在centos中可以使用yum install bridge-utils来安装
启动并运行一个容器

[root@localhost ~]# docker exec -it test1 /bin/bash
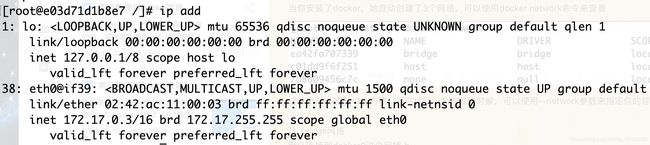
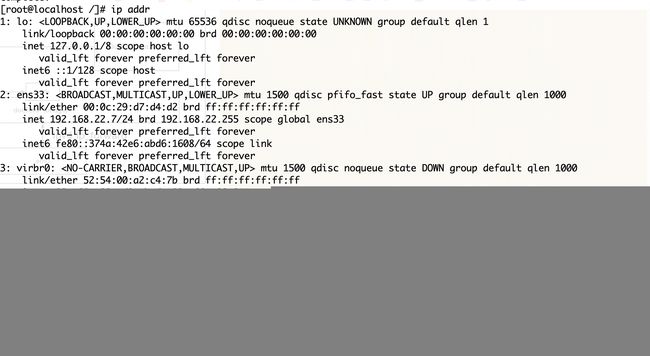
可以看到test1容器已经获取了一个地址172.17.0.3,和主机的docker0接口地址在同一个网络,并将主机的docker0接口地址设置为了网关。

在物理主机上,查看网桥docker0,可以看到已经多了一个接口。
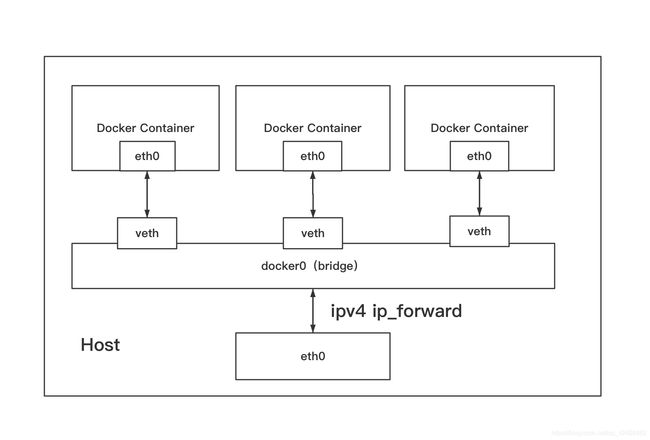
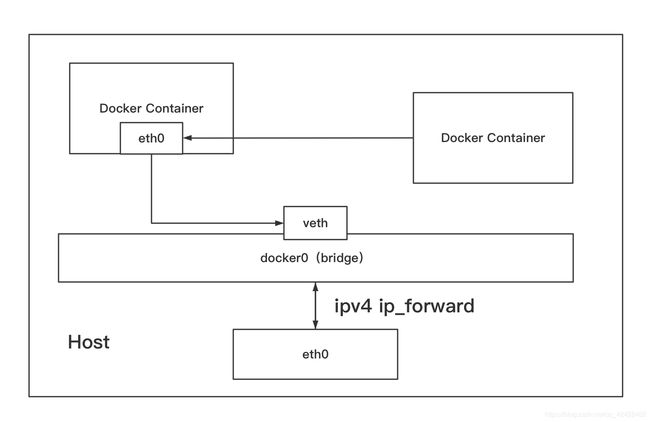
Docker容器默认使用bridge模式的网络,其特点如下:
- 使用一个linux bridge,默认docker0。
- 使用veth对,一头在容器的网络namespace中,一头在docker0上。
- 该模式下Docker Container不具有一个公有IP,因为宿主机的IP地址与veth pair的IP地址不在同一个网段内。
- Docker采用NAT方式,将容器内部的服务监听的端口与宿主机的某一个端口port进行”绑定“,使得宿主机以外的世界可以主动将网络保存发送至容器内部。
- 外界访问容器内的服务时,需要访问宿主机的IP以及宿主机的端口port。
- NAT模式由于是在三层网络上的实现手段,故肯定会影响网络的传输效率。
- 容器拥有独立、隔离的网络栈;让容器和宿主机以外的世界通过NAT简历通信
效果是这样的:
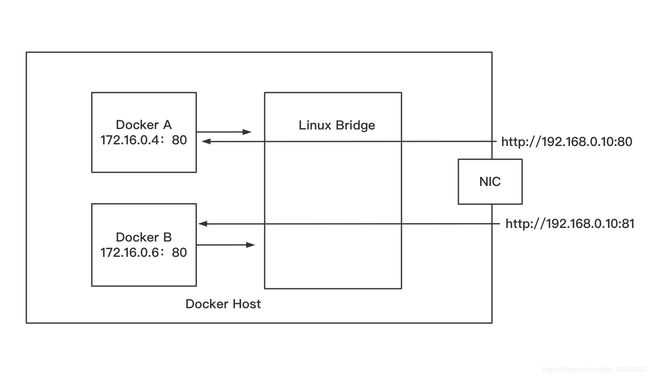
示意图如下:
在物理主机上查看iptables的nat表,可以看到在POSTROUTING链中做了地址伪装:MASQUERADE动作,这样容器就可以通过原地址转换NAT访问外部网络了。
通过iptables -t nat -vnL命令查看到:

可以使用docker network inspect bridge命令来查看bridge网络情况:
[root@localhost ~]# docker network inspect bridge
[
{
"Name": "bridge",
"Id": "d22bd827a7eb3206cd71bd7c60c4fe68b8ba068a2716abf89b7a5a3c68dd9635",
"Created": "2020-10-21T21:37:12.892688838+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "172.17.0.0/16",
"Gateway": "172.17.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {},
"Options": {
"com.docker.network.bridge.default_bridge": "true",
"com.docker.network.bridge.enable_icc": "true",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.host_binding_ipv4": "0.0.0.0",
"com.docker.network.bridge.name": "docker0",
"com.docker.network.driver.mtu": "1500"
},
"Labels": {}
}
]
2)none网络模式:
网络模式为none,即不为Docker容器构造任何网络环境,不会为容器创建网络接口,一旦Docker容器采用了none网络模式,那么容器内部就只能使用loopback网络设备,不会再有其他的网络资源。Docker Container的网络模式意味着不给该容器创建任何网络环境,容器只能使用127.0.0.1的本机网络。
启动一个容器,设为none网络
[root@localhost ~]# dockerv run -it -d --network none --name test3 ubuntu /bin/bash
由于没有网络不能使用yum安装ip addr命令,所以不能查看网卡。
3)host网络模式
Host模式并没有为容器创建一个隔离的网络环境。而之所以称之为host模式,是因为该模式下的Docker容器会和host宿主机共享同一个网络namespace,故Docker Container可以和宿主机一样,使用宿主机的eth0,实现和外界的通信。换言之,Docker Container其特点包括:
- 这种模式下的容器没有隔离的network namespace
- 容器的IP地址同Docker host的IP地址
- 需要注意容器中服务的端口号不能与Docker host上已经使用的端口号相冲突
- host模式能够和其它模式共存
示意图:

例如,我们在192.168.22.7/24的机器上用host模式启动一个含有web应用的Docker容器,监听tcp80端口。当我们在容器中执行任何类似ifconfig命令查看网络环境时,看到的都是宿主机上的信息。而外界访问容器中的应用,则直接使用192.168.22.7:80即可,不用任何NAT转换,就如直接跑在宿主机一样。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。
启动容器前,查看物理主机的httpd进程

启动一个容器:
[root@localhost ~]# docker run -itd --privileged --name test5 --network host centos:7 init
进入容器,安装httpd容器,并启动:
[root@localhost ~]# docker exec -it test5 /bin/bash
[root@localhost /]# yum -y install httpd
[root@localhost /]# systemctl start httpd
[root@localhost /]# echo "test docker host network" > /var/www/html/index.html
退出容器,在此查看httpd进程:

访问主机的80端口,可以访问到容器test5网站服务(注意防火墙):
[root@localhost ~]# firewall-cmd --add-port=80/tcp
success

4)container模式
这个模式指定新创建的容器和已经存在的一个容器共享一个Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的IP,而是和一个指定的容器共享IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进行列表等还是隔离的。两个容器的进程可以通过lo网卡设备通信。
Container网络模式是Docker中一种较为特别的网络模式。这两个容器之间不存在网络隔离,而这两个容器又与宿主机以及除此之外其他的容器存在网络隔离。
注意:因为此时两个容器要共享一个network namespace,因此需要注意端口冲突情况,否则第二个容器将无法被启动
示意图:
运行一个容器:查看容器IP

![]()
启动另外一个容器,使用test5容器网络:
[root@localhost ~]# docker run -itd --name test6 --network container:test5 centos:7 /bin/bash
5f726c21a516f081212f0b6dee91f0e86ba30dd8eb1c88f2fc38ca8c04222e79

进入test6容器,查看网络情况,可以看到两个容器地址信息相同,是共享的


通过上面的docker网络学习,已经可以实现容器和外部网络通信了,但是如何让外部网络来访问容器呢?
外部访问容器:
容器中可以运行一些网络应用,要让外部也可以访问这些应用,可以通过-P或-p参数来指定端口映射。
当使用-P(大写)标记时,Docker会随机映射一个随机端口到内部容器开放的网络端口。
注意:-P使用时需要指定--expose选项或dockerfile中用expose指令容器要暴露的端口,指定需要对外提供服务的端口。
从docker hub下载一个http的镜像


使用这个下载的镜像启动一个容器:

可以看到容器的80端口被随机映射到主机的32768端口
访问主机IP地址的32768端口,就可以访问到容器的httpd服务。

-p(小写)则可以指定要映射的端口,并且,在一个指定端口上只可以绑定一个容器。支持的格式有ip:hostPort:containerPort | ip::containerPort | hostPort:containerPort
注意:
- 容器有自己的内部网络和ip地址(使用docker inspect可以获取所有的变量。)
- -p标记可以多次使用来绑定多个端口

可以看到主机8000端口已经和容器web-test002的80端口做了映射
访问主机的8000端口

映射到指定地址的指定端口:
可以使用ip:hostPort:containerPort格式,指定映射使用一个特定地址,比如宿主机网卡配置的一个地址192.168.22.7
![]()
映射到指定地址的任意端口:
使用ip::containerPort绑定192.168.22.7的任意端口到容器80端口,本地主机会自动分配一个口。--name为启动的容器指定一个容器名。
![]()
注意:还可以使用udp标记来指定udp端口
[root@localhost ~]# docker run -d -p 127.0.0.1:5000:5000/udp --name db4 mysql
查看映射端口配置

docker端口映射实质上是在iptables的nat表中添加了DNAT规则:


3、用户自定义网络:
建议使用用户定义的桥接网络来控制容器之间的彼此通信,并启用容器名称和IP地址的自动DNS解析,docker默认提供了用于创建这些网络的默认网络驱动程序,你能创建:
- bridge network
- overlay network
- MACVLAN network
- network plugin
- remote network
您可以根据需要创建尽可能多的网络,并且可以在任何给定的时间将容器连接到0个或多个网络。此外,还可以在不重新启动容器的情况下连接和断开网络中的运行容器。当容器连接到多个网络时,它的外部连接是通过第一个非内部网络提供的。
Bridge network:
是docker中最常见的网络类型,它类似于默认的桥接网络,但是添加了一些新功能,去掉一些旧功能。
可以通过下面的命令创建一个bridge网络:
[root@localhost ~]# docker network create --driver bridge isolated_nw
d219160db427d56bc8dd4b1d7f98534834e13da48da1636d251436a2731187be
查看网络情况:
[root@localhost ~]# docker network inspect isolated_nw
[
{
"Name": "isolated_nw",
"Id": "d219160db427d56bc8dd4b1d7f98534834e13da48da1636d251436a2731187be",
"Created": "2020-10-22T00:18:59.886808362+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.18.0.0/16",
"Gateway": "172.18.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {},
"Options": {},
"Labels": {}
}
]
查看网桥:

启动一个容器然后将其加入新创建的网络:
[root@localhost ~]# docker run -itd --network isolated_nw --name web002 httpd
7201f6f3536b8af1feaf7f99fa347839138b49cf243d33bbf66a4e5ec4dcb05b
[root@localhost ~]# docker network inspect isolated_nw
[
{
"Name": "isolated_nw",
"Id": "d219160db427d56bc8dd4b1d7f98534834e13da48da1636d251436a2731187be",
"Created": "2020-10-22T00:18:59.886808362+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.18.0.0/16",
"Gateway": "172.18.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {
"7201f6f3536b8af1feaf7f99fa347839138b49cf243d33bbf66a4e5ec4dcb05b": {
"Name": "web002",
"EndpointID": "b0aa915664497f50d459f64ce1f5ffd1f46621a046982c89430fa701f1ddf6ff",
"MacAddress": "02:42:ac:12:00:02",
"IPv4Address": "172.18.0.2/16",
"IPv6Address": ""
}
},
"Options": {},
"Labels": {}
}
]
加入你创建的网络中的容器必须在同一个HOST主机上,网络中的每个容器都可以立即与网络中的其他容器通信。然而,网络本身将容器与外部网络隔离开来。
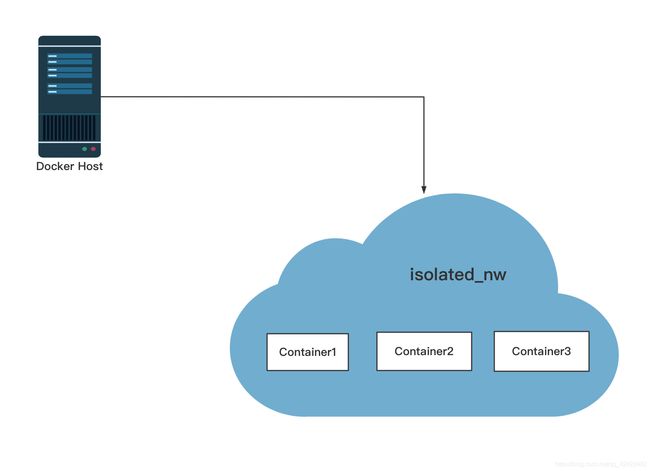
在用户定义的网桥网络中,不支持linking(连接)。可以在这个网络中公开和发布容器端口,也就是expose and publish(暴露端口和公开端口)
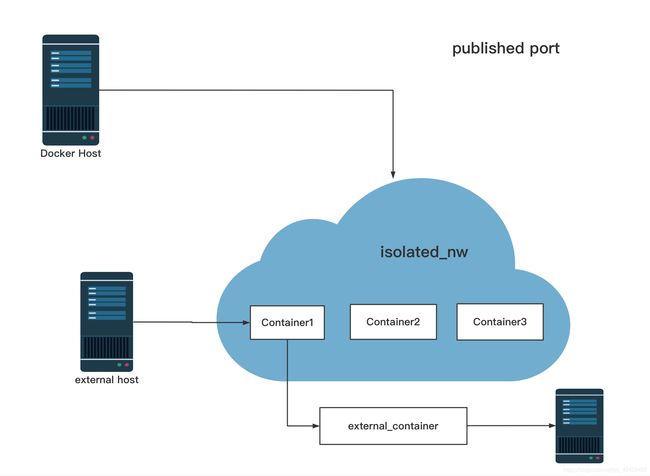
注解:external host为外界主机。
如果你想在单一主机上运行一个相对小的网络,使用桥接网络是有效果的。
然而你想创建一个大网络,可以通过Overlay网络来实现。
跨主机Docker容器通信方案:
现有的主要Docker网络方案
1、基于实现方式分类:
1)隧道方案
通过隧道,或者说Overlay Networking的方式:
- Weave:UDP广播,本机建立新的BR,通过PCAP互通。
- Open vSwitch(OVS):基于VxLan和GRE协议,但是性能方面损失比较严重。
- Flannel:UDP广播,VxLan。
注解:
VxLan:VxLAN(Virtual eXtensible Local Area Network,虚拟扩展局域网)技术很好地解决了现有VLAN技术无法满足大二层网络需求的问题。VxLAN技术是一种大二层的虚拟网络技术,主要原理是引入一个UDP格式的外层隧道作为数据链路层,而原有数据报文内容作为隧道净荷加以传输。由于外层采用了UDP作为传输手段,净荷数据可以轻松地在二三层网络中传送。VxLAN已成为业界主流的虚拟网络技术之一,IETF正在制定相关标准。
GRE协议:通用路由封装 (GRE)定义了在任意一种网络层协议上封装任意一个其它网络层协议的协议。
隧道方案在IaaS层的网络中应用也比较多,大家共识是随着节点规模的增长复杂度会提升,而且出了网络问题跟踪起来比较麻烦,大规模群集情况下这是需要考虑的一点。
2)路由方案
通过路由来实现,比较典型的代表有:
- Calico:基于BGP协议的路由方案,支持很细致的ACL控制,对混合云亲和度比较高。
- Macvlan:从逻辑和Kernel层来看隔离性和性能最优的方案,基于二层隔离,所以需要二层路由支持,大多数云服务商不支持,所以混合云上比较难以实现。
注解:BGP:(BGP/BGP4:Border Gateway Protocol,边界网关协议)是一种实现自治系统AS(Autonomous System)之间的路由可达,并选择最佳路由的距离矢量路由协议。
MP-BGP是对BGP-4进行了扩展,来达到在不同网络中应用的目的,BGP-4原有的消息机制和路由机制并没有改变。MP-BGP在IPv6单播网络上的应用称为BGP4+,在IPv4组播网络上的应用称为MBGP(Multicast BGP)。
AS自治系统:互联网是一个网络; 它被分解成数十万个称为自治系统(AS)的小型网络。这些网络中的每一个本质上都是由单个组织运行的大型路由器池。
自治系统是由单个组织管理的大型网络或网络组。AS可能有许多子网,但都共享相同的路由策略。通常,AS是ISP或具有自己的网络的非常大的组织,以及从该网络到ISP的多个上游连接(这称为“多宿主网络”)。每个AS都分配有自己的自治系统编号(ASN),以便轻松识别它们。
路由方案一般是从3层或者2层实现隔离和跨主机容器互通的,出了问题也很容易排查。
2、基于网络模型分类:
Docker Libnetwork Container Network Model(CNM)阵营
- Docker Swarm Overlay
- Macvlan & IP network drivers
- Calico
- Contiv(from Cisco)
Docker Libnetwork的优势就是原生,而且和Docker容器生命周期结合紧密;缺点也可以理解为原生,被Docker“绑架”。
Container Network Interface(CNI)阵营
- Kubernetes
- Weave
- Macvlan
- Flannel
- Calico
- Contiv
- Mesos CNI
CNI的优势是兼容其他容器技术(e.g.rkt)及上层编排系统(Kuberneres & Mesos),而且社区活跃势头迅猛,Kuberneres加上CoreOS主推了,缺点是非Docker原生。
从上面的可以看出,有一些第三方的网络方案是同时属于两个阵营的。
下面主要介绍了Docker容器平台中的Libnetwork,Flannel、Calico、Weave这几种跨主机通信方案,并对各个方法的原理进行阐述。
Libnetwork:
Libnetwork是从1.6版本开始将Docker的网络功能从Docker核心代码中分离出去,形成一个单独的库。Libnetwork的目标是定义一个健壮的容器网络模型,提供一个一致的编程接口和应用程序的网络抽象。
Libnetwork通过插件的形式为Docker提供网络功能,使得用户可以根据自己的需求实现自己的Driver来提供不同的网络功能,从1.9版本开始,Docker已经实现了基于Libnetwork和Libkv库的网络模式-多主机Overlay网络。
Libnetwork索要实现的网络模型基本是这样的:用户可以创建一个或多个网络(一个网络就是一个网桥或者一个VLAN),一个容器可以加入一个或多个网络。同一个网络中容器可以通信,不同网络中的容器隔离。
Libnetwork实现了一个叫做Container Network Model(CNM)的东西,也就是说希望成为容器的标准网络模型、框架。其中包含了下面几个概念:
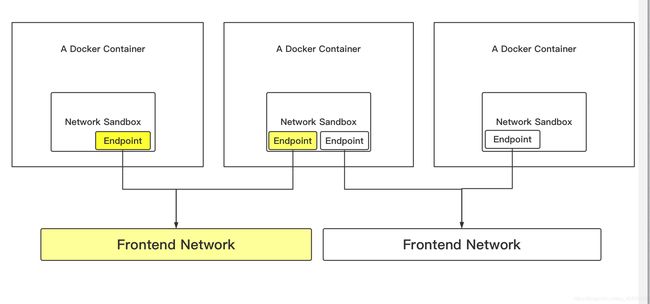
- Sandbox:Sandbox包含容器网络栈的配置,包括容器接口,路由表。DNS配置等管理。Linux network namespace是常见的一种Sandbox的实现。Sandbox中包含众多网络中的若干Endpoint。
- Endpoint:Neutron中和Endpoint相对的概念应该是VNIC,也就是虚拟机的虚拟网卡(也可以看成VIF)。Endpoint的常见实现包括veth pair、Openvswitch的internal port当Sandbox要和外界通信的时候就是通过Endpoint连接到外界的,最简单的情况就是连接到一个Bridge上。
- Network:Network是一组可以互相通信的Endpoint集合,组内Endpoint可以相互通讯。不同组内Endpoint是不能通信的,是完全隔离的。常见的实现包括Linux bridge,Vlan等。
目前已经实现了如下driver:
- Host:主机网络,只用这种网络的容器会使用主机的网络,这种网络对外界是完全开放的,能够访问到主机,就能访问到容器。
- Bridge:桥接网络,这个Driver就是Docker现有网络Bridge模式的实现。除非创建容器的时候指定网络,不然容器就会默认使用桥接网络。属于这个网络的容器之间可以互相通信,外界想要访问到这个网络的容器需要使用桥接网络。
- Null:Driver的空实现,类似于Docker容器的None模式。使用这种网络的容器会完全隔离。
- Overlay:Overlay驱动可实现通过Vxlan等重叠网络封装技术跨越多个主机的网络,目前Docker已经自带该驱动。
- Remote:Remote驱动包不提供驱动,但提供了融合第三方驱动的接口。
Flannel:
Flannel之前的名字是Rudder,它是由CoreOS团队针对Kubernetes设计的一个重载网络工具,它的主要思路是:预先留出一个网段,每个主机使用其中一部分,然后每个容器被分配不同的IP;让所有的容器认为大家在同一个直连网络上,底层通过UDP/VxLan等进行报文的封装和转发。
Flannel类似于Weave、VxLAN,提供了一个可配置的虚拟承载网络。Flannel以一个daemon(守护进程)形式运行,负责子网的分配,Flannel使用etcd(类似数据库)存储,交换网络配置,状态等信息。
Flannel基本原理
Flannel默认使用8285端口作为UDP封装报文的端口,VxLAN使用8472端口。
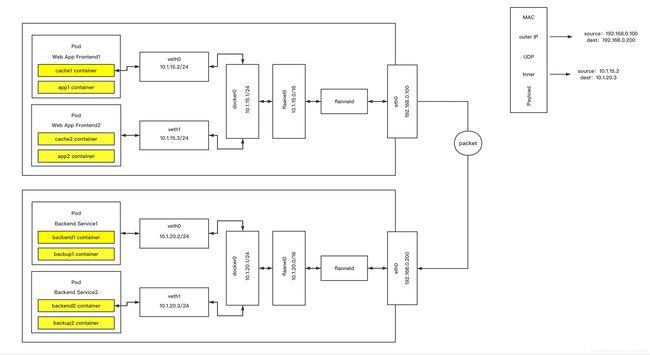
1)容器直接使用目标容器的IP访问,默认通过容器内部的eth0发送出去。
2)报文通过veth pair被发送到vethXXX。
3)vethXXX是直接连接到虚拟交换机docker0的,报文通过虚拟bridge docker0发送出去。
4)查找路由表,外部容器ip的报文都会转发到flannel0虚拟网卡,这是一个P2P(个人对个人)的虚拟网卡,然后报文就被转发到监听在另一端的flanneld。
5)flanneld通过etcd维护了各个节点之间的路由表,把原来的报文UDP封装一层,通过配置的iface(类似回环lo)发送出去。
6)报文通过主机之间的网络找到目标主机。
7)报文继续往上,到传输层,交给监听在8285端口的flanneld程序处理。
8)数据被解包,然后发送给flannel0虚拟网卡
9)查找路由表,发现对应容器的报文要交给docker0。
10)docker0找到连接到自己的容器,把报文发送过去。
Calico
Calico是一个纯3层的数据中心网络方案,而且无缝集成像Openstack这种IaaS(基础设施即服务)云架构,能够提供可控的VM、容器、裸机之间的IP通信。
它基于BPG协议和Linux自己的路由转发机制,不依赖特殊硬件,没有使用NAT或Tunnel等技术。能够方便的部署在物理服务器、虚拟机或者容器环境下,同时它自带的基于iptables的ACL管理组件非常灵活,能够满足比较复杂的安全隔离需求。
Calico在每一个计算节点利用Linux Kernel实现一个高效的VRouter来负责数据转发,而每个vRouter通过BGP协议负责把自己运行的workload(工作网络)的路由信息向整个Calico网络内传播——小规模部署可以直接互联,大规模下可通过制定的BGP route reflector(公共程序集)来完成。
这样保证最终所有的workload之间的数据流量都是通过IP路由的方式完成互联的。
基本原理:
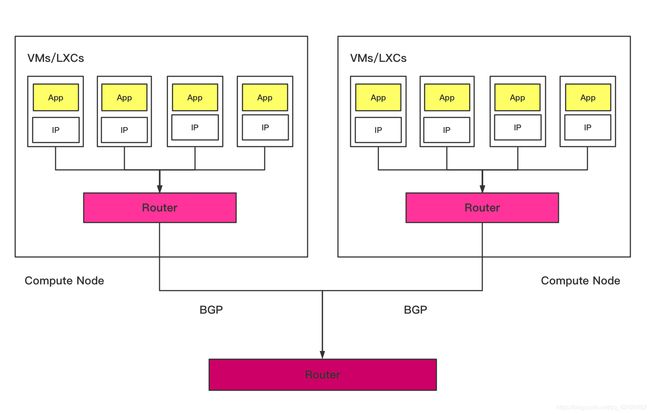
Calico的方案如上图所示。它把每个操作系统的协议栈认为是一个路由器,然后把所有的容器认为是连在这个路由器上网络终端,在路由器之间跑标准的路由协议——BGP的协议,然后让他们自己去学习这个网络拓扑该如何转发。所以Calico方案其实是一个纯3层的方案,也就是说让每台机器的协议栈的3层去确保两个容器、跨主机容器之间的3层连通性。
Calico架构:
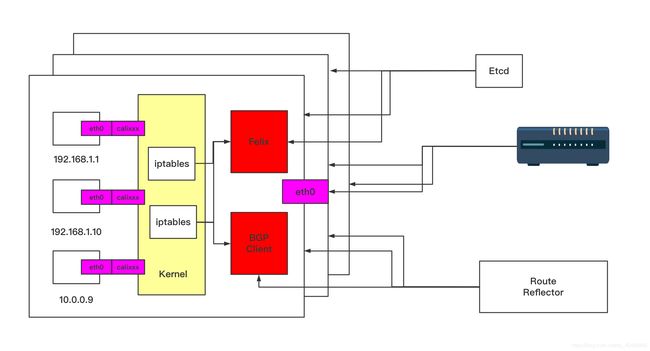
结合上面这张图,我们来过一遍Calico的核心组件:
- Felix:Calico Agent,跑在每台需要运行Workload的节点上,主要负责配置路由及ACLS(访问控制列表)等信息来确保Endpoint(端点)的连通状态。
- etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性。
- BGP Client(BIRD):主要负责把Felix写入Kernel的路由信息分发到当前Calico网络,确保Workload间的通信的有效性。
- BGP Route Reflector(BIRD):大规模部署时使用,摒弃所有节点互联的mesh(无线网格网络)模式,通过一个或者多个BGP Route Reflector来完成集中式路由分发。
每个节点上会运行两个主要的程序,一个是它自己的叫Felix,它会监听ECTD中心的存储,从它获取事件,比如说用户在这台机器上加了一个IP,或者是分配了一个容器等。接着会在这台机器上创建出一个容器,并将其网卡、IP、MAC都设置好了,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。
bird是一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,你们路由的时候要到这里来。
由于Calico是一种纯三层的实现,因此可以避免与二层方案相关的数据包封装的操作,中间没有任何的NAT,没有任何的Overlay,所以它的转发效率可能是所有方案中最高的,因为它的包直接走原生TCP/IP的协议栈,它的隔离也因为这个栈而变得好做。因为TCP/IP协议栈是提供了一整套的防火墙的规则,所以它可以通过iptables的规则达到比较复杂的隔离逻辑。
Calico优劣势:
- Calico优势
1、网络拓扑直观易懂,平行式扩展,可扩展型强。
2、容器间网络三层隔离,无需要担心arp风暴。
3、基于iptable/linux kernel包转发效率高,损耗低。
4、更容易的变成语言(python)
5、社区活跃,正式版本成熟
- Calico劣势
1、Calico仅支持TCP、UDP、ICMPandICMPv6协议,如果你想使用L4协议,你只能选择Flannel,Weave或Docker Overlay Network。
2、Calico没有加密数据路径,用不可信网络上的Calico建立覆盖网络时不安全的。
3、没有IP重叠支持。虽然Calico社区正在开发一个实验功能,将重叠IPv4包放入IPv6包中。但这只是一个辅助解决方案,并不完全支持技术上的IP重叠。
Weave
Weave是由Zett.io公司开发的,它能够创建一个虚拟网络,用于连接部署在多台主机上的Docker容器,这样容器就像被接入了同一个网络交换机,那些使用网络的应用程序不必去配置端口映射和链接等信息。
外部设备能够访问Weaver网络上的应用程序容器所提供的服务,同时已有的内部系统也能够暴露到应用程序容器上,Weave能够穿透防火墙并运行在部分链接的网络上,另外,Weave的通信支持加密,所以用户可以从一个不受信任的网络连接到主机。
Weave实现原理:(主机A、B、C运行的容器如图所示)
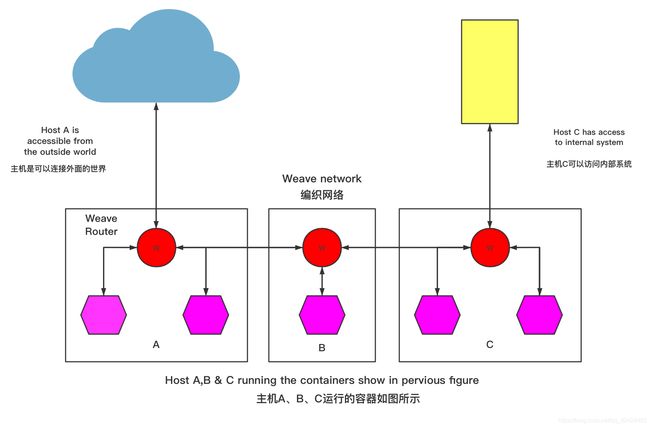
容器的网络通讯都通过route服务和网桥转发。

Weave会在主机上创建一个网桥,每一个容器通过veth pair连接到该网桥上,同时网桥上有个Weave router的容器与之连接,该router会通过连接在网桥上的接口来抓取网络包(该接口工作在Promiscuous混杂模式(网络中的一种术语,是指一台机器的网卡能够接受所有经过它的数据流。))。
在每一台部署Docker的主机(可能是物理机也可能是虚拟机)上都部署有一个W(即Weave router),它本身也可以以一个容器的形式部署。Weave run的时候就可以给每个veth的容器端分配一个IP和相应的掩码。veth的网桥这端就是Weave router容器,并在Weave launch(发射)的时候分配好IP和掩码。
Weave网络是由这些Weave routers组成的对等端点(peer)构成,每个对等的一端都有自己的名字,其中包括一个可读性好的名字用于表示状态和日志输出,一个唯一标识符用于运行中相互区别,即使重启Docker主机名字也保持不变,这些名字默认是MAC地址。
每个部署了Weave router的主机都需要将TCP和UDP的6783端口的防火墙设置打开,保证Weave router之间控制面流量和数据面流量的通过,控制面由Weave routers之间建立的TCP连接构成,通过它进行握手和拓扑关系信息的交换通信。这个通信可以被配置为加密通信。而数据面由Weave routers之间建立的UDP连接构成,这些连接大部分都会加密。这些连接都是全双工的,并且可以穿越防火墙。
Weave优劣势:
- Weave优势
1、支持主机间通信加密。
2、支持container动态加入或者剥离网络。
3、支持跨主机多子网通信。
- Weave劣势
1、只能通过Weave launch或者Weave connect加入Weave网络。
各个方案对比
- Flannel和Overlay方案均使用承载网络,承载网络的优势和劣势都是非常明显的。
优势:对底层网络依赖较少,不管底层是物理网络还是虚拟网络,对层叠网络的配置管理影响较少;配置简单,逻辑清晰,易于理解和学习,非常使用与开发测试对网络性能要求不高的场景。
劣势:网络封装是一种传输开销,对网络性能会有影响,不适用于对网络性能要求高的生产场景;由于对底层网络结构缺乏了解,无法做到真正有效的流程工程控制,也会对网络性能产生影响,某些情况下也不能完全做到与下层网络无关,例如隧道封装会对网络的MTU限制产生影响。
- Calico方案因为没有隧道封装的网络开销,会带来相对比较高的网络性能。不支持多租户,由于没有封装所有的容器只能通过真实的IP地址来区分自己,这就要求所有租户的容器统一分配一个地址空间。Calico基于三层转发的原理对物理架构可能会有一定的要求和侵入性。
- Weave可以穿透防火墙,安全性较高,流量是被加密的,允许主机连接通过一个不被信任的网络,同样会有承载网络带来的优缺点。
Docker网络管理命令如下:
- docker network create
- docker network connect
- docker network ls
- docker network rm
- docker network disconnect
- docker network inspect
创建网络:
默认创建的是bridge网络:
[root@localhost ~]# docker network create simple-network
f07ccd0b1cadba30204786dfc7af4faf3ea43e121e3ac799107d29ce8c4f54d3
[root@localhost ~]# docker network inspect simple-network
[
{
"Name": "simple-network",
"Id": "f07ccd0b1cadba30204786dfc7af4faf3ea43e121e3ac799107d29ce8c4f54d3",
"Created": "2020-10-25T17:22:57.666963117+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.19.0.0/16",
"Gateway": "172.19.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {},
"Options": {},
"Labels": {}
}
]
不像bridge网络,直接可以创建,创建Overlay网络需要一些条件:
- 访问到一个键值存储,支持Consul,Etcd,Zookeeper分布式键值存储
- 与键值存储连接的主机集群
- 在Sware群集中的每个主机上正确配置了引擎的daemon
支持Overlay网络的docker选项:
- --cluster-store
- --cluster-store-opt
- --cluster-advertise
当你创建了一个网络,默认会创建一个不重叠的子网,使用--subnet选项可以直接指定子网络,在bridge网络中只可以指定一个子网络,而在Overlay网络中支持多个子网络。
除了--subnet,还可以指定:--gateway,--ip-range,--aux-address选项。
[root@localhost ~]# docker network create -d overlay \
> --subnet=192.168.22.0/16 \
> --subnet=192.170.22.0/16 \
> --gateway=192.168.22.100 \
> --gateway=192.170.22.100 \
> --ip-range=192.168.23.0/24 \
> --aux-address="my-router=192.168.23.5" --aux-address="my-switch=192.168.23.6" \
> --aux-address="my-printer=192.170.23.5" --aux-address="my-nas=192.170.23.6" \
> my-multihost-network
注意:以上是示例,告诉怎么去配置Overlay网络,请在Docker swarm中使用,单独使用会报错,错误信息如下:
Error response from daemon: This node is not a swarm manager. Use "docker swarm init" or "docker swarm join" to connect this node to swarm and try again.
(守护进程的错误响应:此节点不是群集管理器。使用“docker swarm init”或“docker swarm join”将此节点连接到swarm,然后重试。)
要确保子网不会重叠,否则,网络会创建失败并返回错误。
创建自定义网络时,可以向驱动程序传递附加选项,bridge驱动接受以下选项:
| Option(选项) |
Equivalent(等效) |
Description(描述) |
| com.docker.network.bridge.name |
- |
bridge name to be used when creating the Linux bridge (在创建Linux网桥时使用的网桥名) |
| com.docker.network.bridge.enable_ip_masquerade |
--ip-masq |
Enable IP masquerading(启用IP伪装) |
| com.docker.network.bridge.enable_icc |
--icc |
Enable or disable inter container connectivity(启用或禁用容器间连接) |
| com.docker.network.bridge.host_binding_ipv4 |
--ip |
Default IP when binding container ports(绑定容器端口时的默认IP) |
| com.docker.network.driver.mtu |
--mtu |
Set the containers network MTU(设置容器网络的MTU) |
com.docker.network.driver.mtu这个选项也支持Overlay驱动。
下面的参数在使用docker network create命令时,可以传递给任意网络驱动。
| Argument(论点) |
Equivalent(等效) |
Description(描述) |
| --internal(内部) |
- |
Restrice external access to the network(限制外部访问网络) |
| --ipv6 |
--ipv6 |
Enable IPv6 networking(启用ipv6网络) |
例如:
[root@localhost ~]# docker network create -o "com.docker.network.bridge.host_binding_ipv4"="192.168.22.7" my-network
8a26ce23bc9e44f3eec4f89e98f0dbbbf660366cdf3eda70ba0de7c9812efd33
[root@localhost ~]# docker network inspect my-network
[
{
"Name": "my-network",
"Id": "8a26ce23bc9e44f3eec4f89e98f0dbbbf660366cdf3eda70ba0de7c9812efd33",
"Created": "2020-10-25T18:17:57.426584326+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.20.0.0/16",
"Gateway": "172.20.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {},
"Options": {
"com.docker.network.bridge.host_binding_ipv4": "192.168.22.7"
},
"Labels": {}
}
]
启动一个容器并发布端口:可以看到绑定的地址。
[root@localhost ~]# docker run -itd -P --network my-network --name web001 httpd
f45cfdfdc1d0cc801fc3df49fb7893311d1d7405fbbead3a461b6145af98a42f
[root@localhost ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f45cfdfdc1d0 httpd "httpd-foreground" 11 seconds ago Up 9 seconds 192.168.22.7:32769->80/tcp web001
7201f6f3536b httpd "httpd-foreground" 3 days ago Up 3 days 80/tcp web002
0c90b2488372 httpd "httpd-foreground" 3 days ago Up 3 days 0.0.0.0:8000->80/tcp web-test002
b7f279a988ec httpd "httpd-foreground" 3 days ago Up 3 days 192.168.22.7:32768->80/tcp webserver
1714a06a13da httpd "httpd-foreground" 3 days ago Up 3 days 192.168.22.7:80->80/tcp, 192.168.22.7:10112->22/tcp dazzling_lewin
连接到容器:
可以连接已存在的容器到一个或者多个网络中,一个容器可以连接到多个不同网络驱动的网络中。
当连接一旦建立,容器便可以和其他的容器通讯,通过IP或者容器名称。
对于支持多个主机连接的Overlay网络或者自定义插件,连接到同一个多主机网络的不同主机上的容器,也可以用这种方式通信。
基本容器网络示例:
1、首先,创建和运行两个容器:container1和container2
[root@localhost ~]# docker run -itd --name container1 centos /bin/bash
d9d0c1fdf76aba061bbdbbc5b17551db48c87d8ec230dbd264b7f50ba15bad81
[root@localhost ~]# docker run -itd --name container2 centos /bin/bash
e933d14177b13c8319137b090470ca1196327e9b2733e0380445b801f2a18873
2、创建一个用户自定义网络isolated_nw,是bridge网络
[root@localhost ~]# docker network create -d bridge --subnet 172.25.0.0/16 --gateway 172.25.0.1 isolated_nw
91aced71d72b3a6e9efcaf0d38d2c013f298db1fa68e88792052140baf272976
3、连接container2容器到这个新创建网络,并inspace这个网络,检查网络的连接。
[root@localhost ~]# docker network connect isolated_nw container2
[root@localhost ~]# docker network inspect isolated_nw
[
{
"Name": "isolated_nw",
"Id": "91aced71d72b3a6e9efcaf0d38d2c013f298db1fa68e88792052140baf272976",
"Created": "2020-10-25T19:08:54.585910719+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.25.0.0/16",
"Gateway": "172.25.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {
"70383c4821843facc8d3feb416512b49a335ccadd98f5d92cc939a302afaf029": {
"Name": "container2",
"EndpointID": "71d8e71423a4096d9b2163fd149753c8e446f8e2ef9693e1d1c955acf8c76d4e",
"MacAddress": "02:42:ac:14:00:02",
"IPv4Address": "172.25.0.2/16",
"IPv6Address": ""
}
},
"Options": {},
"Labels": {}
}
]
4、创建容器container3,并分配一个固定IP172.25.3.3
[root@localhost ~]# docker run -itd --name container3 --network isolated_nw --ip=172.25.3.3 centos /bin/bash
f2379d55bf81ebf5231175bf901ac7f962482875d89703e6649b0db31688cc99
使用--ip和--ip6参数指定IP地址,如果是用户定义的网络,在容器重启的时候,会保持有效,如果不是用户定义的网络,分配的IP地址是不会保持有效的。
5、检查container3的网络资源。
[root@localhost ~]# docker inspect --format '{{json .NetworkSettings.Networks}}' container3 | python -m json.tool
{
"isolated_nw": {
"Aliases": [
"f2379d55bf81"
],
"DriverOpts": null,
"EndpointID": "53d30f41d9304c4520bf24d301ddc9945d49ac3784ed88c7fbb13c93cb3220f1",
"Gateway": "172.25.0.1",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"IPAMConfig": {
"IPv4Address": "172.25.3.3"
},
"IPAddress": "172.25.3.3",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"Links": null,
"MacAddress": "02:42:ac:19:03:03",
"NetworkID": "019293fb7cb0aaab3957de99af1a8bb8a651cbb14abfefbf756c25c44b0a6c18"
}
}
6、检查container2容器的网络资源:
[root@localhost ~]# docker inspect --format '{{json .NetworkSettings.Networks}}' containet2 | python -m json.tool
{
"bridge": {
"Aliases": null,
"DriverOpts": null,
"EndpointID": "c17697970b44a7ef722992f2cd6b6792ad7b00958eab7c68ea1f532516946582",
"Gateway": "172.17.0.1",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"IPAMConfig": null,
"IPAddress": "172.17.0.3",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"Links": null,
"MacAddress": "02:42:ac:11:00:03",
"NetworkID": "c013430953bd85703126b0ad85811edf4432a43036585fb9ee3788a097a67adb"
},
"isolated_nw": {
"Aliases": [
"816ece7dc447"
],
"DriverOpts": {},
"EndpointID": "5978aadc59d67bc64a057b1d47a32de64558a7b59d73e813a8e56cb33bf7d691",
"Gateway": "172.25.0.1",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"IPAMConfig": {},
"IPAddress": "172.25.0.2",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"Links": null,
"MacAddress": "02:42:ac:19:00:02",
"NetworkID": "019293fb7cb0aaab3957de99af1a8bb8a651cbb14abfefbf756c25c44b0a6c18"
}
}
现在container2属于两个网络。
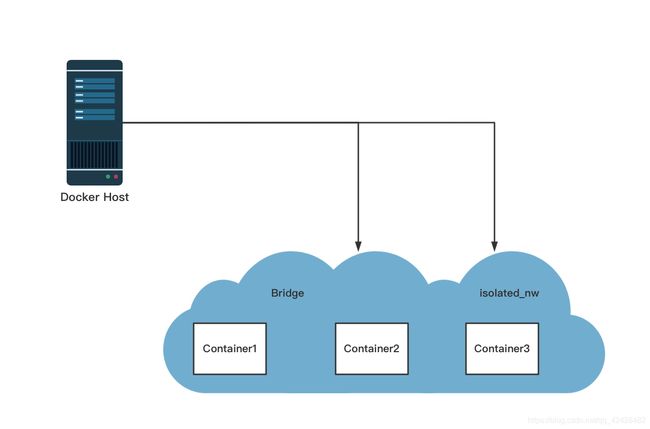
7、进入容器container2,并尝试和container3及container1通信。
[root@localhost ~]# docker exec -it container2 /bin/bash
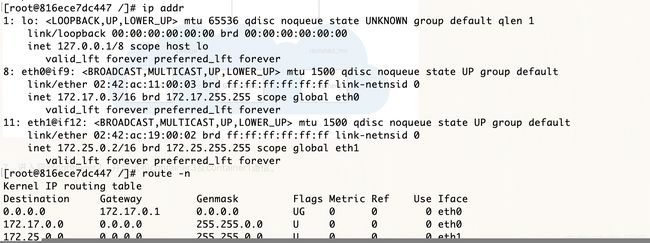
有两个IP,网关是连接到的第一个玩过的网关。
docker内嵌了DNS服务,意思是连接到同一个网络的容器,可以使用容器名进行通信。

默认的bridge网络是不可以使用名称通信的,IP可以。
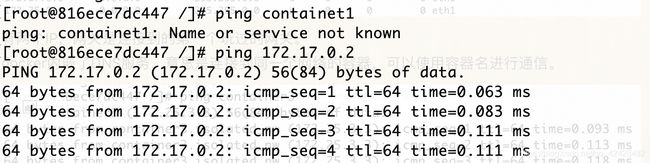
如果想让默认网络中,也可以使用容器名进行通信呢?
使用link的特性,这是唯一推荐会用link的场景。应该使用自定义的网络来替代它的。
在默认网络中使用link增加以下特性:
- 解析容器名到IP地址
- 定义网络别名
- --link=CONTAINER-NAME:ALIAS
- 增强网络连接的安全性
- 环境变量注入
例如:
[root@localhost ~]# docker run -itd --name container4 --link containet1:c1 centos /bin/bash
84fadca13e7f1d2b1a1c54adcda2c69b9a97baf61ea1463e0c7b635a7df3de56

(上图的容器名称写错了,按照正常的容器英文名字写container)
取消连接:
[root@localhost ~]# docker network disconnect isolated_nw containet2
[root@localhost ~]# docker network disconnect isolated_nw container3
删除网络:
