通过PyTorch构建的LeNet-5网络对手写数字进行训练和识别
调用PyTorch相关接口实现一个LeNet-5网络,然后通过MNIST数据集训练模型,最后对生成的模型进行预测,主要包括2大部分:训练和预测
1.训练部分:
(1).加载MNIST数据集,通过调用TorchVision模块中的接口实现,将每幅图像缩放到32*32大小,小批量数据集数量设置为32;
(2).设置网络参数的初始值,这样保证每次重新训练时初始值都是固定的,便于查找定位问题;
(3).设计LeNet-5网络,并实例化一个网络对象,重载了__init__和forward两个函数,使用到的layer包括Conv2d、AvgPool2d、Linear;激活函数使用Tanh:
(4).指定优化算法,这里采用Adam;
(5).指定损失函数,这里采用CrossEntropyLoss;
(6).训练,epochs设置为10,给出每次的训练结果;
(7).保存模型,推荐使用state_dict。
代码段如下:
def load_mnist_dataset(img_size, batch_size):
'''下载并加载mnist数据集
img_size: 图像大小,宽高长度相同
batch_size: 小批量数据集数量
'''
# 对PIL图像先进行缩放操作,然后转换成tensor类型
transforms_ = transforms.Compose([transforms.Resize(size=(img_size, img_size)), transforms.ToTensor()])
'''下载MNIST数据集
root: mnist数据集存放目录名
train: 可选参数, 默认为True; 若为True,则从MNIST/processed/training.pt创建数据集;若为False,则从MNIST/processed/test.pt创建数据集
transform: 可选参数, 默认为None; 接收PIL图像并作处理
target_transform: 可选参数, 默认为None
download: 可选参数, 默认为False; 若为True,则从网络上下载数据集到root指定的目录
'''
train_dataset = datasets.MNIST(root="mnist_data", train=True, transform=transforms_, target_transform=None, download=True)
valid_dataset = datasets.MNIST(root="mnist_data", train=False, transform=transforms_, target_transform=None, download=False)
# 加载MNIST数据集:shuffle为True,则在每次epoch时重新打乱顺序
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(dataset=valid_dataset, batch_size=batch_size, shuffle=False)
return train_loader, valid_loader, train_dataset, valid_dataset
class LeNet5(nn.Module):
'''构建lenet网络'''
def __init__(self, n_classes: int) -> None:
super(LeNet5, self).__init__() # 调用父类Module的构造方法
# n_classes: 类别数
# nn.Sequential: 顺序容器,Module将按照它们在构造函数中传递的顺序添加,它允许将整个容器视为单个module
self.feature_extractor = nn.Sequential( # 输入32*32
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=0), # 卷积层,28*28*6
nn.Tanh(), # 激活函数Tanh,使其值范围在(-1, 1)内
nn.AvgPool2d(kernel_size=2, stride=None, padding=0), # 平均池化层,14*14*6
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0), # 10*10*16
nn.Tanh(),
nn.AvgPool2d(kernel_size=2, stride=None, padding=0), # 5*5*16
nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5, stride=1, padding=0), # 1*1*120
nn.Tanh()
)
self.classifier = nn.Sequential( # 输入1*1*120
nn.Linear(in_features=120, out_features=84), # 全连接层,84
nn.Tanh(),
nn.Linear(in_features=84, out_features=n_classes) # 10
)
# LeNet5继承nn.Module,定义forward函数后,backward函数就会利用Autograd被自动实现
# 只要实例化一个LeNet5对象并传入对应的参数x就可以自动调用forward函数
def forward(self, x: Tensor):
x = self.feature_extractor(x)
x = torch.flatten(input=x, start_dim=1) # 将输入按指定展平,start_dim=1则第一维度不变,后面的展平
logits = self.classifier(x)
probs = F.softmax(input=logits, dim=1) # 激活函数softmax: 使得每一个元素的范围都在(0,1)之间,并且所有元素的和为1
return logits, probs
def validate(valid_loader, model, criterion, device):
'''Function for the validation step of the training loop'''
model.eval() # 将网络设置为评估模式
running_loss = 0
for X, y_true in valid_loader:
X = X.to(device) # 将数据导入到指定的设备上(cpu或gpu)
y_true = y_true.to(device)
# Forward pass and record loss
y_hat, _ = model(X) # 前向传播:调用Module的__call__方法, 此方法内会调用指定网络(如LeNet5)的forward方法
loss = criterion(y_hat, y_true) # 计算loss,同上,通过__call__方法调用指定损失函数类(如CrossEntropyLoss)中的forward方法
running_loss += loss.item() * X.size(0)
epoch_loss = running_loss / len(valid_loader.dataset)
return model, epoch_loss
def get_accuracy(model, data_loader, device):
'''Function for computing the accuracy of the predictions over the entire data_loader'''
correct_pred = 0
n = 0
with torch.no_grad(): # 临时将循环内的所有Tensor的requires_grad标志设置为False,不再计算Tensor的梯度(自动求导)
model.eval() # 将网络设置为评估模式
for X, y_true in data_loader:
X = X.to(device) # 将数据导入到指定的设备上(cpu或gpu)
y_true = y_true.to(device)
_, y_prob = model(X) # y_prob.size(): troch.Size([32, 10]): [cols, rows]
# torch.max(input):返回Tensor中所有元素的最大值
# torch.max(input, dim):按维度dim返回最大值,并且返回索引
# dim=0: 返回每一列中最大值的那个元素,并且返回索引
# dim=1: 返回每一行中最大值的那个元素,并且返回索引
_, predicted_labels = torch.max(y_prob, 1)
n += y_true.size(0)
correct_pred += (predicted_labels == y_true).sum()
return correct_pred.float() / n
def train(train_loader, model, criterion, optimizer, device):
'''Function for the training step of the training loop'''
model.train() # 将网络设置为训练模式
running_loss = 0
for X, y_true in train_loader: # 先调用DataLoader类的__iter__函数,接着循环调用_DataLoaderIter类的__next__函数
# X.size(shape: [n,c,h,w]): torch.Size([32, 1, 32, 32]); y_true.size: torch.Size([32]); n为batch_size
optimizer.zero_grad() # 将优化算法中的梯度重置为0,需要在计算下一个小批量数据集的梯度之前调用它,否则梯度将累积到现有的梯度中
# 将Tensor数据导入到指定的设备上(cpu或gpu)
X = X.to(device)
y_true = y_true.to(device)
y_hat, _ = model(X) # 前向传播:调用Module的__call__方法, 此方法内会调用指定网络(如LeNet5)的forward方法
# y_hat.size(): torch.Size([32, 10]); _.size(): torch.Size([32, 10])
loss = criterion(y_hat, y_true) # 计算loss,同上,通过__call__方法调用指定损失函数类(如CrossEntropyLoss)中的forward方法
running_loss += loss.item() * X.size(0)
loss.backward() # 反向传播,使用Autograd自动计算标量的当前梯度
optimizer.step() # 根据梯度更新网络参数,优化器通过.grad中存储的梯度来调整每个参数
epoch_loss = running_loss / len(train_loader.dataset)
return model, optimizer, epoch_loss
def training_loop(model, criterion, optimizer, train_loader, valid_loader, epochs, device, print_every=1):
'''Function defining the entire training loop
model: 网络对象
criterion: 损失函数对象
optimizer: 优化算法对象
train_loader: 训练数据集对象
valid_loader: 测试数据集对象
epochs: 重复训练整个训练数据集的次数
device: 指定在cpu上还是在gpu上运行
print_every: 每训练几次打印一次训练结果
'''
train_losses = []
valid_losses = []
for epoch in range(0, epochs):
model, optimizer, train_loss = train(train_loader, model, criterion, optimizer, device)
train_losses.append(train_loss)
# 每次训练完后通过测试数据集进行评估
with torch.no_grad(): # 临时将循环内的所有Tensor的requires_grad标志设置为False,不再计算Tensor的梯度(自动求导)
model, valid_loss = validate(valid_loader, model, criterion, device)
valid_losses.append(valid_loss)
if epoch % print_every == (print_every - 1):
train_acc = get_accuracy(model, train_loader, device=device)
valid_acc = get_accuracy(model, valid_loader, device=device)
print(f' {datetime.now().time().replace(microsecond=0)}:'
f' Epoch: {epoch}', f' Train loss: {train_loss:.4f}', f' Valid loss: {valid_loss:.4f}'
f' Train accuracy: {100 * train_acc:.2f}', f' Valid accuracy: {100 * valid_acc:.2f}')
return model, optimizer, (train_losses, valid_losses)
def train_and_save_model():
print("#### start training ... ####")
print("1. load mnist dataset")
train_loader, valid_loader, _, _ = load_mnist_dataset(img_size=32, batch_size=32)
print("2. fixed random init value")
# 用于设置随机初始化;如果不设置每次训练时的网络初始化都是随机的,导致结果不确定;如果设置了,则每次初始化都是固定的
torch.manual_seed(seed=42)
#print("value:", torch.rand(1), torch.rand(1), torch.rand(1)) # 运行多次,每次输出的值都是相同的,[0, 1)
print("3. instantiate lenet net object")
model = LeNet5(n_classes=10).to('cpu') # 在CPU上运行
print("4. specify the optimization algorithm: Adam")
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.001) # 定义优化算法:Adam是一种基于梯度的优化算法
print("5. specify the loss function: CrossEntropyLoss")
criterion = nn.CrossEntropyLoss() # 定义损失函数:交叉熵损失
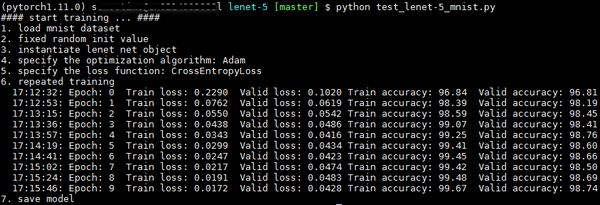
print("6. repeated training")
model, _, _ = training_loop(model, criterion, optimizer, train_loader, valid_loader, epochs=10, device='cpu') # epochs为遍历训练整个数据集的次数
print("7. save model")
model_name = "../../../data/Lenet-5.pth"
#torch.save(model, model_name) # 保存整个模型, 对应于model = torch.load
torch.save(model.state_dict(), model_name) # 推荐:只保存模型训练好的参数,对应于model.load_state_dict(torch.load)执行结果如下所示:
2.手写数字图像识别部分:
(1).加载模型,推荐使用load_state_dict,对应于保存模型时使用的state_dict;
(2).设置网络到评估模式;
(3).准备测试图像,一共10幅,0到9各一幅,如下图所示,注意:训练图像背景色为黑色,而测试图像背景色为白色:
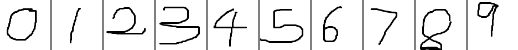
(4).依次对每幅图像进行识别。
代码段如下所示:
def list_files(filepath, filetype):
'''遍历指定目录下的指定文件'''
paths = []
for root, dirs, files in os.walk(filepath):
for file in files:
if file.lower().endswith(filetype.lower()):
paths.append(os.path.join(root, file))
return paths
def get_image_label(image_name, image_name_suffix):
'''获取测试图像对应label'''
index = image_name.rfind("/")
if index == -1:
print(f"Error: image name {image_name} is not supported")
sub = image_name[index+1:]
label = sub[:len(sub)-len(image_name_suffix)]
return label
def image_predict():
print("#### start predicting ... ####")
print("1. load model")
model_name = "../../../data/Lenet-5.pth"
model = LeNet5(n_classes=10).to('cpu') # 实例化一个网络对象
model.load_state_dict(torch.load(model_name)) # 加载模型
print("2. set net to evaluate mode")
model.eval()
print("3. prepare test images")
image_path = "../../../data/image/handwritten_digits/"
image_name_suffix = ".png"
images_name = list_files(image_path, image_name_suffix)
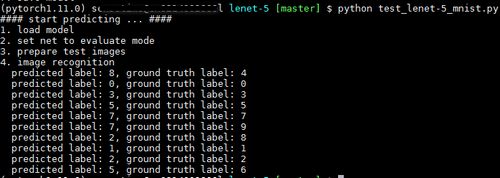
print("4. image recognition")
with torch.no_grad():
for image_name in images_name:
#print("image name:", image_name)
label = get_image_label(image_name, image_name_suffix)
img = cv2.imread(image_name, cv2.IMREAD_GRAYSCALE)
img = cv2.resize(img, (32, 32))
# MNIST图像背景为黑色,而测试图像的背景色为白色,识别前需要做转换
img = cv2.bitwise_not(img)
#print("img shape:", img.shape)
# 将opencv image转换到pytorch tensor
transform = transforms.ToTensor()
tensor = transform(img) # tensor shape: torch.Size([1, 32, 32])
tensor = tensor.unsqueeze(0) # tensor shape: torch.Size([1, 1, 32, 32])
#print("tensor shape:", tensor.shape)
_, y_prob = model(tensor)
_, predicted_label = torch.max(y_prob, 1)
print(f" predicted label: {predicted_label.item()}, ground truth label: {label}")执行结果如下图所示:
GitHub: https://github.com/fengbingchun/PyTorch_Test