C++ std::regex | 正则表达式
cppreference: https://zh.cppreference.com/w/cpp/regex
结合以下网站食用更加:
- 正则大全
- 正则解析:Regulex:JavaScript Regular Expression Visualizer
- 正则练习:regex101: build, test, and debug regex
文章目录
-
-
- 一、正则表达式的操作
- 二、主要的几个类
-
- 2.1 basic_regex 正则表达式对象
-
- 示例:
- 2.2 match_results 正则匹配结果集
-
- 示例:
- 2.3 sub_match 匹配项match_results的 一部分
-
- 示例:
- 三、算法
-
- regex_match 完整匹配
-
- 示例:
- regex_search 任意部分匹配
-
- 示例:
- regex_match 与 regex_search 区别
-
- 示例:
- regex_replace 替换
- 迭代器
-
- regex_iterator 全局匹配(匹配多个)
- 示例:
- regex_token_iterator
- 示例:反向匹配正则
- 示例:分组匹配
- 四、其他
-
一、正则表达式的操作
- 目标序列:被正则表达式搜索的目标序列。可以是二个迭代器所指定的范围、空终止字符串或一个 std::string 。
- 模式:即正则表达式。使用正则特定语法的字符串构成的 std::basic_regex 类型对象。
受支持的语法变体的描述见 syntax_option_type(定义一些匹配规则,如不区分大小写等) 。 - 匹配的结果集:关于匹配的信息使用 std::match_results 类型对象获取。
- 替换字符串:将匹配到的字符替换。受支持的语法变体的描述见 match_flag_type 。
简单示例:
#include 输出结果:

二、主要的几个类
这些类封装正则表达式和在字符的目标序列中匹配正则表达式的结果。
2.1 basic_regex 正则表达式对象
用于构建正则对象。
类型别名:
- regex == basic_regex
示例:
regex reg("") 构建用于匹配正则的表达式。
string s = "This is a simple example";
regex reg("(simple)");
string new_s = regex_replace(s, reg, "[$&]");
cout << new_s << '\n'; // This is a [simple] example
2.2 match_results 正则匹配结果集
std::match_results 保有表示正则表达式匹配结果的字符序列汇集。
类型别名:
- std::cmatch == std::match_results
- std::smatch == std::match_results
该类型从std::regex_iterator 获得,或通过 std::regex_search 或 std::regex_match 修改(传参后回写)。
std::match_results 保有 std::sub_match ,它们每个都是一对指向匹配的原初字符序列中的迭代器,故若原初字符序列被销毁,或指向它的迭代器因另外的原因非法化,则检验 std::match_results 是未定义行为。
示例:
用法:
smatch result; // string类型的mattch
regex_search(s, result, reg); // 匹配
regex_match(s, result, reg); // 完全匹配
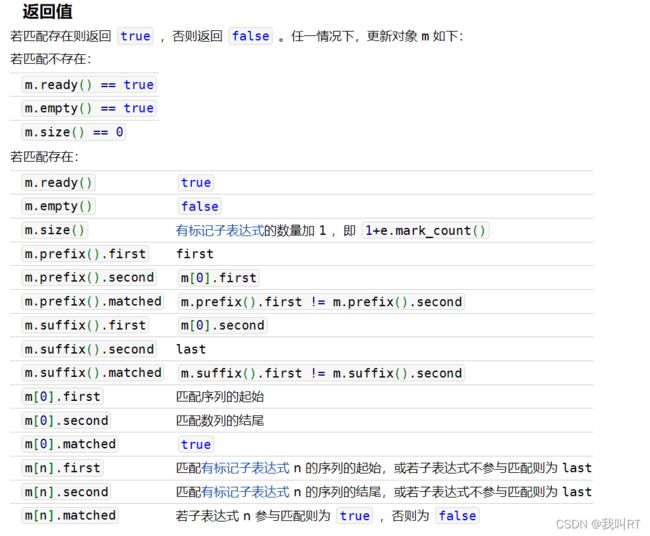
有关match_results 成员变量:https://zh.cppreference.com/w/cpp/regex/match_results
match_results成员函数
string s = "This is a simple example"; /* 目标序列 */
smatch result; /* 结果集 */
regex reg("(\\w{5,})"); /* 模式串 */
regex_search(s, result, reg);
cout << "regex_search(s, result, reg)\n";
cout << "\n状态:";
cout << "\n-- 检查结果是否合法(合法为 true) result.ready() = " << result.ready();
cout << "\n\n大小:";
cout << "\n-- 检查匹配是否成功(失败匹配则为 true) result.empty() = " << result.empty();
cout << "\n-- 返回完全建立的结果状态中的匹配数 result.size() = " << result.size();
cout << "\n-- 返回子匹配的最大可能数量 result.max_size() = " << result.max_size();
cout << "\n\n元素访问:";
cout << "\n-- 返回特定子匹配的长度 result.length() = " << result.length();
cout << "\n-- 返回特定子匹配首字符的位置 result.position() = " << result.position();
cout << "\n-- 返回特定子匹配的字符序列 result.str() = " << result.str();
cout << "\n-- 返回指定的子匹配 result[0] = " << result[0];
cout << "\n-- 返回目标序列起始和完整匹配起始之间的子序列 result.prefix() = " << result.prefix();
cout << "\n-- 返回完整匹配结尾和目标序列结尾之间的子序列 result.suffix() = " << result.suffix();
cout << "\n\n迭代器:";
cout << "\n--返回指向子匹配列表起始的迭代器 result.begin()/cbegin()";
cout << "\n--返回指向子匹配列表末尾的迭代器 result.end()/cend()";
cout << "\n\n其他:";
cout << "\n--为输出格式化匹配结果 result.format";
cout << "\n--交换内容 result.swap()";
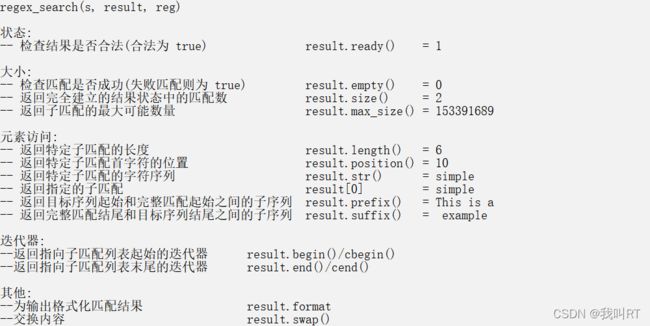
如果regex_search(s, result, reg);匹配失败,size为0,empty为true。

并且通过上述输出可知,result 的size即使为0,仍然可以通过下标访问其元素(下标返回的对象类型是sub_match)。
regex_search(s, result, reg);
cout << result.size() << "\n"; // 匹配到的个数
cout << result[0].matched << "\n"; // 匹配是否成功,返回bool
通过VS 调试窗口可以证实这一点(match_results 内部由 sub_match组成)

2.3 sub_match 匹配项match_results的 一部分
sub_match 的实例作为 std::match_results 容器的一部分正常构造并移居。
类型别名:
- csub_match == sub_match
- ssub_match == sub_match
该对象继承自std::pair,first保存子表达式匹配序列的开始,second保存匹配序列的结尾后一位置。
- length 若存在则返回匹配的长度
- str 转换为底层字符串类型
- compare 若存在则比较匹配的子序列
示例:
regex_search(s, result, reg);
// 输出类型信息
cout << typeid(result.str()).name() << "\n"; // std::basic_string
cout << typeid(result[0]).name() << "\n"; // std::sub_match
for (ssub_match sub : result) // 遍历所有结果
{
cout << "是否匹配成功:" << sub.matched << "\n";
cout << "匹配到的内容:" << sub.str() << "\n";
cout << "匹配到的长度:" << sub.length() << "\n";
cout << sub.compare("simple") << "\n"; // 等价于string::compare. 返回 -1,0,1
}

三、算法
这些算法将封装于 regex 的正则表达式应用到字符的目标序列。
match_result 中所含的首个 sub_match (下标 0 )始终表示 regex 所做的目标序列内的完整匹配,而后继的 sub_match 表示按顺序对应分隔正则表达式中子表达式的左括号的子表达式匹配
regex_match 完整匹配
尝试匹配一个正则表达式到整个字符序列

示例:
string ss[] = { "foo.txt", "bar.txt", "baz.dat", "zoidberg" };
// 提取几个子匹配
regex reg("([a-z]+)\\.([a-z]+)"); // 匹配xxx.xxx 格式的字符串
smatch result;
for (const auto& s : ss) {
if (regex_match(s, result, reg)) {
cout << s << '\n';
for (size_t i = 0; i < result.size(); ++i) {
ssub_match sub_match = result[i];
string piece = sub_match.str();
cout << " submatch " << i << ": " << piece << '\n';
}
}
}

注意这里每个匹配项输出了3个,其中result[0]是完整匹配,其他是匹配成功后根据(进行分组的项。
regex_search 任意部分匹配
尝试匹配一个正则表达式到字符序列的任何部分
示例:
string log(R"(
Speed: 366
Mass: 35
Speed: 378
Mass: 32
Speed: 400
Mass: 30)");
regex reg(R"(Speed:\t\d*)");
smatch sm;
while (regex_search(log, sm, reg))
{
cout << sm.str() << '\n';
log = sm.suffix(); // sm.suffix() 是剩余的字符串
}

// C 风格字符串演示
cmatch cm;
if (regex_search("this is a test", cm, regex("test")))
cout << "\nFound " << cm[0] << " at position " << cm.prefix().length();
// Found test at position 10
regex_match 与 regex_search 区别
- regex_match 只考虑完全匹配,只有目标串与模式串完全匹配才会返回True,并将结果集回填到 result 中。
- regex_search 只要匹配到重合部分,就判定为匹配成功。
示例:
regex re("Get|GetValue");
cmatch m;
regex_search("GetValue", m, re); // 返回 true ,且 m[0] 含 "Get"
regex_match ("GetValue", m, re); // 返回 true ,且 m[0] 含 "GetValue"
regex_search("GetValues", m, re); // 返回 true ,且 m[0] 含 "Get"
regex_match ("GetValues", m, re); // 返回 false
上述 regex_match 匹配时,模式串为 Get 或 GetValue。 进行正则匹配时:
GetValues,或 GetValues 都只匹配到整个单词的一部分,因此是不完全匹配,regex_match 认为是匹配失败。
而 regex_search 只要匹配到单词的一部分,就算匹配成功。
regex_replace 替换
以格式化的替换文本来替换正则表达式匹配的出现位置
int main()
{
string text = "Quick brown fox";
regex vowel_re("a|e|i|o|u");
// 写结果到输出迭代器
regex_replace(ostreambuf_iterator<char>(cout),
text.begin(), text.end(), vowel_re, "*");
// 构造保有结果的字符串
cout << '\n' << regex_replace(text, vowel_re, "[$&]") << '\n';
}
迭代器
regex_iterator 用于遍历在序列中找到的匹配正则表达式的整个集合。
regex_iterator 全局匹配(匹配多个)
迭代一个字符序列中的所有正则表达式匹配。
类型别名:
- cregex_iterator == regex_iterator
- sregex_iterator == regex_iterator
示例:
使用 regex_iterator 创建的迭代器,会自动进行正则匹配,并在 ++ 操作时,从上一次匹配到的位置继续进行正则匹配。
const string s = "This is a simple example.";
regex reg("[^\\s]+"); // 匹配单词
auto words_begin = sregex_iterator(s.begin(), s.end(), reg);
auto words_end = sregex_iterator();
cout << "size = " << distance(words_begin, words_end);
for (sregex_iterator i = words_begin; i != words_end; ++i) {
cout << i->str() << " ";
}
cout << endl;
/* 输出
size = 5
This is a simple example.
*/
regex_token_iterator
迭代给定字符串中的所有正则表达式匹配中的指定子表达式,或迭代未匹配的子字符串
示例:反向匹配正则
注意 sregex_token_iterator 最后一个参数,表示第几组。
当最后一个参数为 -1 时,则结果集中保存所有不匹配正则表达式的部分,类似 split 函数切割字符串。
const string s = "This_is_a_simple_example.";
regex reg("_+"); // 匹配下划线
auto words_begin = sregex_token_iterator(s.begin(), s.end(), reg, -1);
auto words_end = sregex_token_iterator();
cout << "size = " << distance(words_begin, words_end) << "\n";
for (sregex_token_iterator i = words_begin; i != words_end; ++i) {
cout << i->str() << " ";
}
cout << endl;
/* 输出
size = 5
This is a simple example.
*/
示例:分组匹配
第四个参数如果不填,默认为 0, 等同于不分组。
// 正则reg中,一个封闭`(`视为一个分组
regex reg("_+"); // 不加括号,没有分组
regex reg("(_+)"); // 有括号,只有一个分组
- 对于没有分组的,
sregex_token_iterator(s.begin(), s.end(), reg);第四个参数需要不填,或填为0 才能匹配到 reg。 - 对于有有分组的:
- 参数为 0,匹配所有分组
- 参数为1,匹配第一个分组
- 参数为2,匹配第二个分组
- …
- 参数为n,如果分组不足n,则不匹配
- 参数为-1,则匹配与reg相反的。
参考下列示例:
const string s = "foo.txt, bar.txt, baz.dat, zoidberg";
regex reg("([a-z]+)\\.([a-z]+)"); // 两个分组,匹配 xxx.xxx 格式
using reg_iter = sregex_token_iterator;
cout << "is -1 : ";
for (auto i = reg_iter(s.begin(), s.end(), reg, -1); i != reg_iter(); ++i) {
cout << i->str() << " ";
}
cout << "\nis 0 : ";
for (auto i = reg_iter(s.begin(), s.end(), reg, 0); i != reg_iter(); ++i) {
cout << i->str() << " ";
}
cout << "\nis 1 : ";
for (auto i = reg_iter(s.begin(), s.end(), reg, 1); i != reg_iter(); ++i) {
cout << i->str() << " ";
}
cout << "\nis 2 : ";
for (auto i = reg_iter(s.begin(), s.end(), reg, 2); i != reg_iter(); ++i) {
cout << i->str() << " ";
}
cout << "\nis 3 : ";
for (auto i = reg_iter(s.begin(), s.end(), reg, 3); i != reg_iter(); ++i) {
cout << i->str() << " ";
}

四、其他
异常:
- 此类定义作为异常抛出以报告来自正则表达式库错误的类型。
- regex_error 报告正则表达式库生成的错误
特征:
- regex_traits 类用于封装 regex 的本地化方面。
- regex_traits 提供正则表达式库所需的关于字符类型的元信息
常量
- 定义于命名空间 std::regex_constants
- syntax_option_type 控制正则表达式行为的通用选项
- match_flag_type 特定于匹配的选项
- error_type 描述不同类型的匹配错误