时间序列异常检测- 基于KDD99数据集的实战
一. 介绍
异常检测(Anomaly detection)是目前时序数据分析最成熟的应用之一,定义是从正常的时间序列中识别不正常的事件或行为的过程。有效的异常检测被广泛用于现实世界的很多领域,例如量化交易,网络安全检测、自动驾驶汽车和大型工业设备的日常维护。
基础上,将会呈现之前提及的一些深度/传统机器学习算法模型基于KDD99以及NSL_KDD数据集的性能表现,并结合具体数据情况给出各个模型的评估结果,并做一个总结。
二. KDD数据集
- KDDCup99
介绍:https://blog.csdn.net/abrohambaby/article/details/78702512
下载链接:KDD Cup 1999 Data
全集很大有约500w数据,建议使用10%的这个data files 大约50w数据量,用于检验模型性能比较合理。

- NSL_KDD
介绍: https://www.unb.ca/cic/datasets/nsl.html
下载链接:https://github.com/defcom17/NSL_KDD
NSL_KDD在KDDCup99数据集的基础上进行了一下改进:

通常选择这两个数据集作为Training data 和 Testing data:

三. 数据预处理
对于连续数值,我们使用scikit-learn库提供的MinMaxScaler来对数值进行归一化
至于离散数值,我们使用一种One-Hot编码。 encode_text函数可实现此目的。
# Helper function for scaling continous values
def minmax_scale_values(training_df,testing_df, col_name):
scaler = MinMaxScaler()
scaler = scaler.fit(training_df[col_name].values.reshape(-1, 1))
train_values_standardized = scaler.transform(training_df[col_name].values.reshape(-1, 1))
training_df[col_name] = train_values_standardized
test_values_standardized = scaler.transform(testing_df[col_name].values.reshape(-1, 1))
testing_df[col_name] = test_values_standardized
#Helper function for one hot encoding
def encode_text(training_df,testing_df, name):
training_set_dummies = pd.get_dummies(training_df[name]) # get_dummies 是利用pandas实现one hot 编码的方式
testing_set_dummies = pd.get_dummies(testing_df[name])
for x in training_set_dummies.columns:
dummy_name = "{}_{}".format(name, x)
training_df[dummy_name] = training_set_dummies[x]
if x in testing_set_dummies.columns :
testing_df[dummy_name]=testing_set_dummies[x]
else :
testing_df[dummy_name]=np.zeros(len(testing_df))
training_df.drop(name, axis=1, inplace=True)
testing_df.drop(name, axis=1, inplace=True)
sympolic_columns=["protocol_type","service","flag"]
label_column="Class"
for column in df.columns :
if column in sympolic_columns:
encode_text(training_df,testing_df, column)
elif not column == label_column:
minmax_scale_values(training_df,testing_df, column)四.建模
4.1 基于 AE 自编码器的时间序列异常检测代码实现(Tensorflow,Keras前端接口)
- 模型介绍
为了避免训练数据中代表每种攻击类型的样本不平衡,并避免模型无法通过观察现有攻击类型来学习新的攻击类型,我们提出一种利用AE自动编码器和重构误差来检测异常的方法。
在这种方法中,我们实现了带有输入缺失的稀疏自动编码器,它由122个神经元的输入层组成,这是因为每个样本的特征数量为122,然后是缺失层和8个神经元单元的隐藏层.因此,自动编码器的隐藏表示形式具有122/8的压缩比,迫使其学习有趣的模式和特征之间的关系,最后有122个单元的输出层,隐藏层和输出层的激活函数是relu。
对自动编码器进行了训练以重建其输入,换言之,它学习了身份函数,仅使用训练数据集中标有“正常”的样本对模型进行了训练,从而可以捕获正常行为的性质,这是通过训练模型以最小化其输出和输入之间的均方误差 MSE (mean squared error)。
在自动编码器上施加的正则化约束阻止了它简单地将输入复制到输出并过度拟合数据,此外,输入上出现的缺失使自动编码器成为去噪自动编码器的特殊情况,这种自动编码器经过训练可以重建输入从本身已失真的损坏版本中删除,迫使自动编码器学习更多数据属性。
有关算法细节我觉得张老师这篇讲的挺好的,大家可以拓展看看。
张戎:基于自编码器的时间序列异常检测算法195 赞同 · 47 评论文章
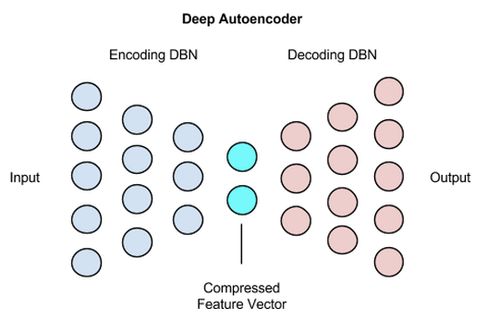
- 训练
使用Adam优化器(batch大小为100)对模型进行了10个epoch的训练,此外,我们保留了10%的正常训练样本作为 validation data 来验证模型的效果。
def getModel():
input_layer = Input(shape=(x.shape[1],))
encoded = Dense(8, activation='relu', activity_regularizer=regularizers.l2(10e-5))(input_layer) # l2正则化约束
decoded = Dense(x.shape[1], activation='relu')(encoded)
autoencoder = Model(input_layer, decoded)
autoencoder.compile(optimizer='adam', loss='mean_squared_error')
return autoencoder
autoencoder = getModel()
history = autoencoder.fit(
x[np.where(y0==0)],x[np.where(y0==0)],
epochs=10,
batch_size=100,
shuffle=True,
validation_split=0.1
)基本到第三个Epoch就开始收敛了,训练速度很比较快,基于NSL_KDD的话大概一个epoch控制在 15s 以内。
- 预测
该模型通过计算样本的重构误差来执行异常检测,因为该模型是使用正常数据样本训练的,所以与正常数据样本的重构误差相比,代表攻击的样本的重构误差应该相对较高,这种直觉使我们能够通过为重构误差设置阈值来检测攻击,如果数据样本的重构误差高于预设阈值,则将该样本归类为攻击,否则将其归类为正常流量。
对于阈值的选择,两个值可以帮助指导过程,即训练数据集和验证数据集的Loss,我们通过实验发现围绕这些值的选择会产生可接受的结果,对于我们的实验,我们将模型训练数据的Loss设定为阈值。
由于这种方法的性质,它只能用于2类分类,因为它仅用于异常检测而不是分类。
下面评估测试数据集的性能,calculate_losses是一个辅助函数,该函数接受原始特征和预测特征(自动编码器的输出)并返回每个数据样本的重构损失,然后根据每个数据样本对其的分类重建误差和预设阈值。
# calculate_losses是一个辅助函数,计算每个数据样本的重建损失
def calculate_losses(x, preds):
losses = np.zeros(len(x))
for i in range(len(x)):
losses[i] = ((preds[i] - x[i]) ** 2).mean(axis=None)
return losses
# 我们将阈值设置为等于自动编码器的训练损失
threshold = history.history["loss"][-1]
testing_set_predictions=autoencoder.predict(x_test)
test_losses=calculate_losses(x_test,testing_set_predictions)
testing_set_predictions=np.zeros(len(test_losses))
testing_set_predictions[np.where(test_losses>threshold)]=1- 评估
为了评估模型,我们计算以下性能指标:Accuracy Recall Precision F1 Score
recall=recall_score(y0_test,testing_set_predictions)
precision=precision_score(y0_test,testing_set_predictions)
f1=f1_score(y0_test,testing_set_predictions)
print("Performance over the testing data set \n")
print("Accuracy : {} \nRecall : {} \nPrecision : {} \nF1 : {}\n".format(accuracy,recall,precision,f1 ))- 小结
在这种方法中,我们试图克服KDD99和NSL-KDD数据集中存在的问题,即类不平衡问题和数据与实际不太相符,通过避免训练期间的攻击数据,仅使用正常流量对模型进行训练,因此它不受数据集类别不平衡的影响,此外,它仅使用常规流量数据进行训练这一事实使它在现实世界的应用程序中更有价值,并且在实际网络中使用时更可行。
这种方法的另一个优势是它的简单性,它仅由8个神经元的单个隐藏层组成,因此非常易于训练,特别适合在线学习。在评估过程中,我们避免了人工操作阈值以实现可重现的结果而不会受到人工干扰,但是在实际网络中,当部署系统时,网络管理员可以手动调整阈值,从而可以根据网络需求在灵敏度和特异性之间进行权衡与其他现有方法相比,这是一个巨大的优势。在检测率方面,AE的性能也很显著。
此方法的明显局限性在于它只能区分正常流量和攻击流量(二分类器而非多分类器),因此无法将攻击分类为不同的攻击类型,可以通过建立模型的集合以及其他扩展模型来完成克服此限制的工作。其功能才能实现5级分类。
- 补充
此外类似的模型还有基于VAE的改进模型Dount,链接如下
https://github.com/NetManAIOps/donutgithub.com/NetManAIOps/donut
感兴趣的朋友可以自己深入去了解下,整体来说自编码器类模型在执行基于重构误差的时间序列异常检测上的效果还是很不错的,业界(AIOps)和学界(清华裴丹)都有很广泛的应用。
4.2 基于 LSTM_CNN 的时间序列异常检测代码实现(Tensorflow,Keras前端接口)
- 模型介绍
CNN LSTM结构涉及在输入数据中使用卷积神经网络(CNN)层做特征提取并结合LSTM来支持序列预测。CNN LSTMs开发用来时间序列预测问题(NLP领域应用更广泛)和图像序列生成文本描述的应用(例如:视频),但是也没有人说不能在KPIs时间序列异常检测场景应用,对吧~ 所以我也基于KDD数据集试了一下。
这种架构最初被称为长期卷积神经网络(Long-term Recurrent Convolutional Network)或者LRCN模型。尽管我们将使用更通用的名为CNN-LSTM来指代本课中使用的CNN作为前段的LSTM模型。该体系结构的关键是使用CNN模型做特征提取,LSTM模型帮助模型学习跨时间步长的特征。
1.LSTM
长短时记忆(LSTM)模型是循环神经网络(recurrent neural network, RNN)的一种特殊形式,可在每个神经元处提供反馈。RNN的输出不仅取决于当前神经元的输入和权重,还取决于先前神经元的输入。因此,从理论上讲,RNN结构通常适用于处理时间序列数据。然而,在处理一系列长期相关的数据样本时,RNN会出现梯度爆炸和梯度消失问题 ,这成为后来引入LSTM模型的关键点。
为了克服RNN模型的梯度消失问题,LSTM模型包含贮存有用信息和丢弃无用信息的内部循环。LSTM模型的流程图中有四个重要元素:单元状态,输入门,遗忘门和输出门。输入、遗忘和输出门用于控制单元状态中包含信息的更新,维护和删除。前向计算过程可以表示为:


其中Ct,Ct−1和C˜t分别表示当前单元状态值,上一时刻的单元状态值和当前单元状态值的更新。符号ft,it和ot分别表示遗忘门,输入门和输出门。在适当的参数设置下,根据等式(4)~(6),基于C˜t和Ct的值计算输出值ht。根据输出值与实际值之间的差值,所有的权重矩阵通过时间反向传播算法(back-propagation through time, BPTT)进行更新。
2.CNN
卷积神经网络(CNN)可能是最常用的深度学习神经网络,目前主要应用于计算机视觉领域的图像识别/分类主题。对于大量原始数据样本,CNN通常能够有效地提取输入数据的有用子集。一般来说,CNN仍然是前馈神经网络,由多层神经网络(multi-layer neural network, MLNN)扩展而来。CNN与传统MLNN的主要区别在于CNN具有稀疏交互和参数共享的特性。
传统MLNN使用全连接策略在输入层和输出层之间建立神经网络,这意味着每个输出神经元都有机会与每个输入神经元进行交互。假设有m个输入神经元和n个输出神经元,权重矩阵有 m×n 个参数。CNN通过设置大小为 k×k的卷积核大大减少权重矩阵的参数。CNN的两个属性提高了参数优化的训练效率;在相同的计算复杂度下,CNN能够训练具有更多隐藏层的神经网络,即深层神经网络。
时态卷积神经网络引入了特殊的一维卷积,适用于处理单变量时间序列数据。时态CNN不像传统CNN那样使用 k×k卷积核,而是使用大小为 k×1的卷积核。经过时间卷积运算之后,原始的单变量数据集可以扩展为m维特征的数据集。这样,时态CNN将一维卷积应用于时间序列数据,并将单变量数据集扩展为多维提取的特征;扩展后的多维特征数据更适合使用LSTM进行预测。
因此我们基于Keras框架定义了一个CNN LSTM模型:
#import data
traindata = pd.read_csv('./data/kddtrain.csv', header=None)
testdata = pd.read_csv('./data/kddtest.csv', header=None)
X = traindata.iloc[:,1:42]
Y = traindata.iloc[:,0]
C = testdata.iloc[:,0]
T = testdata.iloc[:,1:42]
scaler = Normalizer().fit(X)
trainX = scaler.transform(X)
scaler = Normalizer().fit(T)
testT = scaler.transform(T)
y_train1 = np.array(Y)
y_test1 = np.array(C)
y_train= to_categorical(y_train1)
y_test= to_categorical(y_test1)
# reshape input to be [samples, time steps, features]
X_train = np.reshape(trainX, (trainX.shape[0],trainX.shape[1],1))
X_test = np.reshape(testT, (testT.shape[0],testT.shape[1],1))- 训练
-
# train the model # define parameters verbose, epochs, batch_size = 1, 10, 1000 n_timesteps, n_features, n_outputs = X_train.shape[1], X_train.shape[2],1 # 122,1,1 # reshape output into [samples, timesteps, features] y_train = y_train.reshape((y_train.shape[0], 1, 1)) # define model lstm_cnn = Sequential() lstm_cnn.add(Conv1D(filters=64, kernel_size=3, activation='relu', input_shape=(n_timesteps,n_features))) lstm_cnn.add(Conv1D(filters=64, kernel_size=3, activation='relu')) lstm_cnn.add(MaxPooling1D(pool_size=2)) lstm_cnn.add(Flatten()) lstm_cnn.add(RepeatVector(n_outputs)) model.add(LSTM(200, activation='relu', return_sequences=True)) lstm_cnn.add(Dropout(0.1)) lstm_cnn.add(Dense(1, activation='sigmoid')) lstm_cnn.compile(loss="binary_crossentropy", optimizer="adam", metrics=['accuracy']) # set checkpoint checkpointer = callbacks.ModelCheckpoint(filepath="results/lstm_cnn_results/checkpoint-{epoch:02d}.hdf5", verbose=1, save_best_only=True, monitor='val_acc',mode='max') # set logger csv_logger = CSVLogger('results/lstm_cnn_results/cnntrainanalysis1.csv',separator=',', append=False) # fit network lstm_cnn.fit( X_train, y_train, epochs=epochs, batch_size=batch_size, verbose=verbose, validation_split=0.1, callbacks=[checkpointer,csv_logger])binary_crossentropy是交叉熵损失函数,一般用于二分类的损失计算: 这个是针对概率之间的损失函数,你会发现只有预测值和y相等时loss才为0,否则loss就是为一个正数。 而且,概率相差越大,loss就越大。(如果出现负数说明X或者y没有归一化)
-
y_pred = lstm_cnn.predict_classes(X_test) y_pred = y_pred[:,0] accuracy = accuracy_score(y_test,y_pred) recall = recall_score(y_test,y_pred, average="binary") precision = precision_score(y_test,y_pred, average="binary") f1 = f1_score(y_test,y_pred, average="binary") print("Performance over the testing data set \n") print("Accuracy : {} \nRecall : {} \nPrecision : {} \nF1 : {}\n".format(accuracy,recall,precision,f1 )) - 小结
-
模型受到数据集类不均衡影响,Recall分数较AE低说明放过了许多attack没有检测出来,间接影响F1 = 2precisionrecall/(precision+recall) 也不如AE模型。
另一个劣势在于网络相对较复杂一些,训练时间会相对比较长。
但是一个优势在于可以做多分类器,如果想要实现5级分类也是可以做到的
- 附加
-
LSTM-CNN在疾病预测问题方向的应用:《基于混合深度学习算法的疾病预测模型 - Disease Prediction Models Based on Hybrid Deep Learning Strategy》
基于混合深度学习算法的疾病预测模型m.hanspub.org/journal/paper/34067

4.3 基于 DAGMM 的时间序列异常检测代码实现(Tensorflow)
参考论文:《DEEP AUTOENCODING GAUSSIAN MIXTURE MODEL FOR UNSUPERVISED ANOMALY DETECTION》
论文链接:https://openreview.net/pdf?id=BJJLHbb0-
- 模型介绍
-
在论文中,提出了深度自动编码高斯混合模型(DAGMM),这是一个深度学习框架,从几个方面解决了无监督异常检测中的上述挑战。
首先,DAGMM在低维空间中保留输入样本的关键信息,该低维空间包括由维数减少和诱导重建误差发现的减小维度的特征。从图1所示的例子中,我们可以看到异常在两个方面与正常样本不同:
(1)异常可以在缩小的维度中显着偏离,其特征以不同的方式相关;
(2)与正常样本相比,异常难以重建。与仅涉及具有次优性能的方面之一(Zimek等人(2012); Zhai等人(2016))的现有方法不同,DAGMM利用称为压缩网络的子网络通过自动编码器执行降维,通过连接来自编码的减少的低维特征和来自解码的重建误差,为输入样本准备低维表示。

其次,DAGMM在学习的低维空间上利用高斯混合模型(GMM)来处理具有复杂结构的输入数据的密度估计任务,这对于现有工作中使用的简单模型来说相当困难(Zhai等人(2016) ))。虽然GMM具有强大的能力,但它也在模型学习中引入了新的挑战。由于GMM通常通过诸如期望最大化(EM)(Huber(2011))等交替算法来学习,因此难以进行维数降低和密度估计的联合优化,为了让GMM模型更好得学习,GMM学习通常退化为传统的两步做法:DAGMM利用称为估计网络(Estimation Network)的子网络,该子网络从压缩网络(Compression Network)获取Input得低维输入并输出每个样本的 ”混合成员预测“(mixture membership prediction)。利用预测样本的membership ,我们可以直接估计GMM的参数,便于评估输入样本的能量/然似。通过同时最小化来自压缩网络的重建误差和来自估计网络的样本然似/能量。
- OVERVIEW
-
深度自动编码高斯混合模型(DAGMM)由两个主要部分组成:压缩网络和估计网络。 如图2所示,DAGMM的工作原理如下:

(1)压缩网络通过深度自动编码器对输入样本进行降维,从缩小的空间和重建误差特征中准备它们的低维表示,并将表示提供给随后的估算网络;
(2)估计网络采用馈送,并在高斯混合模型(GMM)的框架中预测它们的似然(Energy)
- 训练
-
Fit Data to DAGMM Model
next three points are different from original paper:
- hiddens layers dimensions : [120,60,30,1] (original paper = [60,30,10,1])
- 2 = 0.0001 (original paper = 0.005)
- Add small value(10−6) to diagonal elements of GMM covariance (paper: no additional value)
- Standard Scaler is applied to input data (This DAGMM implementation default) -
model = DAGMM( comp_hiddens=[60, 30,10, 1], comp_activation=tf.nn.tanh, est_hiddens=[10, 4], est_dropout_ratio=0.5, est_activation=tf.nn.tanh, learning_rate=0.005, epoch_size=200, minibatch_size=1024, random_seed=42 ) model.fit(X_train)源代码可以参考一下这个日本人的https://github.com/tnakae/DAGMM/blob/master/KDDCup99.ipynb
- 预测
-
同样这个模型我们基于重构误差来对结果进行异常判断,通过百分位函数(percentile)界定小于或等于某个阈值(thleshold)的预测值占总预测数的百分比。
-
y_pred = model.predict(X_test) # Energy thleshold to detect anomaly = 80% percentile of energies anomaly_energy_threshold = np.percentile(y_pred, 80) # 百分位数函数,至少有80%的数据项小于或等于这个值,并且至少有20%的数据项大于或等于这个值 print(f"Energy thleshold to detect anomaly : {anomaly_energy_threshold:.3f}") # Detect anomalies from test data y_pred_flag = np.where(y_pred > anomaly_energy_threshold, 1, 0)prec, recall, fscore, _ = precision_recall_fscore_support(y_test, y_pred_flag, average="binary") print(f" Precision = {prec:.3f}") print(f" Recall = {recall:.3f}") print(f" F1-Score = {fscore:.3f}") - 小结
-
最后,DAGMM对端到端训练很友好。通常,通过端到端训练很难学习深度自动编码器,因为它们很容易陷入不那么有吸引力的局部最佳状态,因此学界和业界广泛采用预训练来避免这一现象。但是,预训练限制了调整降维行为的可能性,因为很难通过微调对训练有素的自动编码器进行任何重大改变。我们的实证研究表明,DAGMM通过端到端训练得到了充分的学习,因为估计网络引入的正则化极大地帮助压缩网络中的自动编码器摆脱了不太吸引人的局部最优解。
几个公共基准数据集的实验表明,DAGMM具有优于现有技术的卓越性能,异常检测的F1得分提高了14%。此外,我们观察到端到端训练中DAGMM中自动编码器的重建误差与其预训练对应的重建误差一样低,而来自估计网络没有正则化的自动编码器的重建误差保持不变高。此外,端到端训练的DAGMM明显优于依赖于预先训练的自动编码器的所有基线方法。
Table 2: Average precision, recall, and F1 from DAGMM and the baseline methods. For each metric,the best result is shown in bold.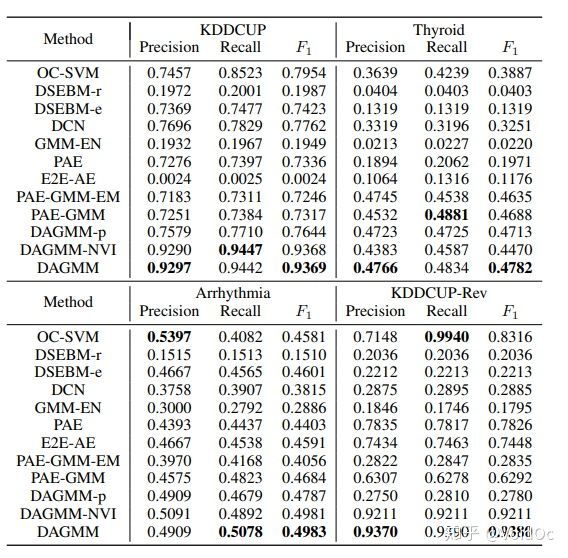
4.4 基于 One-Class SVM 的时间序列异常检测代码实现
和AE、Isolation Forest一样,One-Class SVM可以做单样本检测,这个算法的思路非常简单,就是寻找一个超平面将样本中的正例圈出来,预测就是用这个超平面做决策,在圈内的样本就认为是正样本。由于核函数计算比较耗时,在海量数据的场景用的并不多;
- 模型介绍
-
One Class SVM也是属于支持向量机大家族的,但是它和传统的基于监督学习的分类回归支持向量机不同,它是无监督学习的方法,也就是说,它不需要我们标记训练集的输出标签。
那么没有类别标签,我们如何寻找划分的超平面以及寻找支持向量机呢?One Class SVM这个问题的解决思路有很多。这里只讲解一种特别的思想SVDD,对于SVDD来说,我们期望所有不是异常的样本都是正类别,同时它采用一个超球体而不是一个超平面来做划分,该算法在特征空间中获得数据周围的球形边界,期望最小化这个超球体的体积,从而最小化异常点数据的影响。
假设产生的超球体参数为中心 o 和对应的超球体半径 r >0,超球体体积V(r) 被最小化,中心 o 是支持行了的线性组合;跟传统SVM方法相似,可以要求所有训练数据点xi到中心的距离严格小于r。但是同时构造一个惩罚系数为 C 的松弛变量 ζi ,优化问题如下图所示
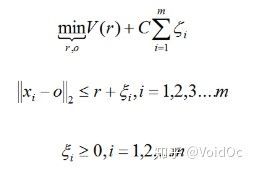
采用拉格朗日对偶求解之后,可以判断新的数据点 z 是否在内,如果 z 到中心的距离小于或者等于半径 r ,则不是异常点,如果在超球体以外,则是异常点。
在Sklearn中,我们可以采用SVM包里面的OneClassSVM来做异常点检测。OneClassSVM也支持核函数,所以普通SVM里面的调参思路在这里也使用。
- 训练
-
需要注意的是在建模前需要设定训练误差nu (在(0, 1]范围内),表示异常点比例;然后kernel一般用高斯核,核计算很费时间做好心理准备。
-
# we're using a one-class SVM, so we need.. a single class. the dataset 'label' # column contains multiple different categories of attacks, so to make use of # this data in a one-class system we need to convert the attacks into # class 1 (normal) and class -1 (attack) data.loc[data['label'] == "normal.", "attack"] = 1 data.loc[data['label'] != "normal.", "attack"] = -1 # grab out the attack value as the target for training and testing. since we're # only selecting a single column from the `data` dataframe, we'll just get a # series, not a new dataframe target = data['attack'] # find the proportion of outliers we expect (aka where `attack == -1`). because # target is a series, we just compare against itself rather than a column. outliers = target[target == -1] print("outliers.shape", outliers.shape) print("outlier fraction", outliers.shape[0]/target.shape[0]) # drop label columns from the dataframe. we're doing this so we can do # unsupervised training with unlabelled data. we've already copied the label # out into the target series so we can compare against it later. data.drop(["label", "attack"], axis=1, inplace=True) # check the shape for sanity checking. data.shape from sklearn.model_selection import train_test_split train_data, test_data, train_target, test_target = train_test_split(data, target, train_size = 0.8) train_data.shape from sklearn import svm # set nu (which should be the proportion of outliers in our dataset) nu = outliers.shape[0] / target.shape[0] print("nu", nu) model = svm.OneClassSVM(nu=nu, kernel='rbf', gamma=0.00005) model.fit(train_data) - 调参
- 评估
-
一些参数的介绍可以从https://www.cnblogs.com/wj-1314/p/10701708.html上了解一下,我这里不展开讲了。
-
preds = model.predict(test_data) targs = test_target print("accuracy: ", metrics.accuracy_score(targs, preds)) print("precision: ", metrics.precision_score(targs, preds)) print("recall: ", metrics.recall_score(targs, preds)) print("f1: ", metrics.f1_score(targs, preds)) print("area under curve (auc): ", metrics.roc_auc_score(targs, preds)) - 小结
- 从理论上说,它只能对一个时间序列单独训练一个模型,不同类型的时间序列需要使用不同的模型。这样的话,其实维护模型的成本比较高,不太适用于大规模的时间序列异常检测场景;
- 对周期型的曲线效果比较好,如果是毛刺型的数据,有可能就不太适用;因为长期的毛刺型数据就可以看成正常的数据了。
- 每次调参需要人为设置一定的阈值,或者根据训练loss的收敛值来定义,这就导致了不同的时间序列(或者每次训练后)所定的阈值是变化的。
-
5 补充
5.1 重构误差阈值设定的方法
本文涉及了两种定义重构误差阈值的方法,我还想给大家补充讲一下。
a)百分比阈值Percentile:
Doyle于1962年提出的P-Tile (即P分位数法)可以说是最古老的一种阈值选取方法。该方法根据先验概率来设定阈值,使得二值化后的目标或背景像素比例等于先验概率,比如训练集中我们知道异常占比80%,所以测试集中就把重构误差从小到大排序,前20%正常,后80%异常;又比如在CV领域,已知目标或背景像素比例等于先验概率;更简单的讲就是在找阈值前已经知道,目标或背景占整幅图比率多少。
该方法简单高效,但是对于先验概率难于估计的数据集却无能为力,所以对于先验概率不知道的场景不建议选用此方法。
b)训练loss收敛后的极值
上面介绍了基于自编码器的异常检测的基本原理,是利用异常数据在通过自动编码器 编码与解码 过程中所产生的较大波动(重构误差更大,大于阈值)来实现异常检测。那么如何合理设置重构误差阈值,才能够准确地检测出异常呢?
由于咱们的训练数据中只包含正常样本,其中一个方法就是可以将阈值设置为等于自动编码器的训练损失, 然后测试集中每个数据样本的重建损失跟阈值进行比对,超过阈值的认定为异常。
除此之外,在CV领域还有专家认为在输入图像和重构图像之间的 L2 距离上设置阈值可以有效检测出攻击图像等等。
阈值的选择一直是堪比调参的一门玄学学问,需要通过多次实验,或者基于所谓的”专家经验“在假阳性和假阴性检测率中进行权衡,从而使得模型的检测效果最优化。
6 总结需要在假阳性和假阴性检测率中进行权衡
通常来说,在时间序列异常检测场景中,异常的比例相对于正常的比例而言都是非常稀少的。因此,除了有监督算法(分类,回归)之外,基于无监督算法的异常检测算法也是必不可少的。除了 HoltWinters,ARIMA 等算法之外,一些单样本二分类器和基于深度学习的模型也可以起到很好的检测效果。

尤其是自编码器类模型在不同的数据集中综合表现突出,我们可以利用自编码器的重构误差和局部误差,针对时间序列的异常检测的场景,初步达到了一个还不错的效果。
这种方法可以用来提供部分异常样本,加大异常检测召回率的作用。但是这种方法也有一定的弊端: