遗传算法(一) 遗传算法的基本原理
遗传算法(一)遗传算法的基本原理
1.概述
遗传算法(Genetic Algorithm, GA)起源于对生物系统所进行的计算机模拟研究。它是模仿自然界生物进化机制发展起来的随机全局搜索和优化方法,借鉴了达尔文的进化论和孟德尔的遗传学说。其本质是一种高效、并行、全局搜索的方法,能在搜索过程中自动获取和积累有关搜索空间的知识,并自适应地控制搜索过程以求得最佳解。
相关概念:(高中所学)
基因型(genotype):性状染色体的内部表现;
表现型(phenotype):染色体决定的性状的外部表现,或者说,根据基因型形成的个体的外部表现;
进化(evolution):种群逐渐适应生存环境,品质不断得到改良。生物的进化是以种群的形式进行的。
适应度(fitness):度量某个物种对于生存环境的适应程度。
选择(selection):以一定的概率从种群中选择若干个个体。一般,选择过程是一种基于适应度的优胜劣汰的过程。
复制(reproduction):细胞分裂时,遗传物质DNA通过复制而转移到新产生的细胞中,新细胞就继承了旧细胞的基因。
交叉(crossover):两个染色体的某一相同位置处DNA被切断,前后两串分别交叉组合形成两个新的染色体。也称基因重组或杂交;
变异(mutation):复制时可能(很小的概率)产生某些复制差错,变异产生新的染色体,表现出新的性状。
编码(coding):DNA中遗传信息在一个长链上按一定的模式排列。遗传编码可看作从表现型到基因型的映射。
解码(decoding):基因型到表现型的映射。
个体(individual):指染色体带有特征的实体;
种群(population):个体的集合,该集合内个体数称为种群 的大小。
2.遗传算法的步骤
开始循环直至找到满意的解。
1.评估每条染色体所对应个体的适应度。
2.遵照适应度越高,选择概率越大的原则,从种群中选择两个个体作为父方和母方。
3.抽取父母双方的染色体,进行交叉,产生子代。
4.对子代的染色体进行变异。
5.重复2,3,4步骤,直到新种群的产生。
结束循环。


3.遗传算法的具体过程
为了让讲解更为简便,我们先来理解一下著名的组合优化问题「背包问题」。
比如,你准备要去野游 1 个月,但是你只能背一个限重 30 公斤的背包。现在你有不同的必需物品,它们每一个都有自己的「生存点数」(具体在下表中已给出)。因此,你的目标是在有限的背包重量下,最大化你的「生存点数」。

3.1 初始化(编码)
这里我们用遗传算法来解决这个背包问题。第一步是定义我们的总体。总体中包含了个体,每个个体都有一套自己的染色体。
我们知道,染色体可表达为二进制数串,在这个问题中,1 代表接下来位置的基因存在,0 意味着丢失。(译者注:作者这里借用染色体、基因来解决前面的背包问题,所以特定位置上的基因代表了上方背包问题表格中的物品,比如第一个位置上是 Sleeping Bag,那么此时反映在染色体的『基因』位置就是该染色体的第一个『基因』。)
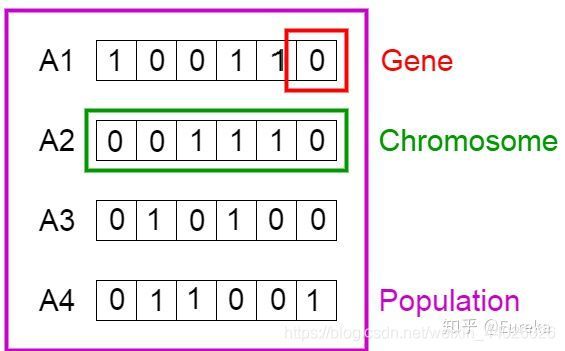
现在,我们将图中的 4 条染色体看作我们的总体初始值
3.2 编码补充
二进制编码
二进制编码由二进制符号0和1所组成的二值符号集。
格雷码
格雷码编码是其连续的两个整数所对应的编码之间只有一个码位是不同的,其余码位完全相同。
二进制码转为格雷码:异或运算:同则为0,异则为1。
浮点编码法
二进制编码虽然简单直观,但明显地。但是存在着连续函数离散化时的映射误差。个体长度较短时,可能达不到精度要求,而个体编码长度较长时,虽然能提高精度,但增加了解码的难度,使遗传算法的搜索空间急剧扩大。
所谓浮点法,是指个体的每个基因值用某一范围内的一个浮点数来表示。编码长度等于决策变量的个数。 在浮点数编码方法中,必须保证基因值在给定的区间限制范围内,遗传算法中所使用的交叉、变异等遗传算子也必须保证其运算结果所产生的新个体的基因值也在这个区间限制范围内。
符号编码法
符号编码法是指个体染色体编码串中的基因值取自一个无数值含义、而只有代码含义的符号集如{A,B,C…}。
3.3 适应度函数
接下来,让我们来计算一下前两条染色体的适应度分数。对于 A1 染色体 [100110] 而言,有:

类似地,对于 A2 染色体 [001110] 来说,有:
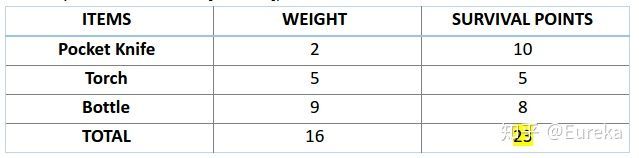
对于这个问题,我们认为,当染色体包含更多生存分数时,也就意味着它的适应性更强。因此,由图可知,染色体 1 适应性强于染色体 2。
3.4 选择
现在,我们可以开始从总体中选择适合的染色体,来让它们互相『交配』,产生自己的下一代了。这个是进行选择操作的大致想法,但是这样将会导致染色体在几代之后相互差异减小,失去了多样性。因此,我们一般会进行「轮盘赌选择法」(Roulette Wheel Selection method)。
想象有一个轮盘,现在我们将它分割成 m 个部分,这里的 m 代表我们总体中染色体的个数。每条染色体在轮盘上占有的区域面积将根据适应度分数成比例表达出来。
基于上图中的值,我们建立如下「轮盘」。

现在,这个轮盘开始旋转,我们将被图中固定的指针(fixed point)指到的那片区域选为第一个亲本。然后,对于第二个亲本,我们进行同样的操作。有时候我们也会在途中标注两个固定指针,如下图:
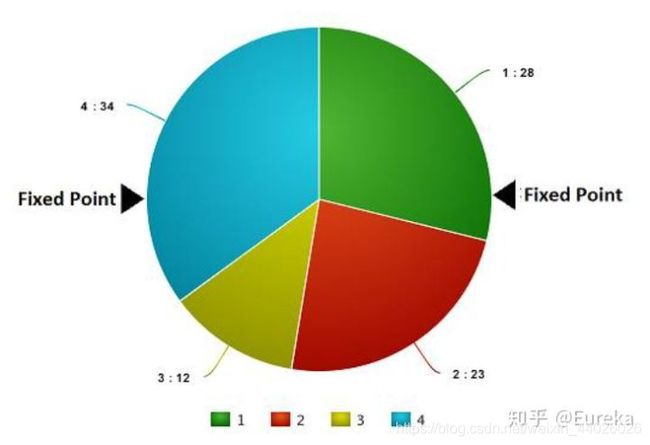
通过这种方法,我们可以在一轮中就获得两个亲本。我们将这种方法成为「随机普遍选择法」(Stochastic Universal Selection method)。
3.5 交叉
在上一个步骤中,我们已经选择出了可以产生后代的亲本染色体。那么用生物学的话说,所谓「交叉」,其实就是指的繁殖。现在我们来对染色体 1 和 4(在上一个步骤中选出来的)进行「交叉」,见下图:
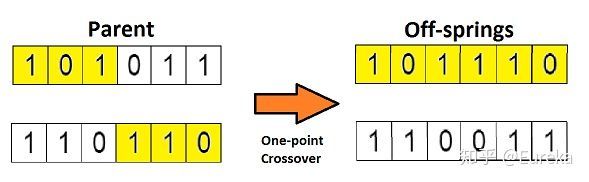
这是交叉最基本的形式,我们称其为「单点交叉」。这里我们随机选择一个交叉点,然后,将交叉点前后的染色体部分进行染色体间的交叉对调,于是就产生了新的后代。
如果你设置两个交叉点,那么这种方法被成为「多点交叉」,见下图:
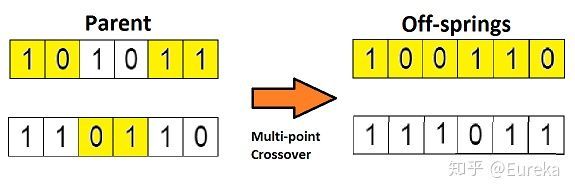
3.6变异
如果现在我们从生物学的角度来看这个问题,那么请问:由上述过程产生的后代是否有和其父母一样的性状呢?答案是否。在后代的生长过程中,它们体内的基因会发生一些变化,使得它们与父母不同。这个过程我们称为「变异」,它可以被定义为染色体上发生的随机变化,正是因为变异,种群中才会存在多样性。
下图为变异的一个简单示例:

变异完成之后,我们就得到了新为个体,进化也就完成了,整个过程如下图:

在进行完一轮「遗传变异」之后,我们用适应度函数对这些新的后代进行验证,如果函数判定它们适应度足够,那么就会用它们从总体中替代掉那些适应度不够的染色体。这里有个问题,我们最终应该以什么标准来判断后代达到了最佳适应度水平呢?
一般来说,有如下几个终止条件: 1. 在进行 X 次迭代之后,总体没有什么太大改变。 2. 我们事先为算法定义好了进化的次数。 3. 当我们的适应度函数已经达到了预先定义的值。
例子:
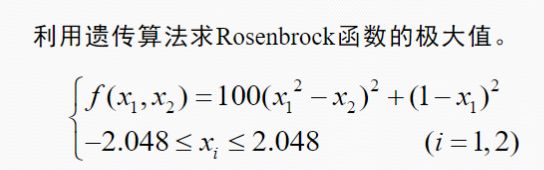
matlab:
%Generic Algorithm for function f(x1,x2) optimum
clear all;
close all;
%Parameters
Size=80; %群体大小
G=100; %终止进化代数
CodeL=10;
umax=2.048;
umin=-2.048;
E=round(rand(Size,2*CodeL)); %Initial Code
%Main Program
for k=1:1:G
time(k)=k;
for s=1:1:Size
m=E(s,:);
y1=0;y2=0;
%Uncoding 解码
m1=m(1:1:CodeL);
for i=1:1:CodeL
y1=y1+m1(i)*2^(i-1);
end
x1=(umax-umin)*y1/1023+umin;
m2=m(CodeL+1:1:2*CodeL);
for i=1:1:CodeL
y2=y2+m2(i)*2^(i-1);
end
x2=(umax-umin)*y2/1023+umin;
F(s)=100*(x1^2-x2)^2+(1-x1)^2; % F(x1,x2)
end
Ji=1./F; %选个体适应度的倒数作为目标函数
%****** Step 1 : Evaluate BestJ ******
BestJ(k)=min(Ji);
fi=F; %Fitness Function
[Oderfi,Indexfi]=sort(fi); %Arranging fi small to bigger
Bestfi=Oderfi(Size); %Let Bestfi=max(fi)
BestS=E(Indexfi(Size),:); %Let BestS=E(m), m is the Indexfi belong to max(fi)
bfi(k)=Bestfi;
%****** Step 2 : Select and Reproduct Operation******
fi_sum=sum(fi);
fi_Size=(Oderfi/fi_sum)*Size;
fi_S=floor(fi_Size); %Selecting Bigger fi value
kk=1;
for i=1:1:Size
for j=1:1:fi_S(i) %Select and Reproduce
TempE(kk,:)=E(Indexfi(i),:);
kk=kk+1; %kk is used to reproduce
end
end
%************ Step 3 : Crossover Operation ************
pc=0.60;
n=ceil(20*rand);
for i=1:2:(Size-1)
temp=rand;
if pc>temp %Crossover Condition
for j=n:1:20
TempE(i,j)=E(i+1,j);
TempE(i+1,j)=E(i,j);
end
end
end
TempE(Size,:)=BestS;
E=TempE;
%************ Step 4: Mutation Operation **************
%pm=0.001;
%pm=0.001-[1:1:Size]*(0.001)/Size; %Bigger fi, smaller Pm
%pm=0.0; %No mutation
pm=0.1; %Big mutation
for i=1:1:Size
for j=1:1:2*CodeL
temp=rand;
if pm>temp %Mutation Condition
if TempE(i,j)==0
TempE(i,j)=1;
else
TempE(i,j)=0;
end
end
end
end
%Guarantee TempPop(30,:) is the code belong to the best individual(max(fi))
TempE(Size,:)=BestS;
E=TempE;
end
Max_Value=Bestfi
BestS
x1
x2
figure(1);
plot(time,BestJ);
xlabel('Times');ylabel('Best J');
figure(2);
plot(time,bfi);
xlabel('times');ylabel('Best F');