python数据分析实战:使用Lightgbm解决二分类预测问题以泰坦尼克号数据为例
1. 背景
来自于kaggle上的一个经典比赛,我们使用Lightgbm进行分类预测,数据说明:
| Variable | Definition | Key |
|---|---|---|
| survival | Survival | 0 = No, 1 = Yes |
| pclass | Ticket class | 1 = 1st, 2 = 2nd, 3 = 3rd |
| sex | Sex | |
| Age | Age in years | |
| sibsp | # of siblings / spouses aboard the Titanic | |
| parch | # of parents / children aboard the Titanic | |
| ticket | Ticket number | |
| fare | Passenger fare | |
| cabin | Cabin number | |
| embarked | Port of Embarkation | C = Cherbourg, Q = Queenstown, S = Southampton |
2. 模型训练及预测
数据预处理
lightgbm前期不需要去除空缺值和特征选择,只需进行哑变量转换即可。
#加载数据
#train是我们训练用的数据,带有标签
#test是我们预测用的数据,不带标签
train=pd.read_csv('train.csv')
test=pd.read_csv('test.csv')
#哑变量转换
def make_dummy(df,col):
df[col]=df[col].astype('object')
encode = pd.get_dummies(df[col])
df=df.drop(col,1)
df=pd.concat([df,encode],axis=1)
return df
train=make_dummy(train,['Pclass','Sex','Embarked'])
test=make_dummy(test,['Pclass','Sex','Embarked'])
#特征集和标签集合
train_x = train.drop(['PassengerId','Name','Cabin','Survived','Ticket'],1)
train_y = train['Survived'].values
交叉验证
自建函数,进行5折交叉验证,计算平均准确率。
def fit(x,y,params=None):
folds = KFold(n_splits=5, shuffle=True,random_state=666)
accuracy=0
clf=lgb.LGBMClassifier(**params)
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train)):
clf.fit(x.iloc[trn_idx],y[trn_idx])
pred=clf.predict(x.iloc[val_idx])
accuracy+=accuracy_score(y[val_idx],pred)/folds.n_splits
return accuracy
网格调参
自建函数,最大化准确率,挑选最优参数集。
def grid(x,y,params):
default={'n_jobs':-1}
init=fit(x,y,default)
for key in params.keys():
for i in params[key]:
dic=default.copy()
dic[key]=i
score=fit(x,y,dic)
print(dic,score)
if score>init:
init=score
default=dic
print(default,init)
param={'max_depth':[3,4,5],'num_leaves':[6,14,31],'subsample':[0.8,0.9,1],'colsample_bytree':[0.8,0.9,1],
'reg_alpha':[1,2,3,4,10],'reg_lambda':[1,2,3,4]}
grid(train_x,train_y,param)
得到的结果为
![]()
模型训练、绘制决策树、特征重要性
#模型训练
default={'n_jobs': -1, 'max_depth': 4, 'num_leaves': 14}
clf=lgb.LGBMClassifier(**default)
clf.fit(train_x,train_y)
#绘制决策树
lgb.create_tree_digraph(clf)
#特征重要性
lgb.plot_importance(clf)

预测
预测后结果上传到kaggle。
clf.predict(test)
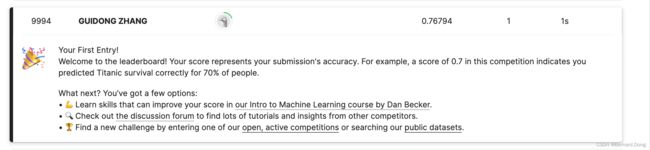
准确率0.77,排名9994。
3. 其他说明
lightgbm原生API
lightgbm使用C++实现,为python提供了接口,分为了lightgbm naive API,以及为了和机器学习最常用的库sklearn一致而提供的sklearn wrapper。前文用的都是sklearn的api,这里介绍一下原生API。官方文档
使用lightgbm.train方法前要先将数据转化为lightgbm.Dataset类。
train=pd.read_csv('train.csv')
x=train[['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']]
y=train['Survived']
x['Sex']=x['Sex'].map({'male':1,'female':0})
x['Embarked']=x['Embarked'].map({'S':1,'C':2,'Q':3})
x_train,x_test,y_train,y_test=train_test_split(x,y,train_size=0.8)
trn_data = lgb.Dataset(x_train, label=y_train,categorical_feature=['Pclass','Sex','Embarked'])#训练集
val_data = lgb.Dataset(x_test, label=y_test,categorical_feature=['Pclass','Sex','Embarked'])#测试集
params = {
'objective': 'binary',
'max_depth': 5,
'learning_rate': 0.1,
"feature_fraction": 0.9,
"n_jobs": -1,
'num_leaves': 31,
'metric': {'binary_logloss', 'auc'},
"random_state": 2019,
# 'device': 'gpu'
}
clf = lgb.train(params,
trn_data,
num_round,
valid_sets=[val_data],
verbose_eval=20,#返回信息的间隔
categorical_feature=cate_feature,
early_stopping_rounds=60
)
如何调参
首先了解一下参数的定义。如何调参我在之前的文章中提到过:python数据分析实战:近地面臭氧浓度预测,也可以参考这篇文章:lightgbm挑参。