<>linux下内存泄露查找、BUG调试
先收藏着,抽空好好看看:http://www.ibm.com/developerworks/cn/linux/l-pow-debug/
调试程序有很多方法,例如向屏幕上打印消息,使用调试器,或者只需仔细考虑程序如何运行,并对问题进行有根有据的猜测。
在修复 bug 之前,首先要确定在源程序中的位置。例如,当一个程序产生崩溃或生成核心转储(core dump)时,您就需要了解是哪行代码发生了崩溃。在找到有问题的代码行之后,就可以确定这个函数中变量的值,函数是如何调用的,更具体点说,为什么会发生这种错误。使用调试器查找这些信息非常简单。
本文将简要介绍几种用于修复一些很难通过可视化地检查代码而发现的 bug 的技术,并阐述了如何使用在 Linux on Power 架构上可用的工具。
动态内存分配看起来似乎非常简单:您可以根据需要分配内存 —— 使用 malloc() 或其变种 —— 并在不需要时释放这些内存。实际上,内存管理的问题是软件中最为常见的 bug,因为通常在程序启动时这些问题并不明显。例如,程序中的内存泄漏可能开始并不为人注意,直到经过多天甚至几个月的运行才会被发现。接下来的几节将简要介绍如何使用流行的调试器 Valgrind 来发现并调试这些最常见的内存 bug。
在开始使用任何调试工具之前,请考虑这个工具是否对重新编译应用程序有益,是否可以支持具有调试信息的库(-g 选项)。如果没有启用调试信息,调试工具可以做的最好的事情也不过是猜测一段特定的代码是属于哪个函数的。这使得错误消息和概要分析输出几乎没有什么用处。使用 -g 选项,您就有可能获得一些信息来直接指出相关的代码行。
Valgrind 已经在 Linux 应用程序开发社区中广泛用来调试应用程序。它尤其擅长发现内存管理的问题。它可以检查程序运行时的内存泄漏问题。这个工具目前正由 Julian Seward 进行开发,并由 Paul Mackerras 移植到了 Power 架构上。
要安装 Valgrind,请从 Valgrind 的 Web 站点上下载源代码(参阅 参考资料)。切换到 Valgrind 目录,并执行下面的命令:
# make # make check # make install |
Valgrind 的输出格式如下:
# valgrind du –x –s . . ==29404== Address 0x1189AD84 is 0 bytes after a block of size 12 alloc'd ==29404== at 0xFFB9964: malloc (vg_replace_malloc.c:130) ==29404== by 0xFEE1AD0: strdup (in /lib/tls/libc.so.6) ==29404== by 0xFE94D30: setlocale (in /lib/tls/libc.so.6) ==29404== by 0x10001414: main (in /usr/bin/du) |
==29404== 是进程的 ID。消息 Address 0x1189AD84 is 0 bytes after a block of size 12 alloc'd 说明在这个 12 字节的数组后面没有存储空间了。第二行以及后续几行说明内存是在 130 行(vg_replace_malloc.c)的 strdup() 程序中进行分配的。strdup() 是在 libc.so.6 库的 setlocale() 中调用的;main() 调用了 setlocale()。
最为常见的一个 bug 是程序使用了未初始化的内存。未初始化的数据可能来源于:
- 未经初始化的变量
- malloc 函数所分配的数据,在写入值之前使用了
下面这个例子使用了一个未初始化的数组:
2 {
3 int i[5];
4
5 if (i[0] == 0)
6 i[1]=1;
7 return 0;
8 }
|
在这个例子中,整数数组 i[5] 没有进行初始化;因此,i[0] 包含的是一个随机数。因此使用 i[0] 的值来判断一个条件分支就会导致不可预期的问题。Valgrind 可以很容易捕获这种错误条件。当您使用 Valgrind 运行这个程序时,就会接收到下面的消息:
# gcc –g –o test1 test1.c # valgrind ./test1 . . ==31363== ==31363== Conditional jump or move depends on uninitialised value(s) ==31363== at 0x1000041C: main (test1.c:5) ==31363== ==31363== ERROR SUMMARY: 1 errors from 1 contexts (suppressed: 7 from 1) ==31363== malloc/free: in use at exit: 0 bytes in 0 blocks. ==31363== malloc/free: 0 allocs, 0 frees, 0 bytes allocated. ==31363== For counts of detected errors, rerun with: -v ==31363== No malloc'd blocks -- no leaks are possible. |
Valgrind 的输出说明,有一个条件分支依赖于文件 test1.c 中第 5 行中的一个未初始化的变量。
内存泄漏是另外一个常见的问题,也是很多程序中最难判断的问题。内存泄漏的主要表现为:当程序连续运行时,与程序相关的内存(或堆)变得越来越大。结果是,当这个程序所消耗的内存达到系统的上限时,就会自己崩溃;或者会出现更严重的情况:挂起或导致系统崩溃。下面是一个有内存泄漏 bug 的示例程序:
1 int main(void)
2 {
3 char *p1;
4 char *p2;
5
6 p1 = (char *) malloc(512);
7 p2 = (char *) malloc(512);
8
9 p1=p2;
10
11 free(p1);
12 free(p2);
13 }
|
上面的代码分别给字符指针 p1 和 p2 分配了两个 512 字节的内存块,然后将指向第一个内存块的指针设置为指向第二个内存块。结果是,第二个内存块的地址丢失了,并导致内存泄漏。在使用 Valgrind 运行这个程序时,会返回如下的消息:
# gcc –g –o test2 test2.c # valgrind ./test2 . . ==31468== Invalid free() / delete / delete[] ==31468== at 0xFFB9FF0: free (vg_replace_malloc.c:152) ==31468== by 0x100004B0: main (test2.c:12) ==31468== Address 0x11899258 is 0 bytes inside a block of size 512 free'd ==31468== at 0xFFB9FF0: free (vg_replace_malloc.c:152) ==31468== by 0x100004A4: main (test2.c:11) ==31468== ==31468== ERROR SUMMARY: 1 errors from 1 contexts (suppressed: 7 from 1) ==31468== malloc/free: in use at exit: 512 bytes in 1 blocks. ==31468== malloc/free: 2 allocs, 2 frees, 1024 bytes allocated. ==31468== For counts of detected errors, rerun with: -v ==31468== searching for pointers to 1 not-freed blocks. ==31468== checked 167936 bytes. ==31468== ==31468== LEAK SUMMARY: ==31468== definitely lost: 512 bytes in 1 blocks. ==31468== possibly lost: 0 bytes in 0 blocks. ==31468== still reachable: 0 bytes in 0 blocks. ==31468== suppressed: 0 bytes in 0 blocks. ==31468== Use --leak-check=full to see details of leaked memory. |
正如您可以看到的一样,Valgrind 报告说这个程序中有 512 字节的内存丢失了。
这种情况发生在程序试图对一个不属于程序本身的内存地址进行读写时。在有些系统上,在发生这种错误时,程序会异常结束,并产生一个段错误。下面这个例子就是一个常见的 bug,它试图读写一个超出数组边界的元素。
1 int main() {
2 int i, *iw, *ir;
3
4 iw = (int *)malloc(10*sizeof(int));
5 ir = (int *)malloc(10*sizeof(int));
6
7
8 for (i=0; i<11; i++)
9 iw[i] = i;
10
11 for (i=0; i<11; i++)
12 ir[i] = iw[i];
13
14 free(iw);
15 free(ir);
16 }
|
从这个程序中我们可以看出,对于 iw[10] 和 ir[10] 的访问都是非法的,因为 iw 和 ir 都只有 10 个元素,分别是从 0 到 9。请注意int iw[10 ] 和 iw = (int *)malloc(10*sizeof(int)) 是等效的 —— 它们都是用来给一个整数数组 iw 分配 10 个元素。
当您使用 Valgrind 运行这个程序时,会返回如下的消息:
# gcc –g –o test3 test3.c # valgrind ./test3 . . ==31522== Invalid write of size 4 ==31522== at 0x100004C0: main (test3.c:9) ==31522== Address 0x11899050 is 0 bytes after a block of size 40 alloc'd ==31522== at 0xFFB9964: malloc (vg_replace_malloc.c:130) ==31522== by 0x10000474: main (test10.c:4) ==31522== ==31522== Invalid read of size 4 ==31522== at 0x1000050C: main (test3.c:12) ==31522== Address 0x11899050 is 0 bytes after a block of size 40 alloc'd ==31522== at 0xFFB9964: malloc (vg_replace_malloc.c:130) ==31522== by 0x10000474: main (test10.c:4) ==31522== ==31522== ERROR SUMMARY: 2 errors from 2 contexts (suppressed: 7 from 1) ==31522== malloc/free: in use at exit: 0 bytes in 0 blocks. ==31522== malloc/free: 2 allocs, 2 frees, 84 bytes allocated. ==31522== For counts of detected errors, rerun with: -v ==31522== No malloc'd blocks -- no leaks are possible. |
在 test3.c 的第 9 行发现一个非法的 4 字节写操作,在第 12 行发现一个非法的 4 字节读操作。
Valgrind 也可以帮助判断内存误用的问题,例如:
- 读/写已经释放的内存
- C++ 环境中错误地使用 malloc/new 与 free/delete 的配对
下面这个列表介绍了 POWER 架构上 Valgrind 的状态:
- memcheck 和 addrcheck 工具都可以很好地工作。然而,其他工具还没有进行大量的测试。另外,Helgrind (一个数据竞争的检测程序)在 POWER 上尚不能使用。
- 所有的 32 位 PowerPC? 用户模式的指令都可以支持,除了两条非常少用的指令:lswx 和 stswx。具体来说,所有的浮点和 Altivec(VMX)指令都可以支持。
- Valgrind 可以在 32 位或 64 位 PowerPC/Linux 内核上工作,但是只能用于 32 位的可执行程序。
有关 Valgrind 内存调试的更多信息,请访问 Valgrind HOW TO 站点。还可以参阅 Steve Best 的“Debugging Memory Problems”(Linux Magazine,2003 年 5 月)。参考资料 中有它们的链接
除了 Valgrind 之外,还可以使用其他几个内存调试工具;例如,Memwatch 和 Electric Fence。
除了内存 bug 之外,开发人员通常还会碰到程序虽然能够成功编译,但是在运行时却会产生内核转储或段错误的问题。有时在程序完成之后,程序的输出可能与所期望或设计的不同。在这两种情况中,可能代码中存在您认为正确而实际上错误的情况。接下来的几节中介绍的调试器将帮助您找到这些情况的原因。
GDB(GNU 项目调试器)可以让您了解程序在执行时“内部” 究竟在干些什么,以及在程序发生崩溃的瞬间正在做什么。
GDB 做以下 4 件主要的事情来帮助您捕获程序中的 bug:
- 在程序启动之前指定一些可以影响程序行为的变量或条件
- 在某个指定的地方或条件下暂停程序
- 在程序停止时检查已经发生了什么
- 在程序执行过程中修改程序中的变量或条件,这样就可以体验修复一个 bug 的成果,并继续了解其他 bug
要调试的程序可以是使用 C、C++、Pascal、Objective-C 以及其他很多语言编写的。GDB 的二进制文件名是 gdb。
gdb 中有很多命令。使用 help 命令可以列出所有的命令,以及关于如何使用这些命令的介绍。下表给出了最常用的 GDB 命令。
| 命令 | 说明 | 例子 |
|---|---|---|
help |
显示命令类别 | help - 显示命令类别help breakpoints - 显示属于 breakpoints 类别的命令help break - 显示 break 命令的解释 |
run |
启动所调试的程序 | ? |
kill |
终止正在调试的程序的执行 | 通常这会在要执行的代码行已经超过了您想要调试的代码时使用。执行 kill 会重置断点,并从头再次运行这个程序 |
cont |
所调试的程序运行到一个断点、异常或单步之后,继续执行 | ? |
info break |
显示当前的断点或观察点 | ? |
break |
在指定的行或函数处设置断点 | break 93 if i=8 - 当变量 i 等于 8 时,在第 93 行停止程序执行 |
Step |
单步执行程序,直到它到达一个不同的源代码行。您可以使用 s 来代表 step 命令 |
? |
Next |
与 step 命令类似,只是它不会“单步跟踪到”子例程中 | ? |
print |
打印一个变量或表达式的值 | print pointer - 打印变量指针的内容print *pointer - 打印指针所指向的数据结构的内容 |
delete |
删除某些断点或自动显示表达式 | delete 1 - 删除断点 1。断点可以通过 info break 来显示 |
watch |
为一个表达式设置一个观察点。当表达式的值发生变化时,这个观察点就会暂停程序的执行 | ? |
where |
打印所有堆栈帧的栈信息 | where - 不使用参数,输出当前线程的堆栈信息where all - 输出当前线程组中所有线程的堆栈信息where threadindex - 输出指定线程的堆栈信息 |
attach |
开始查看一个已经运行的进程 | attach <process_id> - 附加到进程 process_id 上。process_id 可以使用 ps 命令找到 |
info thread |
显示当前正在运行的线程 | ? |
thread apply threadno command |
对一个线程运行 gdb 命令 | thread apply 3 where - 对线程 3 运行 where 命令 |
Thread threadno |
选择一个线程作为当前线程 | ? |
如果一个程序崩溃了,并生成了一个 core 文件,您可以查看 core 文件来判断进程结束时的状态。使用下面的命令启动 gdb:
# gdb programname corefilename |
要调试一个 core 文件,您需要可执行程序、源代码文件以及 core 文件。要对一个 core 文件启动 gdb,请使用 -c 选项:
# gdb -c core programname |
gdb 会显示是哪行代码导致这个程序产生了核心转储。
默认情况下,核心转储在 Novell 的 SUSE LINUX Enterprise Server 9(SLES 9)和 Red Hat? Enterprise Linux Advanced Server(RHEL AS 4)上都是禁用的。要启用核心转储,请以 root 用户的身份在命令行中执行 ulimit –c unlimited。
清单 8 中的例子阐述了如何使用 gdb 来定位程序中的 bug。清单 8 是一段包含 bug 的 C++ 代码。
清单 8 中的 C++ 程序试图构建 10 个链接在一起的数字框(number box),例如:
然后试图从这个列表中逐个删除数字框。
编译并运行这个程序,如下所示:
# g++ -g -o gdbtest1 gdbtest1.cpp # ./gdbtest1 Number Box "0" created Number Box "1" created Number Box "2" created Number Box "3" created Number Box "4" created Number Box "5" created Number Box "6" created Number Box "7" created Number Box "8" created Number Box "9" created list created Number Box "9" deleted Segmentation fault |
正如您可以看到的一样,这个程序会导致段错误。调用 gdb 来看一下这个问题,如下所示:
# gdb ./gdbtest1 GNU gdb 6.2.1 Copyright 2004 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "ppc-suse-linux"...Using host libthread_db library "/lib/tls/libthread_db.so.1". (gdb) |
您知道段错误是在数字框 "9" 被删除之后发生的。执行 run 和 where 命令来精确定位段错误发生在程序中的什么位置。
(gdb) run
Starting program: /root/test/gdbtest1
Number Box "0" created
Number Box "1" created
Number Box "2" created
Number Box "3" created
Number Box "4" created
Number Box "5" created
Number Box "6" created
Number Box "7" created
Number Box "8" created
Number Box "9" created
list created
Number Box "9" deleted
Program received signal SIGSEGV, Segmentation fault.
0x10000f74 in NumBox<int>::GetNext (this=0x0) at gdbtest1.cpp:14
14 NumBox<T>*GetNext() const { return Next; }
(gdb) where
#0 0x10000f74 in NumBox<int>::GetNext (this=0x0) at gdbtest1.cpp:14
#1 0x10000d10 in NumChain<int>::RemoveBox (this=0x10012008,
|
跟踪信息显示这个程序在第 14 行 NumBox<int>::GetNext (this=0x0) 接收到一个段错误。这个数字框上 Next 指针的地址是 0x0,这对于一个数字框来说是一个无效的地址。从上面的跟踪信息可以看出,GetNext 函数是由 63 行调用的。看一下在 gdbtest1.cpp 的 63 行附近发生了什么:
54 } else {
55 temp->SetNext (current->GetNext());
56 delete temp;
57 temp = 0;
58 return 0;
59 }
60 }
61 current = 0;
62 temp = current;
63 current = current->GetNext();
64 }
65
66 return -1;
|
第 61 行 current=0 将这个指针设置为一个无效的地址,这正是产生段错误的根源。注释掉第 61 行,将其保存为 gdbtest2.cpp,然后编译并重新运行。
# g++ -g -o gdbtest2 gdbtest2.cpp # ./gdbtest2 Number Box "0" created Number Box "1" created Number Box "2" created Number Box "3" created Number Box "4" created Number Box "5" created Number Box "6" created Number Box "7" created Number Box "8" created Number Box "9" created list created Number Box "9" deleted Number Box "0" deleted |
这个程序现在可以成功完成而不会出现段错误了。然而,结果并不像我们预期的一样:程序在删除 Number Box "9"之后删除了 Number Box "0",而不像我们期望的一样删除 Number Box "8,"。使用 gdb 再次来看一下。
# gdb ./gdbtest2 GNU gdb 6.2.1 Copyright 2004 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "ppc-suse-linux"...Using host libthread_db library "/lib/tls/libthread_db.so.1". (gdb) break 94 if i==8 Breakpoint 1 at 0x10000968: file gdbtest2.cpp, line 94. (gdb) run Starting program: /root/test/gdbtest2 Number Box "0" created Number Box "1" created Number Box "2" created Number Box "3" created Number Box "4" created Number Box "5" created Number Box "6" created Number Box "7" created Number Box "8" created Number Box "9" created list created Number Box "9" deleted Breakpoint 1, main (argc=1, argv=0xffffe554) at gdbtest2.cpp:94 94 list ->RemoveBox(i); |
您可能希望找出为什么这个程序删除的是 Number Box 0,而不是 Number Box 8,因此需要在您认为程序会删除 Number Box 8 的地方停止程序。设置这个断点:break 94 if i==8,可以在 i 等于 8 时在第 94 行处停止程序。然后单步跟踪到 RemoveBox() 函数中。
(gdb) s
38 NumBox<T> *temp = 0;
(gdb) s
40 while (current != 0) {
(gdb) print pointer
$1 = (NumBox<int> *) 0x100120a8
(gdb) print *pointer
$2 = {Num = 0, Next = 0x0}
(gdb)
|
指针早已指向了 Number Box "0",因此这个 bug 可能就存在于程序删除 Number Box "9" 的地方。要在 gdb 中重新启动这个程序,请使用 kill 删除原来的断点,然后添加一个 i 等于 9 时的新断点,然后再次运行这个程序。
(gdb) kill
Kill the program being debugged? (y or n) y
(gdb) info break
Num Type Disp Enb Address What
1 breakpoint keep y 0x10000968 in main at gdbtest2.cpp:94
stop only if i == 8
breakpoint already hit 1 time
(gdb) delete 1
(gdb) break 94 if i==9
Breakpoint 2 at 0x10000968: file gdbtest2.cpp, line 94.
(gdb) run
Starting program: /root/test/gdbtest2
Number Box "0" created
Number Box "1" created
Number Box "2" created
Number Box "3" created
Number Box "4" created
Number Box "5" created
Number Box "6" created
Number Box "7" created
Number Box "8" created
Number Box "9" created
list created
Breakpoint 2, main (argc=1, argv=0xffffe554) at gdbtest2.cpp:94
94 list ->RemoveBox(i);
(gdb)
|
当这一次单步跟踪 RemoveBox() 函数时,要特别注意 list->pointer 正在指向哪一个数字框,因为 bug 可能就在于 list->pointer 开始指向 Number Box "0" 的地方。请使用 display *pointer 命令来查看,这会自动显示这个函数。
清单 17. 使用 display *pointer 命令进行监视
Breakpoint 2, main (argc=1, argv=0xffffe554) at gdbtest2.cpp:94 94 list ->RemoveBox(i); (gdb) s NumChain<int>::RemoveBox (this=0x10012008, item_to_remove=@0xffffe200) |
从上面的跟踪过程中,您可以看到 list->pointer 在删除 Number Box "9" 之后指向了 Number Box "0"。这个逻辑并不正确,因为在删除 Number Box "9" 之后,list->pointer 应该指向的是 Number Box "8"。现在非常显然我们应该在第 50 行之前添加一条语句pointer = pointer->GetNext();,如下所示:
清单 18. 在第 50 行之前添加一条 pointer = pointer->GetNext(); 语句
49 } else {
50 pointer = pointer->GetNext();
51 delete current;
52 current = 0;
53 }
54 return 0;
|
将新修改之后的程序保存为 gdbtest3.cpp,然后编译并再次运行。
# g++ -g -o gdbtest3 gdbtest3.cpp # ./gdbtest3 Number Box "0" created Number Box "1" created Number Box "2" created Number Box "3" created Number Box "4" created Number Box "5" created Number Box "6" created Number Box "7" created Number Box "8" created Number Box "9" created list created Number Box "9" deleted Number Box "8" deleted Number Box "7" deleted Number Box "6" deleted Number Box "5" deleted Number Box "4" deleted Number Box "3" deleted Number Box "2" deleted Number Box "1" deleted Number Box "0" deleted |
这才是我们期望的结果。
在 GDB 中有一些特殊的命令可以用于多线程应用程序的调试。下面这个例子给出了一个死锁情况,并介绍了如何使用这些命令来检查多线程应用程序中的问题:
#include <stdio.h>
#include "pthread.h>
pthread_mutex_t AccountA_mutex;
pthread_mutex_t AccountB_mutex;
struct BankAccount {
char account_name[1];
int balance;
};
struct BankAccount accountA = {"A", 10000 };
struct BankAccount accountB = {"B", 20000 };
void * transferAB (void* amount_ptr) {
int amount = *((int*)amount_ptr);
pthread_mutex_lock(&AccountA_mutex);
if (accountA.balance < amount) {
printf("There is not enough memory in Account A!\n");
pthread_mutex_unlock(&AccountA_mutex);
pthread_exit((void *)1);
}
accountA.balance -=amount;
sleep(1);
pthread_mutex_lock(&AccountB_mutex);
accountB.balance +=amount;
pthread_mutex_unlock(&AccountA_mutex);
pthread_mutex_unlock(&AccountB_mutex);
}
void * transferBA (void* amount_ptr) {
int amount = *((int*)amount_ptr);
pthread_mutex_lock(&AccountB_mutex);
if (accountB.balance < amount) {
printf("There is not enough memory in Account B!\n");
pthread_mutex_unlock(&AccountB_mutex);
pthread_exit((void *)1);
}
accountB.balance -=amount;
sleep(1);
pthread_mutex_lock(&AccountA_mutex);
accountA.balance +=amount;
pthread_mutex_unlock(&AccountB_mutex);
pthread_mutex_unlock(&AccountA_mutex);
}
int main(int argc, char* argv[]) {
int threadid[4];
pthread_t pthread[4];
int transfer_amount[4] = {100, 200, 300, 400};
int final_balanceA, final_balanceB;
final_balanceA=accountA.balance-transfer_amount[0]- |
使用 gcc 来编译这个程序,如下所示:
# gcc -g -o gdbtest2 gdbtest2.c -L/lib/tls -lpthread |
程序 gdbtest2 会挂起,不会返回一条 All the money is transferred !! 消息。
将 gdb 附加到正在运行的进程上,从而了解这个进程内部正在发生什么。
# ps -ef |grep gdbtest2
root 9510 8065 1 06:30 pts/1 00:00:00 ./gdbtest2
root 9516 9400 0 06:30 pts/4 00:00:00 grep gdbtest2
# gdb -pid 9510
GNU gdb 6.2.1
Copyright 2004 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you
are welcome to change it and/or distribute copies of it under certain
conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for
details.
This GDB was configured as "ppc-suse-linux".
Attaching to process 9510
Reading symbols from /root/test/gdbtest2...done.
Using host libthread_db library "/lib/tls/libthread_db.so.1".
Reading symbols from /lib/tls/libpthread.so.0...done.
[Thread debugging using libthread_db enabled]
[New Thread 1073991712 (LWP 9510)]
[New Thread 1090771744 (LWP 9514)]
[New Thread 1086577440 (LWP 9513)]
[New Thread 1082383136 (LWP 9512)]
[New Thread 1078188832 (LWP 9511)]
Loaded symbols for /lib/tls/libpthread.so.0
Reading symbols from /lib/tls/libc.so.6...done.
Loaded symbols for /lib/tls/libc.so.6
Reading symbols from /lib/ld.so.1...done.
Loaded symbols for /lib/ld.so.1
0x0ff4ac40 in __write_nocancel () from /lib/tls/libc.so.6
(gdb) info thread
5 Thread 1078188832 (LWP 9511) 0x0ffe94ec in __lll_lock_wait ()
from /lib/tls/libpthread.so.0
4 Thread 1082383136 (LWP 9512) 0x0ffe94ec in __lll_lock_wait ()
from /lib/tls/libpthread.so.0
3 Thread 1086577440 (LWP 9513) 0x0ffe94ec in __lll_lock_wait ()
from /lib/tls/libpthread.so.0
2 Thread 1090771744 (LWP 9514) 0x0ffe94ec in __lll_lock_wait ()
from /lib/tls/libpthread.so.0
1 Thread 1073991712 (LWP 9510) 0x0ff4ac40 in __write_nocancel ()
from /lib/tls/libc.so.6
(gdb)
|
从 info thread 命令中,我们可以了解到除了主线程(thread #1)之外的所有线程都在等待函数 __lll_lock_wait () 完成。
使用 thread apply threadno where 命令来查看每个线程到底运行到了什么地方:
(gdb) thread apply 1 where Thread 1 (Thread 1073991712 (LWP 9510)): #0 0x0ff4ac40 in __write_nocancel () from /lib/tls/libc.so.6 #1 0x0ff4ac28 in __write_nocancel () from /lib/tls/libc.so.6 Previous frame identical to this frame (corrupt stack?) #0 0x0ff4ac40 in __write_nocancel () from /lib/tls/libc.so.6 (gdb) thread apply 2 where Thread 2 (Thread 1090771744 (LWP 9514)): #0 0x0ffe94ec in __lll_lock_wait () from /lib/tls/libpthread.so.0 #1 0x0ffe466c in pthread_mutex_lock () from /lib/tls/libpthread.so.0 #2 0x0ffe466c in pthread_mutex_lock () from /lib/tls/libpthread.so.0 #3 0x0ffe466c in pthread_mutex_lock () from /lib/tls/libpthread.so.0 #4 0x0ffe466c in pthread_mutex_lock () from /lib/tls/libpthread.so.0 Previous frame inner to this frame (corrupt stack?) #0 0x0ff4ac40 in __write_nocancel () from /lib/tls/libc.so.6 (gdb) thread apply 3 where Thread 3 (Thread 1086577440 (LWP 9513)): #0 0x0ffe94ec in __lll_lock_wait () from /lib/tls/libpthread.so.0 #1 0x0ffe466c in pthread_mutex_lock () from /lib/tls/libpthread.so.0 #2 0x0ffe466c in pthread_mutex_lock () from /lib/tls/libpthread.so.0 #3 0x0ffe466c in pthread_mutex_lock () from /lib/tls/libpthread.so.0 #4 0x0ffe466c in pthread_mutex_lock () from /lib/tls/libpthread.so.0 Previous frame inner to this frame (corrupt stack?) #0 0x0ff4ac40 in __write_nocancel () from /lib/tls/libc.so.6 (gdb) thread apply 4 where Thread 4 (Thread 1082383136 (LWP 9512)): #0 0x0ffe94ec in __lll_lock_wait () from /lib/tls/libpthread.so.0 #1 0x0ffe466c in pthread_mutex_lock () from /lib/tls/libpthread.so.0 #2 0x0ffe466c in pthread_mutex_lock () from /lib/tls/libpthread.so.0 #3 0x0ffe466c in pthread_mutex_lock () from /lib/tls/libpthread.so.0 #4 0x0ffe466c in pthread_mutex_lock () from /lib/tls/libpthread.so.0 Previous frame inner to this frame (corrupt stack?) #0 0x0ff4ac40 in __write_nocancel () from /lib/tls/libc.so.6 (gdb) thread apply 5 where Thread 5 (Thread 1078188832 (LWP 9511)): #0 0x0ffe94ec in __lll_lock_wait () from /lib/tls/libpthread.so.0 #1 0x0ffe466c in pthread_mutex_lock () from /lib/tls/libpthread.so.0 #2 0x0ffe466c in pthread_mutex_lock () from /lib/tls/libpthread.so.0 #3 0x0ffe466c in pthread_mutex_lock () from /lib/tls/libpthread.so.0 #4 0x0ffe466c in pthread_mutex_lock () from /lib/tls/libpthread.so.0 Previous frame inner to this frame (corrupt stack?) #0 0x0ff4ac40 in __write_nocancel () from /lib/tls/libc.so.6 |
每个线程都试图对一个互斥体进行加锁,但是这个互斥体却是不可用的,可能是因为有另外一个线程已经对其进行加锁了。从上面的证据我们可以判断程序中一定存在死锁。您还可以看到哪个线程现在拥有这个互斥体。
(gdb) print AccountA_mutex
$1 = {__m_reserved = 2, __m_count = 0, __m_owner = 0x2527, |
从上面的命令中,我们可以看出 AccontA_mutex 是被线程 5(LWP 9511)加锁(拥有)的,而 AccontB_mutex 是被线程 3(LWP 9513)加锁(拥有)的。
为了解决上面的死锁情况,可以按照相同的顺序对互斥体进行加锁,如下所示:
.
.
void * transferAB (void* amount_ptr) {
int amount = *((int*)amount_ptr);
pthread_mutex_lock(&AccountA_mutex);
pthread_mutex_lock(&AccountB_mutex);
if (accountA.balance < amount) {
printf("There is not enough memory in Account A!\n");
pthread_mutex_unlock(&AccountA_mutex);
pthread_exit((void *)1);
}
accountA.balance -=amount;
sleep(1);
accountB.balance +=amount;
pthread_mutex_unlock(&AccountA_mutex);
pthread_mutex_unlock(&AccountB_mutex);
}
void * transferBA (void* amount_ptr) {
int amount = *((int*)amount_ptr);
pthread_mutex_lock(&AccountA_mutex);
pthread_mutex_lock(&AccountB_mutex);
if (accountB.balance < amount) {
printf("There is not enough memory in Account B!\n");
pthread_mutex_unlock(&AccountB_mutex);
pthread_exit((void *)1);
}
accountB.balance -=amount;
sleep(1);
accountA.balance +=amount;
pthread_mutex_unlock(&AccountA_mutex);
pthread_mutex_unlock(&AccountB_mutex);
}
.
.
|
或者对每个帐号单独进行加锁,如下所示:
.
.
void * transferAB (void* amount_ptr) {
int amount = *((int*)amount_ptr);
pthread_mutex_lock(&AccountA_mutex);
if (accountA.balance < amount) {
printf("There is not enough memory in Account A!\n");
pthread_mutex_unlock(&AccountA_mutex);
pthread_exit((void *)1);
}
accountA.balance -=amount;
sleep(1);
pthread_mutex_unlock(&AccountA_mutex);
pthread_mutex_lock(&AccountB_mutex);
accountB.balance +=amount;
pthread_mutex_unlock(&AccountB_mutex);
}
void * transferBA (void* amount_ptr) {
int amount = *((int*)amount_ptr);
pthread_mutex_lock(&AccountB_mutex);
if (accountB.balance < amount) {
printf("There is not enough memory in Account B!\n");
pthread_mutex_unlock(&AccountB_mutex);
pthread_exit((void *)1);
}
accountB.balance -=amount;
sleep(1);
pthread_mutex_unlock(&AccountB_mutex);
pthread_mutex_lock(&AccountA_mutex);
accountA.balance +=amount;
pthread_mutex_unlock(&AccountA_mutex);
}
.
.
.
|
要调试 64 位的应用程序(使用 GCC 的 –m64 选项或 IBM XL C/C++ 编译器的 –q64 选项编译),应该使用一个特别的 gdb 版本 gdb64。
Java? 调试器 JDB 是一个用来调试 Java 类的命令行调试器。它提供了对本地或远程 Java 虚拟机(JVM)的检查和调试功能。其二进制文件是 jdb。
JDB 是与 java 编译器 javac 一起打包的,在 java2 rpm 包中。
有很多方法都可以开始一个 jdb 会话。最常见的方法是让 jdb 启动一个新的 Java 虚拟机,其中运行要调试的应用程序的主类。这可以通过在命令行中使用命令 jdb 替换 java 来实现。例如,如果您的应用程序的主类是 appClass,那么就使用下面的命令在 JDB 中调试这个程序:
# jdb appClass |
另外一种使用 jdb 的方法是将其附加到一个早已在运行的 JVM 上。要使用 jdb 进行调试的 VM 必须是使用下面的选项启动的:
# java -Xdebug -Xnoagent - |
然后您就可以使用下面的命令将 jdb 附加到这个 VM 上:
# jdb -attach 8888 |
jdb 最常用的命令与 gdb 的类似。详细信息请参考 表 1。
使用图形模式的调试器相对于命令行调试器的一个优点是,在调试器中单步执行程序的同时可以看到对应的每行源代码。
GNU DDD(Data Display Debugger)就是一个调试器(例如 GDB 和 JDB)的图形化前端。除了常见的前端特性(例如查看源代码)之外,DDD 还通过将要显示的数据结构以交互式的图形化方式进行显示而闻名。
对于 SLES 9 来说,用于 PowerPC 的 DDD 二进制文件是在 SUSE Linux SDK CD 中单独提供的,也可以从 Novell 公司的网站上进行下载(参阅 参考资料)。RedHat 在 RHEL AS 4 CD 中提供了 DDD 的 rpm 包。
图 2 是在使用 DDD 来调试 清单 19 (gdbtest3.cpp)中的例子时的截图。
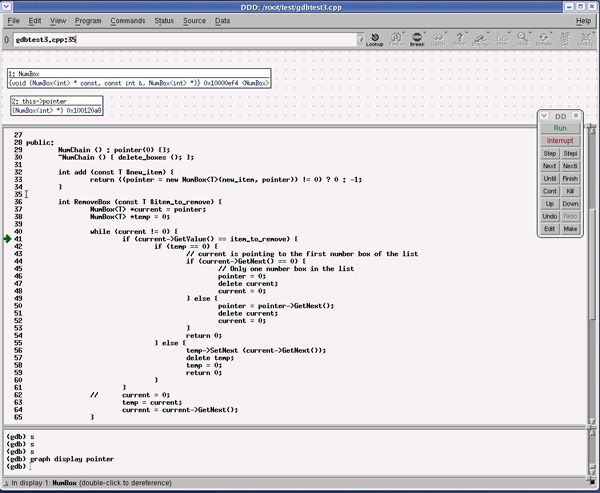
默认情况下,DDD 使用 gdb 作为后端调试器;要切换到 jdb,请使用 ddd -jdb 来启动 DDD。
有关 DDD 的更多信息,请参考 GNU 项目 Web 站点上的 DDD 部分(参阅 参考资料)。
strace 命令是可以在 Linux on POWER 架构上使用的一个功能非常强大的工具。它可以显示用户空间的应用程序所执行的全部系统调用。strace 可以以符号表的形式显示这些调用的参数和返回值。strace 从内核接收信息,并不需要采用任何特殊的方式来构建内核。要跟踪的应用程序也不需要为 strace 重新进行编译,当我们无法访问应用程序的源代码时,这是非常方便的一种方法。
下面的例子使用 strace 来跟踪一个普通用户执行 cat /etc/shadow 的过程,然后将跟踪到的结果打印到 strace.cat.out 中。这个程序依然正常运行,但是在使用 strace 运行时速度稍微有些慢;最后,我们得到一个跟踪文件。
$ strace -o strace.cat.out cat /etc/shadow cat: /etc/shadow: Permission denied $ |
跟踪文件通常都很大。即使对这个简单的例子来说,strace.cat.out 也有 111 行长。这个文件的最后包含下面的行:
88 open("/usr/lib/locale/en_US.UTF-8/LC_NUMERIC",
O_RDONLY) = -1 ENOENT (No such file or directory)
89 open("/usr/lib/locale/en_US.utf8/LC_NUMERIC", O_RDONLY) = 3
90 fstat64(3, {st_mode=S_IFREG|0644, st_size=54, ...}) = 0
91 mmap(NULL, 54, PROT_READ, MAP_PRIVATE, 3, 0) = 0x4010f000
92 close(3) = 0
93 open("/usr/lib/locale/en_US.UTF-8/LC_CTYPE",
O_RDONLY) = -1 ENOENT (No such file or directory)
94 open("/usr/lib/locale/en_US.utf8/LC_CTYPE", O_RDONLY) = 3
95 fstat64(3, {st_mode=S_IFREG|0644, st_size=208464, ...}) = 0
96 mmap(NULL, 208464, PROT_READ, MAP_PRIVATE, 3, 0) = 0x40110000
97 close(3) = 0
98 fstat64(1, {st_mode=S_IFCHR|0620,
st_rdev=makedev(136, 4), ...}) = 0
99 open("/etc/shadow", O_RDONLY|O_LARGEFILE) = -1 EACCES
(Permission denied)
100 write(2, "cat: ", 5) = 5
101 write(2, "/etc/shadow", 11) = 11
102 open("/usr/share/locale/en_US.UTF-8/LC_MESSAGES/libc.mo",
O_RDONLY) = -1 ENOENT (No such file or directory)
103 open("/usr/share/locale/en_US.utf8/LC_MESSAGES/libc.mo",
O_RDONLY) = -1 ENOENT (No such file or directory)
104 open("/usr/share/locale/en_US/LC_MESSAGES/libc.mo",
O_RDONLY) = -1 ENOENT (No such file or directory)
105 open("/usr/share/locale/en.UTF-8/LC_MESSAGES/libc.mo",
O_RDONLY) = -1 ENOENT (No such file or directory)
106 open("/usr/share/locale/en.utf8/LC_MESSAGES/libc.mo",
O_RDONLY) = -1 ENOENT (No such file or directory)
107 open("/usr/share/locale/en/LC_MESSAGES/libc.mo",
O_RDONLY) = -1 ENOENT (No such file or directory)
108 write(2, ": Permission denied", 19) = 19
109 write(2, "\n", 1) = 1
110 close(1) = 0
111 exit_group(1)
|
注意在第 99 行处,命令会失效,因为系统调用 open("/etc/shadow", O_RDONLY|O_LARGEFILE) 失效了,返回了一个 EACCESS 错误代码,这说明权限不符合。
在有些情况中,应用程序可能会挂起,并且不能响应诸如 ctrl+c(SIGINT)之类的信号。这说明应用程序正在调用的系统调用在其内核模式下挂起了,一直不会返回用户模式。strace 可以非常有用地用来判断是哪一个系统调用,以及传给这个系统调用的参数是什么。可能性最大的情况是参数的位置不对而导致了问题。
与 gdb64 是用于 64 位应用程序的 gdb 类似,strace64 也用来跟踪 64 位应用程序所请求的系统调用。
在 Linux on POWER 平台上可以使用很多工具来帮助调试应用程序。本文中介绍的工具可以帮助您解决很多编码的问题。诸如 Valgrind 之类的工具可以显示内存泄漏的位置、非法读/写以及类似的内容,这可以解决内存管理的问题。
使用 gdb 和 jdb 有助于解决那些导致应用程序异常结束的问题,以及导致非预期或不想要的结果的 bug。DDD 工具可以帮助简化调试任务,方法是通过将代码的执行与源代码行联系在一起,并在数据显示窗口中可视化地显示数据结构。另外,strace 是一个功能非常强大的工具,它可以用来跟踪应用程序的所有系统调用。因此,下一次当您要在 Linux 上修复 bug 时,可以试用一下这些工具。
我要感谢 Linda Kinnunen 为我提供文档模板,并帮我审阅本文;感谢 John Engel 和 Chakarat Skawratananond 所提供的技术帮助以及对本文的审阅。
本文所介绍的信息仅仅限于本文的环境,并不提供任何担保。
本文中介绍的所有客户例子都是用来解释这些客户如何使用 IBM 产品的,以及他们达到了什么结果。针对每个客户的实际环境,成本和性能可能会有很大的差异。
非 IBM 产品中的信息来源于这些产品的供应商所公开发表的资料,或可以公开使用的源代码,这并不说明 IBM 产品对它们的认可。非 IBM 产品的价格和性能都来源于可公开使用的信息,包括供应商的公告和供应商的全球主页。IBM 没有对这些产品进行测试,也不保证性能、能力数据的正确性,以及其他有关非 IBM 产品的声明的正确性。有关非 IBM 产品的功能的问题应该由这些产品的供应商来解决。
所有有关 IBM 将来方向和兴趣的声明都可能会不加任何通知而发生变化或撤销,这只是为了表示我们的目标。有关具体的方向声明的全文,请与您本地的 IBM 办公室或 IBM 认证的分销商联系。
有些信息是为了解决预期将来的功能。这种信息不会作为对将来任何产品所能实现特定级别的性能、功能或上市周期的承诺的最终声明。这些承诺只在 IBM 产品声明中做出。本文中提到这些信息是为了说明 IBM 目前的投资和开发活动是真正为了帮助客户实现将来的计划。
性能是在一个受控的环境中使用标准的 IBM 基准测试结果而得出的。用户自己环境中的实际吞吐量或性能可能会有很大的不同,这取决于很多方面,例如用户作业流中的程序数量,I/O 配置情况,存储配置,以及所处理的任务负载。因此,我们并不保证每个用户能获得的吞吐量和性能方面的提高都与本文中介绍的相同。
- 参与论坛讨论。
- 请参考以下资料:
- “Debugging Memory Problems”(Linux Magazine,2003 年 5 月)介绍了更多有关 Valgrind 内存调试的内容。
- Valgrind HOW TO 也介绍了更多有关 Valgrind 内存调试的内容。
- Linux on Power Architecture Developer's Corner:介绍了更多有关 Linux on Power 的内容。您可以在这里找到很多技术文档、培训、下载和产品信息。
- developerWorks Linux 专区:可以找到更多为 Linux 开发人员准备的资料
- Linux at IBM:可以找到硬件、软件和服务,以及为新手和专家提供的建议。
- “从 Solaris 向 Linux on POWER 迁移指南”(developerWorks,2005 年 2 月)帮助您加速移植。学习 Solaris 和 Linux on POWER 上的区别是在移植过程中经常碰到的一个问题。
- 获得产品和技术