云原生(待更新)
云原生(待更新)
文章目录
- 云原生(待更新)
-
- 一、云原生概念
- 二、云原生技术图谱
- 三、云原生在企业中的4大支柱
-
- 1、云原生的团队与流程(T)
- 2、云原生的架构(A)
- 3、云原生的工具(T)
- 4、云原生的运维(O)
- 四、常见的云原生技术整理(待更新)
参考
- 云原生资料库地址
- 云原生到底是什么?
- 云原生的运维 CloudNative Operations
- 深挖云原生的真正含义
Note:本文大量引用其他博主对云原生的观点,本文作为资源整合方,并非原创
云原生(Cloud Native)是最近技术圈一个比较火的名词,相信大家或多或少都听说过。不过对于大多数普通研发朋友来说,"云原生"这个词多少可能还是有些陌生,以至于刚开始听到这个词时可能还会一脸懵逼的问"这到底是一个什么技术,我用过吗?"这样的问题。
其实这并不奇怪,因为对于绝大多数普通开发者来说,我们大部分时间都是在别人构建的基础设施里专注于业务代码的开发,而很少关心业务应用运行所依赖的基础设施环境,但这恰恰也是构建云原生应用的核心意义所在。在今天的文章中,就和大家聊一聊关于云原生的话题!
一、云原生概念
云原生是设计理念 ,系统架构 ,或者方法论。
什么是云原生?对于这个问题我们需要理解,云原生并不是指某一项具体的技术,而是一组技术体系、概念及系统设计原则的集合。例如我们常讨论的微服务架构、Kubernetes容器编排、Devops等内容都是云原生体系的组成部分。
从这个角度看,对于目前已经实现了云服务部署、Spring Cloud微服务架构体系、Kubernetes容器化部署、且构建起了一套自动化发布系统的公司来说,事实上就已经是在践行云原生架构理念了。所以,你看是不是很多公司其实都已经在实施云原生架构了呢?
根据CNCF(云原生计算基金会)的官方描述,云原生技术是指有利于在公有云、私有云或混合云等新型动态环境下,实现应用可弹性伸缩部署的技术体系。云原生的代表技术主要包括容器、服务网格、微服务、不可变基础设施及声明式API。利用这些技术可以构建出容错性更好、更易于管理和观察的松耦合系统,再加上一些可靠的自动化技术及完备的监控预警体系,云原生技术将使开发人员能更快速、轻松地迭代和交付软件系统。
所以从上述描述看,云原生技术实际上并不是突然才流行起来的概念,而是随着云计算、微服务架构、服务网格等分布式应用架构技术普及流行,以及在以Docker、Kubernetes为代表的容器化技术的推动下,逐步被业界所认可的一种系统架构理念及设计原则的抽象总结。
小总结:
云原生是被业界所认可的一种系统架构理念及设计原则的抽象总结,从宏观上看云原生架构是一个非常庞大的体系,它几乎能包含目前软件后端技术领域的方方面面,但从细节上看它却又是我们现阶段工作中都多少能接触到的技术,例如Spring Cloud微服务、服务熔断限流、Kubernetes容器编排等等。
所以从某种程度上讲,云原生是一个抽象又具体的存在。它不是一个具体的产品,而是一套技术体系和一套方法论,随着围绕着云原生架构的各类开源技术的进一步发展,云原生技术体系必将成为主流,进而影响到每一个技术人员、每一个企业和行业。
二、云原生技术图谱
这里介绍关于云原生系统架构的技术实现。
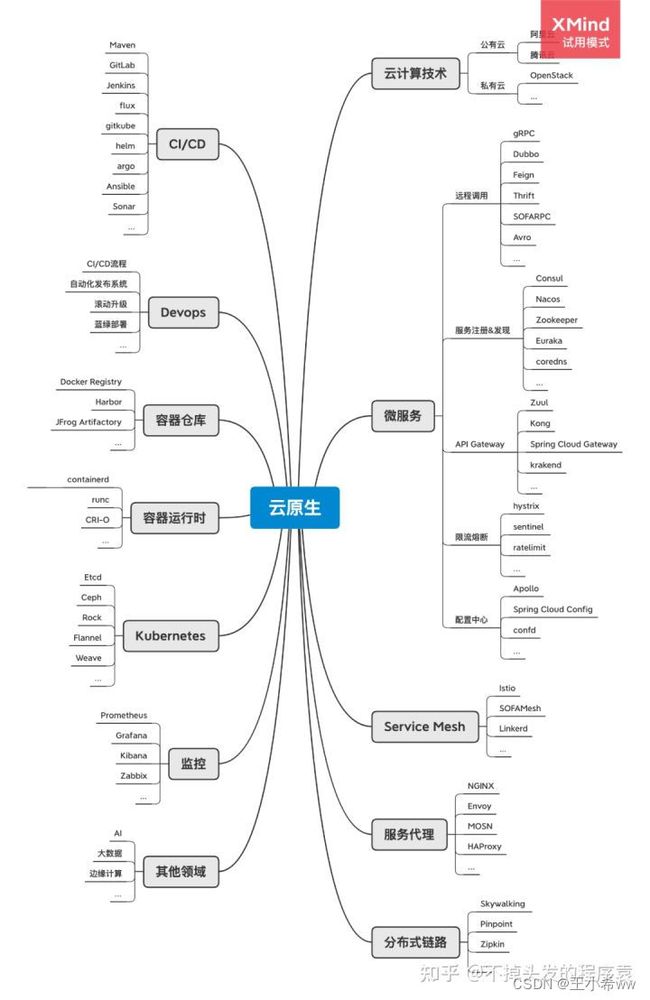
如上图所示,你会发现所谓的云原生简直就是一个技术大杂烩,它几乎囊括目前大部分流行的后端技术,甚至还延伸到了AI、机器学习、边缘计算等领域。但从实际应用场景来说云原生架构主要特征还是体现在云端环境、微服务架构、服务网格、Devops自动化交付、容器化部署这几个方面。
云端环境就是要使用云服务器,对于大部分公司来说就是使用阿里云、腾讯云之类的公有云服务来部署应用,而不是自己在额外维护一套复杂服务器机房。这样做的好处就在于利用云服务的弹性及分布式优势,可以大大降低运维成本,并且提升服务的稳定性。
而面向微服务的架构,能将原先耦合度高的单体系统,在遵循软件“高内聚、低耦合”设计原则的前提下,以独立业务能力为边界拆分为一个个原子系统。这样做的好处是,每个子系统都可以独立交付部署,从而能实现更敏捷的软件迭代效果。目前以Spring Cloud为代表的微服务技术,几乎已成为事实上的软件构建标准;而以Istio、Linkerd为代表的下一代服务网格技术也在快速发展,这一切都为云原生架构理念的普及作了有效地铺垫。
关于Devops,它强调的是以开发运维的视角,去构建一套高效完备的CI/CD流程,并通过自动化构建工具及发布系统,来实现软件生命周期的管理。从而使得普通开发人员,能够更快、更频繁地交付更加稳定的软件代码。例如我在本专栏发表的<
此外基于Kubernetes的容器化编排技术,已经事实上成为微服务运行的标准基础架构环境,也正是Kubernetes的流行,才真正推动了云原生架构理念的普及,Kubernetes可以说就是云原生架构的核心承载平台。
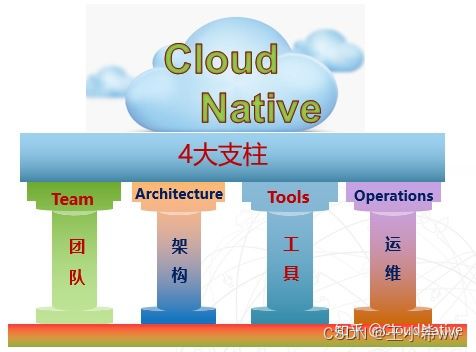
三、云原生在企业中的4大支柱
云原生作为一个云时代的企业组织文化,它有4大支柱。我把它们总结成TATO,即:
- Team & Process 团队与流程
- Architecture 架构
- Tools 工具
- Operations 运维
1、云原生的团队与流程(T)
云原生团队:小, 全栈, DevOps, 敏捷
-
小团队开发 (2-pizza Team)
云原生的应用一般由多个小团队共同开发。各个团队负责应用的不同部分,即不同的微服务。这样才能使得团队具有灵活性,对客户要求进行快速反应。团队的具体大小没有固定的定义。一个参照是在午餐时,两个比萨饼可以把团队喂饱。
-
全栈团队 (Full Stack Team)
云原生的团队成员的工作性质会随着不同的项目而变化。每个工程师既负责开发,也负责测试。按照项目需要,可能前端和后端的开发工作都有。
-
研发与运维的结合(DevOps)
云原生团队的成员对微服务有端到端的责任(End to End Ownership)。他们既负责服务的开发,也负责服务的运维。这样工程师在做服务开发时就会考虑服务的可运维性。如何更好的部署?如何方便地排错?如何快速地回滚?如何在服务失败后尽快地恢复?而且这样做还使得工程师更贴近客户,了解应用是如何被客户使用的,从而更有效地对服务进行持续改进。
-
去中心化(Decentralization)
云原生团队对服务的开发和运维有充分的技术决策权。使用什么技术栈,什么工具,什么数据库都可以由团队在整体大方向下自主地根据具体项目需要来做最佳的选取。
-
敏捷的研发流程 (Agile Development)
云原生的团队由于更加贴近客户,所以对客户的需求有更好的了解。团队可以根据这种了解对工作内容和优先级做及时的调整。而不会被自上而下的统筹安排所束缚。从而得以极快的速度来满足客户的诉求。
2、云原生的架构(A)
云原生的架构:微服务,云基础,服务注册与发现,伸缩扩展,无状态,无本地依赖
系统框架是云原生的另外一个基石。系统架构在任何计算机系统里都是至关重要的。系统的架构对系统的性能,可靠性,可扩展性,长期可维护性,和可运维性等等都起着决定性的作用。对于云原生系统也不例外。
-
微服务化架构(Micro Service Architecture)
云原生的应用一般不是单体架构,而是由一些功能专一的微服务组成。这些微服务高度解耦。相互之间沟通是通过接口调用。这些服务可以独立开发,测试,部署,和运维。
-
基于云基础设施(Based on Cloud Infrastructure)
云原生的应用都会搭建在基于云的基础设施上。应用会按需自动获取或释放云基础设施提供的计算,网络,存储等云服务。
-
分布式云化部署 (Distributed Deployment)
组成云原生应用的微服务大都部署在虚拟IP地址(VIP)后面的虚机集群的多个节点上。通过负载均衡器(ELB)来管理服务请求的分发。这样可以避免单机失败对服务的影响,提高服务的韧性。同时也方便调整资源的容量。这些服务还可以部署到不同地理区域的数据中心。这样可以获得更加坚固的冗余性。对全球客户的支持也会有更佳的性能。分布式部署的去中心化的服务可以使用自己独立的数据库存储,以满足服务的需要。
-
无状态(Stateless)
为了提高服务的处理效率和有效地支持服务的横向扩展,需要保证对服务的调用请求可以由任意一个节点处理。所以云原生应用会采取无状态的服务架构,服务请求中已包括处理此请求所需的足够信息。这样也会保证单点失败对服务功能无影响。
-
无本地依赖 (Localless)
分布式的多节点部署带来的一个问题是这些单个节点可以由于硬盘,网络等各种原因导致其失败。当一个节点失败时,节点上的数据也会丢失。因此,云原生的应用会尽量使用云资源而避免使用本地资源。比如使用云存储,云数据库,基于云的缓存,消息队列等等云服务。
-
可水平自动弹性伸缩(Horizontal Auto Scaling)
为了应对服务的流量变化,云原生的应用会利用无状态无本地依赖等架构设计使得应用的性能可以随着调整节点数量而得到线性调整。从而提高应用性能和资源利用率。应用可以通过自动伸缩引擎定义弹性伸缩的规则,使得在流量负载达到特定指标时在不经手工干预的情况下完成对资源的调整。在资源调整过程中,现有服务连接会被优雅地管理,做到前端无感知。
-
服务注册与发现 (Service Registration and Discovery)
像前面已经讨论的,分布式的多节点部署带来的一个问题是这些单个节点可以由于硬盘,网络等各种原因导致其失败。新的节点会补上来。另外计算节点在做自动伸缩时,节点地址也会发生动态变化。服务注册与发现可以体现服务的最新的可用节点。负载均衡器可以基于这个信息安排调用请求的导流。
3、云原生的工具(T)
云原生的工具:自环,框架,生产模拟,分踪,自测,自滚,CI,CD,版管
工欲善其事必先利其器。云原生的应用由很多微服务组成。云原生应用的特点就是能够快速更新以满足市场和用户的需要。应用的更新是通过微服务的快速更新迭代来实现的。行业顶尖公司的应用在现网(生产环境)更新是以秒级来计算的。也就是每天的更新可以达到近万次。为了支持如此高频的现网更新,同时还要保证更新的质量,有效的高度自动化的研发工具是能否成功地持续开发云原生应用的关键。
-
自助环境获取(Self Serviced Environment Acquisition)
无论是开发新功能,或者复现一个问题,工程师最大的抱怨就是建立相应的开发环境。装操作系统,装工具,下代码,做配置。要折腾好几天才可以开始看具体问题。切换成本非常大。所以有预制的开发资源(虚机或者容器),上面预装了相应的开发环境和配置,并且这些资源可以自助获取,可以大幅提高研发人员的工作效率。
-
统一标准的服务开发框架或基础设施 (Standardized Service Framework or infrastructure)
开发一个高质量的微服务,需要考虑的因素很多。除了服务本身的商业逻辑,还需要关注每个服务都需要处理的公共功能,例如身份验证与授权,限流,缓存,日志,监控与度量,等等。这样使得开发人员不能专注于自己的商业逻辑,降低了开发效率。而且对开发人员的要求也更高。公共功能的实现也不能达到一致的质量和行为。所以使用统一标准的服务开发框架有助于云原生应用的开发。Spring Boot是一个这样的开源的服务框架。亚马逊使用Coral服务框架。不过这些源代码级的服务框架会对编程语言有限制。最近兴起的服务网格(Service Mesh)从网络层面解决这个问题,应该是一个长期的发展方向。
-
贴近现网环境的模拟开发环境 (Production Environment Simulation for Local Development)
开发的一大痛点就是程序在开发机上运行正常,但是到现网环境不工作。简单的环境可以提供通过基础设施即代码(Infrastructure as Code)的方式自动建立。谷歌的Cloud Code工具就是采用这种做法。亚马逊的AWS CDK也提供了类似功能。
依赖复杂环境和相关数据的程序调试则相对困难。同一服务的多个版本的存在更需要借助API网关进行管理。即使这样仍需要把开发机的最新代码打包部署到测试环境,无法直接在开发人员本地的开发机上进行代码调试,降低开发效率。目前最佳的解决办法是使用开源的Telepresence用双向代理把本地开发机接入到测试环境里。这样本地机被虚拟成在测试环境里的一个节点。开发者就可以直接在本机上做调试了。
-
分布式跟踪(Distributed Tracing)
一个用户服务请求很有可能需要提供调用多个服务完成,即A服务调用B服务,B服务调用C服务的方式。于是用于跨服务的调用链的跟踪就变得非常重要。像Zipkin,Jaeger这样的分布式跟踪工具可以提供这种的能力。这样在做端到端的调试和调用链分析的时候就非常有用了。
-
测试自动化 (Test Automation)
应用的质量至关重要。对要上线的功能执行相应测试用例才能确认软件包的质量。快速上线的要求需要测试用例的高度自动化来保障。首先是自动化尽量多的单元测试。功能测试中的API测试由于不涉及UI,所以测试用例的自动化也比较好维护。因此在设计功能的测试用例时,尽量使用API测试。对于UI测试,由于UI可能的变化,UI在测试运行时所处状态和时间问题,导致UI的自动化测试用例的运行不够稳定。所以在设计UI测试用例时要着重注意提高测试稳定性。需要考虑的策略包括:使用类似辅助功能模型(accessibility model)的功能来驱动UI,初始状态的检验和重设,用智能等待(smart wait)解决时间问题(timing issue),简化或者隔离测试环境以降低环境噪音。最后就是有足够的测试日志和截屏信息。这样当有测试用例失败时,可以迅速找到失败的原因。
-
场景模拟 (Scenario Simulation)
当你调试应用的一些时候,你需要调用到其他服务。并且需要这些接口返回特定的数据。有时候这些接口还没有准备好,或者设置那个接口返回你所需要的数据比较困难。这时可以采用接口模拟工具(mock)去模拟你需要的场景。
-
A/B测试 (A/B Testing)
云原生的应用应该利用云应用的实时反馈优势,理解客户的诉求。像开源软件Convert就是一个不错的A/B测试的选择。
-
开发者工具网站 (Simple developer web portal)
这个比较容易理解。所有研发工具最好有一个公共入口。这样可以提高工具的可发现性。
-
持续集成 (Continuous Integration)
一个应用一般会有很多服务组成。这些服务都在由不同的研发团队并行开发。持续集成系统会定期把不同开发人员提交的新代码集成在一起,进行编译和自动化测试。以时刻保证应用的质量。
-
持续交付流水线 (CD Pipeline)
与持续集成相关的是持续交付流水线。持续交付流水线的目的是确认应用发布包的质量并最终将发布包部署到现网环境。持续交付流水线一般会包含几个阶段。每一个阶段会对应一个部署环境。每一个阶段会定义此阶段需要执行的测试内容。流水线会负责这些环境的管理并根据每个阶段的测试执行结果决定是否把新的发布包沿着流水线继续向前推动。Jenkins是目前极为流行的CI/CD的执行工具。
-
灰度发布和回滚自动化 (Gray Release and Automated Rollback)
研发的最后一步就是把发布包部署到现网。云原生的应用在新版本更新时要保证服务的持续性。如果一个应用仍然需要定期地下线进行维护,在此时间段不能使用,那这个应用还没有完成云原生的征程。云原生的应用经常会通过灰度发布等方式达到服务的持续性。灰度发布过程中,灰度发布引擎会先把部分节点下线,进行服务的版本更新和测试。版本更新过程一般不会覆盖旧的版本,这样在需要的时候方便版本回滚。新版本测试成功后,会把更新后的节点上线,把现网的正常流量部分导流到新版本的节点上。如此循环操作,直到所有节点都转到新版本上。在这个发布的过程里,如果发生新版本更新失败,灰度发布引擎会触发回滚机制,把已更新的版本节点回退到更新前的版本。当然在这个过程里会涉及到具体的升级和回滚的策略,比如每次升级的节点数量,现网导流到新节点的流量,如何定义更新失败,回滚的次序和节点数量等等,都可以在灰度发布引擎中定义。
-
依赖与版本管理 (Dependency and Version Management)
云原生的应用使用微服务的架构。微服务的功能相对独立。微服务需要与其他微服务合作去完成某项任务。不同版本的服务功能会有所不同。有时某个服务需要另外一个服务的某个特定版本里的功能。这就产生了服务的版本依赖。在服务众多的情况下,这个依赖关系会比较复杂。依赖和版本的有效管理对服务编译和上线的运维都有重要的影响。亚马逊的VersionSet和LinkedIn的Dependency Service从不同角度去解决这个问题。
4、云原生的运维(O)
云原生的运维包含以下重要的因素(容,服感→服恢,采→报,调,视,定,备恢,工单,可测)
-
基于容器的部署(Container Based Deployment)
云原生的一个基本要求是应用可以快速部署。容器的秒级拉起时间可以完全满足这一要求。如果一个容器挂机,也可以马上被替补。容器在一定程度上还完成了跨云兼容的任务。另外,容器如果与服务网格结合使用,可以简洁方便地完成几乎所有复杂的网络导流的需求。
-
服务状态的实时感知(Real Time Service Status through Monitoring)
云原生的运维必须可以实时感知服务的运行状态。任何黑盒的服务都是不可支持的。运维人员可以通过对资源和应用收集预定参数,以监控服务的运行状况。根据服务的实时运行状况,运维人员可以采取相应的措施使得服务健康地持续运行。
-
实时报警(Real Time Alerting)
云原生的运维需要有一个报警引擎。针对运维过程中收集的监控数据,运维人员可以通过报警引擎去定义当被监控数据超过预定值后,产生报警信息。报警信息可以通过各种形式传达给运维人员,比如监控大屏信息,短信,电话,电子邮件等。这样可以是运维人员及时意识到服务运行中产生的问题。随着AI在DevOps中的不断应用,报警引擎的规则也会逐渐由人工产生逐渐转向AI自动生成。
-
基于日志的运维数据采集和处理(Log Based Data Collection and Processing)
微服务在运行中会产生大量的系统和服务日志。这些日志里包含了大量关于系统和服务的运行信息。云原生的运维需要有一个高性能的分布式日志处理系统,去从各个节点收集日志,存储日志,和处理这些日志。
-
资源管理与调度(Resource Management and Allocation)
云计算厂商需要保证资源合理,有效和充分的应用,以获得最佳性价比。一方面,我们不想资源闲置造成浪费。另一方面,我们不想有需求却由于没有可用资源而影响服务性能。另外资源调度系统需要管理硬件的定期主动下线维修和软件的主动更新和系统重启,以降低服务的被动故障率,提高服务在线时间。
-
运维和业务相关指标的图形化的数据仪表盘 (Visualized Dashboards for Operational and Business Metrics)
很多服务厂商需要运维大量的微服务。理解系统的整体性能状况和每一个微服务的运行状况是一项极端复杂的任务。清晰反映系统和服务运行状况的图形化的数据仪表盘对运维人员的工作效率至关重要。仪表盘需要反映系统的整体状况,又可以利用点击深入到具体服务的运行状况。重要报警信息也可以在这里显示和处理。仪表盘数据需要及时更新。仪表盘内容可以由运维人员进行选择和自定义。
-
快速问题定位 (Fast Issue Isolation)
多数公司需要运维成百上千的微服务。当你的微服务变慢或者系统不能正常工作,快速找到问题的根源变得非常具有挑战性。一个功能的完成可能经过多个服务。一个服务的集群通常会有多个节点。所以一个功能的完成,很有可能是前端调用了服务A(使用了A集群里的A1节点),服务A再调用服务B(使用了B集群里的B2节点),服务B又调用了服务C(使用了C集群里的C3节点)。所以你会有一个类似这样的数据链:Client<->A1<->B2<->C3。云原生的运维需要有工具帮助快速定位问题出现在哪个服务的哪个节点上。
-
故障的自动恢复 (Automated Recovery from Failure)
云原生的应用需要服务有高可用性。服务不中断。所以当服务失败发生时,如何快速地恢复服务是一个需要解决的问题。服务的错误种类很多,处理方式也不尽相同。**高度自动化的服务恢复系统,**可以根据不同的服务错误,自动触发相应的处理机制。
-
自动在线备份和灾难恢复。(Automated Backup and Disaster Recovery)
由于云计算提供的云服务的故障原因,或者是业务服务自己的缺陷,甚至是人为的因素,都有可能导致服务的失败。严重的会导致数据的丢失。云原生运维需要通过在线备份来恢复数据,避免数据的永久丢失。云原生的运维还需要提供方便的数据检验机制,以确认备份和灾难恢复机制是确实在运行正确的。
-
现网测试和现网探针 (Test in Production/Probe in Production)
即使工程团队力图使测试环境尽量贴近生产环境(现网),完全的一致性是不可能的。当一个服务更新使用灰度部署上线的过程中,应当使用现网的测试能力去确认功能在现网运行如同预期。在服务在现网的运行过程中,除了后台的各种监控机制,还可以提供现网探针的功能,从使用者的视角去监控评估服务的运行状态。
-
工单系统 (Ticketing System)
现网出现问题后,问题需要有统一的全员可见的系统用来跟踪问题的解决状态。状态更新的通知机制也会使运维更有效率。
-
多版本部署 (Multiple Versions in Production)
由于微服务的独立性,各服务以自身的节奏向前推进。各种各样的现实情况会导致某个服务需要在现网有多版本的存在。云原生的运维需要支持这样的部署方式。并且需要利用接口路由把调用引导到正确的服务版本的节点。
-
历史审计 (Audit Trail Information)
由于云原生应用的分布式特点,每一个有一定规模的站点都可能有成千上万的节点组成。每个节点上都会有事件不断的发生。一个详尽并且全面的历史审计系统对整个云应用的管理至关重要。
-
可测量的服务SLA (Measurable Service Level Agreement)
云原生的应用一定会有可测量的服务SLA。服务运维过程中会产生大量的系统和服务数据。这些数据提供了从多个维度衡量一个服务的客观依据。这个是实现DataOps的基石。
-
资源记账 (Resource and its Usage Accounting)
云计算的资源的使用效率需要不断优化。这个能力是云计算与传统数据中心相比的一个根本优势。云原生的运维会有效的利用运维数据与相应的工具对这个需求提供支持。
以上是对云原生的运维的主要特性的总结。我们也许不能期望所有公司都做到上述的云原生运维要素,并且每一项都做得很好。但是这些要求肯定是高度云原生的运维所需要不断接近的目标。
四、常见的云原生技术整理(待更新)
- Nacos介绍和使用:nacos应用于微服务,主要实现服务发现和服务检查
- Nacos服务注册中心应用实践
- k8s-学习笔记总结(从入门到放弃的学习路线)
- Harbor部署及使用
- MinIO官网
- MinIO基础知识介绍
- Calico官网
- Calico网络原理、组网方式和使用
- Calico网络原理分析
- K8s架构|全面整理K8s的架构介绍
- k8s官方文档