从零开始的tensorflow小白使用指北
文章目录
- TensorFlow是什么
- TensorFlow搭建神经网络
-
- 数据准备
-
- 构建data_iterator
- 模型准备
- 模型训练
- 保存/加载模型参数
- 模型评价
从零开始的pytorch小白使用指北这篇博客介绍了Python深度学习的量大框架之一——pytorch,今天来对照学习另一个框架:TensorFlow。
TensorFlow是什么
TensorFlow是一个开源的深度学习库,Tensor(张量)意味着 N 维数组,Flow(流)意味着基于数据流图的计算,TensorFlow即为张量从图的一端流动到另一端。其作用主要体现在以下两个方面:
- 支持异构设备分布式计算,从电话、单个CPU / GPU到成百上千GPU卡组成的分布式系统。
- 可以对定义在 Tensor(张量)上的函数自动求导。
TensorFlow搭建神经网络
数据准备
这里以deepctr中预定义的DeepFM系列为例进行数据准备,模型从deepctr.models导入,自定义的模型构建在后面具体讲解。
需要构建sparse_feat_dict、dense_feat_list,两类特征共同组成data_input,以及data_labels。
以 kaggle 上的一个CTR预估竞赛数据集The Criteo Display Ads dataset 为例,里面包含13个数值特征:I1-I13,和26个类别特征:C1-C26。
数据获取:https://github.com/shenweichen/DeepCTR/blob/master/examples/criteo_sample.txt
 `
`
import pandas as pd
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from deepctr.models import DeepFM
data = pd.read_csv('./criteo_sample.txt')
sparse_features = ['C' + str(i) for i in range(1, 27)]
dense_features = ['I'+str(i) for i in range(1, 14)]
data[sparse_features] = data[sparse_features].fillna('-1', )
data[dense_features] = data[dense_features].fillna(0,)
target = ['label']
data.head(5)
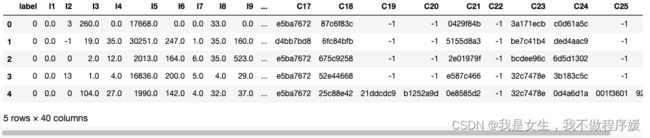
# 特征预处理
# 类别特征:使用LabelEncoder重新编码(或者哈希编码)
for feat in sparse_features:
lbe = LabelEncoder()
data[feat] = lbe.fit_transform(data[feat])
# 数值特征:使用MinMaxScaler压缩到0~1之间
mms = MinMaxScaler(feature_range=(0, 1))
data[dense_features] = mms.fit_transform(data[dense_features])
data.head(5)
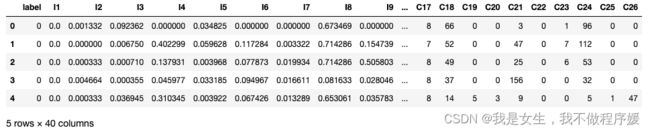
# 因为模型要对类别特征进行Embedding,所以需要告诉模型每一个特征组有多少个embbedding向量,可通过pandas的nunique()方法统计:
sparse_feature_dict = {feat: data[feat].nunique() for feat in sparse_features}
dense_feature_list = dense_features
# 进行Embedding
sparse_feat_columns = [SparseFeat(k,vocabulary_size = v,embedding_dim = 8) for k,v in sparse_feature_dict.items()]
dense_feat_columns = [DenseFeat(k, dimension = 1) for k in dense_feature_list]
print(sparse_feat_columns[0])
print(dense_feat_columns[0])

# 分别指定dnn网络和LR网络的输入数据,一般都选择全部特征
dnn_feat_columns = sparse_feat_columns + dense_feat_columns
linear_feat_columns = sparse_feat_columns + dense_feat_columns
# 构造DeepFM网络,其实这里只指定了网络结构,并没有输入实际的数据
model = DeepFM({"sparse": sparse_feature_dict, "dense": dense_feature_list},
final_activation='sigmoid')
model.compile("adam", "binary_crossentropy",
metrics=['binary_crossentropy'], )
# 拼接sparse特征和dense特征输入模型进行训练(这里才实际输入了数据)
# data[col].values: 将Series转化为 ndarray
model_input = [data[feat].values for feat in sparse_feature_dict] + [data[feat].values for feat in dense_feature_list]
history = model.fit(model_input, data[target].values, batch_size=256, epochs=10, verbose=2, validation_split=0.2, )
print("train done")
![]()
构建data_iterator
模型准备
主要分为Model和Layer两个层次。
Model:tensorflow定义的神经网络,对应pytorch的nn.Module;
Layer:神经网络的层,对应pytorch的nn.Linear,nn.Conv2d等。
用法一:和pytorch类似,自定义Model子类继承 tf.keras.Model,被自定义的神经网络类所继承。
自定义一个神经网络class通常包括两部分:init() 定义网络层,call() 函数定义网络计算函数。
# Model定义
class LinearModel(tf.keras.Model):
def __init__(self):
super().__init__() # python2使用super(MyModel,self).__init__()
self.layer1 = tf.keras.layers.Dense(units=1,
kernel_initializer=tf.zeros_initializer(),
bias_initializer=tf.zeros_initializer())
self.layer2 = tf.keras.layers.BuiltinLayer/CustomLayer(...)
def call(self, input):
x = self.layer1(input)
output = self.layer2(x)
return output
myModel = LinearModel()
Layer:作为Model中的元素,代表一个网络层。
可以使用tf.keras.layer.内置函数,也可以自定义神经网络层。
'''
Embedding层:将每个特征转化为一个指定维数的向量,只能作为神经网络的第一层。
层输入是1*input_dim向量。输出是1*input_dim*output_dim向量。
'''
tf.keras.layers.Embedding(
input_dim = voc_size,ouput_dim = embedding_size, embeddings_initializer
)
'''
dense层:全连接层,对输入变量进行线性变换+激活函数处理
activation: tf.nn.relu, tf.nn.tanh, tf.nn.sigmoid等
name: string,该层的名字,可在model.compile指定各输出的loss和loss_weight时使用
'''
tf.keras.layers.Dense(
units = output_dim,activation,use_bias,name
)
'''
Lambda(): 构建自定义函数层,将输入变量进行lambda函数转化
该例传入[output_prob,embedding_tensor]二元组,计算操作取二元组的第一个元素和第二个元素进行matmul(矩阵乘法)
'''
self.mylayer = tf.keras.layser.Lambda(lambda x: tf.matmul(x[0],x[1]))
output = self.mylayer([output_prob,embedding_tensor])
用法二:定义一个forward chain,通过指定 tf.keras.Mode 的 input 和 output定义网络结构。
deepctr即采用了这种方式
import tensorflow as tf
def MyModel(inputs): # 注意,这里是def function,而非定义class
x = tf.kera.layers.Dense(4,activation = tf.nn.relu)(input)
outputs = tf.keras.layer.Dense(5,activation = tf.nn.softmax)(x)
model = tf.keras.Model(inputs = inputs,outputs = outputs)
model = MyModel(tf.keras.Input(shape=(3,))
模型训练
model.compile():指定loss等参数,model.fit()使用设置好结构和参数的模型进行训练
model.fit():使用设置好结构和参数的模型进行训练。可以修改Keras内置的fit() 函数,在不同epoch动态调整模型参数。
'''
optimizer: string or optimizer instance
loss: loss function,可自定义,当model的output有多个时,可使用功能字典指定不同loss函数
metrics: 用于参考的指标,可指定多个,不用于loss计算和参数更新
loss_weights: 字典,当model有多个output时,可以分别指定其权重,最终loss为其加权和
'''
model.compile(tf.keras.optimizers.Adam(learning_rate = 0.001),
loss = 'binary_crossentropy'
metrics=['binaray_crossentropy')
# 多输出示例
def MyModel(input_list):
output1 = tf.keras.layers.Dense(...,name = 'loss1')
output2 = tf.keras.layers.Dense(...,name = 'loss2')
model = tf.keras.models.Model(inputs = input_list,outputs = [output1,output2])
return model
model = MyModel(...)
model.compile(...,loss = {'loss1':'binary_crossentropy',
'loss2':'binary_crossentropy'}
loss_weights = {'loss1':0.5,'loss2':0.5}
...)
model.fit(
train_data, train_labels,
batch_size, num_epochs, verbose=2, validation_split=0.01)
保存/加载模型参数
model.save_weights() & model.load_weights()
其中,model_path为.pkl文件。
if not exists(model_path):
model.compile()
model.fit()
model.save_weights(model_path)
else:
model.load_weights(model_path)
模型评价
probs = model.predict(data)
calc_all_metrics(labels.probs)