在window10下python:ocr实战
前言
最近在做一个ocr的项目,主要是识别数字和英文字符,因此在尝试现在开源的各种基于python语言(其实是想在pytorch框架下使用)的ocr库
先附上测试图片如上:

easyocr
pip install easyocr

在大量warning后成功安装了!!!
因为我主要是识别数字和英文字符,使用中文版本效果不佳,它的调用原理好像是easyocr.Reader()的第一个参数只会调用列表的第一个,换成英文之后出错率为1/14(仅用上图衡量)
import easyocr
path='C:/Users/11027/Desktop/test1.jpg'
reader = easyocr.Reader(['en'],gpu = False)
result = reader.readtext(path)
print(result)
#22G1会识别成'2261'
输出:
Using CPU. Note: This module is much faster with a GPU.
[([[307, 67], [349, 67], [349, 121], [307, 121]], '[0]', 0.2496181348819496), ([[82.817179374673, 18.268717498692013], [226.37590341350617, -1.1571357200124375], [232.182820625327, 75.73128250130799], [88.62409658649383, 95.15713572001243]], 'TBJU', 0.8707327246665955), ([[86.65181877371504, 84.3117294627456], [289.02336666519545, 60.9225513668679], [292.34818122628496, 138.6882705372544], [89.97663333480457, 162.0774486331321]], '004057', 0.9909699998969699), ([[88.96405360576286, 157.26340370189882], [224.4601580727819, 137.28127584248975], [231.03594639423716, 210.73659629810118], [96.5398419272181, 230.71872415751025]], '2261', 0.9822619656327679)]
为了不让你们看的太辛苦,截了一个图

pytesseract
先去下载安装包
然后在终端
pip install pytesseract
给一张安装完成的图:

我的话一上来就报错了。
![]()
没有在路径上检查两个点:
①环境路径要增加两个系统环境变量(说实话我也不确定是不是两个都有用但是没啥影响)
具体增加的变量要根据自己下载的位置。比如我下载的位置是D:\computervision\ocr\ocr_project\Tesseract-OCR。
第一个是新增的
![]()
第二个是加在path中

②修改pytesseract.py
这个也是看自己的设置,我是直接pip install pytesseract在虚拟环境里,所以它的位置就在D:\conda\envs\pytorch\Lib\site-packages\pytesseract
测试代码
from PIL import Image
import pytesseract
path='C:/Users/11027/Desktop/test1.jpg'
text = pytesseract.image_to_string(path)
print(text)
大寄!啥也没识别到(是有效的,但是好像对于英文字符和数字效果不行)

重新训练的话太麻烦了先跳过了
cnocr
下载的话:
pip3 install cnocr -i https://mirrors.aliyun.com/pypi/simple/
会有一堆warning,但是不影响!
然后对应不同的ocr任务有不同的方案,具体的话可以看官方的github
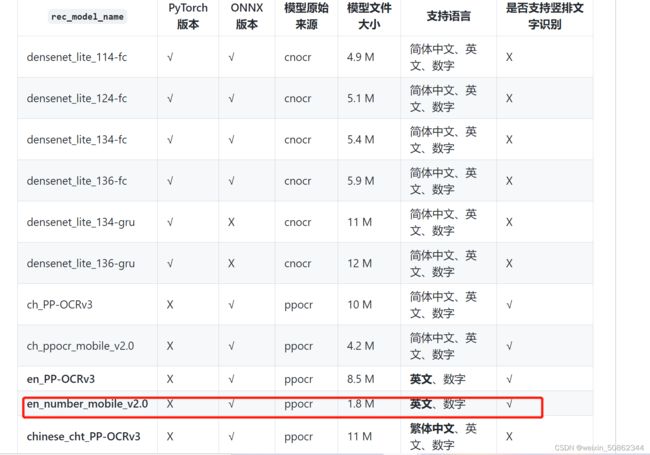
我用的是1.8M这个但是仍然是对比起其他开源的ocr库效果最香
from cnocr import CnOcr
path='C:/Users/11027/Desktop/test1.jpg'
ocr = CnOcr(rec_model_name='en_number_mobile_v2.0')
out = ocr.ocr(path)
print(out)
# import testcnocr
# print(cnocr.__file__)
全部都能识别到!!!
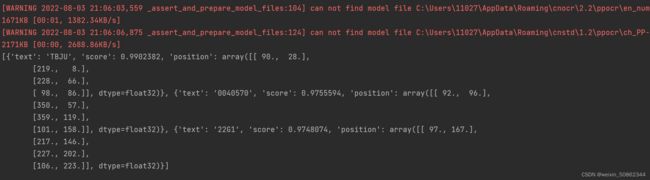
其实我一开始也是报了一个错的:太蠢了

错因:我把测试文件命名为cnocr了
paddleocr
不得不说要不是paddleocr在paddle框架下,我觉得paddleocr整体效果是最好的,当然cnocr也不错!