【Python工具】Python实现一款支持各大平台的视频下载器 | 附源码
相关文件
想学Python的小伙伴可以关注小编的公众号【Python日志】
有很多的资源可以白嫖的哈,不定时会更新一下Python的小知识的哈!!
需要源码的小伙伴可以在公众号回复视频下载器
简介
一款简单易用的视频下载器,目前支持的平台如下: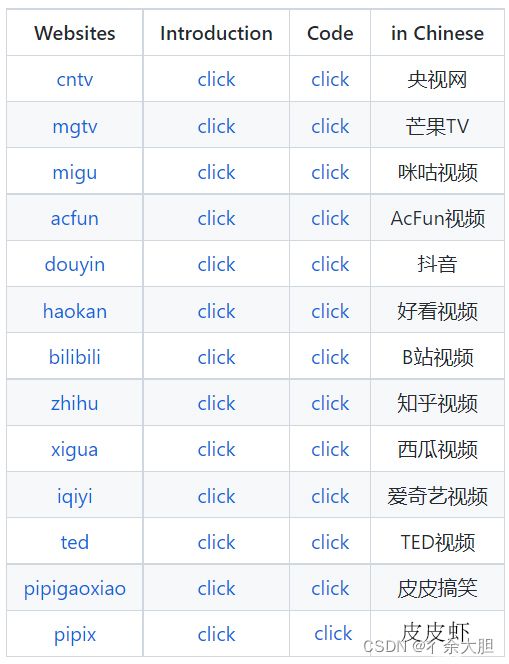
开发环境
Python版本:3.7.8
相关模块:
requests模块;
tqdm模块;
pyfreeproxy模块;
pyecharts模块;
以及一些python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
效果展示
直接输入我们的一个视频链接就可以直接下载到文件夹downloaded中

复制哔哩哔哩视频链接
b站视频链接
https://www.bilibili.com/video/BV1si4y1y76f?spm_id_from=333.999.0.0
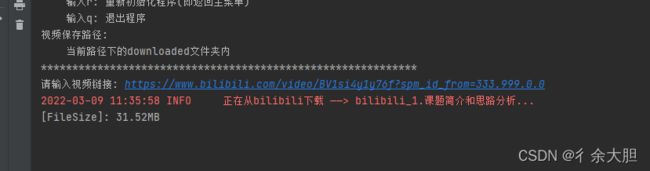

然后就可以直接播放我们的视频啦!!
代码实现过程
主代码
import sys
import copy
import json
import click
if __name__ == '__main__':
from modules import *
from __init__ import __version__
else:
from .modules import *
from .__init__ import __version__
'''basic info'''
BASICINFO = '''************************************************************
Function: 视频下载器 V%s
微信公众号: Python日志
操作帮助:
输入r: 重新初始化程序(即返回主菜单)
输入q: 退出程序
视频保存路径:
当前路径下的%s文件夹内
************************************************************'''
'''视频下载器'''
class videodl():
def __init__(self, configpath=None, config=None, **kwargs):
assert configpath or config, 'configpath of config should be given...'
self.config = loadConfig(configpath) if config is None else config
self.logger_handle = Logger(self.config['logfilepath'])
self.supported_sources = self.initializeAllSources()
'''非开发人员外部调用'''
def run(self):
print(BASICINFO % (__version__, self.config.get('savedir')))
while True:
# 视频链接输入
user_input = self.dealInput('请输入视频链接: ')
# 判断视频链接类型是否支持解析下载
source = self.findsource(user_input)
if source is None:
self.logger_handle.warning('暂不支持解析视频链接: %s...' % user_input)
continue
# 实例化
client = source(self.config, self.logger_handle)
# 视频链接解析
videoinfos = client.parse(user_input)
# 视频下载
client.download(videoinfos)
'''判断视频源'''
def findsource(self, url):
for key, source in self.supported_sources.items():
if source.isurlvalid(url): return source
return None
'''初始化所有支持的搜索/下载源'''
def initializeAllSources(self):
supported_sources = {
'ted': Ted,
'cntv': CNTV,
'mgtv': MGTV,
'migu': Migu,
'pipix': Pipix,
'acfun': AcFun,
'zhihu': Zhihu,
'xigua': Xigua,
'iqiyi': Iqiyi,
'douyin': Douyin,
'haokan': Haokan,
'bilibili': Bilibili,
'pipigaoxiao': Pipigaoxiao,
}
return supported_sources
'''处理用户输入'''
def dealInput(self, tip=''):
user_input = input(tip)
if user_input.lower() == 'q':
self.logger_handle.info('ByeBye...')
sys.exit()
elif user_input.lower() == 'r':
self.initializeAllSources()
self.run()
else:
return user_input
'''cmd直接运行'''
@click.command()
@click.option('-i', '--url', default=None, help='想要下载的视频链接, 若不指定, 则进入videodl终端版')
@click.option('-l', '--logfilepath', default='videodl.log', help='日志文件保存的路径')
@click.option('-p', '--proxies', default='{}', help='设置的代理')
@click.option('-s', '--savedir', default='videos', help='视频保存的文件夹')
def videodlcmd(url, logfilepath, proxies, savedir):
config = {
'logfilepath': logfilepath,
'proxies': json.loads(proxies),
'savedir': savedir,
}
dl_client = videodl(config=config)
if url is None:
dl_client.run()
else:
source = dl_client.findsource(url)
client = source(dl_client.config, dl_client.logger_handle)
videoinfos = client.parse(url)
client.download(videoinfos)
'''run'''
if __name__ == '__main__':
import os
rootdir = os.path.split(os.path.abspath(__file__))[0]
dl_client = videodl(os.path.join(rootdir, 'config.json'))
dl_client.run()
bilibili代码
'''
Function:
B站视频下载器类
'''
import re
import time
from .base import Base
from ..utils.misc import *
'''B站视频下载器类'''
class Bilibili(Base):
def __init__(self, config, logger_handle, **kwargs):
super(Bilibili, self).__init__(config, logger_handle, **kwargs)
self.source = 'bilibili'
self.__initialize()
'''视频解析'''
def parse(self, url):
response = self.session.get(url, headers=self.headers)
bv = re.compile('BV..........').search(url).group()
response = self.session.get(self.pagelist_url.format(bv), headers=self.headers)
response_json = response.json()
cid_list = [item['cid'] for item in response_json['data']]
titles = [item.get('part', f'视频走丢啦_{time.time()}') for item in response_json['data']]
download_urls = []
for cid in cid_list:
response = self.session.get(self.play_url.format(cid, bv), headers=self.headers)
response_json = response.json()
for item in response_json['data']['durl']:
download_urls.append(item['url'])
assert len(titles) == len(download_urls)
videoinfos = []
for idx, download_url in enumerate(download_urls):
videoinfo = {
'source': self.source,
'download_url': download_url,
'savedir': self.config['savedir'],
'savename': '_'.join([self.source, filterBadCharacter(titles[idx])]),
'ext': 'mp4',
}
videoinfos.append(videoinfo)
return videoinfos
'''初始化'''
def __initialize(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
self.pagelist_url = 'https://api.bilibili.com/x/player/pagelist?bvid={}&jsonp=jsonp'
self.play_url = 'http://api.bilibili.com/x/player/playurl?&cid={}&bvid={}&qn=80&fnval=0&fnver=0&fourk=1'
'''判断视频链接是否属于该类'''
@staticmethod
def isurlvalid(url):
valid_hosts = ['bilibili.com/video']
for host in valid_hosts:
if host in url: return True
return False
抖音代码
'''
Function:
抖音视频下载器类
'''
import re
import json
import time
import random
import requests
from .base import Base
from ..utils.misc import *
'''抖音视频下载器类'''
class Douyin(Base):
def __init__(self, config, logger_handle, **kwargs):
super(Douyin, self).__init__(config, logger_handle, **kwargs)
self.source = 'douyin'
self.__initialize()
'''视频解析'''
def parse(self, url):
url = re.findall(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+', url)[0]
response = self.session.get(url)
if response.url[:28] == 'https://www.douyin.com/user/':
videoinfos = self.multiparse(response)
else:
videoinfos = self.singleparse(response)
return videoinfos
'''批量下载用户的视频'''
def multiparse(self, response):
videoinfos = []
key = re.findall(r'/user/(.*?)\?', str(response.url))[0]
if not key: key = response.url[28: 83]
page_count, max_cursor = 35, 0
while True:
url = self.uid_url.format('post', key, page_count, max_cursor)
response = self.session.get(url, headers=self.headers)
response_json = json.loads(response.content.decode())
max_cursor, aweme_list = response_json['max_cursor'], response_json['aweme_list']
if max_cursor == 0: break
for idx in range(min(page_count, len(aweme_list))):
download_url = str(aweme_list[idx].get('video', {}).get('play_addr', {}).get('url_list', [''])[0])
videoinfo = {
'source': self.source,
'aweme_id': aweme_list[idx].get('aweme_id', None),
'download_url': download_url,
'savedir': self.config['savedir'],
'savename': '_'.join([self.source, filterBadCharacter(str(aweme_list[idx].get('desc', f'视频走丢啦_{time.time()}')))]),
'ext': 'mp4',
}
if videoinfo['download_url']: videoinfos.append(videoinfo)
time.sleep(random.random() + 0.2)
return videoinfos
'''下载单个视频'''
def singleparse(self, response):
url = self.iteminfo_url.format(re.findall(r'video/(\d+)?', str(response.url))[0])
response_json = json.loads(self.session.get(url, headers=self.headers).text)
try: download_url = str(response_json['item_list'][0]['video']['play_addr']['url_list'][0]).replace('playwm','play')
except: return []
videoinfo = {
'source': self.source,
'download_url': download_url,
'savedir': self.config['savedir'],
'savename': '_'.join([self.source, filterBadCharacter(str(response_json.get('item_list', [{}])[0].get('desc', f'视频走丢啦_{time.time()}')))]),
'ext': 'mp4',
}
return [videoinfo]
'''初始化'''
def __initialize(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Mobile Safari/537.36 Edg/87.0.664.66',
}
self.iteminfo_url = 'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids={}'
self.uid_url = 'https://www.iesdouyin.com/web/api/v2/aweme/{}/?sec_uid={}&count={}&max_cursor={}&aid=1128&_signature=PDHVOQAAXMfFyj02QEpGaDwx1S&dytk='
'''判断视频链接是否属于该类'''
@staticmethod
def isurlvalid(url):
valid_hosts = ['v.douyin.com']
for host in valid_hosts:
if host in url: return True
return False
皮皮搞笑视频
import re
import json
from .base import Base
from ..utils.misc import *
'''皮皮搞笑视频下载器类'''
class Pipigaoxiao(Base):
def __init__(self, config, logger_handle, **kwargs):
super(Pipigaoxiao, self).__init__(config, logger_handle, **kwargs)
self.source = 'pipigaoxiao'
self.__initialize()
'''视频解析'''
def parse(self, url):
pattern = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+', re.S)
url = re.findall(pattern, url)[0]
self.headers['Referer'] = url
try:
mid = re.findall('mid=(\d+)', url, re.S)[0]
pid = re.findall('pid=(\d+)', url, re.S)[0]
except:
mid = ''
pid = url.split('/')[-1]
data = {
'mid': int(mid) if mid else 'null',
'pid': int(pid),
'type': 'post',
}
response = self.session.post(self.content_url, data=json.dumps(data), headers=self.headers)
response_json = response.json()
download_url = response_json['data']['post']['videos'][str(response_json['data']['post']['imgs'][0]['id'])]['url']
title = response_json['data']['post']['content'].replace('\n', '')
videoinfo = {
'source': self.source,
'download_url': download_url,
'savedir': self.config['savedir'],
'savename': '_'.join([self.source, filterBadCharacter(title)]),
'ext': 'mp4',
}
return [videoinfo]
'''初始化'''
def __initialize(self):
self.headers = {
'Host': 'share.ippzone.com',
'Origin': 'http://share.ippzone.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36',
}
self.content_url = 'https://h5.ippzone.com/ppapi/share/fetch_content'
'''判断视频链接是否属于该类'''
@staticmethod
def isurlvalid(url):
valid_hosts = ['h5.ippzone.com', 'share.ippzone.com']
for host in valid_hosts:
if host in url: return True
return False
代码量太多,小编就不全部展示啦
代码获取可以关注小编公众号:Python日志
在公众号中回复:视频下载器就可以领取啦