Redis缓存雪崩、缓存穿透、缓存击穿
Redis缓存雪崩、缓存穿透、缓存击穿
- Redis缓存过程
- 缓存雪崩
-
- 解决方案
-
- 永不过期
- 合理的设置过期时间
- 使用Redis的分布式锁
- 缓存穿透
-
- 解决方案
-
- 过滤非法查询
- 缓存空对象
- 布隆过滤器
-
- 布隆过滤器的新增
- 布隆过滤器的查询
- 布隆过滤器的删除
- 布隆过滤器解决缓存穿透
- 布隆过滤器的特点
- 缓存击穿
-
- 解决方案
-
- 设置热点Key永不过期
- 使用Redis的分布式锁
Redis缓存过程
Redis数据库是一个nosql数据库,存储的数据格式是key-value。Redis数据库运行在内存中,因此他的查询速度比MySql快的多。所以我们会把一些用户经常查询的数据放在Redis中,当Redis有的时候就直接返回,当Redis中没有的时候再去数据库中查找。以此增加服务的运行效率。

缓存雪崩
Redis中的缓存数据是有过期时间的,当在同一时间大量的缓存同时失效时就会造成缓存雪崩。
比如说,在11点的时候大家都去饿了么点外卖,这个时候饿了么的Redis中就存了一大批商家的信息,并且饿了么的程序员给这个缓存设置的过期时间是6个小时。那么到下午5点晚饭时间又是一大波人来饿了么点外卖,这个时候Redis的缓存刚刚好集体过期了,短时间内大量的查询请求就全部落到了脆弱的MySql上,导致MySql直接爆炸!

解决方案
要解决Redis的缓存雪崩就需要避免Redis的缓存在短时间内大量的过期
永不过期
设置Redis中的key永不过期,但是这样会占用很多服务器的内存。
合理的设置过期时间
根据业务需要来合理的设置过期的时间。但是架不住有一些突发的情况。
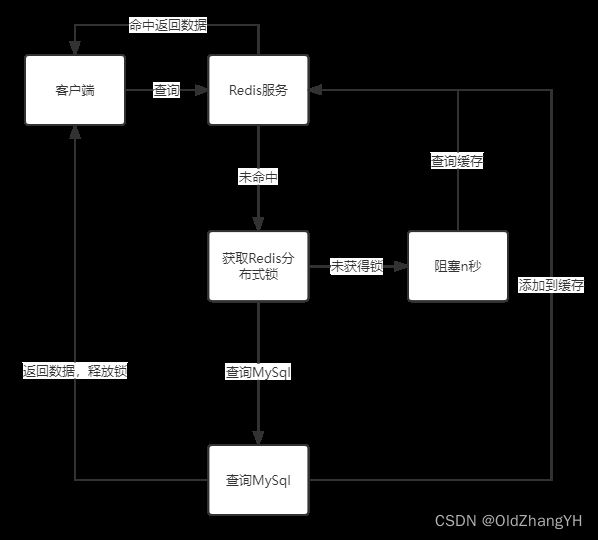
使用Redis的分布式锁
既然一瞬间大量请求落到MySql上会导致MySql爆炸!那么就加一点限制,让一时间只有一个相同请求落到MySql上,反正都是查询同一个信息,之后的其他请求就可以去Redis中找了。
缓存穿透
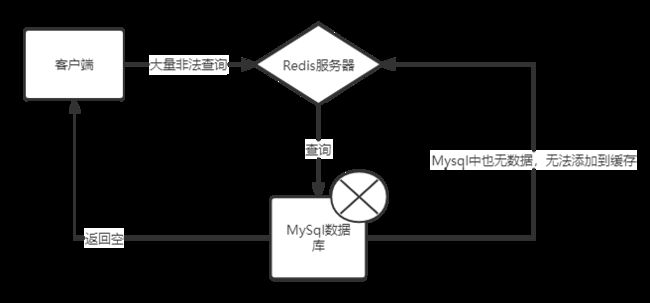
Redis缓存穿透指的是,在Redis缓存和数据库中都找不到相关的数据。也就是说这是个非法的查询,客户端发出了大量非法的查询 比如id是负的 ,导致每次这个查询都需要去Redis和数据库中查询。导致MySql直接爆炸!
解决方案
过滤非法查询
在后台服务中过滤非法查询,直接不让他落到Redis服务上。比如id<=0或者分页内容过大的等
缓存空对象
如果他的查询数据是合法的,但是确实Redis和MySql中都没有,那么我们就在Redis中储存一个空对象,这样下次客户端继续查询的时候就能在Redis中返回了。但是,如果客户端一直发送这种恶意查询,就会导致Redis中有很多这种空对象,浪费很多空间
布隆过滤器
布隆过滤器由一个二进制数组和k个哈希数组组成。
布隆过滤器的新增
当我们想新增一个元素时(例如新增python),布隆过滤器就会使用hash函数计算出几个索引值,然后将二进制数组中对应的位置修改为1。

布隆过滤器的查询
当我们想查询一个元素时(例如查询python),布隆过滤器就会使用hash函数计算出几个索引值,然后查询二进制数组中的对应位置是否都为1。如果都为1就说明改元素存在。但是布隆过滤器存在误判的可能性,因为不同的元素hash后的值可能是一样的,例如我们查询java,java经过hash计算出来的索引值和python的一模一样,那么就会认为java也在布隆过滤器中。

布隆过滤器的删除
同上,布隆过滤器删除就是把hash后数组对应的位置改成0.但是存在误删的可能。按照上面的例子删除python就会同时把java给删掉。
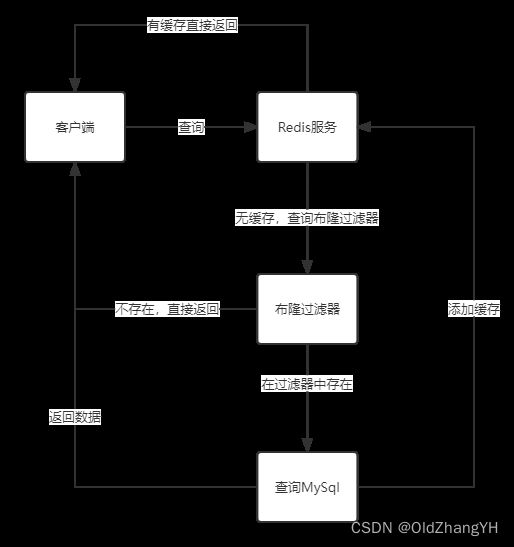
布隆过滤器解决缓存穿透
我们首先把MySql中的数据存到布隆过滤器中(由于使用二进制数组,也就是位图所以空间使用很少),之后如果Redis缓存中没有命中,就需要查询MySql数据库前先在布隆过滤器中查询是否在MySql有数据。
布隆过滤器的特点
- 存在误判的可能性
- 如果数据存在,那么一定返回true
- 查询的时间复杂度是O(k),k为hash函数个数
- k越大,数组长度越大,误判的可能性越低
- 使用位图(二进制数组)所以内存压力较小
缓存击穿
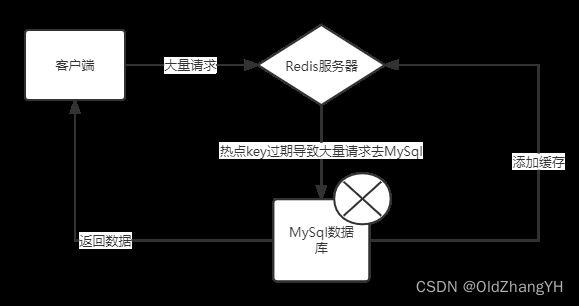
缓存击穿和缓存雪崩类似,也是因为Redis中key过期导致的。只不过缓存击穿是某一个热点的key过期导致的。当有一个热点数据突然过期时,就会导致突然有大量的情况直接落到MySql上,导致MySql直接爆炸!
解决方案
主要是两个思路,
- 让那个热点的key不要突然过期
- 不要让大量的请求落到MySql上。
设置热点Key永不过期
简单粗暴,我都不过期了,你就不可能绕开我去访问MySql。但是可能会对Redis内存造成巨大的压力,所以一般会设置一个较长的时间。
使用Redis的分布式锁
既然一瞬间大量请求落到MySql上会导致MySql爆炸!那么就加一点限制,让一时间只有一个相同请求落到MySql上,反正都是查询同一个信息,之后的其他请求就可以去Redis中找了。
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦