【C/C++实现 MiniTcMalloc】高并发内存池项目,七夕学会可以教另一半~
文章目录
- 一、内存池的作用
- 二、定长内存池
-
- 申请内存
- 释放讲解
- 三、大致介绍每一层的作用
-
- thread cache
- central cache
- page cache
- 四、每一层详解
-
- thread cache
- central cache
- page cache
- 五、释放逻辑
- 六、大块内存的申请/释放逻辑
- 七、常见问题
- 八、结果展示
一、内存池的作用
该项目是模仿谷歌的tcmalloc库,例如GoLang上面就有使用。
使用内存池的好处
效率问题: 池化技术即一次申请过量的资源,拿的时候就不用频繁申请了。因为频繁调用malloc,new申请内存空间实际上是比较慢的,如果一次申请大量内存,那么能极大程度提高效率。
缓解内存碎片问题: 内存碎片包括内碎片和外碎片,内碎片在该项目当中可以通过控制每一个内存往多少对齐从而控制。外碎片在该项目的PageCache层能够将小页进行合并,能够一定程度缓解外碎片问题。
项目涉及到的C/C++语言;链表,哈希表等容器;操作系统内存管理模块,多线程,互斥锁;以及单例模式。
开胃菜,定长内存池
二、定长内存池
定长内存池可以用作对象池,若需要频繁申请某个对象,可以用定长内存池来管理。
什么是自由链表:
- 自由链表即不再需要存储数据的链表,而是将一个个内存块链接起来的链表。并且自由链表当中的头插头删的时间复杂度都是O(1)。
原理:
- 从操作系统申请一块大块内存,在用户层进行管理。
- 释放该内存则用freelist(自由链表)将该内存挂起,不可以直接还给操作系统,因为释放一块内存需要从申请的虚拟地址还起,并且一次需要还完。
- 需要申请内存的时候先从自由链表当中找(O(1)操作),如果自由链表当中没有就切割大块内存。
- 释放回来的内存: 内存的释放一定是怎么申请,一定也要从头还起,所以对于已经申请的内存并且已经使用完的,我们选择挂在一个链表当中freelist。
所以定长内存池在只申请固定长度内存时性能达到极致,并且不需要考虑内存碎片的问题。
注意:申请的内存块要是4/8字节,如果小于这个则无法使用这种方法,因为指针在32位是4字节,在64位是8字节!
申请内存
T* New()
{
T* obj = nullptr;
// 优先把还回来内存块对象,再次重复利用
if (_freeList)
{
void* next = *((void**)_freeList);
obj = (T*)_freeList;
_freeList = next;
}
else
{
// 剩余内存不够一个对象大小时,则重新开大块空间
if (_remainBytes < sizeof(T))
{
_remainBytes = 128 * 1024;
//_memory = (char*)malloc(_remainBytes);
_memory = (char*)SystemAlloc(_remainBytes >> 13);
if (_memory == nullptr)
{
throw std::bad_alloc();
}
}
//需要考虑要的内存没有一个指针大的情况
obj = (T*)_memory;
size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);
_memory += objSize;
_remainBytes -= objSize;
}
// 定位new,显示调用T的构造函数初始化
new(obj)T;
return obj;
}
代码片段讲解:
if(_memory == nullptr)是一个错误的判断,因为只有第一次_memory会为空,后续即使内存不够开辟一个对象,此时_memory也不是NULL了,所以需要定义一个成员变量记录剩余的字节数,对剩余不足以T的对象空间直接抛弃,后续不会有人使用这块内存空间,不会影响我们的释放和申请逻辑。
所以判断调节变为if(_remainBytes < sizeof(T))即剩余的内存只要不够就释放。
释放讲解
void Delete(T* obj)
{
// 显示调用析构函数清理对象
obj->~T();
// 头插
*(void**)obj = _freeList;
_freeList = obj;
}
代码片段讲解:
*(void**)obj = _freeList;_freeList = obj;组成了头插,*(void**)obj实际上是想取出obj的4/8字节,由于void**是地址,32位4字节,64位8字节,用这种写法可以适配两个平台。
若有内存m1,m2,区分m1 = m2 与 NextObj(m1) = m2
- 赋值是将m2内存的值拷贝。
- NextObj则是将m2的地址进行拷贝到m1的内存上。
当然,若是要替换malloc,上述new,malloc都是要被替换的:
VirtualAlloc就是windows下申请内存的方法。
Linux需要替换成brk和mmap。
介绍每一层的大致作用,避免后面针对每一层的介绍完后忘记前面的作用~
三、大致介绍每一层的作用

thread cache

thread cache是管理小块内存,如上图,0下标的桶后面挂着都是8字节的内存,是每一个线程都各自私有一个的,他是由线程本地存储(TLS)实现的,thread cache类似有多个定长内存池实现,用户若是需要小于256KB的内存现在这一层寻找,若是能够找到,立马返回,并且这一层的访问由于是每一个线程私有一份,所以不用加锁,效率很高(只涉及单链表的头删)。
central cache
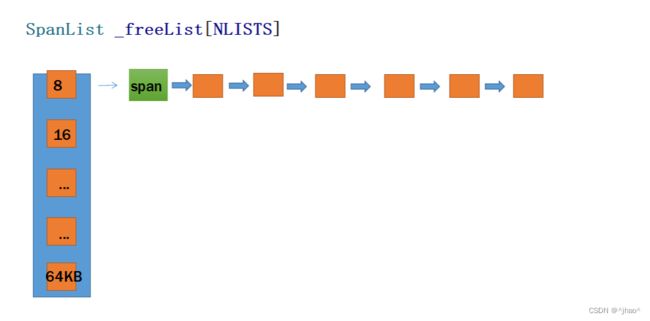
- central cache 与thread cache层管理的内存的大小相同,不同的是central cache是管理页,
如0下标的桶,管理的都是若干页,一个页的大小8KB,这里的不同字节后面挂着的页是不同的,当下标越大,则桶的页可能会越大。并且central cache的页的内存是已经被切分好若干块的,thread cache申请central cache只能到对应下标处,不能到其它的桶获取内存。
例如,一页8KB,能够切出1024个8字节的小内存,而申请不到一个256KB的内存。后续讲解如何得知该桶后面的页是多大(NumMovePage函数)。 - 并且需要注意的是访问central cache是需要加桶锁的,central cache还需要起到居中调度的作用,对于某个thread cache的链表过长的时候是会向central cache回收,并且用户申请内存在thread cache没找到经由central cache若找到对应桶有页,就可以用这个页的数据。
解释thread cache为什么要和central cache申请内存的时候对应
- 方便释放逻辑,若都是从central cache的一个桶获取,那么释放的时候只用锁住一个桶,倘若是多个桶当中获取的,那么需要一次锁住多个桶。
page cache

page cache与前两层不同,不同的桶管理的是不同大小的页,若central cache的桶后挂的内存满足对应的页的大小,就可以往下放,生成一个更大的页。但是由于涉及到大页的合并,所以访问page cache层的时候需要加大锁。
但是不必太过担心效率问题,因为通常来说,分配的逻辑只有合适,到page cache的可能是比较低的。
四、每一层详解
了解了每一层大致的作用,接下来是对于每一层的详解
thread cache
在上面的叙述中,我们知道thread cache是类似多个定长内存池,这个实现起来很简单,但是我们要多少个定长内存池,并且间距怎么设置合适其实更值得思考。
假设我们每8个字节都用一个桶映射:
- 倘若256KB全部都是以8字节来对齐,那么ThreadCache需要开辟
32768个桶,这个桶数是十分多的,每个桶虽然只有一个指针变量,并且这一种方式的内存浪费可以有效的控制在较低的一个范围。但是我们还是采取梯度对齐的方案。
梯度对齐和按8字节的对比
- 梯度对齐桶数更少,但是申请内存的时候浪费的内碎片会更多。
- 8字节对齐的话内碎片浪费更少,就是桶数过多。
综上,每一个字节都开一个自由链表更加不可能了,所以只能一个梯度设置一个大小,也就是申请的内存可能会给多,但是实际上使用的时候他并不会用的内存的剩余部分,最后没用上的部分称之为内碎片。所以我们需要选择一个合适的方式去对其,保证:桶的数量不会太多,并且空间浪费也处于一个合理的区间。

解决方案:
- 保证每一个桶申请出来最多浪费10%左右的内碎片浪费。
如何定位到我们需要的桶
- 当我们需要一个size大小的空间,去哪一个哈希桶当中找实际上是一个问题。
- 如果我们每次找需要遍历所有桶,那么申请的流程未免太慢了。有一种算法能够O(1)让size找到对应的桶上面找,实际上也是哈希的一种思想。
[1,128]不纳入考虑,因为这个1即使对齐到2都是浪费了50%,总体上看浪费的空间实际上是10%
下图当中浪费率=浪费的空间/实际的空间,分子这里浪费的空间最多是对齐数-1,分母的最小的时候就是浪费率最高,我们看浪费率最高的场景,那么分别就是1+7,129+15,1025+127,8*1024+1025…算出来除了第一个,浪费率都在10%左右。

桶数就是128/8,(1024-128)/16即【128+1,1024】有56个桶
其中RoundUp函数就是让字节对齐到某个梯度。
void* ThreadCache::Allocate(size_t size)
{
assert(size <= MAX_BYTES);
//到对应的桶当中进行申请,若没有则像CentralCache层申请
size_t alignSize = SizeClass::RoundUp(size);//对齐数
size_t index = SizeClass::Index(size);//桶
//优先到桶中寻找
if (!_freeLists[index].Empty())
{
return _freeLists[index].Pop();
}
//不得不往CentralCache层要了
return FetchFromCentralCache(index, alignSize);
}
Index可以通过传进的字节数匹配到访问的对应的桶,由于是按照梯度进行计算,所以Index也需要按照梯度进行计算桶的位置。
static size_t Index(size_t size)
{
static int arr[] = { 16,56,56,56 };
if (size <= 128)
{
return _Index(size, 3);
}
else if (size <= 1024)
{
return _Index(size - 128, 4) + arr[0];
}
else if (size <= 8 * 1024)
{
return _Index(size - 1024, 7) + arr[0] + arr[1];
}
else if (size <= 64 * 1024)
{
return _Index(size - 8 * 1024, 10) + arr[0] + arr[1] + arr[2];
}
else if (size <= 256 * 1024)
{
return _Index(size - 64 * 1024, 13) + arr[0] + arr[1] + arr[2] + arr[3];
}
else
{
assert(false);
return -1;
}
}
static inline size_t _Index(size_t bytes, size_t align_shift)
{
//7 15
return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}
RoundUp函数的作用是对齐,类似size为7字节,他就会帮助我们对齐到8字节。
static size_t RoundUp(size_t size)
{
if (size <= 128)
{
return _RoundUp(size, 8);
}
else if (size <= 1024)
{
return _RoundUp(size, 16);
}
else if (size <= 8 * 1024)
{
return _RoundUp(size, 128);
}
else if (size <= 64 * 1024)
{
return _RoundUp(size, 1024);
}
else if (size <= 256 * 1024)
{
return _RoundUp(size, 8 * 1024);
}
else
{
assert(false);
return -1;
}
}
static size_t _RoundUp(size_t size, size_t align_size)
{
//7 8 14 & 7~ 1110 1000
return (size + align_size - 1) & (~(align_size - 1));
}
如何让每个线程有独立的threadCache:
- 倘若设置成全局变量或者是静态变量,那么访问threadcahce的时候就需要加上一把锁,这明显是不好的,而我们采用的方法是tls,thread local storage–线程本地存储,类似线程独享的资源。TLS,是一种变量的存储方式,这个变量在他所在的县城是 全局可访问的,但是不能被其他线程访问到,这样就保持了数据在线程中的独立性。
自由链表结构,方法一览:
class FreeList
{
public:
void Push(void*& obj)
{
//头插两步骤
NextObj(obj) = _freeList;
_freeList = obj;
++_size;
}
void* Pop()
{
assert(_freeList);
//保存当前,_freeLists指向下一个节点即可
void* obj = _freeList;
_freeList = NextObj(obj);
_size--;
return obj;
}
bool Empty()
{
//为NULL则返回true
return _freeList == nullptr;
}
void PushRange(void* start, void* end, size_t n)
{
//将整个内存块看成一个整体
assert(start);
assert(end);
NextObj(end) = _freeList;
_freeList = start;
_size += n;
/*NextObj(end) = _freeList;
_size += n;
if (_freeList)
NextObj(_freeList) = start;
else
_freeList = start;*/
// 条件断点
/* int j = 0;
void* cur = start;
while (cur)
{
cur = NextObj(cur);
++j;
}
if (j != n)
{
int x = 0;
}*/
}
void PopRange(void*& start, void*& end, size_t n)
{
assert(n <= _size);
start = _freeList;
end = _freeList;
for (size_t i = 0; i < n - 1; ++i)
{
end = NextObj(end);
条件断点
/* if (end == nullptr)
{
int x = 0;
}*/
}
_freeList = NextObj(end);
NextObj(end) = nullptr;
_size -= n;
}
size_t& MaxSize()
{
return max_size;
}
size_t Size()
{
return _size;
}
private:
//void* 就是一个自由链表
void* _freeList = nullptr;
size_t max_size = 1;//标识一次性threadcache可以从centralcache拿多少
size_t _size = 0; //标识一个List当中有多少数据
};
central cache

-
central cache 与thread cache类似,也是按照对应的大小的对应规则的哈希结构。
并且这个用的是桶锁,虽然centreal cache需要加锁,但是加锁的粒度还是比较小的。
span是管理多个连续大块内存跨度的结构 -
central cache挂的是一个个的span,span即跨度,它可以将一个span切分成对应桶的大小,一个个切,span是以多个页为单位的内存。
-
由上到下span当中页的数量也是不一样的,因为一个页能切若干个8Byte,但是一个256KB的对象都切不出来。
-
centralcache给threadcache的时候给批量,剩余的依旧挂在桶上。
-
自由链表_list用于标识是否页是否被用完,若为nullptr则可以认为该页的内存全部被切割完。但是不能用来判断还剩下多少。
-
_usecount 能够标识是否全部还回来了,即_usecount能够用来标识还剩下多少块内存。
总结:
- 即若用完了则由_list标识,若_usecount为0则该Span尚未被使用或已经全部还回。
在Central Cache::GetOneSpan当中切内存块的时候,建议使用尾插,因为这样别人拿到的内存是一块连续的,缓存利用率高。
页号跟进程地址强相关,跟我们的地址是强相关的,跟指针类似,只不过我们这里的跨度更大而已。我们采取一页为8KB的方案。
注意事项:
- 由于页号的大小32/64位用的必须不同,所以说采用ifdef进行条件编译,32位下用size_t,64位用unsinged longlong

来自百度百科:

- SpanList的桶的数量跟Threadcache的数量相同。
- 由于是桶锁,所以可以直接放在SpanList结构体当中。只有两个或以上线程访问到一个锁的时候会被阻塞。
//CentralCache|PageCache
class Span
{
public:
void* _freeList = nullptr;//管理小块内存的自由链表
size_t _n = 0;//标识有多少页
PAGE_ID _pageId = 0;//页号
size_t use_count = 0; //用于标识是否span有人使用,为0标识无人使用
Span* _next = nullptr;
Span* _prev = nullptr;
size_t _objsize = 0;
bool _isUse = false;
};
//封装了Span,是双链表结构
class SpanList
{
public:
SpanList()
{
_spanList = new Span;
_spanList->_next = _spanList;
_spanList->_prev = _spanList;
}
Span* begin()
{
return _spanList->_next;
}
Span* end()
{
return _spanList;
}
void Push_Front(Span* span)
{
assert(span);
insert(span, begin());
}
void insert(Span* newspan, Span* span)
{
assert(newspan);
assert(span);
//将newspan插入到span之前 prev newspan span
Span* prev = span->_prev;
//bug
prev->_next = newspan;
newspan->_prev = prev;
newspan->_next = span;
span->_prev = newspan;
}
bool Empty()
{
return _spanList->_next == _spanList;
}
Span* Pop_Front()
{
assert(_spanList->_prev != _spanList);
Span* sbegin = begin();
Erase(sbegin);
return sbegin;
}
void Erase(Span* span)
{
assert(span);
assert(span != _spanList);
Span* prev = span->_prev;
Span* next = span->_next;
prev->_next = next;
next->_prev = prev;
}
public:
std::mutex _mtx;//桶锁
public:
Span* _spanList;
};
单例模式的使用:
- 由于多个线程共享一个centralcache,所以central cache可以直接设置成单例。这里设置成饿汉,懒汉都可以。
由于这里小对象可以给多一点,大对象给少一点,所以我们可以用一个NumMoveSize来从thread cache从中心缓存获取若干个对象,这里标识了一次性能够获取的最大对象数,并且这里的值会给一个上限,和一个下限,这里是别人研究好的,但也可以调整;但我们并不是一次就给他申请这么多。所以我们还需要一个慢开始的算法,慢开始的算法需要在每一个桶都添加一个_maxSize字段,标识这个桶曾经一次性最多开辟的对象的数量。
// 计算一次向系统获取几个页
// 单个对象 8byte
// ...
// 单个对象 256KB
static size_t NumMovePage(size_t size)
{
//计算出创建多少对象共需要的字节数,再计算要获取多少页
size_t num = NumMoveSize(size);
size_t total_bytes = num * size;
//这是/
size_t n = total_bytes >> PAGE_SHIFT;
if (n == 0)
n = 1;
return n;
}
// 一次从中心缓存获取多少个
static size_t NumMoveSize(size_t size)
{
//通过一次所需要的对象的大小来计算在哪个桶拿
assert(size > 0);
size_t objNum = MAX_BYTES / size;//256K除以单个对象的大小
//最多申请512个对象,最少申请2个对象
if (objNum > 512)
objNum = 512;
else if (objNum < 1)
objNum = 2;
return objNum;
}
span指向end的next,end的前四个字节指向空即可。

page cache
page cache 申请规则:
-
在threadcache当中不能出现申请超过256K的内存以及释放256K的内存空间,在ConcurrentAlloc当中就应当做判断,当申请大的内存块的时候应当直接去pageCache当中申请。
-
pagecache当中挂着是一个个的span,但是这里的映射规则与前面的不一样,总共128个桶,centralcache找pagecache的时候只关注要找多少页的桶即可。
-
最大的桶为128页,由于单个对象最大时256KB,既可以切出4个最大的内存,已经足够了。
-
pageCache的锁用的是大锁,因为他这里用到的时候需要把多个页合并
-
当这个对应的桶没有,可以去后面的桶里面找。如果没有的话就像系统申请一个128页的span。
-
这个128页的span的内存空间是连续的,它可以被切分成1~127的页,但是只要能够合并,最终都可以合并成128页。其实合并成128页就是为了防止要大内存的时候页都是被切分小的这种情况,所以将没有使用的页进行合并是为了减少外碎片。
建立页号到Span的映射原因:
- 因为当内存释放的时候是以指针的形式传参,此时我们内部通过指针可以找到对应的页号,但是页号不能知道是哪一个Span,所以需要建立映射,这样方便更新Span的use_count,从而知道该页是否可以被合并成大页。
为何同时存在is_use和use_count两个字段?
- 有这样一种可能,当pagecache正在合并的时候,由于正好centreal cache层的span有内存块还回,此时这个span的use_count为0,但这个时候他需要获得pagecache的锁再去进行合并,而这个时候已经获取了page cache的大锁的线程若是以use_count为是否在使用的依据的话会将它合并,而它后面也会又合并一次, 那么结果就会错误。
注意:
- central cache上获取的前提条件是必须已经挂在central cache对应的桶上面,而page cache获取的页需要手动挂起来。
is_use什么时候设置成true
- 当is_use设置成true的时候应当是span还没挂在central cache,这样设置为true也不用担心就直接被使用了。
is_use什么时候设置成false
- is_use设置成false的时候说明此时可以被合并,那么一定要先从central cache下取下来,防止合并期间又被其他线程从桶当中获取内存。
注意:
用大锁的好处,当有需要一页的span和两页的span,此时只有一个三页的span,若pagecache采取的是桶锁,这个时候1号和2号桶都被不同线程上锁了,此时假设需要1号线程的跑得快,他需要1页,就拿3页的切成1页和2页,这个时候就需要2页的锁,可是2页的被线程占住了,并且他需要3号线程的锁,此时形成了死锁状态。
解决方案:
- 若是想用桶锁的话,则需要提前判断需要哪些桶,一次性获取锁起来。
如何找到知道需要多少页的span?
- SIzeClass有个函数NumMoveSize,这个函数的作用是通过数量和对象的大小查看所需要的字节数,然后再转化成需要多少页,若不满足1页则给1页。
常用的桶实际上是1~64号桶
- 实际上 256K*2(最大) / 8K = 64,实际上即使申请最大的也只要去找64号桶,
65~128的页实际上用的不频繁,所以65~128的页通常是用于挂着待切分,提前储备起来。
当由于centralcache的上了桶锁了之后,要不要释放锁再去pagecache层?
- 实际上是可以解掉的,这个时候若有内存还回桶当中,centralcache的时候依旧能够申请内存。这个时候加锁反而会把释放内存也给锁住。
- 并且因为span的use_count为0的已经从central cache解掉了,也不会影响该span,此时释放桶锁能够让其他span都利用起来,没必要在锁着了!
从PageCache获取的span切分成小内存不需要加锁
- 刚获取上来的span既不会挂在page cache,并且也还没有挂着central cache,这就说明了没有人能找到这块span,所以这个时候切分是不需要加锁的,但若要挂回去之前需要加上桶锁。
min的,由于windows.h当中有宏定义,所以这里我们选择使用min。
可以通过这种方式来确认是否来连接上,观察他的内存可以知道是否指向下一个位置。
当size=24的时候,观察下图结果,是尾插并且切分无问题。

五、释放逻辑
由于释放逻辑比较少,所以三层一起讲~
- thread cache释放的时候先往自由链表插入,满足批量内存往central cache的span还。
- central cache的span若use_count 为0表明当前span没有使用,则归还给page cache合并成一个大块内存。
- page cache负责合并use_count为0的span的前后span生成一个不超过128页的大页。
注意:
- ThreadCache::ListTooLong的PopRange这个过程将批量内存获取上来时会设置末尾连接nullptr。
- 需要动态计算PopRange的批量内存,有可能是从不同的span获取的,所以需要对每一块内存动态计算span。指针->页号->span
- span的与页号的映射都在page cache完成,但是并不是span的每一个页号都需要映射。若是申请超过128页的大页,则只需要建立第一页的映射。而返回给central cache的span都需要建立映射,因为这些页会被切成若干个小块内存,所以为了释放的时候能找到span,我们采用全部页建立映射。而挂在page cache的页只需要建立第一页和最后一页的映射,这是为了合并的时候能够找到前一页和后一页。
在我们实现的内存池当中,内碎片只是暂时的,而外碎片如果不采用小页合并成大页,那么外碎片问题则会一直存在。
常规的内存块的释放逻辑告一段落,由于超过256KB的内存是不会经过central cache层的,所以我们这里分开大块内存的申请与释放逻辑来讲。
六、大块内存的申请/释放逻辑
- 由前面可以知道小于256KB是走三层缓存。
- 而大于256KB的则至少一个对象需要32页以上,若是在32页~128页,则申请可以从page cache拿,释放的时候也可以放在pagecache的桶当中。
- 而大于128*8k的内存直接调用系统堆,此时没有用到我们的内存池,释放的时候也是直接释放的,不会放入内存池。
- 由于申请大块内存都会用到NewSpan,所以我们在这里添加申请和释放的逻辑。
void PageCache::ReleaseSpanToPageCache(Span* span)
{
assert(span);
if (span->_n >= NPAGES)
{
//大于128页直接还给堆,因为也是直接从堆申请的并且没有多个线程使用的。
SystemFree((void*)(span->_pageId << PAGE_SHIFT));
_spanPool.Delete(span);
}
}
inline static void SystemFree(void* ptr)
{
#ifdef _WIN32
VirtualFree(ptr, 0, MEM_RELEASE);
#else
// sbrk unmmap等
#endif
}
七、常见问题
用对象池替换new
- 由于一个thread cache大概在2000字节左右,对象池的大小在128*1024的话可以开个几十个,所以差不多了。
- 由于threadCache在这里的话开辟是不会轻易释放的,所以我们计算他的大小,让对象池的大小差不多够用。而span是经常进行申请和释放的,所以这里给这个值也够用。
不传对象进行内存释放
- 存储在span的_objsize的是对齐后的大小,通过指针找到页号再去找span,就能够获取他的_objsize,即如果释放内存不传内存大小,就提前存起来。
遇到性能问题的处理
- 采用条件断点(注释有)
条件断点在这个项目用于检测是否切分的是否正确好用,查看调用栈帧,配合监控使用定位问题。若遇到死循环,调试模式的全部中断能够帮助你快速定位错误。
// 条件断点
int j = 0;
void* cur = span->_freeList;
while (cur)
{
cur = NextObj(cur);
++j;
}
if (j != count)
{
int x = 0;
}
性能瓶颈测试
- MapObjectToSpan若是使用的是哈希表是需要加锁的,一开始我所采用的就是哈希表,因为插入过程是可能需要扩容,并且进行单链表的插入,这个过程会导致哈希表的结构发生变化,可能影响到其他线程对其他span的读取。



加入基数树进行优化
- 基数树是建立页号到span的映射,不同的是它的一层基数树是一次性将空间开出来,一层的基数树在32位下是完全没有问题的。

- 两层或者三层的基数树的优点在于不用一次性把数组开出来,通常在64位下使用,由于64位若一次性把页号与span建立映射,所需要的内存是十分多的,所以需要采用两层或三层基数树。
采用基数树不需要加锁的原因:
- 因为往基数树建立映射的时候是span没有在central cache不会给外层使用,并且建立好一次映射关系,后续不需要再建立了,后续都是读了。
vs打包成库
- 两步骤,项目右键属性
 - 属性有常规,点击配置类型。
- 属性有常规,点击配置类型。
end~
八、结果展示
release x86下访问不同桶的时候检测的时间。

项目源码