Mysql的事务、隔离级别、脏读、幻读以及数据落盘步骤
一、Mysql事务概念
二、事务的四大特性ACID
三、事务的隔离级别实战分析(mysql8.0版本)
四、Mysql脏读幻读不可重复读
五、Mysql从数据执行到落盘步骤分析
六、Mysql RedoLog与UndoLog日志
导读:本博文先讲解了mysql事务的概念,然后实际操作语句验证了事务的隔离级别,以及幻读、不可重复读等情况加深理解,最后引入了mysql数据落盘的步骤和RedoLog和UndoLog作用。
一、Mysql事务概念
What:事务是并发控制的基本单位。所谓的事务,就是这些操作要么都 执行,要么都不执行,它是一个不可分割的工作单位。
Why:事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性,如积分总表和积分详情表要么一起更新、新增成功要么一起失败。
How:start transaction,step 1,step2,commit/rollback
二、事务的四大特性ACID
原子性(Atomicity):原子性指的是整个数据库的事务是一个不可分割的工作单位,每一个都应该是一个原子操作。
当我们执行一个事务的时候,如果一系列的操作中,有一个操作失败了,那么,需要将这一个事务中的所有操作恢复到执行事务之前的状态,这就是事务的原子性
一致性(Consistency):一致性是指事务将数据库从一种状态转变为下一种一致性的状态,也就是说在事务执行前后,这两种状态应该是一样的,也就是数据库的完整性约束不会被破坏,另外,需要注意的是一致性是不关注中间状态的
隔离性(Isolation):MySQL数据库中可以同时启动很多的事务,但是,事务和事务之间他们是相互分离的,也就是互不影响的,这就是事务的隔离性。
持久性(Durability):事务的持久性是指事务一旦提交,就是永久的了,就是发生问题,数据库也是可以恢复的。因此,持久性保证事务的高可靠性
三、事务的隔离级别实战分析(mysql8.0版本)
事务的隔离级别详细举例加深理解:
第一种 read uncommitted(读取未提交数据)-不常用:
第一步:
user表中就这一条数据 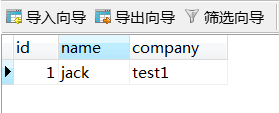
第二步:
会话一:#第一步把事务级别设置成读未提交
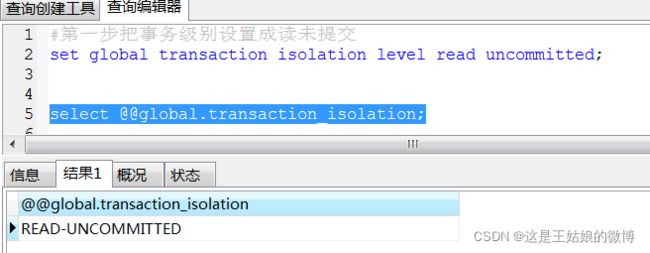
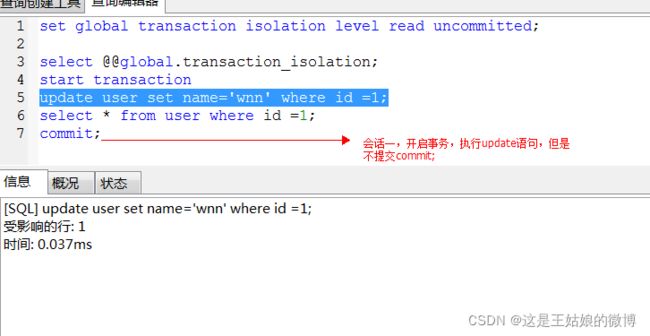 会话二:
会话二:
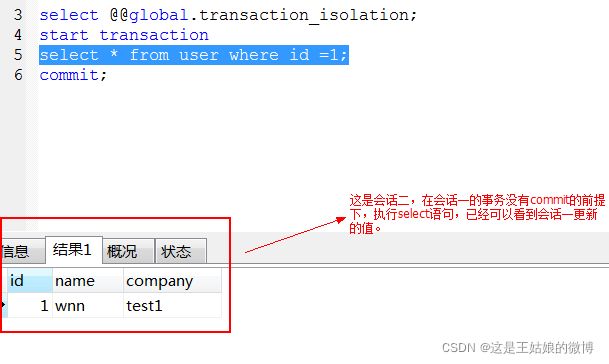
结论:即便是事务没有commit,但是其他连接仍然能读到未提交的数据,这是所有隔离级别中最低的一种(读取未提交数据)
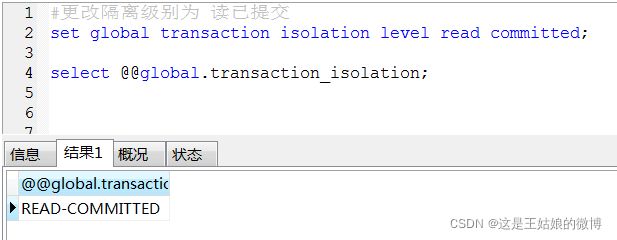
第二种 read committed(可以读取其他事务提交的数据):
第一步:
会话一:
会话二:
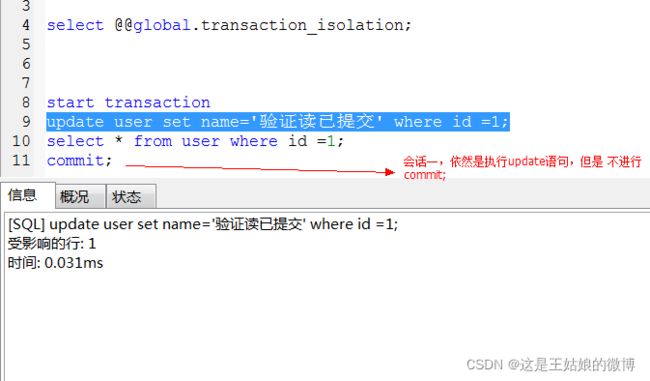
第二步:
会话一:
commit;提交下事务
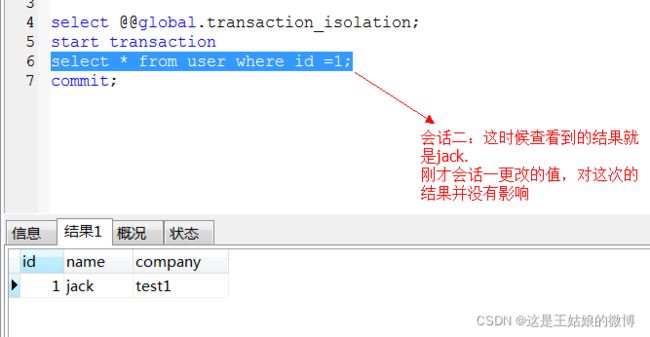
会话二:
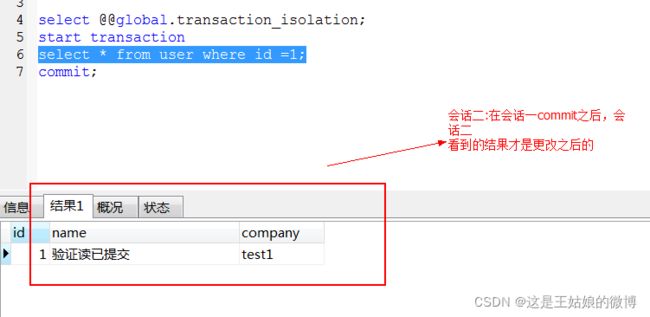
结论:当前会话只能读取到其他事务提交的数据,未提交的数据读不到
注意: 这种模式会存在一个问题:
第一步:
会话一 第一次更改,更改后进行commit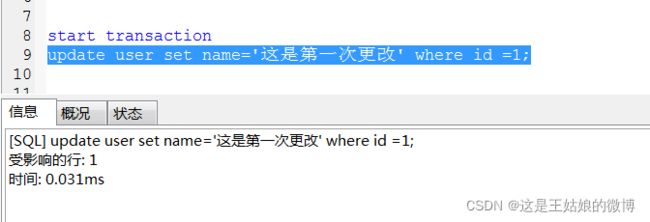
会话二进行查询: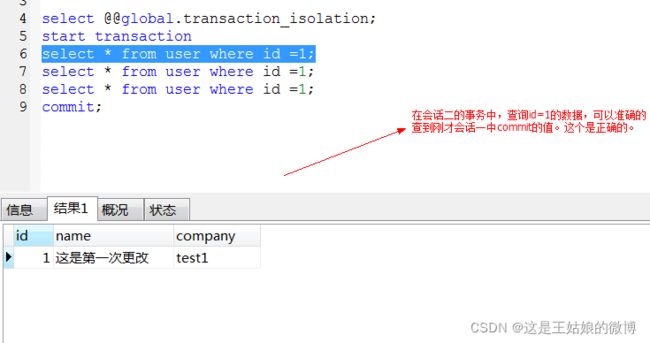
第二步:
会话一进行第二次更改,然后commit
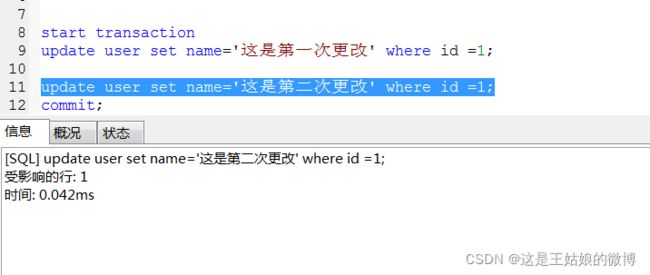
会话二:
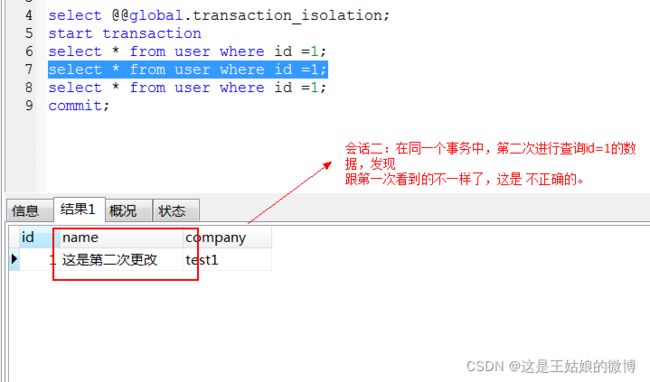
结论:需要保证同一个事务里面,多次查询数据结果是一样的。已提交读模式下是不可重复读取的。
第三种 repeatable read(可重读)---MySQL默认的隔离级别:当前会话可以重复读,意思就是每次读取的结果集都相同,而不管其他事务有没有提交
第一步:
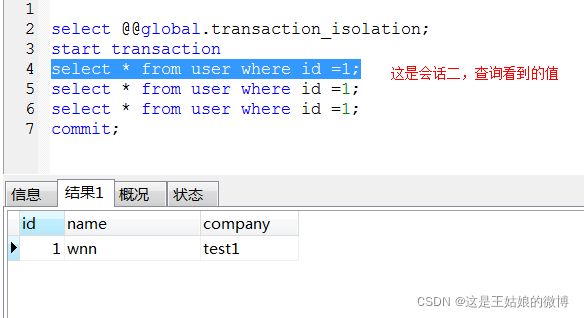
第二步:
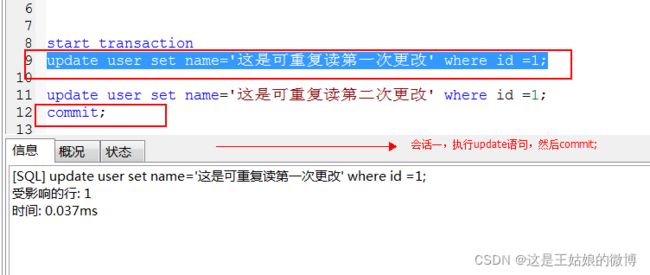
不管会话一更改几次,提交几次,在会话二的同一个事务中,看到的始终是会话二开始之后,会话一的最后一个update-commit值。
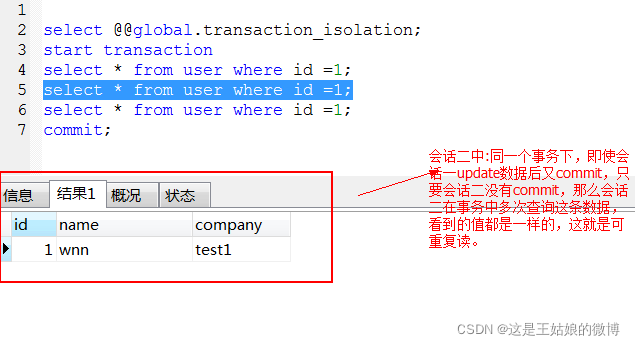
结论:当前会话可以重复读,就是每次读取的结果集都相同,而不管其他事务有没有提交。这种可重复读是mysql默认的隔离级别。
serializable(串行化)-基本不用:其他会话对该表的写操作将被挂起。这是隔离级别中最严格的,但是这样做势必对性能造成影响。
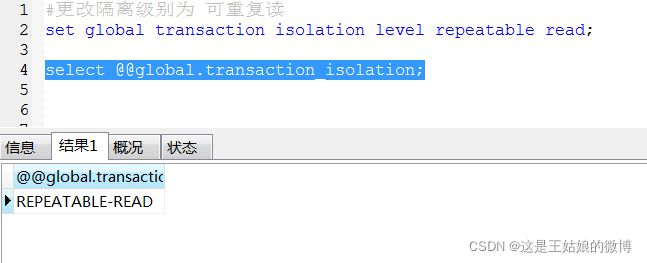
设置事务隔离级别语句(mysql8):
set global transaction isolation level repeatable read;
select @@global.transaction_isolation;#查看隔离级别
四、Mysql脏读幻读不可重复读
脏读:所谓脏读是指一个事务中访问到了另外一个事务未提交的数据
读未提交隔离状态的时候,就会出现这种情况,当session 2更新值,session1可以立马看到最新更新的name=daniel 紧跟着session2 rollback,session1又读了之前的数据,所以说session1读取到了没用的脏数据,也就是脏读
解决:隔离级别设置成读已提交 或者 可重复读 就可以解决这个问题

幻读:一个事务读取2次,得到的记录条数不一致
session1 前后查询的2次的条数都会不一样,这种称之为幻读

不可重复读:一个事务读取同一条记录2次,得到的结果不一致

不可重复读和幻读的区别:前者是针对具体一条数据后者是针对范围的数据。
解决方案:采用可重复读取(Repeatable Read),禁止不可重复读取和脏读取,但是有时可能出现幻读数据
那么什么情况下可能出现幻读数据呢?
会话一:总数十万零一条,在会话一中做了一个新增的操作后,进行commit
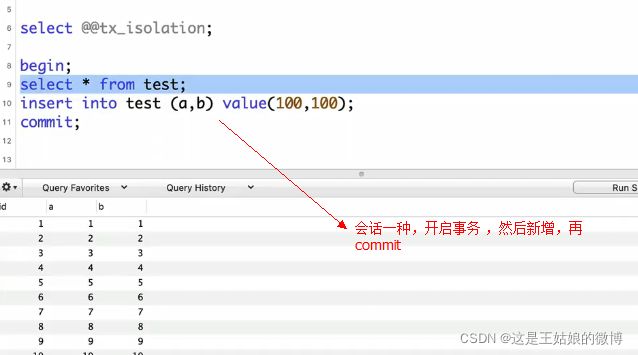
会话二:正常情况下更新一条才是正确的,但是在会话中更新了两条
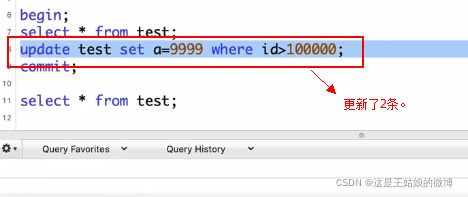
这种现象跟mysql实现可重复读的MVCC机制有关,开启一个事务后,会去表中读取数据,读取的是一个快照,所以不管读多少次,读取结果都是一样的,但是update更新的实际上的数据库,所以导致的查询结果跟update结果不一样。
结论:Innodb下可重复读还是会出现幻读,但是出现的场景是在update情况中,所以可重复读只是解决了部分幻读。使用串行化可以解决,或者是Select lock in share mode; select ...for update.
可以通过“共享读锁”和“排他写锁”实现。读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务。
五、Mysql从数据执行到落盘步骤分析
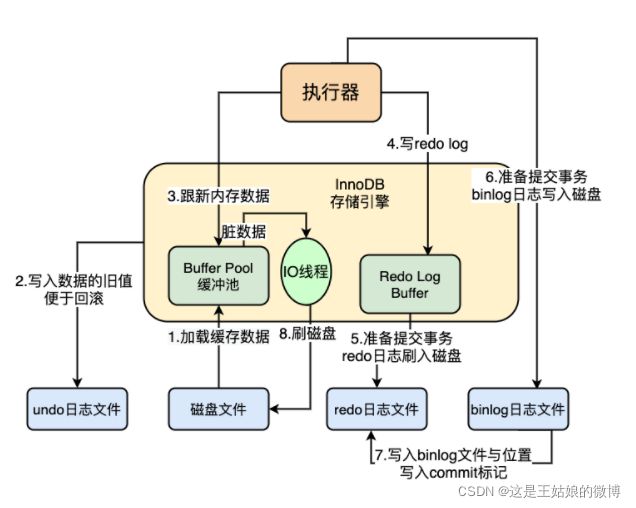
Mysql如果直接与磁盘进行交互的话,它的性能会变得特别慢,因为对磁盘交互过程当中,至少先经历找到磁盘,再找寻磁道,再找到磁道对应的上驱 这个寻址时间是特别慢的。所以直接在内存操作数据,会比磁盘快很多。
Buffer Pool是什么?
Buffer Pool(默认128MB)就是数据库的一个内存组件,缓存了磁盘上的真实数据,我们的系统对数据库执行的增删改操作,其实主要就是对这个内存数据结构中的缓存数据执行的
显示缓存:区大小 show global variables like 'innodb_buffer_pool_size';
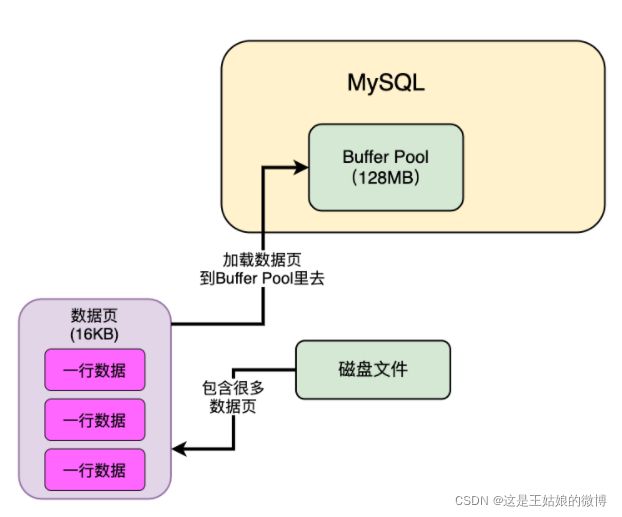
既然是内存那么就会有满了的时候,当满了的时候数据又是怎么淘汰的呢?
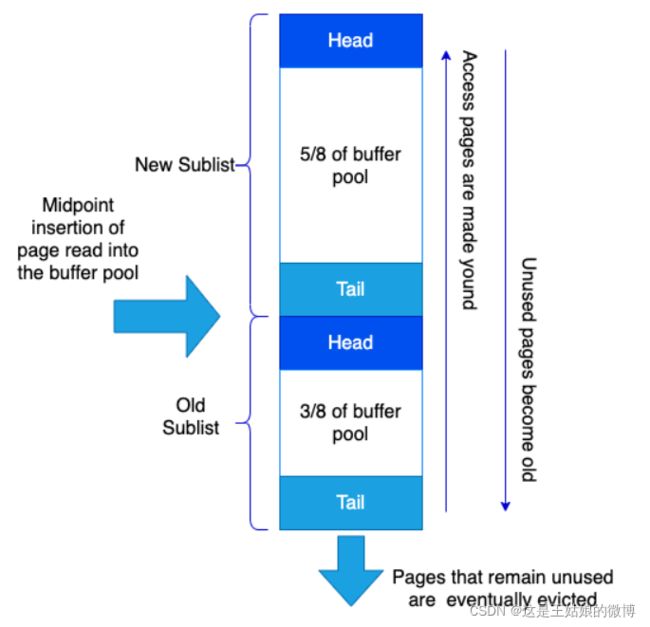
Mysql使用的内存淘汰算法 LRU (最近最少使用)
使用频率高放在new区域占比5/8.使用频率低的放在old区域,占比3/8
六、Mysql RedoLog与UndoLog日志
InnoDB 使用undo、 redo log来保证事务原子性、一致性及持久性,同时采用预写日志方式将随机写入变成顺序追加写入,提升事务性能
undo log :
作用:记录事务变更前的状态。操作数据之前,先将数据备份到undo log,然后进行数据修改,如果出现错误或用户执行了rollback语句,则系统就可以利用undo log中的备份数据恢复到事务开始之前的状态。
内容:逻辑格式的日志,在执行undo的时候,仅仅是将数据从逻辑上恢复至事务之前的状态,而不是从物理页面上操作实现的
文件位置:位于数据库的data目录下的ibdata
redo log :
作用:记录事务变更后的状态。在事务提交前,只要将redo log持久化即可,数据在内存中变更。当系统崩溃时,虽然数据没有落盘,但是redo log已持久化,系统可以根据redo Log的内容,将所有数据恢复到最新的状态。
内容:物理格式的日志,记录的是物理数据页面的修改的信息,其redo log是顺序写入redo log file的物理文件中去的
文件位置:位于数据库的data目录下的ib_logfile1&ib_logfile2
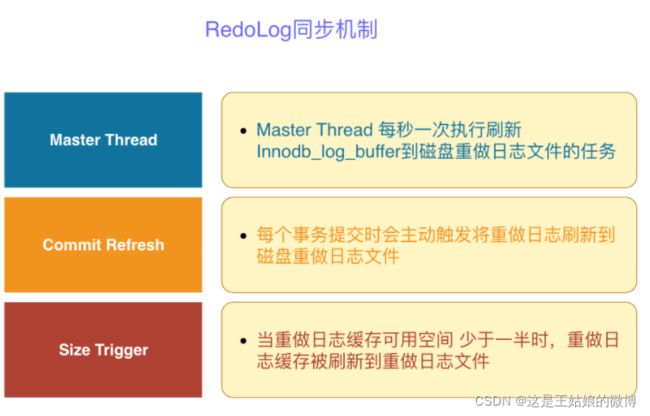
这种同步机制跟redis的定期删除、惰性删除有些类似,知识点都是想通的,要交互一起思考呀
随着时间的积累,redo Log会变的很大很大,这种mysql又是怎么处理的呢?
checkpoint:随着时间的积累,redo Log会变的很大很大。如果每次都从第一条记录开始恢复,恢复的过程就会很慢。为了减少恢复的时间,就引入了checkpoint机制。定期将databuffer的内容刷新到磁盘datafile内,然后清除checkpoint之前的redo log。
恢复:InnoDB通过加载最新快照,然后重做checkpoint之后所有事务(包括未提交和回滚了的),再通过undo log回滚那些未提交的事务,来完成数据恢复
Mysql锁系列的问题,可以看看下面这篇博文:
Mysql锁机制之行锁、表锁、死锁_这是王姑娘的微博的博客-CSDN博客乐观锁用的最多的就是数据的版本记录来体现 version ,其实就是一个标识。例如:update test set a=a-1 where id=100 and a> 0; 对应的version就是a字段,并不一定非得要求有一个字段叫做version,要求的是有这个字段,同时当满足这个条件的时候才会触发https://blog.csdn.net/wnn654321/article/details/123364797
Mysql索引系列的问题,可以看看下面这篇博文:
Mysql高性能索引_这是王姑娘的微博的博客-CSDN博客导读:本博文讲解了索引是什么和索引的底层原理,提到了BTREE和B+TREE hash底层实现以及mysql选错索引的原因和解决方式。同时涵盖高频面试题之InnoDB索引和MyIsam索引对比区别,唯一索引和普通索引的区别。https://blog.csdn.net/wnn654321/article/details/123619364